
Разработка сверхбыстрых Промышленных Контроллеров. FPGA vs MCU
Давно не писал о ходе работы своего комплекса для ПЛК (Промышленных контроллеров).
Несмотря на то что все основные вопросы я решил (графический движок, компилятор, виртуальная машина), но для коммерческого использования тут еще много работы: компилятор не выводит предупреждения или ошибки, среда тоже, и еще куча рутинных вопросов, которые я один в ближайший год не решу, особенно с учетом того что работаю по выходным.
Кто читает впервые:
Я, автор , независимый исследователь, разработчик SCADA системы Gatherlog
А так же автор комплекса по разработке Промышленных Контроллеров под названием 3o|||sheet. Среда, IDE читается как Зошыт - тетрадь, но так как для компилятора и среды выполнения названия не придумал, пока все называю 3o|||sheet.
Что касается среды разработки IDE , последнее что я добавил в нее это небольшую CAD. Я подумал, если инженер может рисовать функциональные блоки и описываеть их поведение на языках, почему бы не добавить в проект возможность сохранять графические схемы? Вся эта математика пригодится и для всяких HMI на маломощных микроконтроллерах:
Неформальная история хода разработки в прошлых постах Моими разработками, соревнуюсь с Брендами в АСУ ТП
Я решил больше не форсировать этот “долгострой” , а заняться научной деятельностью, то что под силу одному человеку - научной работой по теме - разработка нового типа отказоустойчивых систем. В чем суть , упомяну в конце. Для предпринимательства нужны деньги и люди, но для научной работы (докторские и прочее) сделанной работы - с головой хватает, так как это является реальным работающим прототипом, а не теорией.
Поехали.
В прошлых постах (особенно - первых) я тестировал свой ПЛК на микроконтроллере STM32G030, где он с треском проигрывал по производительности аналогам с рынка и даже китайским клонам (в 4 раза! В прошлых постах можно ознакомиться). Но время шло, происходила оптимизация, и сейчас мой ПЛК обгоняет китайцев и базовые ПЛК Allen Bradley.
Чтоб не быть голословным, я просто покажу участок кода отвечающий за выборку и выполнение инструкций так как это самое узкое место:
uint8_t memory[SIZE_MEMORY]; // Виртуальная ОЗУ
void (* volatile instruction[255])(void); // Массив указателей на инструкции
Главный цикл:
dec.ui = __builtin_bswap32(*(uint32_t*)&cpu.memory[PC]); // достаем из memory инструкцию
((void (*)(void)) cpu.instruction[dec.b[3]])(); //передаем опкод и вызываем обработку
// Выполняем инструкцию, например ANDM - типичная в LD цепях (контакты катушки)
void ANDM (void)
{
cpu.R[OP_A].ui &= cpu.memory[MASK20]; // Достаем переменную из памяти по адресу
}
MASK20 - immediate значение, адрес переменной или инструкции, прямо в 32 битной инструкции
Конечно, есть много чего другого еще (флаги состояний, и прочее) но это - главное.
Запомните этот код, потому что когда я буду писать что мой ПЛК STM32G030 производительнее Allen Bradley Micro810 и китайских клонов Mitsubishi FX3 на STM32F103 , чтоб каждый мог взять код и протестировать на своих микроконтроллерах если надо для замера. Важно заметить, виртуальная машина все еще написана на СИ без низкоуровневых оптимизаций, так что в коммерческом продукте если до этого дойдет, есть еще запас увеличения производительности на 10-15% от производительности которая будет показана дальше . Я держу проект на СИ для быстрого перехода на разные микроконтроллеры и CPU.
Конкуренты, все-ровно не сделают из этого кода - ПЛК , потому что главное тут - компилятор, его в двух словах не опишешь.
FPGA. Altera EP4CE6E22
Это должно было случится. Виртуальную машину я реализовал на FPGA, и теперь моя виртуальная машина больше не виртуальная, а так называемый Soft Processor. 3o|||sheet Soft Processor будет работать на такой скорости, как будто бы я его вылил - в кремние на какой нибудь фабрике чипов. По сути - создал свой процессор, с своей архитектурой и набором команд.
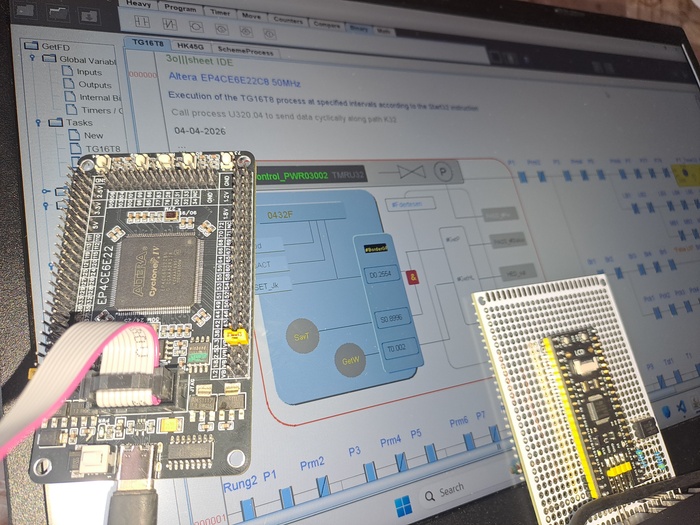
Тестовый стенд. 3o|||sheet система выполнения на FPGA Altera EP4CE6E22С8 и микроконтроллере STM32G030.
Замерялась скорость выполнения базовых логических операций LD а так же функциональных блоков с математическими операциями. Важно отметить, что под математическими операциями пока тестировалась - целочисленная арифметика типа сложение вычитание. Деление например не так просто реализовать на FPGA , это не микроконтроллер, тут самому надо описывать сигналы, и пока не тестировал, но потенциал - виден.
Результаты:
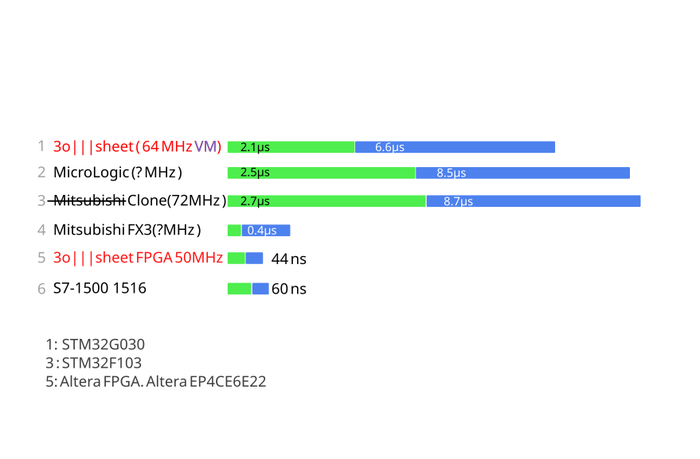
Выполнение базовых логических операций (с загрузкой переменных из памяти) в микросекундах.
Моя система указана красным, 3o|||sheet, данные по результатам замера. Остальные ПЛК , данные взяты из документации. Как видим, моя виртуальная машина на FPGA Altera EP4CE6E22С8 50MHz в десятки раз быстрее чем на микроконтроллере и мой ПЛК находится на уровне Siemens S7 1500. Добиться такой производительности на обычном процессоре пришлось бы использовать CPU в 800 Мгц.
То же самое и с ПЛК Mitsubishi , как видно разница с китайским клоном, несмотря на одну и ту же среду и компилятор - десятки раз.
Что касается Mitsubishi (оригинала) то такие показатели можно достичь и оптимизацией на низкоуровневом программировании, но так как китайцы которые делают клоны (при реверсе) жалуются что им не понятна почему Mitsubishi так неудобно расположила битовые поля в инструкциях, что замедляет их клоны, смею предположить (и это подтверждается в некоторых моделях) что оригинальные Mitsubishi используют собственные процессоры. Например выливают ARM или RISC V на фабриках, но с дополнительными собственными блоками для декодирования инструкций, а может и собственными инструкциями. Но не исключено что они используют и FPGA ( у Allen Bradley были замечены FPGA как сказал мне один электронщик). Если кто то ремонтировал оригиналы ПЛК Mitsubishi , можете поделиться в комментариях, что у них там за CPU.
Секрет FPGA в - параллельности выполнения. Если моя виртуальная машина но микроконтроллере разбирает инструкцию по очереди, тратя на это сотни тактов, то FPGA - все выполняется одновременно за один такт. Это мои первые опыты с FPGA , я не делал никаких конвейеров как в настоящих CPU, и на инструкцию у меня уходит 5 тактов. Но за счет параллельности FPGA в десятки раз быстрее делает большие операции. Можно сравнить с дуршлагом который окунули в воду - вода/логика/ сигналы мгновенно, одновременно пролезает через все дыры и тут же выполняется.
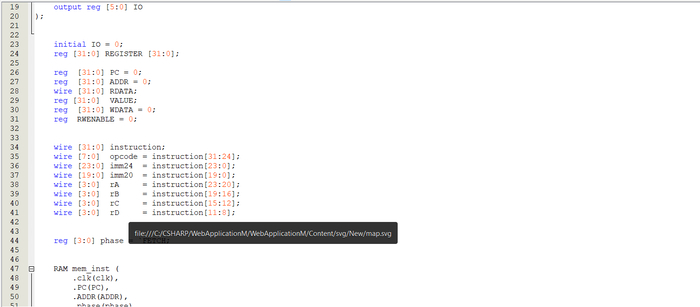
описание логики моей системы выполнения на FPGA.
Но в FPGA я пришел не за скоростью, как упоминал, я являюсь автором научной работы отказоустойчивых систем под названием Дивергентное Многоверсионное выполнение программ. Усиление ошибки, через структурную декорреляцию адресного пространства.
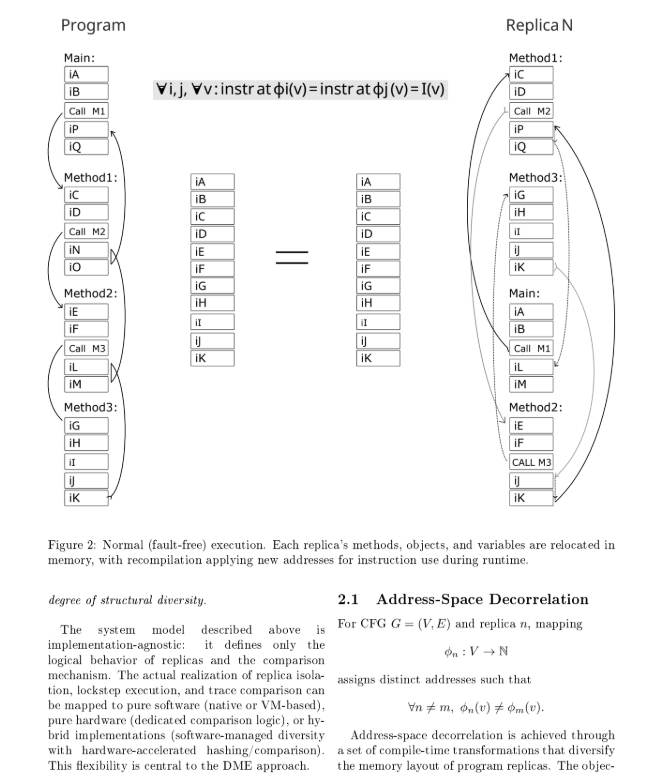
В свой компилятор я внедрил разработано мной систему DME. Суть в том чтоб по особому алгоритму (не случайному) - перемешать функции и блоки в памяти (смотри рисунок вверху), и соответственно выбросить адреса из уравнения, как шум. Отслеживать только семантику.
Компилятор собирает несколько копий одной программы но с разной адресной структурой которые выполняются параллельно (если это многоядерная система, или FPGA) или псевдопараллельно если это микроконтроллер.
Что это дает? а это дает устойчивость к коррелированным ошибкам, ошибки которые бьют сразу по всем копиям программы - одинаково. Первоначально систему разработал для отслеживания багов - собственного компилятора , идея была така - если мой компилятор верно просчитывает адреса, то даже если функции и блоки кода по разным адресам, счетчик инструкций будет сказать по одинаковым командам и переменным, но если компилятор не верно просчитывает и компилирует - то трасса выполнения разойдется сразу (а не через неделю).
Но только через какое то время я понял революционность метода, и его возможное обширное применение: тестирование компиляторов, детектирование ошибок не только компилятора но и программы которая криво написана, детектирование ошибок из за радиации и электрических помех.
Да, все эти системы которые на рынке за десятки тысяч долларов , так называемые TMR (тройное резервирование с голосованием) - не ловят коррелированные ошибки. Если например в стеке произойдет переполнение буфера, и адрес возврата затрется и программа прыгнет не в ту дверь, - хоть 50 ПЛК будет, они все начнут выполнять одинаково неверную программу и не заметят ошибки, система слетит сразу или через - неделю. Потому что существующие методы ловят ошибки на - разности, если вторая копия показывает не то что первая. А если обе ошибаются - то ошибка будет не замечена.
Привет, человеку который (мне писал) что дежурил не производстве , потому что их ПЛК слетал с катушек, и никто не мог понять причину и в каком месте ошибка.
В моей системе это невозможно - ошибка будет выявлена - сразу , а не завтра или через неделю. В классических системах, "одинаковость" результата адресов копий в ядрах или ПЛК - это признак корректности, но если все ПЛК сбиты одинаково - система не заметит ошибки, это легко может произойти при переполнении массива или повреждения адресов в стеках. В моем методе наоборот - одинаковость адресов - воспринимается как ошибка, и если баг в программе приведет все копии одной программы к одинаковому адресу \ месту программы - ошибка будет мгновенно детектирована. Мой метод ловит те ошибки которые ловят обычные ПЛК, но + и те которые не ловятся современными существующими ранее методами. Это не значит что деструктивную разность моя система не заметит, система сравнивает инструкции (опкоды, значения переменных) только не адреса, а саму логику - семантическую траекторию.
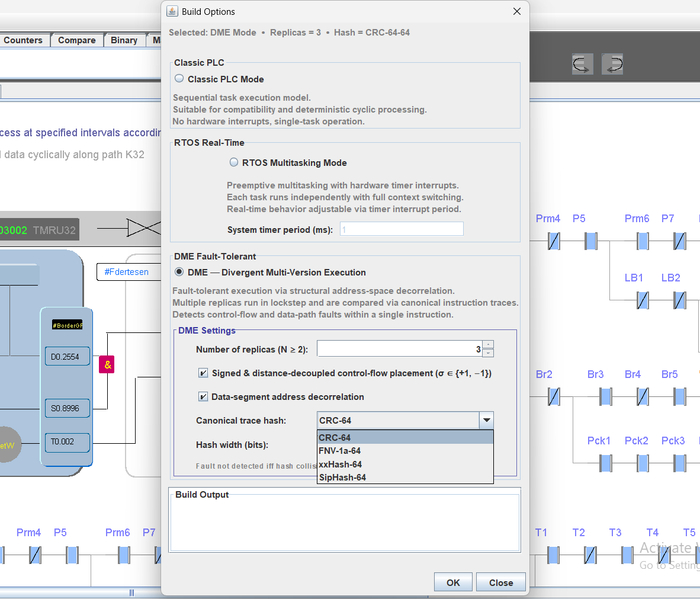
Внедрил в свой компилятор свою отказоустойчивую систему DME
Я начал разработку на FPGA чтоб запустить два ядра работающих в режиме Дивергентного Многоверсионного Режима Выполнения. Так как до этого тестировал только на микроконтроллере. Моя система - прекрасно масштабируется можно запускать N копий программы в режиме DME хоть на микроконтроллере хоть на ядрах, хоть на отдельных ПЛК.
Работа на 20 страниц, с формулами и математическими доказательствами. В то время, существующие методы с рынка в отказоустойчивых ПЛК - их надежность подтверждена - тестированием в лабораторных условиях ( ну и отзывами покупателей). Но насколько эти условия совпадают с условиями эксплуатациями? Вам покажут только лабораторные тесты, что при 10000 итераций, такой то ПЛК пропустил 2% сбоев. Тут надо просто поверить и надеяться что лабораторные условия похожи на рабочие.
У меня ситуация другая, надежность своего метода я доказываю - математически, не важно при каких условиях появится ошибка, но если в проекте инженер внесет такие то настройки , то получит такую то вероятность отказоустойчивости.
Тут конечно нужен отдельный пост про метод, его уже оценили в научных кругах исследователи и разработчики RISC V, и я продолжаю работу.
Если есть какие то вопросы - пишите в комментариях, или на почту zoshytlogic@gmail.com





