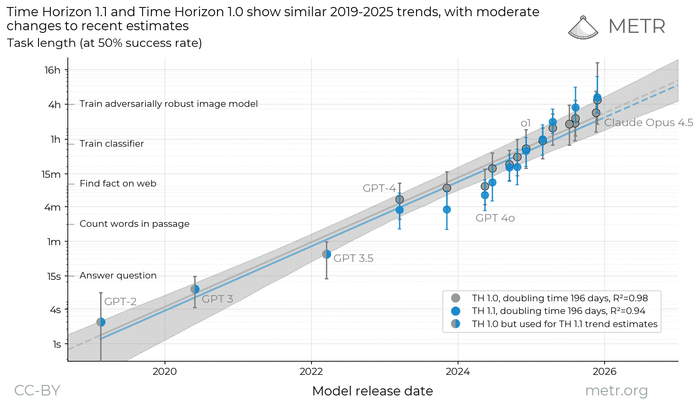
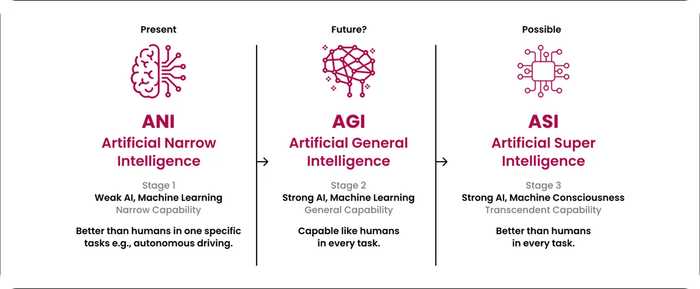
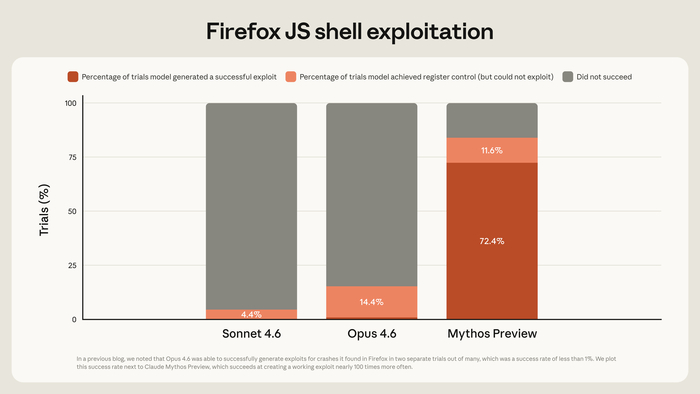
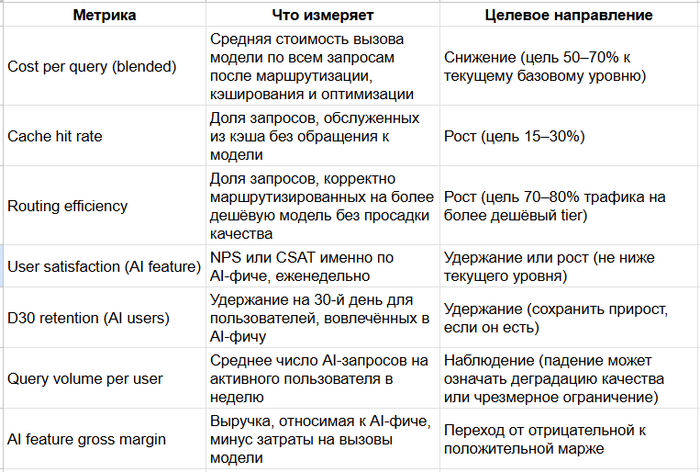
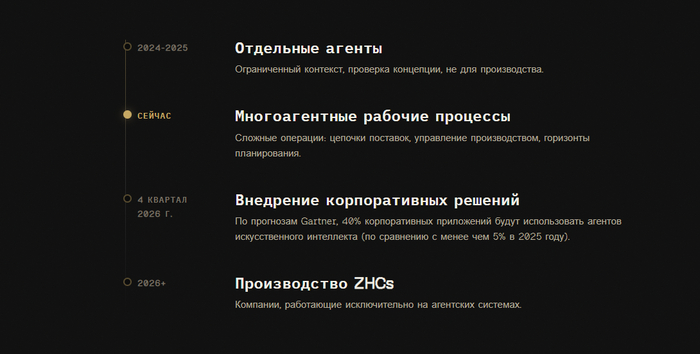
Генеральное исследование рынка ИИ-агентов и Zero-Employee Company
Все же знают, что такое генеральное исследование? Это когда учёные берут несколько опубликованных исследований различных лабораторий и синтезируют новую работу, основанную на результатах проведённых исследований, сравнивая результаты между собой. И я вот подумал, а чем я хуже или лучше учёных? Могу ли я провести самостоятельно свои исследования и затем на их основе создать итоговое генеральное исследование? Оказывается - да.

Исследование рынка ИИ-агентов и Zero-Employee Company
Запрос был примерно такой - какую компанию можно создать, какой рынок нас ждёт и на какие моменты стоит обратить внимание. Цель выглядела так - разработать модель полностью автономной цифровой организации, способной самостоятельно выполнять производственный цикл, маркетинг и управление капиталом. Исключи привязку к современным "legacy" инструментам (вроде классических платформ автоматизации) в пользу систем следующего поколения.
Путь исследования
Сам подход родился из самого понятия генерального исследования. Для начала мне нужно было сформировать запрос на исследования, провести максимальное количество исследований, скомпоновать финальный результат и подготовить само генеральное исследование.
→ Составить изначальный запрос
→ Сделать запросы к моделям
→ Собрать все ответы и источники
→ Дать одной самой сильной модели подготовить генеральный отчёт
Что использовал для исследования
Всего было использовано 11 моделей. В основном это были нейронки, с доступным режимом Deep Research. Deepseek, ChatGPT, notebooklm, glm-5.1 и другие. Там где был не доступен режим глубокого исследования использовал доступный. Одно исключение по режиму - это использование Composer 2 с кастомным скиллом в Cursor.
Ограничения режимов исследования
Не на всех моделях получилось использовать Deep Research режим. Например на Kimi он как бы доступен, но постоянно выводится сообщение вида "Слишком много людей сейчас общаются с Кими. Подпишитесь, чтобы попасть в специальную приоритетную очередь!" Но в какое бы время я не пробовал, сообщение оставалось на месте. Поэтому использовал обычный режим. У Perplexity режим Deep Research доступен только в платной подписке, что сделало не доступным его использование.
Подготовка генерального исследования
По ожиданиям, планировал готовить генеральное исследование через notebooklm от Google. Загрузил туда все материалы, но... результат меня вообще не впечатлил. Хотя сам notebooklm позиционируется как раз как место проведения подобных исследований. Поэтому для генерации генерального исследования использовал ChatGPT 5.5 Pro Extended.
Главный итог исследования и инсайты
Главный итог исследования
Наиболее устойчивый вывод совокупности материалов: жизнеспособная Zero-Employee Company к 2031 году должна пониматься не как “безлюдная” юридическая сущность, а как компания с нулевым постоянным штатом в операционном контуре. Люди сохраняются как владельцы, юридические якоря, аудиторы или лица ответственности, а ежедневное исполнение переносится в мультиагентные системы с проверяемыми ограничителями.
Десять главных инсайтов
1. ZEC нельзя проектировать как “бота, который все делает”; ее нужно проектировать как операционную систему с правами, журналами, политиками и откатом.
2. Самая устойчивая формула автономии — no-FTE operating contour: операционный штат близок к нулю, но человеческая ответственность не исчезает.
3. Нейро-символика — главный архитектурный мост между гибкостью LLM и требованиями бизнеса к правилам, объяснимости и аудиту.
4. Массовый контент дешевеет быстрее, чем доверие; поэтому медиа-модель работает как быстрый MVP, но не как финальный ров.
5. Финансовая автономия привлекательна, но без юридического контейнера, лимитов и KYC/AML может стать главным источником риска.
6. “Право на действие” становится дефицитнее, чем интеллект: многие смогут сгенерировать совет, но немногие смогут безопасно выполнить действие.
7. Data logistics и DePIN привлекательны тем, что продают SLA, provenance и доставку данных, а не абстрактную генерацию.
8. Рынок AI agents быстро растет по всем документам, но конкретные CAGR и TAM нельзя смешивать без единой методологии.9. Computer Use расширяет возможности агентов, но для критичных операций API и детерминированные проверки остаются предпочтительными.
10. Сильная ZEC должна учиться на результатах действий, но обновление бизнес-логики должно проходить через evals, sandbox и human gate для критичных изменений.
Кому полезен документ
Документ полезен основателю, инвестору, техническому лидеру, юристу, продуктовой команде или исследовательской группе, которые оценивают стратегию автономного бизнеса, выбор ниши, архитектуру агентной системы, источники защитного рва и риски юридической автономии.
Полное исследование доступно по ссылке
https://github.com/shenwell/general-research-ai-agents-zero-employee-company
Мой личный вывод по итогам исследования
В итоге я начинаю не с идеи про компанию без людей, а с теперь очевидного вопроса. Какой небольшой бизнес-процесс я могу запустить почти без ручной операционки? Беру одну узкую нишу и собираю вокруг неё понятный путь: идея → исследование → оффер → лендинг → контент → лиды → продажи → саппорт → финансы. Всё, что повторяется, постепенно отдаю агентам. За собой оставляю главное - выбор направления, продуктовые решения, деньги, качество. Моя цель не построить фантастическую автономную компанию (хотя и это тоже), а собрать систему, которая помогает находить спрос, продавать и может улучшаться после каждого цикла.
И какой итог исследования?
Для меня это было необычное погружение. Я познакомился с новыми для себя инструментами - kimi и z.ai я открывал в первый раз. Наглядно увидел возможности различных нейронок по глубине исследования. Получил массу эмоций от моего любимого формата - придумал-сделал-получил результат.
Надеюсь исследование получилось не слишком академическим и натолкнёт вас на интересные размышления в какую сторону движется мир. А идеи возникшие по ходу вы используете для действий и создания ZEC.
Если вам интересна тема Zero-Employee Company или Zero-Human Company, подписывайтесь на канал в ТГ. Там больше постов и самого пути.
Ссылка на канал: https://t.me/supervisionpw