Хомячим домашний сервер - v1.5.0. Итоги года
Прошло примерно три месяца с момента моего первого поста в этом сообществе - про то как я сделал свой домашний сервер. Я был молод и наивен полон энтузиазма и считал что уже все сделал и был готов делится опытом.
Чтош, самое время подвести промежуточные итоги и рассказать о тех ошибках, которые я натворил, возможно кому то они помогут их избежать. Ну и просто похвастаться.

Как лаба выглела три месяца назад - видно в прошлом посте. Так выглядит сейчас. Визуально все не очень изменилось. Добавилось три коробки, из которых одна - временная.
Слой железа.
Добавилась еще одна машинка. Знакомый вворемя заметил тренд на подорожание оперативной памяти и посоветовал - если тебе что то нужно - бери сейчас или потом не ной. Поэтому я залез в кубышку и приобрел еще ASUS NUC 14 Pro Tall Kit RNUC14RVHV500002I (Intel Core U5 135H Processor, Intel Arc Graphics, Intel WiFi 6E, No Operating System, with EU Power Cord), добавил к нему WD_BLACK SN850X NVMe SSD 4 TB Internal SSD и Crucial DDR5 RAM 96GB Kit (2x48GB) 5600MHz SODIMM. Все вместе стоило 1158 евро, сейчас такой же набор уже обошелся бы мне 1973 евров. Моя жаба довольна, до тех пор пока не займусь плотно llm локальными - мне желаза хватит надолго.
Добавился TP-Link TL-SG3428X 24-Port Gigabit L2+ Managed Switch (4 10GE SFP+). Ранее все устройства были воткнуты напрямую в роутер - но это не очень правильно. Добавление считча позволило мне
- обьединить все сервера в высокоскоростную сеть.
- снять нагрузку с с CPU роутера- интегрировать Omada и сделать более сложную топологию сети.
Свитч подключен 10G к роутеру, остальные три порта заняты НАС и двумя машинами.Совершенная ошибка: всего 4 быстрых порта в свитче, сейчас я бы взял 8 SFP+, а меди можно было взять меньше.
В свою защиту скажу что три месяца назад я вообще не знал что такое SFP+ и что бывают скорости больше 2.5 гигабита.
Добавился юсб - хаб, временное колхозное решение, но в серверах начало не хватать портов для переферии. Уберу в версии 2.0.
Слой ОС
Наиболее заметные изменения были именно на этом слое. Три месяца назад на одной машине у меня стоял OMV, на котором крутились все контейнеры, а на второй - Проксмокс, на котором крутились виртуалки Home Assistant.
Совершенная ошибка: OMV это прежде всего сетевое хранилище, на которое «сверху» прикрутили возможность запускать Docker. Если падает ОС или забивается системный диск логами Docker - падает всё сразу.
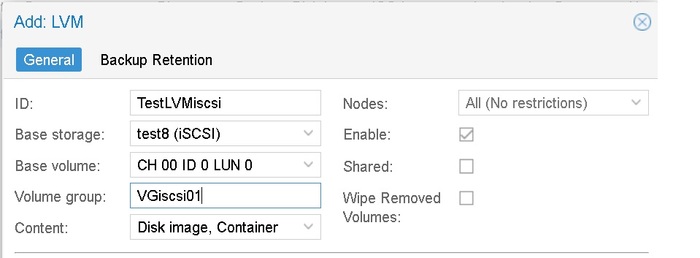
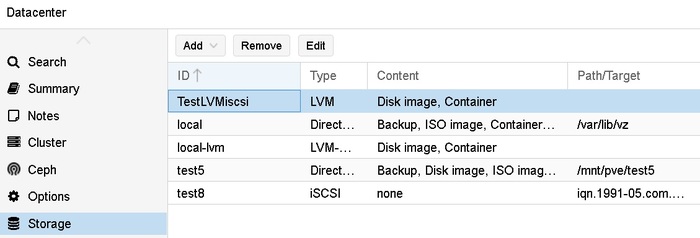
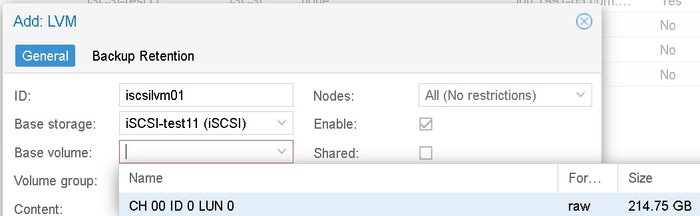
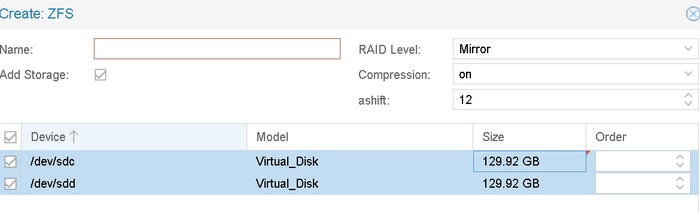
Сейчас OMV я убил полность, а на все три машины установлен Проксмокс, ноды обьединены в один управляемый кластер, критически важные машины используют SSD iSCSI-рейд на NAS.
Proxmox - это гипервизор 1-го уровня. Все сервисы живут отдельно. Падение одного не задевает другого. При наличии кластера (три+ устройства) можно использовать iSCSI луны как системные диски, можно обеспечивать High Availability state. Простыми словами - если запщущенная у меня на одной машине виртуалка падает, даже если вся машина полностью выходит из строя - проксмокс автоматически поднимает ее копию спустя пару минут на другой машине. Часто пользователь даже не замечает этого. В случае если нужно провести обслуживание одной машины - виртуалку за пару минут можно перенести на другоую машину без потери доступности. Proxmox Backup Server позволяет быстро и экономно хранить бекапы всего и вся.
Слой логики.
Совершенная ошибка: Я перетащил все 60 + контейнеров с моей машины OMV на ноду проскмос без проблем - но проблема началась позже. У меня не было распределения сервисов на "критические" и "контентные", все висело на одной виртуалке. Если она падала - падало все. А она падала!
Решением стало выделение отдельной виртуалки (infra-gateway) для системных служб (Nginx Proxy Manager, Omada Controller, Authentik, AdGuard Home, Prometheus, Grafana, Alertmanager, Uptime Kuma, Dozzle Master и CrowdSec). Я повесил ее в режим High Availability state и это стало моим лучшим решением - никакие дальнейшие эксперименты в лабе не могли "сломать мне все". Пойдя дальше я разнес окружения контента и разработки тоже на отдельные машины, но об этом позже. В свое оправдание (да, люблю я оправдываться) могу сказать что про Single Point of Failure, сиречь единая точка отказа и про Blast Radius (радиус поражения) - я тогда не слышал и не задумывался. Хождение по граблям наше все.
Слой приложений.
Этот слой тоже претерпел заметные изменения, как по содержанию, так и по логике.

Первый месяц после сборки своего сервера.
Совершенная ошибка: Первое время логика была такая - О, такая штука есть, я ее себе хочу. Таким образом у меня на OMV в докере появился например YunoHost (внутри которого, в докерах же, появились другие сервимы), или например заметную часть оперативки стал занимать почти корпоративный сервис для аудита безопасности GreenBone.
Пару месяцев спустя и заново изобрел подход (который изобрели задолго до меня) YAGNI (You Ain't Gonna Need It - не устанавливай сервис до тех пор, пока у тебя не возникла реальная, осязаемая потребность в нём. Сервисы нужно обновлять. Сервисы нужно защищать. Сервисы нужно пониторить. Сервисы нужно бекпить. Сервисы тратят ресурсы системы и электричество. Поэтому если я не планирую открывать сервис чаще чем раз в месяц - вероятно сервис мне не нужен.
Пока я не до конца прошел этот путь (у меня есть несколько сервисов с близкими или дублирующимся функциями), но постепенно от них избавляюсь. Уже избавился от Speedtest Tracker (тратит ресурсы, показывает всегда прямую линию), ByteStash (заменил Gitea), Terminal (заменил VC Code), Cockpit (заменил VC Code), YunoHost (работаю напрямую с контейнерами, так гибче и удобней)
Новые сервисы
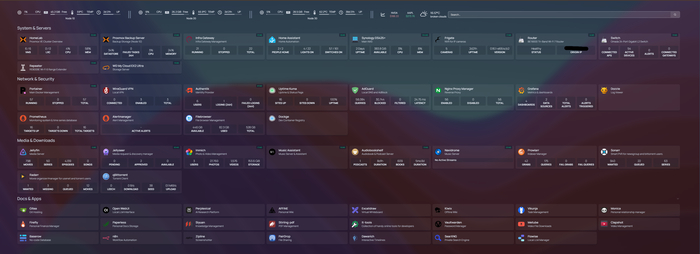
Так сейчас выглядит мой дашблорд с сервисами.
Я все еще продолжаю (и планирую продолжать) экспериментировать с сервисами. Ставлю, смотрю удобно или нет, решает ли мою проблему какую то или нет. Если нет - удаляю, если да - то оставляю. Из интересного за последние месяцы появились
Authentik - единое окно авторизации. С настройкой пришлось повозится, но потом стало очень удобно, особенно когда подвключил к сервисам жену и других родственников. Единожды создаешь пользователя в goauthentik, пользователь помнит пароль только от goauthentik, остальные сервисы используют SSO авторизацию.
Filebrowser - файловый менеджер. Ближайший кандидат к удалению. Через VC Code удобней.
CrowdSec - один из сервисов, который я почти никогда не открываю - но удалять не планирую. Этот сервис "читает" логи Nginx Proxy Manager и Authentik в реальном времени. Он видит каждый IP-адрес и то, что он пытается сделать. Как только поведение признано враждебным, CrowdSec принимает решение: забанить этот IP на определенное время. Далее он передает через апи команду в Cloudflare Bouncer, и тот блокируется на уровне серверов Cloudflare. Решение работает и децентрилизовано - если злоумышленик пытался кого то взломать (тех, у кого тоже стоит краудсек), то он автоматически будет забанен и у меня.
Dockge - сервис имеет аналогичные функции с уже имеющимся у меня Portainer, но я зачем то перевел Portainer на бизнес лицензию (бесплатную для трех нод), поэтому для остальных машин нужно иметь какой то сервис управления докерами - и я выбрал этот. Сейчас Portainer у меня управляет основными нодами (инфраструктура и медиа), а разработка, аи инструменты, фригейт и прочие живут на Dockge
Adguard Slave поселился в добавок к основному - даже если HA машина с основным adguard перегружается или недоступна - доступ к интернету остается. Синкается автоматически.
Немного изменил медиа стек. Раньше я руками заходил в пролар, искал там что-то, отправлял в куторрент. А потом руками переносил в нужную папку - музыка ли, фильмы ли, сериалы ли. Сейчас работает не так - есть Jellyseerr, который выглядит почти как Нетфликс, в котором я просто выбираю что хочу посмотреть, нажимаю "скачать", а дальше происходит магия и нужный сериал или фильм появляется в плеере.
Gitea. Я начал работать с VC Code и гитом, хранить там всякие конфиги, стаки контейнеров, автоматизации, очень удобно.
Paperless-ngx - решает проблему бумажного и цифрового хаоса, превращает горы документов в структурированную базу данных с мгновенным поиском.
Firefly III - удобный менеджер финансов, записываю расходы, доходы, смотрю красивые отчеты
охуеваю от того во сколько мне обходятся мои хобби.Vikunja - удобный таск трекер для личных задач, хобби, развития. Работает для меня и жены.
Monica - Я постоянно забываю дни рождения и всякие важные даты друзей. Эта легкая срм помогает мне, как воробушку социофобушку выносить из "оперативной" памяти всякие дни рождения, свадью, имена детей, предпочтения в еде, карьерные успехи друзей и знакомых. Вероятно люди стали думать что я стал очень внимательный к ним.
Еще несколько сервисов в процессе изучения, и их пока описывать не буду. Если вы дочитали до сюда - вы мой герой с завидной концетрацией, буду рад ответить на вопросы если такие есть.
В ближайших планах
Разрбраться с протоколом связи Meshtastic, установить дома стационарную ноду
Перенести все барахло в специальный ящик, сделать кабель менеджмент
Подключить все это к нормальному ИБП (пока проблем с сетью нет - но могут быть)
В дальних планахКупить для АИ стека машинку PGX 30KL - MT - 1 x GB10 Grace Blackwell Superchip - RAM 128 GB, попробовать поиграться с большими моделями.
Изучить автоматизацию на Flowise и n8n