Переход на Proxmox (Austria) с Hyper-V by Microsoft и VMware by Broadcom Часть 12. Немного про Cpu и кластер
Для лиги лени: ничего нового, проходите мимо
Часть 1. Общая
Часть 2. Gitlab и Nexus
Часть 3. Ansible и Ansible AWS
Часть 4. Наконец переходим к Proxmox
Часть 5, не запланированная. Обновляем Proxmox с 8.4 до 9.0. Неудачно.
Часть 6. Возвращаемся к запуску Ansible
Часть 7. Разница концепций
Разница концепций. Часть 7.1 Обновления компонентов и система информирования.
Разница концепций. Часть 7.2 Сети
Разница концепций. Часть 7.3 предисловие к теме «Дисковое пространство».
Разница концепций. Часть 7.4 «Локальное дисковое пространство».
Часть 8. Разница концепций
Разница концепций. Часть 8.1 Расположение дисков VM
Разница концепций. Часть 8.2 Добавление дисков к хосту
Разница концепций. Часть 8.3 Настройка нескольких дисков
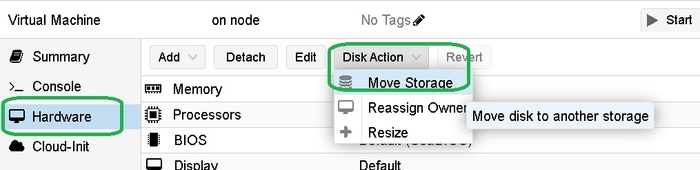
Разница концепций. Часть 8.4 Управление диском виртуальной машины.
Часть 9. Скорости дисков
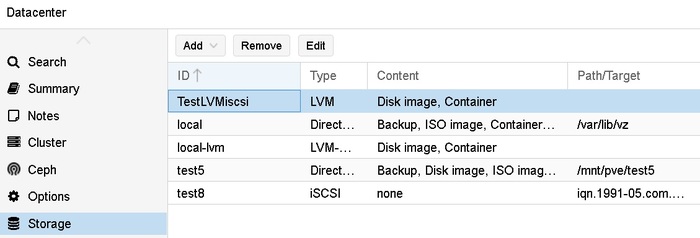
Часть 10. Внешние СХД, iSCSI
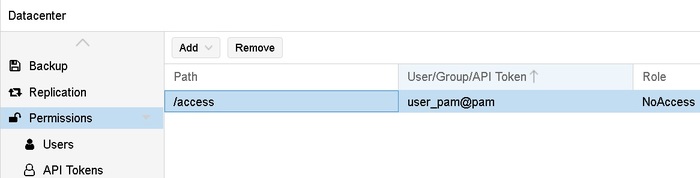
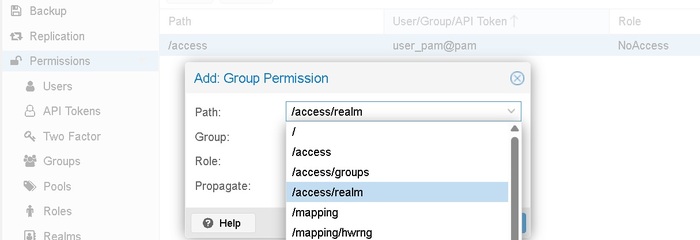
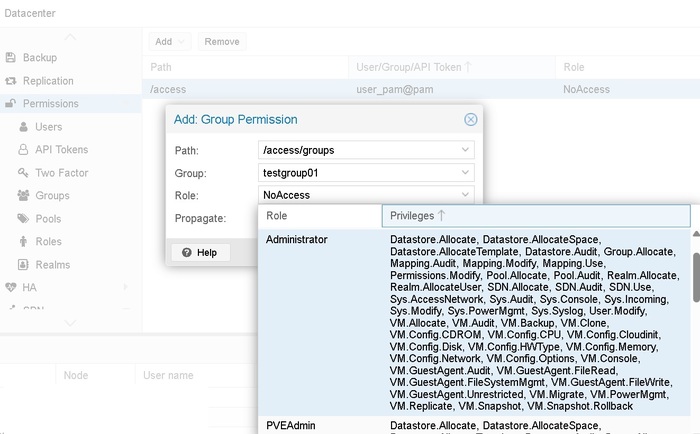
Часть 11. Система прав
Часть 12. Немного про CPU
Часть 12. CPU type
Часть 12. Hyper-threading и безопасность
Часть 12. Hyper-threading и скорость
Часть 12. CPU type
В свойствах виртуальной машины, а может где-то еще, можно настроить CPU type. Причина появления этой настройки понятна, совместимость разных поколений процессоров.
Разные поколения процессоров имеют разные инструкции. Соответственно, чтобы приложение внутри виртуальной машины после миграции не обнаружило, что на новом физическом сервере более старый процессор не умеет выполнять какую-то инструкцию, на исходном сервере операционной системе (и приложению в ней) заранее сообщается, что там стоит «виртуально более старый процессор».
Для ESXi это называется Enhanced vMotion Compatibility (EVC). И отдельно можно поиграть в CPU Compatibility Masks.
Для Hyper-V это называется Processor Compatibility Mode (CompatibilityForMigrationEnabled)
В некоторых задачах (AES) это может дать х3 снижение производительности, в других почти незаметно.
Можно ли жить без этой настройки ? Можно, и желательно держать в кластере (в любом) одинаковые сервера – не только с одинаковыми CPU, но и с одинаковыми версиями BIOS, и с одинаковой прошивкой микрокодов для CPU в этом BIOS. Не потому, что это обязательно, а потому, что так меньше возможных проблем. И плюс исправления к CPU иногда выходят, не забывайте ставить.
Можно ли мигрировать VM «без этой настройки» ?
Выключенные однозначно да, у всех.
Включенные в ESXi – нет.
Включенные в Hyper-V – нет, они с и включенной настройки иногда не мигрируют, хотя и по другим причинам.
Включенные в proxmox – я не пробовал.
Можно ли мигрировать между Intel и AMD ? В рамках домашних лабораторий и учебных стендов можете делать что угодно. В рабочей среде так делать не надо, даже когда режим совместимости заранее выставлен на минимальный минимум. Между Intel и AMD мигрировать в выключенном виде, так спокойнее.
Часть 12. Hyper-threading и безопасность
Когда-то давно, в 2018 году, для Intel нашли уязвимость L1 Terminal Fault (L1TF). Для устранения этой уязвимости, от момента обнаружения до момента выхода исправления, предлагалось, в том числе,:
The L1TF vulnerability introduces risk that the confidentiality of VBS secrets could be compromised via a side-channel attack when Hyper-Threading (HT) is enabled, weakening the security boundary provided by VBS. Even with this increased risk, VBS still provides valuable security benefits and mitigates a range of attacks with HT enabled. Hence, we recommend that VBS continue to be used on HT-enabled systems. Customers who want to eliminate the potential risk of the L1TF vulnerability on the confidentiality of VBS should consider disabling HT to mitigate this additional risk.
Microsoft Guidance to mitigate L1TF variant
После выхода и применения исправлений предлагалось включить HT обратно
Important: Disabling Intel Hyperthreading in firmware/BIOS (or by using VMkernel.Boot.Hyperthreading) after applying vSphere updates and patches is not recommended and precludes potential vSphere scheduler enhancements and mitigations that will allow the use of both logical processors. Mitigation should be done by enabling the ESXi Side Channel Aware Scheduler (see below).
VMware response to ‘L1 Terminal Fault - VMM’ (L1TF - VMM) Speculative-Execution vulnerability in Intel processors for vSphere: CVE-2018-3646
Для проксмокса были те же рекомендации, и предупреждение, цитата
L1TF CPU bug present and SMT on, data leak possible. See CVE-2018-3646 and https://www.kernel.org/doc/html/latest/admin-guide/hw-vuln/l1tf.html for details
Problem/message L1TF CPU bug and data leak
На «сейчас», после обновлений «всего», я такой рекомендации, «выключать», не видел. По крайней мере, не видел на более-менее новых процессорах и версиях 8 и 9.
Часть 12. Hyper-threading и скорость
Hyper-threading is an Intel technology that exposes two hardware contexts (threads) from a single physical core. These threads are referred to as logical CPUs. It is a common misconception that hyper-threading doubles the number of CPUs or cores. This is simply not the case. Hyper-threading improves the overall host throughput from 10-30% by keeping the processor pipeline busier and allowing the hypervisor more opportunities to schedule CPU clock cycles and so you should definitely take advantage of hyper-threading by enabling it in the BIOS of the VM host machine.
SQL Server Best Practices, Part II: Virtualized Environments
Есть несколько бытовых мифов про влияние Hyper-threading на скорость VM
Миф первый. HT замедляет работу, потому что это не настоящее ядро.
Этот миф растет из общего непонимания, что такое «ядро», и как с ним работает операционная система. HT это вообще не ядро, это «нить» или «поток исполнения»
Cores are physical processing units.
Threads are virtual sequences of instructions given to a CPU.
Multithreading allows for better utilization of available system resources by dividing tasks into separate threads and running them in parallel.
Hyperthreading further increases performance by allowing processors to execute two threads concurrently.
What Are CPU Cores vs Threads?
Тут я совсем не уверен в том, как это работает с точки зрения именно планировщика по потокам. В общем виде работает это следующим образом:
В случае нормальной работы планировщика (process scheduler \CPU scheduler ), он распределит задачи сначала по 1 потоку на физическое ядро, то есть не «на задача будет выделено физическое ядро», а «задача будет назначена на первый входящий тред физического ядра».
Поэтому в общем случае у вас не будет какой-то мега нагрузки на CPU.
Но, если вы изначально рассчитывали на включение HT и удвоение производительности, то, конечно, забудьте.
Миф второй. У меня огромнейшая нагрузка, поэтому задача, поставленная не на физическое ядро, будет работать медленно.
Поскольку речь не идет про назначение на ядра, нужно понимать, что кроме задач «на CPU», то есть математики, есть задачи ожидания из «дальней» памяти, от дисков, от сети, от пользователя, итд. Все это время само «физическое» ядро будет ждать поступления команды, и нет никаких причин для не выполнения в это время задачи из второго потока.
Скорее всего, нет у вас такой нагрузки. Но, если вы считаете, что точно есть, ну что ж, выключайте. В некоторых случаях, если вам так будет спокойнее, и вы не готовы что-то численно измерять, то можете выключить. Или сказать что выключили, иногда «сказать, что выключили и ускорили, ничего не делая» ускоряет работу системы в 1.5 раза.
Миф третий. Надо просто дать побольше ядер.
Выдать можно. Планировщик хоста будет пытаться сбалансировать треды исполнения, потому что он ничего не знает про то, какие задачи исполняются внутри.
При этом, для некоторых, довольно специфичных задач, например в случае, если у вас есть DBA, ваш DBA знает что такое NUMA, ваш DBA не боится им пользоваться, и внутри VM стоит Microsoft SQL Server 2022 или Microsoft SQL Server 2025, то выделить VM «чуть больше» чем физических ядер, и покрутить настройки трансляции NUMA может быть полезным. Про SQL soft numa и релиз ноты вообще читать полезно, как и что-то типа SQL Server Best Practices, Part II: Virtualized Environments
В остальных сценариях не надо так делать. Например, у PostgreSQL может быть грусть и тоска
Реальная сложность для меня, это отсутствие в Linux параметра CPU ready в нужном мне виде. И это не Steal time, про это ниже.
В ESXi CPU ready есть, и виден через esxtop, и в некоторых сценариях необходимо уменьшить, именно уменьшить число vCPU - Lowering the number of vCPUs reduces the scheduling wait time
Читать по теме:
CPU Ready Time Issues in ESXi Environments Running SQL Server VMs
Determining if multiple virtual CPUs are causing performance issues
How CPU management works on VMware ESXi 6.7
Для Windows server 2025 были введены новые метрики - CPU jitter counters, CPU Wake Up Time Per Dispatch, CPU Contention Time Per Dispatch, детальнее смотрите в статье CPU oversubscription and new CPU jitter counters in Windows Server 2025.
Для libvirt есть virt-top . Для поиска источника нагрузки на диски есть iotop и htop, оба кстати не установлены из коробки.
В теме Steal time monitoring есть отсылка на проект vmtop, но как его проверить на пригодность, и как он будет жить, не из коробки и с его зависимостями – мне не очевидно. Последний коммит в проект – 16 апреля 2024.
Из этой характеристики вырастает проблема с аналогом VMware DRS (Distributed Resource Scheduler) или Hyper-V Load Balancing, точнее SCVMM dynamic optimization, особенно если на это намазан толстый слой .. для ESXi слой ESXi host group и VM-Host affinity rule , для Hyper-V и SCVMM – слой VM Affinity \ Anti-affinity и Fault domain.
То есть, функционал (некий! (TM)) в Proxmox есть, Proxmox introduces Cluster Resource Scheduler for Proxmox Virtual Environment 7.3, есть отдельно ProxLB
Отдельно надо сказать про мониторинг. Я не знаю, это в Zabbix так сделано, или в Linux, или не знаю где еще, но при включенном HT, при не понятно каких условиях, нагрузка CPU выглядит как «не выше 50%».
Часть 12. И про кластер
Самое неприятное в статье Cluster Manager, это то, что там все работает от root.
Второе, не самое приятное – Corosync.
Потому что под iSCSI отдельные интерфейсы дай, под Corosync – дай (Corosync network planning), плюс лимит в хостов 20, и новостями типа with over 50 nodes in production. Ну что такое 50 нод, это ж немного. Четыре корзины по 12 лезвий.
Часть 12.Подводя итог
Если открыть статью Bibliography, то окажется, что книга Wasim Ahmed. Mastering Proxmox - Third Edition. Packt Publishing - это 2017 год, The Debian Administrator's Handbook – 2021.
Литературы мало, на русском почти нет совсем (кроме разрозненных статей). Порог входа не то чтобы высокий, но выше, чем у Hyper-V. Части привычного функционала еще нет, или он реализуется посторонними проектами. Метрокластер не понятно, как на таком строить.
Кластерная файловая система под вопросами.
Крутить локальные виртуалки – пойдет, и даже iSCSI будет работать. Провайдеры, опять же, всякие в наличии. Но это уже совсем другая история
Литература
QEMU / KVM CPU model configuration
Enhanced vMotion Compatibility (EVC) Explained
Как работает и как используется Enhanced vMotion Compatibility (EVC) в кластерах VMware vSphere
Impact of Enhanced vMotion Compatibility on Application Performance
Processor Compatibility Mode in Hyper-V
Processor compatibility for Hyper-V virtual machines
Performance Impact of Hyper-V CPU Compatibility Mode
Proxmox wiki Manual: cpu-models.conf
Proxmox wiki IO Scheduler
Proxmox wiki High Availability
Proxmox wiki Cluster Manager
Proxmox PVE Bibliography
Старая (2010) статья Multi-Core Scaling In A KVM Virtualized Environment
What is a vCPU and How Do You Calculate vCPU to CPU?
Hyper-V NUMA affinity and hyperthreading
VMware response to ‘L1 Terminal Fault - VMM’ (L1TF - VMM) Speculative-Execution vulnerability in Intel processors for vSphere: CVE-2018-3646 (55806)
Mitigation Instructions for CVE-2022-21123, CVE-2022-21125, and CVE-2022-21166 (VMSA-2022-0016) (88632)
Guidance for mitigating L1 Terminal Fault in Azure Stack
Microsoft Guidance to mitigate L1TF variant
Which process scheduler is my linux system using?
Completely Fair Scheduler and its tuning
Linux schedulers – overview
The Linux Scheduler a Decade of Wasted Cores
New EEVDF Linux Scheduler Patches Make It Functionally "Complete"
What Are CPU Cores vs Threads?
CPU oversubscription and new CPU jitter counters in Windows Server 2025