

Data Science не умер, а залёг на дно

Показать полностью
1

3 месяца назад в одном из комментариев я упомянул, что нахожусь в процессе трудоустройства в дата-саентисты из совершенно другой области деятельности. Около 20 человек попросили рассказать об этом подробнее, когда закончится мой испытательный срок. Вот он заканчивается, но мне уже сказали, что я прошел, так что вот рассказ.
## Немного предыстории.
Я работал с 2013 года на одном месте, а с 2015 года я стал занимать низкую руководящую должность и это было плохо. Напрягали и снизу и сверху, из-за чего процесс выгорания занял гораздо меньше времени, чем можно предположить. Фирма занималась разработкой систем автоматизации химических предприятий, а начальствовал я в сборочном цехе, а значит занимался не только руководством, но и складом, и сборкой, и погрузками-разгрузками, и в командировки ездил, и снег зимой чистил. Интеллектуального развития минимум, зато смог отладить процесс так, что стало появляться много свободного времени, которое я тратил на просмотр пикабу и прочего. И вот, в октябре 2019 я решил, что хватит растрачивать свой потанцевал и надо заняться чем-то интересным. Я вспомнил о том, что в 2015 году я проходил профориентационный тест на hh и он мне показал склонность к аналитике. Тогда я на это дело забил, какая еще аналитика с отверткой в руках, а теперь, в 27 лет, вспомнил и решил посмотреть, что есть в этой области и увидел дата сайенс.
## Процесс обучения
Стоит отметить, что с айти я косвенно сталкивался и исключительно в личных интересах. Как-то ковырял ардуино недолго, еще однажды решил изучать программирование и прошел курс по с++, там была самая база, но курс очень хороший (я даже пытался изучать более углубленно, но тогда застрял на указателях и не осилил). Еще упомяну, что по специальности, которую я получил аж в 2013, я сервисник транспортных и технологических машин и оборудования. В институте на программировании мы разве что оттачивали навык подсчета открывающих и закрывающих скобочек.
Так вот вернусь к октябрю прошлого года, когда 7 числа я открыл курс на степике по введению в машинное обучение (чуть ниже я прикреплю ссылки на некоторые полезные курсы и ресурсы), прочитал описание, увидел, что необходимо предварительно изучить, закрыл курс и начал по списку: python, алгоритмы, статистика, анализ данных и т.д. Только к новому году я дошел до курса по введению в МО и прошел он, после этой базы, как по маслу, а там пошли уже и нейросети.
Многие не верили, что за 3-4 месяца можно освоить профессию. Так вот мой вам ответ - и правда нельзя. Но я прикладывал очень много усилий. Как уже упоминал, у меня было некоторое количество свободного времени на работе, которое я полностью тратил на обучение. 3 месяца я совершенно не просматривал развлекательный контент: ни кино, ни сериалы, ни пикабу - я приходил с работы, и часов до 10 учился. Даже с женой чуть конфликтовали из-за этого. Весь декабрь я провел в командировке, там мы не напрягались, но на режимном заводе особо не поучишься, поэтому мой распорядок дня в декабре выглядел так: в 6:30 просыпался и учился, пока все спали, после работы быстро ел, купался и до вечера снова упарывался. Очень уж увлекло. Вот, например, моя новогодняя фотка:
По поводу ресурсов: в качестве старта мог бы порекомендовать пройти вводный бесплатный модуль яндекс практикума. Там все просто и понятно рассказывается, но, на мой скромный взгляд, довольно не структурировано и скучно. Поэтому однозначно я рекомендую курсы на степике, которые и бесплатны, и дадут необходимую базу для осмысленного гугления. В таком порядке я их проходил:
1. https://stepik.org/course/67
2. https://stepik.org/course/512
3. https://stepik.org/course/217
4. https://stepik.org/course/1547
5. https://stepik.org/course/76
6. https://stepik.org/course/129
7. https://stepik.org/course/724
8. https://stepik.org/course/524
9. https://stepik.org/course/2152
10. https://stepik.org/course/4852
11. https://stepik.org/course/8057
Это база, по МО еще очень хороший курс на курсере, но там много математики:
https://www.coursera.org/learn/vvedenie-mashinnoe-obuchenie/
А потом можно и нейросети посмотреть:
https://stepik.org/course/54098 - курс просто огонь, но он специализирован.
Важно так же учитывать, что умение работать в jupyter notebook оказалось не единственным важным умением для работы вообще: обязательно нужно понимать хотя бы как работают базы данных и уметь делать запросы и аггрегировать данные. На практике оказалось, что БД +- sql-образные, и научившись запросам в MySQL, нет проблем научится в Clickhouse, несмотря на разные архитектуры. Поэтому вот:
https://stepik.org/course/2614
Еще оказалось, что на новой работе все на линуксе. Мне, как виндоводу, оказалось полезно это:
Ну и какой смысл в моих ноутбуках, если я не умею делиться ими:
https://stepik.org/course/3145
Что еще можно сказать по обучению... Обязательно нужно закреплять полученные знания на практике: освоив какую-нибудь крупную тему, я заливал свой говнокод на гитхаб для портфолио (да, уже сейчас я вижу, что он говнокод). И несомненно нужно хоть немного знать английский.

## Собеседование и увольнение.
Так вот к февралю я уже кое-чему научился и решил наудачу сделать новое резюме. В резюме указал все честно, что я щегол, но все равно набрался наглости разослать резюме по 2-м фирмам с просьбой выслать мне тестовое задание, которые нашел в соседнем городе (30 км между городами). В своем городе ничего не было, та еще деревня. По второй вакансии мне сразу отказали, да и по первой тоже, сказав, что кандидат уже есть, да и джун я несчастный, но тестовое могут прислать, мало ли. Тестовое я сделал (необходимо было проанализировать временной ряд с явно выраженной сезонностью и сделать предсказания) и отправил с той же надеждой, типа мало ли. И вот 2 недели тишины. В один из дней на меня наезжала бухгалтерия по поводу беспорядка со спецодеждой, я в сердцах воскликнул, как меня достала эта работа, и тут же (через 2 часа, на самом деле) мне поступил звонок с приглашением на пообщаться. Формулировка та же: ничего не обещаем, но мало ли. Естественно, я поехал.
На собеседовании было неплохо и все по делу. Тестовое оказалось сделано необычно, с изюминкой, видимо это и понравилось. На технические вопросы я ответил (в основном мы общались по нейросетям, потому что я упомянул, что использовал их для своего проекта. Но т.к. всем известно, что для "import keras" много знаний не надо, меня спрашивали по их структуре: что такое функции активации, какие я знаю, почему они должны быть дифференцируемы и т.д.). По итогам собеседование мне сказали, что они еще подумают и через пару дней предложили должность. Естественно, я согласился) Тем более, что стартовую зарплату мне предложили такую же, как я получал на должности начальника на старой работе, но это говорит не об огромных зп в айти, а о мизерных зарплатах в моей "деревне", поверьте.
Увольнение проходило не так уж гладко, потому что много на мне завязано было, но отпустили с миром, за что большое спасибо.
## Новая работа
Новая работа - это жесть. Мне было очень тяжело первое время: непрерывное гугление и чтение документаций, теперь минимум 8 часов в день я непрерывно думал и голова болела каждый вечер. В конце недели я видеть компьютер не мог и ни о каком продолжении саморазвития по выходным я даже думать не хотел - вообще к компьютеру не подходил. Но самое сложное оказалось сидеть: болит не только спина, это лечится упражнениями, но даже жопа. Но ничего, за пару месяцев натер трудовой мозоль.
Не могу сказать, что я ворвался как по маслу в новую работу, было и недопонимание, и притирка к коллегам, да и просто знаний не хватает. Но отмечу, что провал в знаниях у меня больше в сторону программирования и прочих скиллов, связанных с расширением айтишного кругозора, а вот сами алгоритмы МО мне вроде неплохо даются. К тому же, контора занимается защитой трафика, поэтому мне приходится узнавать много об этом тоже: протоколы, атаки, api и т.д. В общем, обучение не прекращается никогда и за 3 месяца испытательного срока я уже научился никак не меньшему, чем за время самостоятельного обучения.
Новая работа нравится и о старой вспоминаю с легким содроганием.
Еще забавный момент. 16 марта я вышел на работу, а с 18 нас отправили по домам на удаленку. Вот до сих пор на ней сижу, в офисе был всего 4 раза за все время)
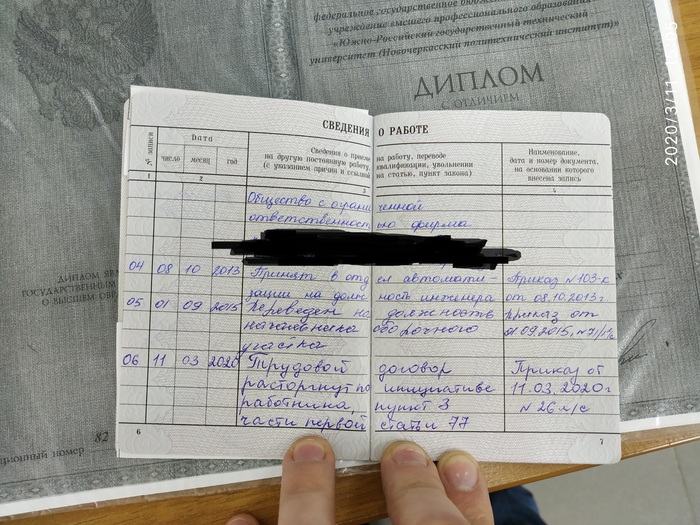
Вроде все. Вот пара пруфов для скептиков.

Недавно на межотраслевой конференции выступал директор одного сравнительно небольшого банка. Он рассказал, что у банка большие амбиции, им нужны математики, кванты и аналитики данных, но нет денег, чтобы конкурировать "со Сбербанком" и приглашать / переманивать достойных специалистов. Как же банк набирает сотрудников? Они просто берут сотрудников из НИИ за намного меньшие деньги - честно признался директор. И вроде бы все хорошо, людям больше денег платят, но сразу так обидно стало. Человек честно признается, что они платят меньше рынка людям. Людям, которые должны науку вперёд двигать, а в итоге дурацкие регрессии в банке считают.
P.s. Не так давно на дне рождения общался с парнем-ядерщиком, и он тоже собирается уходить в машинное обучение в банк. Кто же в других отраслях останется?
@Yandex.Support, Официальное обращение к вам.
Так как портал Coursera закрыл доступ к российским курсам и дал только 90 дней на завершение текущего курса, мы, нижеподписавшиеся (поставившие плюс посту) просим перенести вашу специализацию "Машинное обучение и анализ данных" (Яндекс-МФТИ) на доступную платформу для поддержки и развития российского сообщества Data Science.
https://www.coursera.org/specializations/machine-learning-da...
В качестве дополнительной меры поддержки было бы неплохо сделать этот курс бесплатным
Эта статья дает возможность познакомиться с такой методикой получения и восстановления сигнала, как Compressive Sensing.

Множество всех возможных изображений 2 на 2 с цветами, закодированными одним битом
Пространство изображений огромно, невероятно огромно, но при этом очень мало. Задумайтесь об этом на минуту. Из сетки размером всего 8 на 8 пикселей можно создать 18 446 744 073 709 551 616 различных чёрно-белых изображений. Однако из этих 18 квинтиллионов изображений очень немногие покажутся осмысленными человеческому взгляду. Большинство изображений, по сути, выглядит как QR-коды. Те, которые покажутся человеку осмысленными, принадлежат к тому множеству, которое я называю естественными изображениями. Они представляют крошечную долю пространства изображений 8 на 8. Если мы рассмотрим мегапиксельные изображения, то доля естественных изображений становится ещё меньше, почти ничтожной, однако содержит любое изображение, которое можно придумать. Так чем же эти естественные изображения так уникальны? И можем ли мы использовать эту фундаментальную разницу в собственных интересах?
Спектральное пространство
Рассмотрим два представленных ниже изображения. Оба изображения имеют размер 512 на 512 пикселя. Если вычислить гистограмму значений пикселей, то можно понять, что эти распределения идентичны. И это на самом деле так. Левое изображение такое же, как правое, только пиксели перемешаны случайным образом. Тем не менее между ними есть фундаментальное отличие. Одно выглядит как «снег» на экране старого телевизора, а другое — это лицо человека.

Слева: случайное изображение. Справа: классическое тестовое изображение женщины с тёмными волосами. Оба изображения принадлежат к пространству изображений 512 на 512
Чтобы понять фундаментальную разницу между этими изображениями, нам нужно покинуть пространство пикселей и войти в мир частотного диапазона. С точки зрения математики, преобразование Фурье — это линейное сопоставление пиксельного описания изображения с описанием в виде суммы синусов и косинусов, колеблющихся в двух измерениях. Вместо задания изображения значениями, принимаемыми каждым пикселем, мы задаём его по амплитудам каждого из составляющих его двухмерных синусов и косинусов.
Описание этих двух изображений в пространстве Фурье представлено ниже. Для отображения величины коэффициента Фурье использована логарифмическая шкала. Разница между двумя изображениями теперь очевидна. Одно имеет гораздо больше ненулевых коэффициентов Фурье, чем другое. На языке математики говорится, что естественное изображение является разреженным по базису Фурье. Именно разреженность отличает естественные изображения от случайных. Давайте же используем эту разницу с пользой для себя!
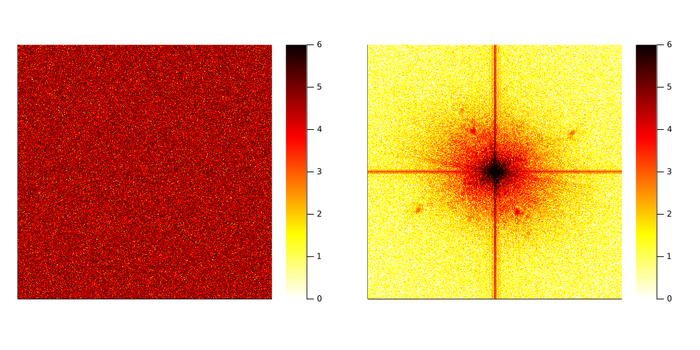
Амплитуда преобразований Фурье обоих изображений. Использована логарифмическая шкала
Воссоздание изображений по нескольким пикселям, задача с высокой степенью неопределённости

Записано всего 10% пикселей
Рассмотрим следующую ситуацию: по какой-то неизвестной причине большинство фотодатчиков камеры оказалось неисправным. Скопировав на компьютер только что сделанную фотографию своей жены (или матери, или друга), вы обнаружили, что изображение получилось таким, как показано выше. Можно ли как-то восстановить изображение?
Допустим, что мы точно знаем, какие фотодатчики исправны. Обозначив как x ∊ ℝⁿ неизвестное изображение (где n — общее количество пикселей, и мы считаем, что оно представлено в виде вектора), а как y ∊ ℝᵐ ненулевые яркости пикселей, зафиксированные датчиками, мы можем записать
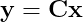
Здесь C — это разреженная матрица измерений m × n. Все элементы, соответствующие неисправным фотодатчикам, равны нулю, и она содержит только m ненулевых элементов, соответствующих исправным датчикам. Следовательно, наша задача — выяснить, каким был x исходного изображения, учитывая, что мы наблюдаем только несколько его пикселей.
С точки зрения математики, это задача с высокой степенью неопределённости. У нас гораздо больше неизвестных, чем уравнений. Эта задача имеет бесконечное количество решений. Значит, вопрос сводится к тому, какое решение из бесконечного множества является тем, которое мы ищем. Естественным способом решения такой задачи было бы принятие того, что решение имеет наименьшую норму ℓ₂. Это можно формализовать как следующую задачу оптимизации:
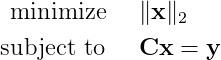
решение которой задаётся так:
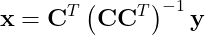
Матрица C соответствует измерениям единичных пикселей, её строки получены из единичной матрицы n × n. В такой ситуации решение задачи оптимизации не особо нам поможет, поскольку оно вернёт только повреждённое изображение (произведение матриц справа сводится к Cᵀ). Очевидно, что это нам не подходит. Но можно ли найти решение получше?
Используем разреженность в спектральном пространстве
При обсуждении уникальных особенностей естественных изображений мы увидели, что они являются разреженными в пространстве Фурье, поэтому давайте этим воспользуемся. Обозначив как Ψ отображение матрицы n × n из пространства Фурье в пространство пикселей, мы получим следующий вид уравнения измерений:
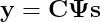
где s — преобразование Фурье x (т. е. x = Ψs). Это по-прежнему задача с высокой степенью неопределённости, но теперь у нас есть дополнительная информация о решении, которое мы ищем. Мы знаем, что оно должно быть разреженным. Введя псевдонорму ℓ₀ для s (т. е. его число ненулевых элементов), мы сможем сформулировать следующую задачу оптимизации:
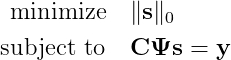
К сожалению, это задача комбинаторики, очень быстро становящаяся нерешаемой. Чтобы найти её решение, потребуется проверить все возможные сочетания. К счастью в своей революционной работе 2006 года Канде et al. [1, 2] показал, что при условии разумных допущений решение изложенной выше задачи можно получить (с высокой вероятностью) при помощи решения более простой задачи:
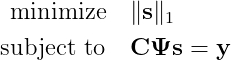
Здесь норма ℓ₁ — это сумма абсолютных значений вектора s. Сегодня хорошо известно, что использование нормы ℓ₁ кроме превращения задачи оптимизации в выпуклую, склонно отдавать предпочтение разреженным решениям. Несмотря на свою выпуклость, эту задачу всё равно может быть достаточно сложно решить на стандартном компьютере. В дальнейшем мы используем более ослабленную версию, задаваемую следующим образом:
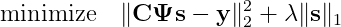
где λ — это задаваемый пользователем параметр, управляющий равновесием между соответствием ограничениям и необходимой разреженностью решения. Эту задачу оптимизации называют Basis Pursuit Denoising. При помощи проксимальных операторов она решается чрезвычайно быстро. Ниже представлена реализация на Julia с использованием StructuredOptimization.jl.
using StructuredOptimization
" " "
Simple implementation of basis pursuit denoising using StructuredOptimization.jl
INPUT
- - - - -
C : The measurement matrix.
Ψ : Basis in which x is assumed to be sparse.
y : Pixel measurements.
λ : (Optional) Sparsity knob.
OUTPUT
- - - - - -
x : Estimated image.
" " "
function bpdn(C, Ψ, y ; λ=0.1)
# - - > Initialize variable.
x = Variable(eltype(y), size(Ψ, 2))
# - - > Solve the compressed sensing problem.
@minimize ls(C * Ψ * x - y) + λ*norm(x, 1)
return ~x
end
Кроме того, мы можем воспользоваться тем фактом, что для спектральных преобразований произведение матрицы и вектора Ψs при помощи алгоритма быстрого преобразования Фурье можно вычислить за O(n log n) операций вместо O(n²).
using StructuredOptimization
" " "
Simple implementation of basis pursuit denoising using StructuredOptimization.jl
INPUT
- - - - -
m, n : Size of the image in both direction.
idx : Linear indices of the measured pixels.
y : Pixel measurements.
λ : (Optional) Sparsity knob.
OUTPUT
- - - - - -
x : Estimated image.
" " "
function bpdn(m, n, idx, y ; λ=0.1)
# - - > Initialize variable.
x = Variable(eltype(y), m, n)
# - - > Solve the compressed sensing problem.
@minimize ls(idct(x)[idx] - y) + λ*norm(x, 1)
return ~x
end
Хотя до сих пор мы предполагали, что Ψ является преобразованием Фурье, в этом фрагменте кода мы использовали косинусное преобразование, являющееся более эффективным преобразованием для изображений. Теперь у нас есть всё необходимое, поэтому давайте вернёмся к исходной задаче. На изображении ниже сравнивается истинное изображение с его реконструкцией при помощи ℓ₁.

Слева: оригинал изображения. Справа: изображение, воссозданное при помощи compressive sensing на основании данных всего 10% пикселей
Даже несмотря на то, что исправно работало всего 10% фотодатчиков камеры, формулировка этой задачи восстановления изображения в рамках Compressed Sensing позволяет нам воссоздать достаточно точное приближение к тому, каким было исходное изображение! Очевидно, что оно всё равно неидеально, однако учитывая обширность пространства изображений и бесконечное количество решений нашей задачи, нужно признать, что результат довольно хорош!
Заключение
Методика Compressed Sensing совершила революцию в сфере обработки сигналов. Если мы заранее знаем, что сигнал, с которым работаем, разрежен по указанному базису, то compressed sensing позволяет восстановить его по гораздо меньшему количеству сэмплов, чем предполагается по теореме выборки Найквиста-Шеннона. Кроме того, она позволяет значительно сжимать данные непосредственно на этапе получения, уменьшая таким образом необходимый объём хранилища данных. Также Compressed Sensing привела к возникновению неожиданных новых технологий, например, однопиксельной камеры, разработанной Университетом Райса, или новых техник обработки для создания визуализаций МРТ в медицине. Я не сомневаюсь, что в ближайшие несколько лет мы станем свидетелями множества новых способов применения этой методики.
Compressed sensing — это гораздо более глубокая область математики, чем можно судить по этому ознакомительному посту. Существует ещё множество не рассмотренных нами вопросов, например:
- Каково наименьшее количество необходимых измерений?
- Могут ли некоторые измерения быть информативнее других?
- Как выбирать эти измерения, имея базис Ψ?
- Существуют ли другие нормы, лучше подходящие для изображений?
Для ответа на эти вопросы потребуется гораздо больше математики, чем можно представить в посте. Если вы хотите знать больше, то крайне рекомендую изучить оригиналы статей, ссылки на которые я указал в конце. Также стоит изучить потрясающий веб-сайт Numerical Tours Габриеля Пейре или последнюю книгу Брантона и Кутца [3], а также соответствующий канал на YouTube (здесь и здесь).
Ссылки на научные работы
[1] Candès E., Romberg J., Tao T. Stable signal recovery from incomplete and inaccurate measurements. Communications on Pure and Applied mathematics. 58(8): 1207–1223. 2006.
[2] Candès E. Compressed sensing. IEEE Transactions on Information Theory. 52(4): 1289–1306. 2006.
[3] Brunton S. L. and Kutz J. N. Data-driven science and engineering: machine learning, dynamical systems, and control. Cambridge University Press, 2019.
Я решил собрать некоторые материалы в одном месте для всех тех, кто хочет войти в науку о данных.
Некоторые курсы я считаю обязательными (их я выделил жирным), некоторые желательными для более глубокого понимания области. Я считаю, что прохождение «жирных» курсов позволит вам приобрести некое понимание о data science, пройдя же все курсы, вы сможете претендовать на начальную позицию.Этот текст - моё видение, некоторые дополнительные ссылки я приложу в конце поста. Буду рад любой конструктивной критике.
1. Основы программирования
Введение в python (обязательно):
https://stepik.org/course/67 — введение в Питон
https://stepik.org/course/512 — введение в Питон чуть более глубокое.
Без программирования аналитику данных представить сложно.
2. Основы математики и статистики
Высшая математика и теория вероятности (желательны для глубокого понимания):
https://stepik.org/course/95/promo — введение в матанализ
https://stepik.org/course/716/promo — матанализ 1
https://stepik.org/course/711/promo — матанализ 2
https://stepik.org/course/2461/promo — курс по линейной алгебре
https://stepik.org/course/3089 — теория вероятности
Подготовительный курс по R (язык программирования для работы с данными):
https://stepik.org/course/497/promo — курс по языку программирования R
Высшая математика позволит вам понимать, что вообще происходит. Без высшей математики вы будете в науке о данных как разнорабочий на стройке — положить кирпичи можете, положить цемент можете, а вот построить крепкую стену/дом без прораба уже не сможете. Так и в науке о данных — будете знать, что такое классификатор, что такое регрессия, алгоритм k-соседей, а вот построить хорошую предсказывающую модель не сможете.
Статистика (обязательно):
https://stepik.org/course/2152
Статистика нужна. Статистика позволяет понять, как работать с данными в первом приближении.
Курсы по алгоритмам и технологиям (не обязательно, но желательно для понимания):
https://stepik.org/course/2614 — базы данных
https://stepik.org/course/217— алгоритмы
https://stepik.org/course/1547 — алгоритмы 2
Последние три курса нужны для лучшего вхождения в сферу и понимания того, что вы делаете. Так, к примеру, знание базовой алгоритмистики позволит вам избежать очень большого количества глупых ошибок.
3. Машинное обучение
Введение в машинное обучение и искусственный интеллект (обязательно):
https://stepik.org/course/4852 — введение в машинное обучение
https://stepik.org/course/401 — машинное обучение
https://stepik.org/course/8057 — машинное обучение
Тут без пояснений — если вы учите data science, то сам data science учить придется.
4. Специализация
Специализация (крайне желательно):
https://stepik.org/course/54098 — обработка текста
http://web.stanford.edu/class/cs224n/ — обработка текста
http://cs231n.stanford.edu/ — обработка изображений
https://stepik.org/course/50352 — компьютерное зрение
Специализация позволит вам применить полученные ранее навыки. Список курсов приведен крайне короткий, и вам придется самим выбирать в каком направлении двигаться дальше.
Полезные материалы
Полезности:
https://vk.com/mlcourse - классная группа, где собрано много полезной информации.
https://habr.com/ru/company/ods/blog/322626/ — курс по data science.
Источники:
Мой путь в data science — история успеха.
https://habr.com/ru/company/plarium/blog/505458/ — история успеха 2.
https://docs.google.com/document/d/1TbMBahh6PNz-qK5hCojfrTJj... (сравнительная таблица).
https://youtu.be/w-IdSp_mQuM — ещё один план-трек.





