

Higgs Audio Studio: локальная озвучка на 100+ языках с клонированием голоса и AI-режиссёром — для подкастов и аудиокниг
Озвучка текста нейросетью — давно не новость. Но почти всё хорошее живёт в облаке: платишь за символы, отдаёшь свой текст чужому серверу и упираешься в лимиты. Higgs Audio Studio разворачивает эту историю на 180°. Это портативная обёртка вокруг свежей модели Higgs Audio v3 TTS (4B) от Boson AI, которая целиком крутится на твоей видеокарте. 100% оффлайн, без подписок и без отправки данных наружу — скачал папку, запустил, говоришь.
В чём прорыв v3. Это не «читалка вслух», а модель, обученная говорить — сама расставляет интонацию, паузы и эмоции по смыслу фразы. И скачок поколения тут реально огромный: на мультиязычном тесте Higgs-Multilingual средняя ошибка распознавания (WER) упала с 52,2 у прошлой версии до 3,6 у v3, на MiniMax-Multilingual — с 49,9 до 2,7. На классическом SeedTTS — 1,11, лучший результат среди 11 моделей в таблице (Fish Audio S2 Pro, Qwen3-TTS, VibeVoice-7B, IndexTTS-2 и др.). И всё это при весе всего ~4 млрд параметров.
Главное — выразительность. В слепом тесте Emergent TTS, где судья сравнивает живость речи, v3 берёт лучший общий результат и первое место в самых сложных категориях: паралингвистика (68,6% побед), вопросительная интонация (61,4%), сложный синтаксис (60,7%). Там, где другие модели «бубнят», эта играет голосом. Она умеет шептать, кричать и даже петь, а в текст можно вставлять 43 управляющих тега: 22 эмоции, стили и 9 звуков — смех, вздох, кашель, чихание и прочее (<|emotion:amusement|>, <|sfx:laughter|>, <|prosody:pause|>).
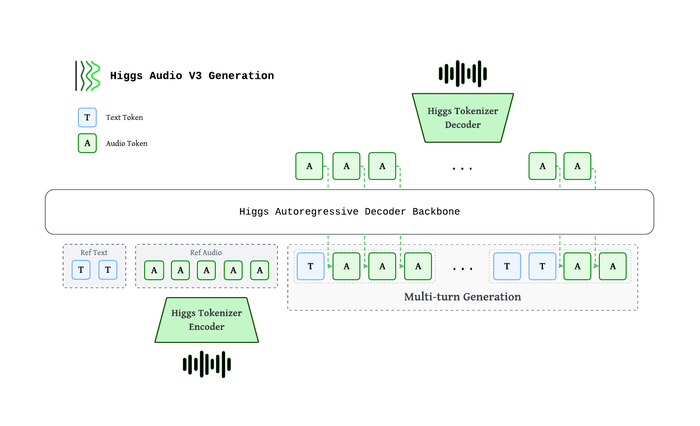
Как это устроено (на схеме в начале поста). Авторегрессионный декодер жуёт вперемешку текстовые и аудио-токены. Звук кодируется собственным Higgs Tokenizer в 8 кодбуков на 25 кадрах/сек, проходит через общий «костяк» модели и де-кодируется обратно в волну 24 кГц. Отсюда живая, многоходовая речь — модель держит контекст диалога, а не озвучивает фразы в вакууме. На серьёзном железе это ещё и быстрее реалтайма (около 7 секунд звука за секунду счёта), но и на домашней видеокарте работает бодро.
AI-режиссёр. Локальная LLM (Qwen3.5-9B / Gemma-3-12B) сама нормализует числа и даты, расставляет эмоции и разбивает длинный текст по ролям — одной кнопкой, без ручной разметки. На видео ниже режиссёр сам превратил кусок прозы в размеченный по спикерам сценарий.
Клонирование голоса. Zero-shot по одному референсу + авто-транскрипт (Moonshine ASR) — модель снимает тембр с короткого образца и говорит им. Подачу можно докручивать тегами эмоций и просодии, есть библиотека пресетов и докачка 743 русских голосов.
Подкаст и аудиокнига. В режиме подкаста достаточно задать тему — сценарий диалога модель пишет сама, раздаёт реплики нескольким дикторам (каждому свой голос) и выравнивает громкость спикеров (LUFS −16, как в индустрии). Режим аудиокниги — рассказчик плюс персонажи с постоянными голосами, длинная форма с переносом тембра. На видео — генерация подкаста на трёх спикеров из одной строки темы.
Что ещё умеет: форматы MP3 / WAV / FLAC / OGG, пакетная озвучка списком с лайв-логом, кнопка «Стоп» на лету, квантизация (bf16 / 8 / 4-бит) + torch.compile ≈2× ускорение, интерфейс RU / EN, тёмная тема. Всё внутри папки — удалил папку = удалил приложение.
Что нужно: NVIDIA GPU от 8 ГБ VRAM (для nf4; 16+ ГБ рекомендуется), 16+ ГБ RAM, ~15 ГБ на диске. Windows, а через Pinokio — ещё Linux и macOS. Установка на выбор: в 1 клик через Pinokio (сам поставит CUDA, Python, PyTorch), zip-установщик под Windows (install.bat → run.bat), готовое окружение (распаковал → run.bat) или git clone.
⚠️ Модель отдана под research/non-commercial лицензию: для себя и экспериментов — пожалуйста, а вот коммерция и клонирование чужого голоса без согласия запрещены.
🔗 GitHub: timoncool/HiggsAudio-Studio
🔗 Модель на HuggingFace: bosonai/higgs-audio-v3-tts-4b
⬇️ Portable-установщик (zip) · готовое окружение под Win11 + RTX4090 · установка в 1 клик через Pinokio
⭐️ Если проект зайдёт — поставьте звезду на GitHub, другим будет проще его найти.
👾 Пост вышел в канале НЕЙРО-СОФТ — делаем нейросети доступнее






