Ответ на пост «История про экономию, которая работает не один раз, а каждый месяц»1
Думал фуфло, а оказалось не совсем...или совсем?
Короче, история такая.
Листаю я ленту, вижу сей пост “подписка на промики, скидки эксклюзив, 199 рублей, экономия с первой покупки” и блаблабла. Первая мысль, дурят нашего брата, как с минусами. Читаю дальше что за подписка, что там за выгода такая - сомнительно, но окээээээй. Дочитываю - отрицание, гнев, торг уже позади. На стадии депрессии думаю, ещё скажите, что работает только сегодня, а потом “ой, акция закончилась, но можно купить за 499”, на стадии принятия - ладно, за 199 рублей можно и посмотреть))0))0
Посмотреть посмотрел, рассказываю что нашел.
Первое на что обратил внимание, оч мало магазинов. Да, ходовые, но и те не все - тут сразу ставлю жирный минус. Сам использовал из подписки пока всего пару промиков но и покупают все по разному поэтому тут кому что.
Теперь о том что есть неплохого. Пятерка как по мне самый большой плюс, я сам там закупаюсь часто потому что она прям в соседнем доме. Заказал продуктов на 2к с небольшим, бах - минус 550 рублей. Сделал второй заказ - ещё столько же. Минус 1к с копейками что приятно. Кстати тут лайфхак даю, больше 550р скинуть за раз не получится так что советую разбить одну доставку на две и сэкономить на обеих, ну это если покупаете много и время терпит пока две доставки довезут.
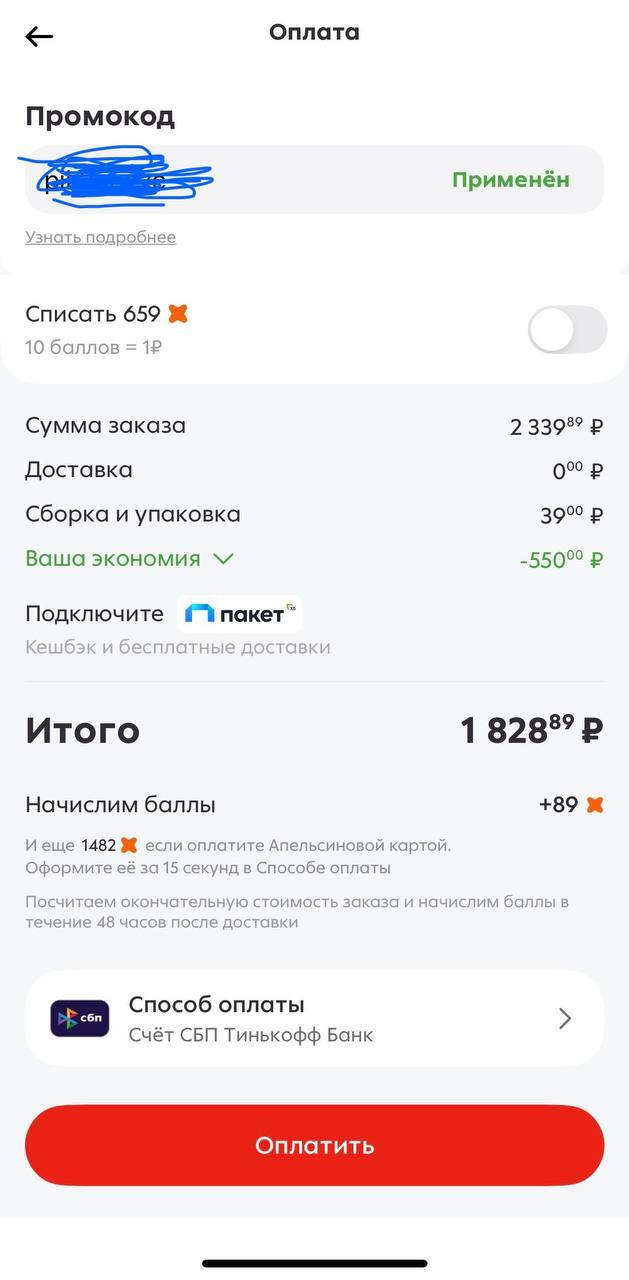
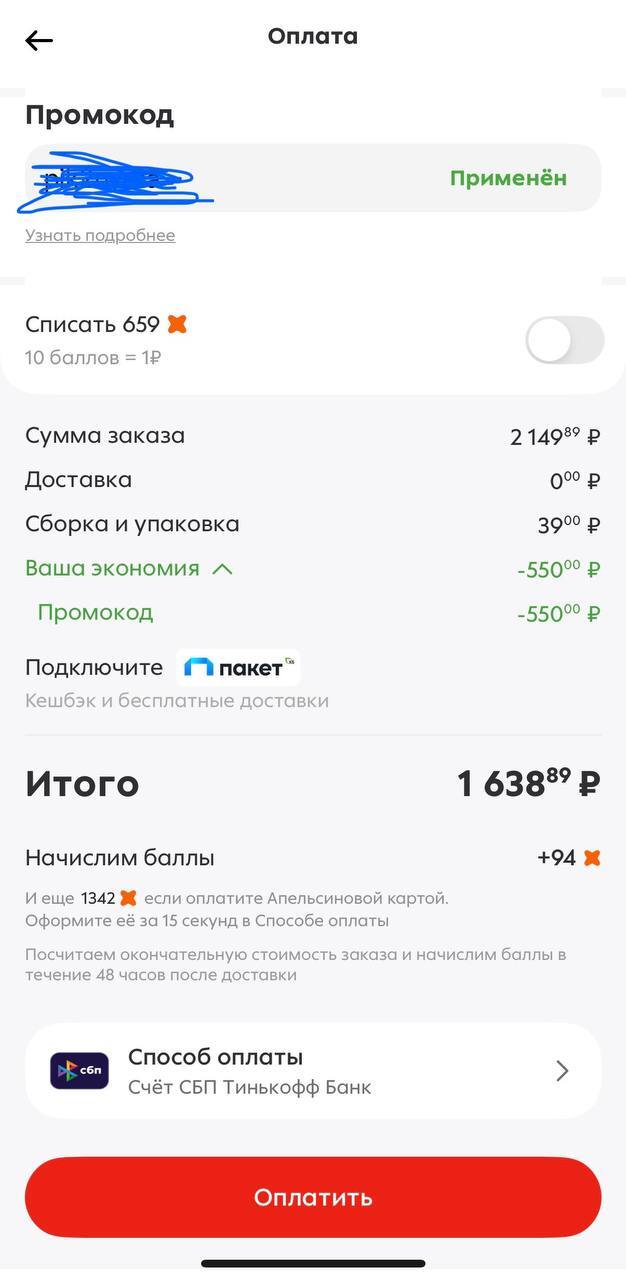
Только тут атеншн - нельзя промики плюсовать с товарами по акции. То бишь ты либо покупаешь красные ценники и экономишь без промиков, либо покупаешь по обычной цене и экономишь за счет купонов этих. Тут тоже кому что подходит больше.
Дальше Лента. В подписке есть код чтоб онлайн применить и код чтоб на кассе показать, кому как удобно. Так вот сам по себе там промик на 15% и я вообще прикола сначала не понял, их и без подписки таких полно. Типа я денег заплатил за то что я и бесплатно забрать могу, лол. Потом дошло что в подписке их во первых два, во вторых можно использовать даже если покупал уже раньше а в интернете есть только если первый раз. Короче, если кто часто закупается тут, тому выгодно.
Для животных Петшоп. Сам тут вообще не закупался раньше, тк песелю все заказываю в 4 лапы, но раз за подписку уплочено - грех не заказать. Скидка на самом деле мелкая, но и 270р лишними не бывают, так что в целом почему бы и да.

В конце увидел что еще и автозаказ можно оформить чтоб скидку увеличить, там типа по расписанию тебе будут привозить когда хочешь, я из любопытсва потыкался со страницы на страницу и забил ибо мне оно и не особо надо, кому то может быть будет ок.
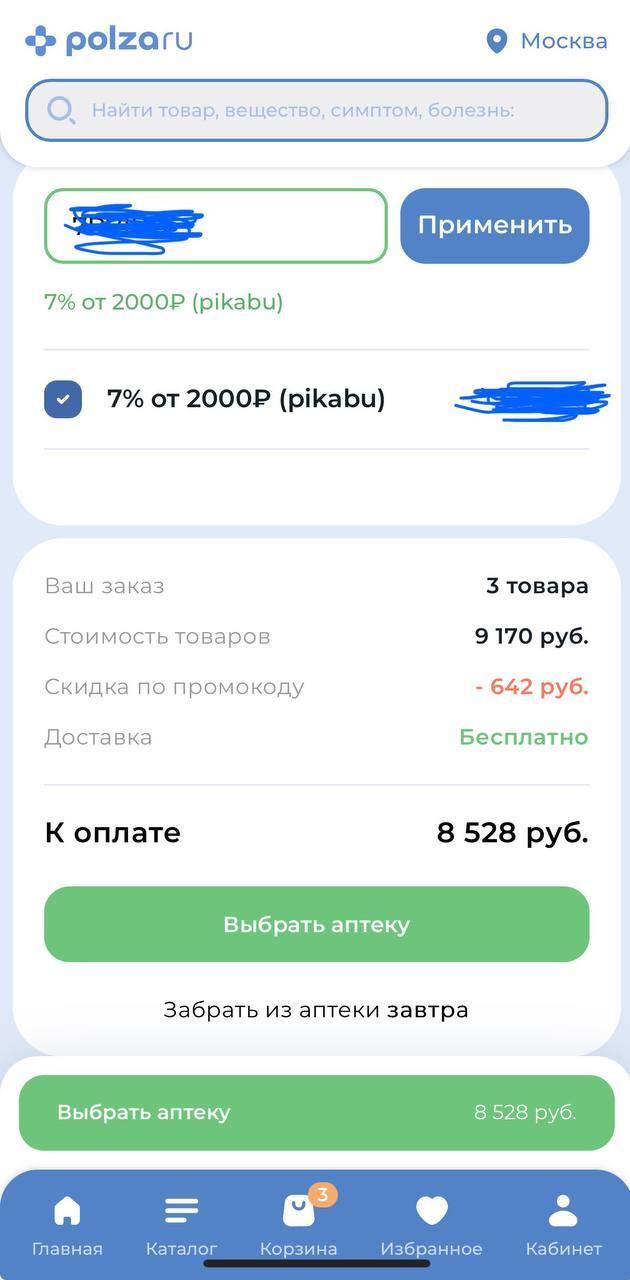
Ну и последнее что использовал аптечный промик на Пользу. Вот тут мое почтение, даже похожих рядом нигде не нашел, везде на первый на первый, в подписке на 7% если покупал уже. Да, тут у них обязательно на 2к набрать, но и у других промиков тоже куча сделай это сделай то, так что тут считаю что оправдано +650 злотых в кошелек.
Все остальное что в подписке есть пока не тестил, могу в двух словах пробежаться: мегамаркет скидку дает до 10к, но товары там в подписке конечно такое себе, магазы ноунеймы с оверпрайсом. Хофф и Леруа, тот что сейчас Лемана стал, вообще для тех, кто или ремонтом занимается или стройкой. Но сэкономить можно, в леруа промики например вообще не нашел нигде такие, опять везде первый первый а в подписке для всех есть. Плюс еще для тачек есть купоны на карш, на запчасти и сервис, но машину я не вожу мб кому то будет полезно. А ну и косметикой не пользуюсь а там дают скидку в Рив Гоше.
В общем настрой был так себе, думал, опять гоев нещадно греют. А вышло, что реально вроде как выгодно, как минимум пятерка с аптекой вообще имба, остальными можно до кучи попользоваться. Итого сэкономил 2к - за подписку отдал 199. Как говорится думайте сами, решайте сами. Всем бобра!