
На что способны такие карточки?
Я конечно не успел на это объявление но иногда бывают. На что такие карты способны?
Показать полностью
1
Я конечно не успел на это объявление но иногда бывают. На что такие карты способны?
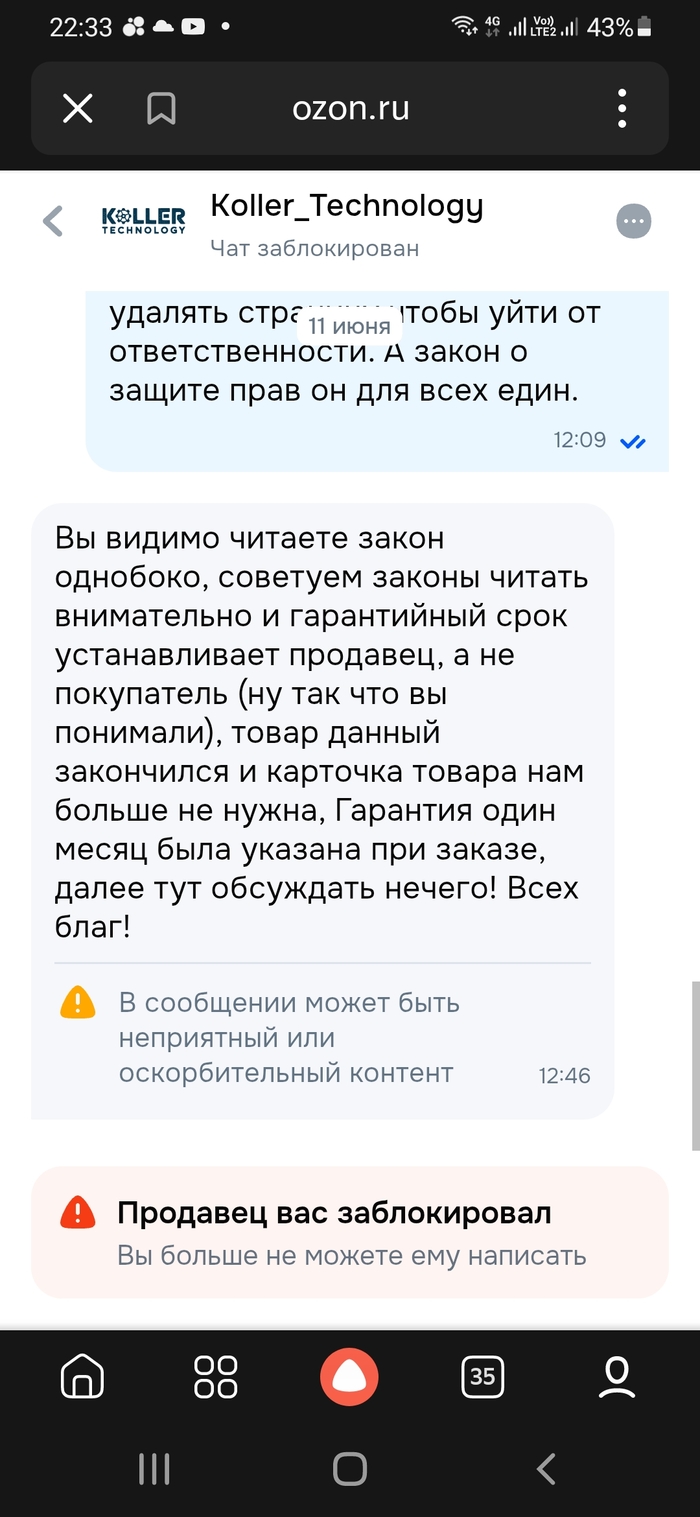
Привет, Пикабу! Хочу рассказать, какой беспредел творится на Озоне и как маркетплейс помогает наглым продавцам кидать обычных покупателей на деньги.Короче, купил я б/у видеокарту XFX Radeon RX 590 за 13 765 рублей. Заказ номер 99250306-0063, продавец Koller_Technology. Поставил в комп, а через месяц она тупо сдохла под нагрузкой, пропал видеосигнал. Классический скрытый брак, короче отвал чипа. При этом я карту не вскрывал, заводские пломбы все на месте, но когда первый раз собирал, сразу заметил на ней следы старых окислов. Продавец ее походу просто подшаманил, чтобы она этот свой один месяц гарантии отработала, и слил.По закону о защите прав потребителей у меня есть два года на возврат, если брак заводской. Я оформил возврат, Озон его одобрил, и я честно отдал карту в пункт выдачи. Товар уехал к продавцу на склад.И тут начался цирк. Продавец получает карту, сразу нажимает кнопку «Отклонить возврат» и пишет мне в чате, что его гарантия в один месяц кончилась, карточка товара ему больше не нужна и обсуждать тут нечего. И сразу после этого этот умник удаляет страницу товара и блокирует меня в чате! На скриншоте прямо горит плашка от Озона, что продавец меня забанил.А что сделал сам Озон? А Озон просто умыл руки. Вместо того чтобы включить арбитраж и наказать мошенника, они тупо заблокировали мне кнопку «Открыть спор» в приложении! Карта сейчас едет обратно, Озон предлагает мне забрать этот кирпич и по факту остаться и без денег, и без рабочей карты.Досудебную претензию я их юристам на почту уже отправил, через пару дней откроются Госуслуги — накатаю жалобу в Роспотребнадзор. Озон, вы там вообще нормальные, покрывать продавцов, которые удаляют товары и банят людей после того, как забрали у них технику? Верните деньги за бракованный товар!
Можно ли пока проверяется один жесткий диск через Викторию, качать что-то на другой диск ?
Это повлияет на проверку или нет ?
Всем привет! Сегодня у нас на операционном столе классическая драма под названием «Он просто упал с дивана, а потом началась мистика».

Речь пойдёт о ноутбуке ударнике, который пришёл с крайне навязчивой проблемой: код 43 на видеокарте.
Первым делом натравливаем на пациента классику жанра — тест MATS для проверки видеопамяти. Тест вываливает тонну ошибок по каналу C0.
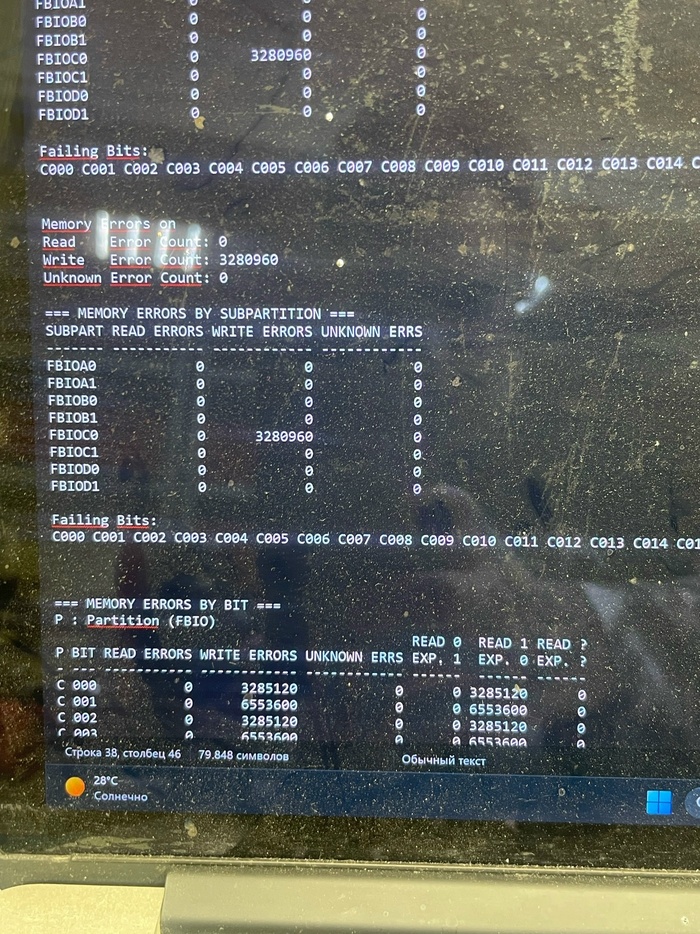
Решено — снимаем банку памяти на канале C0. И вот тут начинается самое интересное.
В поисках проблемы
Сняв чип памяти, я решил на всякий случай пробежаться мультиметром по пятакам на плате. И на одной из линий данных обнаруживаю глухое короткое замыкание на канале C0. К сожалению это не приятное совпадение и падение ноутбука тут не при чем
Делать нечего, отправляем ГПУ на станцию и аккуратно поднимаем чип.

Здесь видны последствия падения оторванный пятак, но повезло что он пустышка. Обрабатываю и закрываю специальной маской
С клиентом был согласован максимально бюджетный вариант с заменой ГПУ и памяти снятых с донора, отказались даже от нормального обслуживания, поэтому будем менять только термопасту





Также за кадром поменял видеопамять на C1 и C0 каналах
Запуск, прогон MATS — чистейшие нули по всем каналам. Код 43 ушёл в историю, ноутбук готов к новым геймерским подвигам.
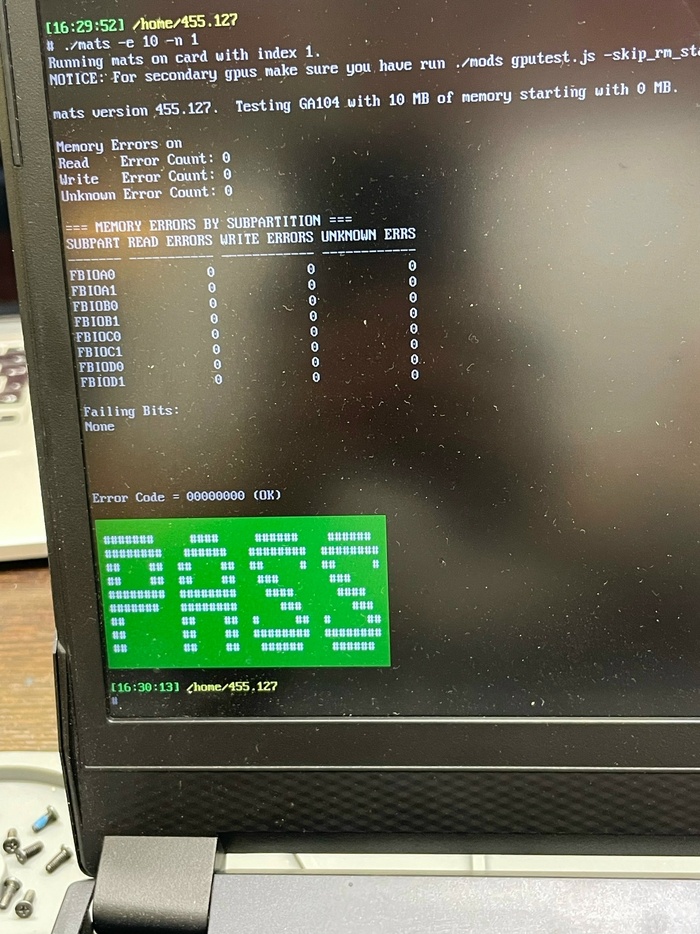
Всем успешных ремонтов!
За ремонтом можете обращаться сюда: https://vk.com/dirkin
MSI на выставке Computex показала сразу несколько технологий, которые могут появиться в будущих видеокартах NVIDIA следующего поколения. Главный акцент компания сделала на охлаждении, защите питания и повышении надёжности топовых GPU.
Первая разработка — новая система охлаждения с металлическими сверхтонкими 7-лопастными вентиляторами. Толщина лопастей составляет около 0,8 мм, а более жёсткая конструкция должна предотвращать деформацию на высоких оборотах. За счёт этого вентиляторы могут эффективнее прогонять воздух через радиатор и снижать сопротивление воздушного потока.
Также MSI использует тепловые трубки со спиральными канавками, которые увеличивают площадь теплообмена. Ещё интереснее выглядят термопрокладки из алмазного композита и новое многослойное основание кулера, где медно-алмазный композитный слой находится между двумя слоями меди. Такая конструкция должна улучшить передачу тепла от GPU к радиатору.
На Computex MSI показала прототип GeForce RTX 5090 32G GAMING TRIO с новой системой охлаждения. Серийно подобные решения могут появиться уже в следующем поколении видеокарт NVIDIA.
Вторая важная технология — новая защитная система питания, похожая на Safeguard из блоков питания MSI. Она должна повысить безопасность видеокарт флагманского уровня при работе с мощными источниками питания.
Третья новинка — серверные многоразовые предохранители eFuse. Они способны быстро реагировать на короткое замыкание примерно за 200 наносекунд и восстанавливаться после срабатывания. Прототип MSI GeForce RTX 5090 32G SUPRIM Safeguard уже показали на выставке, но массово такую защиту планируют применять в будущих топовых видеокартах.
Главный вывод: видеокарты становятся не только мощнее, но и сложнее. Теперь производители борются не только за FPS, но и за охлаждение, безопасность питания и долгую стабильную работу.
ТРЭШ-ДЕТЕКТИВ: Как купить ПК за 150к, изобрести биологическое оружие и лишиться квартиры
История о том, к чему приводит слепая вера в «маму-информатика со стажем 20 лет» и попытка провернуть «схему века» на б/у рынке. Слабонервным и эстетам лучше отойти от экрана.
🎬 Акт 1: Бизнес-план мамы-хакера
В розничном магазине парню и его маме (которая на работе администрирует Пентиум 4, но считает себя Нео из Матрицы) гениальные продавцы-консультанты впарили «топовую игровую RTX 3050» за 27 000 рублей. Но этого им показалось мало, и они докупили «доп. гарантию воздуха на 7 лет» еще за 10к.
Итого: 37 000 рублей за затычку. Карту мечты водрузили в связку к ядерному монстру Core i7-14900KF и 64 ГБ ОЗУ. На сдачу взяли самую дешевую материнку и копеечный кулер на 2 тепловые трубки. Баланс? Не слышали.
🎬 Акт 2: Вскрытие китайского Франкенштейна
Компьютер грелся до 85 градусов в простое, выл как раненый зверь и запускался ровно 20 минут, потому что система была забита майнерами. Спустя полгода парень решил, что он волк с Уолл-стрит, и выставил карту на Авито за 21к. Чтобы сделка прошла быстрее, он решил кинуть покупателя и отправил карту под видом мощной RTX 3070 (внешне кожухи были похожи).
Но покупатель оказался жестким технарем. При проверке он обнаружил, что под видом RTX 3050 парню изначально продали подвальный китайский муляж — древнюю Radeon RX 580 2048SP с чипами памяти Hynix, у которой радиатор был отлит из крашеного серого пластика, а у вентилятора вообще не было лопастей! То есть парень полгода охлаждал раскаленное железо куском пластмассы.
🎬 Акт 3: Органическое возмездие
Разгневанный покупатель вернул посылку, но перед этим устроил тотальную биологическую месть — намертво замазал весь пластиковый радиатор фекалиями, обильно полил нашатырем, мочой и пердежным спреем из магазина приколов.
Наш юный гений, не заметив подвоха (или понадеявшись, что само высохнет), воткнул карту обратно в ПК и запустил стресс-тест. При 85 градусах пластиковый муляж сработал как промышленный вейп-испаритель. Смесь закипела и начала шкворчать, как сочный стейк на сковороде, а раскаленные капли брызнули прямо на материнскую плату и процессор.
🏆 Финал комедии:
Топовый i7-14900KF официально мертв. Агрессивные кислоты и щелочь просочились под крышку процессора, разъели кремниевые контакты и замкнули плату. Медный кулер просто растворился и заржавел. Теперь проц за 60к работает дорогим вонючим брелоком.
Авито-киллеры. Аккаунт парня забанили навсегда без права восстановления, потому что в ответ на претензии покупателей он крыл всех трехэтажным матом в личке.
Экологическое бедствие. Вся квартира (где живет табор из 10 человек, включая 7 детей) намертво провоняла привокзальным туалетом. Выветрить запах не удалось за полгода — семья официально бросила квартиру и съезжает.
Великий даунгрейд. Парень собрал новый ПК на Core i3 второго поколения и видеокарте GT 550Ti на 1 ГБ и теперь плачет в подушку, пока его мама-информатик пишет объяснительную мужу.
Мораль: Не пытайтесь налюбить Авито, чистите кулеры и никогда не покупайте видеокарты из пластика.
перепробовал всё. Обновлял драйвера, пробовал другие версии драйвера. пробовал включать и выключать устройство в диспетчере устройств. Пытался разобраться с питанием. Ничего не помогло. Видеокарта NVIDIA GEFORCE RTX 3050 Laptop GPU. Искренне надеюсь, что проблема не в технической части видеокарты. Способов починить это программно пока ещё не нашёл.
-вкл ReSizable Bar,cpu получает полный доступ ко всему объёму видеопамяти,мгновенно перекидывая тяжёлые текстуры,геометрию уровней и шейдеры.
А это плавность картинки,ускорение работы в софте-рендеринг,нейросети,где важна скорость обмена данными. Повышенные FPS и плавность в играх.




