Ответ на пост «Как я проходил ДНК-тест»6
В общих чертах ваш геном (не весь, а только наиболее общие, не редкие и независимые варианты, закодированные как 0 - если обе копии аллели референсные, например АА, 1 - если гетерозигота АT, и 2 - если TT) добавляется в матрицу к референсной выборке, состоящей из таких же геномов других людей. Чем разнообразнее и больше выборка, тем лучше.
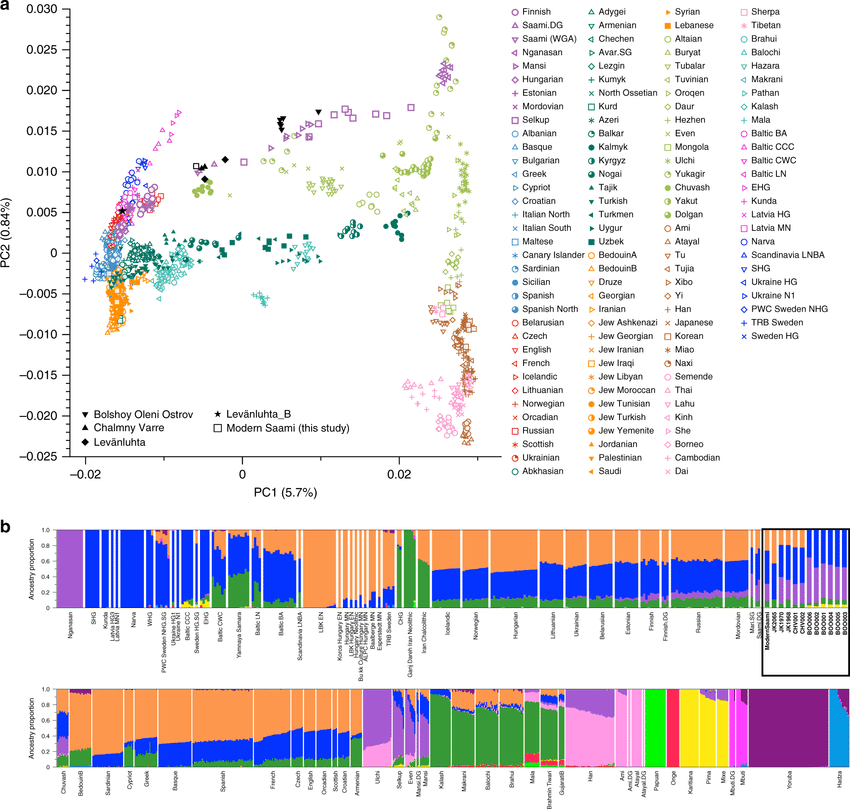
Далее проводится principal component analysis, который уменьшает размерность матрицы до нескольких наиболее значимых векторов. Вектора 1 и 2 чаще всего используются для визуализации кластеров, как на картинке ниже. Т.е. люди, которые генетически ближе друг к другу, будут рядом. Чтобы определить с какой-то точностью, к какой группе ты определен, проводится анализ кластеризации на этих наиболее важных векторах. Это чаще всего модели машинного обучения.
Понятно, что если у вас в предках были чисто калмыки, то вы будете идеально лежать в своем калмыцком кластере. Но если в роду у вас намешено, то вы можете считаться, что называют, Admixture. И обычно с таким самый гемморой для алгоритма. Также, если в выборке не будет калмыков, а вы калмык, то вам калмыка не покажут, покажут кого-то другого, наиболее близкого.
Территориальная привязанность не определяется 100% происхождением. Если у вас указан Казахстан, то это не значит, что вас казахом назвали. В Казахстане живет много русских, и наверное среди них бОльший процент клиентов генотека, чем среди местных казахов.
Гаплогруппа - это не значит, что вы негр. Известно, что люди вышли из Африки, это та кучка, которая разошлась по миру и наплодила потомков, и несла как раз гаплогруппы, которых вполне ограниченное количество. Т.е. если вы начнете идти по предкам далеко назад, то в конце концов вы придете к одной из веток, исходящей из этой кучки: https://ru.wikipedia.org/wiki/Гаплогруппы
Но нужно понимать, что если именно ваш результат не совпал с ожиданиями, это не значит, там даже не старались. Все данные проходят одинаковый алгоритм, никто не придумывает с потолка результаты. В общем, чтобы правильно интерпретировать результаты, нужно хоть немного понимать тему.
Общий скептицизм мне понятен, но эта не та тема, на которую стоит гнать. Одна из самых больших генетических баз данных в мире - это UK Biobank, они собрали 500к человек, генотипировали, секвенировали и собрали огромную базу фенотипов по ним. И сейчас тысячи исследований были проведены и проводятся на этой базе, множество клинически значимых результатов. И знаете кто выигрывает от этого - британцы, так как все эти результаты релевантны именно для людей их происхождения. Я очень надеюсь, что в России тоже будет такая база когда-нибудь. У нас есть очень умные люди в науке, есть деньги, это не такие огромные суммы сравнительно, нужно только грамотное руководство, которое, в том числе, должно подогревать интерес людей. Генотек, хоть и коммерческая компания, но это не корпорация зла. В эти 9к реагентов на 7к, а то и больше.