
Кухонная этимология
7 постов



7 постов

8 постов
5 постов

6 постов
8 постов
11 постов
12 постов
11 постов
4 поста
4 поста
5 постов
6 постов
13 постов
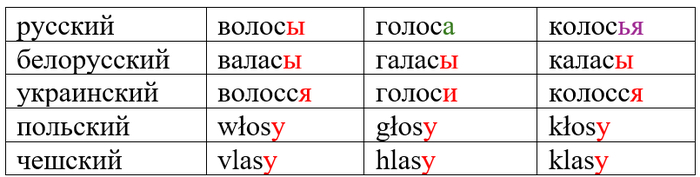
Недавно @Polyglot спросил меня, почему у слов колос, голос, волос так по-разному выглядят формы множественного числа – волосы, голоса́, колосья.
И действительно, в других восточнославянских, а также в западнославянских языках картина выглядит иначе (южнославянские – отдельная история):
Не было такого расхождения ни в древнерусском, предке восточнославянских языков, ни в праславянском, гипотетическом общем предке всех славянских языков.
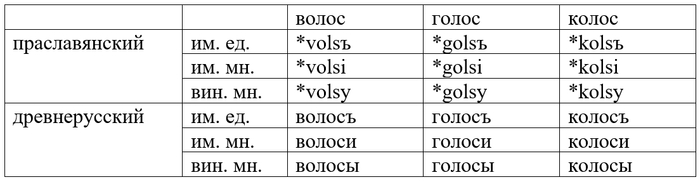
Теперь давайте проследим путь от древнерусских форм к современным. Важным изменением, начавшимся не позднее XII века было слияние форм именительного и винительного падежей существительных мужского рода с основой на твёрдый согласный. Изначально, как мы видим в таблице, разница была, но потом форма винительного падежа стала использоваться и в именительном падеже. Реликтами старого окончания именительного падежа множественного числа -и являются соседи и черти.
Ещё одно изменение – это экспансия окончания -ья. Это достаточно древний формант (суффикс + окончание) с собирательным значением. Например, в древнегреческом φρατρία «фратрия» при φράτηρ «член фратрии». Эти греческие слова, кстати, прямые родственники наших братья и брат.
В древнерусском изначально формой множественного числа от братъ было брати (затем браты), в то время как братья было собирательным обозначением, примерно как «братство», и согласовывалось по единственному числу.
И бѣша три браты, единому имя Кии, другому Щекъ, третиему Хоривъ, а сестра их Лыбедь. [Новгородская Карамзинская летопись. Первая выборка (первая половина XV в.)]
Однако со временем эта система несколько упрощается. Форма братья теряет значение собирательности и начинает восприниматься уже как просто множественное число от братъ, и согласовываться по множественному числу. Иногда можно найти забавные гибриды, как, например, в «Слове о полку Игореве»: Поидем на Киевьскую сторону, где суть (мн.ч.) избита (ед.ч.) братья наша (ед.ч.).
Таким образом, мы переходим от состояния
братъ «брат» : брати (> браты) «братья» : братья «братство» : братьѣ «братства»
к
братъ «брат» : братья «братья»
В новом соотношении -ья уже переосмысляется не как суффикс собирательного существительного, а как просто окончание множественного числа.
Это окончание начинает проникать и в другие существительные, обозначающие мужчин: князья, шурья, деверья, дядья, зятья, мужья, друзья. Соотношение сынъ : сынове сменяет новое сынъ : сыновья, которое тоже было переосмыслено (а точнее переразложено), и как отдельное окончание выделяется уже -овья, что в свою очередь порождает такие формы как кумовья и сватовья.
Однако вынесенные в заглавия поста колосья объясняются несколько иначе. От неодушевлённых существительных в древнерусском образовывались собирательные существительные при помощи форманта -ье. В какой-то мере он представлен и сейчас, например, тряпка – тряпки – тряпьё. При этом, во-первых, в современный литературный русский вошли не все формы, известные нам из памятников, как, например, гвоздье, кирпичье, кнутье, лубье. Во-вторых, с XV века такие собирательные формы начинают образовываться и от одушевлённых существительных, ср. бабьё, вороньё, дурачьё, зверьё.
Первоначально у таких собирательных числительных были возможны формы множественного числа (каменье – каменья), правда использовались они сравнительно редко. Но с того же XV века картина меняется, и, как и в случае с братьями, первоначальное соотношение колосъ : колоси (> колосы) : колосье : колосья упрощается, и у ряда слов множественное число собирательной формы вытесняет старую форму именительного множественного, что приводит к современному соотношению колос : колосья.
Конечно, всё это происходило не одномоментно, и для ряда слов можно проследить конкуренцию форм. Так, Ломоносов в своей «Российской грамматике» писал, что от лист бывает как листья, так и листы, а от пень – как пенья, так и пни. В итоге, как известно, победили соотношения лист : листья, но пень : пни. Правда, если речь о листе бумаги, то мы говорим не листья, но листы. Аналогичным образом размежевались зубы и зубья, корни и коренья.
Проиграли борьбу не только пенья, но и некоторые другие формы на -ья, например, бревенья, желобья, кусья, стебелья, трупья и волосья. Последнее хорошо известно в диалектах, но иногда ему удавалось пробиться и в литературу:
"Эге-ге-ге! " ― сказал Ярослав Ильич, показывая в тюфяке одно худое место, из которого торчали волосья и хлопья. [Ф. М. Достоевский. Господин Прохарчин (1846)]
В ряде случаев конкуренция жива и в современном языке. Так, в ходу как лоскуты, так и лоскутья, как суки́, так и сучья, как крюки, так и крючья.
Если присмотреться к существительным на -ья, то видно, что они образуют лишь несколько семантических групп. Это части дерева (сучья, прутья, листья), изделия из дерева (брусья, колья, клинья, ободья, полозья, стулья), изделия не обязательно из дерева (крючья, зубья, поводья), мелкие, чаще всего неприятные, вещи (клочья, лоскутья, лохмотья, комья, струпья) и немного сельского хозяйства (колосья; гроздья – только во мн.ч.). В среднем роде то же самое (деревья, поленья, донья, помелья, звенья, коленья, шилья), но плюс перья и крылья.
Таким образом, колосья и князья пришли к почти идентичному результату схожими, но несколько отличающимися путями. При этом важное отличие неодушевлённых существительных на -ья от аналогичных одушевлённых в современном русском заключается в ударении: у неодушевлённых оно всегда на основе, а у одушевлённых на окончании (кроме слова братья).
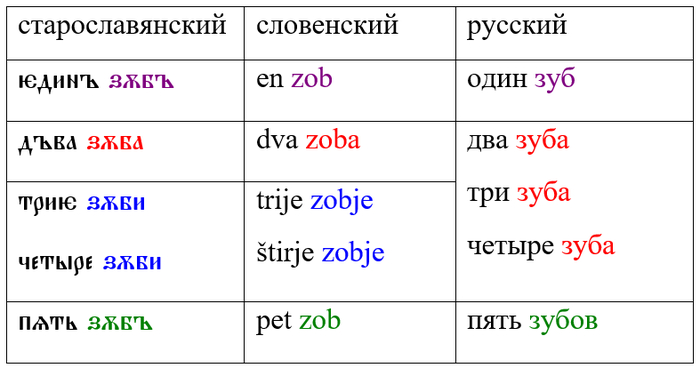
Теперь перейдём к окончанию -а. Здесь следует начать с того, что в древнерусском было не два числа, а три – единственное, множественное и двойственное. То есть, противопоставлялись не зуб – зубы, как сейчас, а зубъ – зуба (2) – зуби (> зубы). Постепенно двойственное число было утрачено, однако небесследно. Его окончание именительного падежа -а долго сохранялось у обозначений парных предметов – бока, глаза, рога, рукава. Кроме того, -а сохранилось в сочетании с числительным два, причём в XVI–XVII веках оно даже расширило сферу своего употребления на числительные три и четыре и превратилось в показатель особой счётной формы. Эту особенность русского хорошо видно при сравнении со старославянским и словенским, в которых есть двойственное число:
Появление счётной формы, совпадение с окончанием им.мн. среднего рода (места), а также экспансия окончаний дат.мн. -амъ, твор.мн. -ами, местн.мн. -ахъ, с которыми -а в именительном и винительном множественного отлично гармонирует, поспособствовали тому, что постепенно это -а начинает распространяться всё шире и шире. В XVII веке к обозначениям парных предметов добавились города, колокола, леса, луга, мастера, моста, месяца, образа, перста, струга, суда и тагана. В XVIII веке таких существительных стало несколько десятков, а в наше время уже несколько сотен, и это число растёт. Не все из них одобряются литературной нормой, но, скажем, даже у классиков можно найти форму волоса́:
Волоса, зачесанные сзади наперед, предполагают в женщине желание нравиться не только спереди, но и сзади. [А. П. Чехов. Руководство для желающих жениться (1885)]
В разговорном языке сильна тенденция к экспансии окончания -а, особенно в среде, где то или иное слово обыденно и часто употребимо, отсюда такие формы как шлема́, крема́, текста́ и т. д.
Краткое резюме:
Колосья вместо колосы – результат распространения собирательного -ья, а голоса́ вместо голосы – следствие распространения старого окончания именительного и винительного падежей двойственного числа.
Основной источник:
Число // Историческая грамматика русского языка / под ред. В.Б. Крысько. М.: Азбуковник, 2020.
Слово «правильно» в заглавии я неслучайно взял в кавычки. Правильно – это то, как отражено в орфографических словарях, составленных специально обученными людьми. Если там стоит «балабол», то так и правильно.
Но как специально обученные люди определяют, что в словарь надо внести «балабол», а не «болобол»? Если предельно упрощать, то принципов русской орфографии три – морфологический, фонетический и традиционный. Оговорю, что соблюдаются они непоследовательно, а иногда и напрямую противоречат друг другу.
Морфологический гласит, что желательно соблюдать графическое единство морфемы вне зависимости от того, как она меняется фонетически. То есть, мы пишем вода, а не вада, потому что есть форма воду. Лавка, а не лафка, потому что есть форма лавок.
Фонетический принцип применяется к ряду приставок: в соответствии с произношением пишутся приставки рас-/раз-, бес-/без-, воз-/вос- (но не в- или с-).
Наконец, традиционный принцип велит писать ту или иную букву в соответствии с происхождением слова. Например, почему мы пишем морковь, а не марковь? Колдун, а не калдун? Колено, а не калено? Ведь никакого «проверочного слова» здесь подобрать не получится. Потому, что в древнерусском языке до появления аканья эти слова произносились через -о-.
К «балаболу» тоже нет проверочного слова. Как определить, какое написание является более верным в соответствии с традиционным принципом: балабол, балобол, болабол или болобол?
В своих постах я неоднократно рассказывал о таком явлении, как метатеза плавных. Упрощённо говоря, выглядело это следующим образом: праславянская группа CoRC (где C – любой согласный, а R – r или l) отразилась в чешском, словацком и южнославянских языках как CRaC, в польском как CRoC, а в русском как CoRoC. Перед гласным группа oR никак не изменялась.
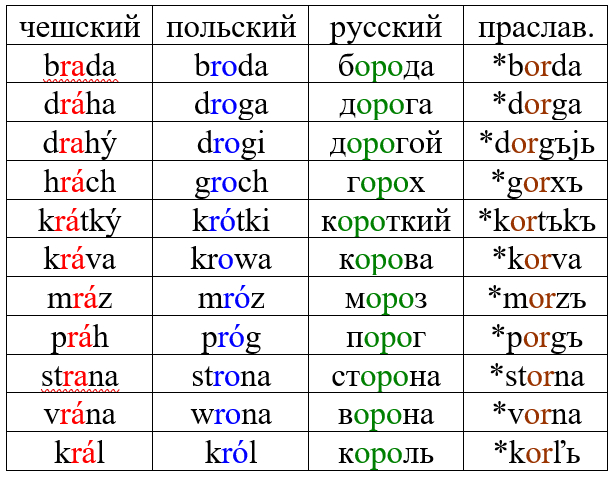
Комментарий: праславянские ъ и ь – гласные звуки типа у и и; x = х, j = й.
А ещё в праславянском языке можно было найти редупликацию (удвоение слова или его части), особенно в звукоподражаниях. Например, такая форма как *kolkolъ закономерно дала русское колокол и церковнославянское клаколъ. Аналогичное по структуре *golgolъ дало церковнославянское глаголъ, в русском ожидалась бы форма *гологол, отсюда мы знаем, что глагол – церковнославянское заимствование в русском, так же как глава, злато, глас, власть при исконных голова, золото, голос и волость. В свою очередь, *porporъ дало древнерусское поропоръ «знамя» (и такая форма засвидетельствована в памятниках), а прапор, от которого образовано слово прапорщик, – церковнославянизм. Глагол хорохориться восходит к редуплицированному *xorxoriti sę.
Но вернёмся к балаболу. Поскольку в чешском есть слово blábol «пустая болтовня, бред», то становится ясно, что это тоже редупликация, *bolbolъ, которая отразилась в русском с «полногласием» – болобол. Соответственно, согласно традиционному принципу, именно так это слово и следовало бы писать, через -оло-. Но поскольку к тому моменту, когда русская орфография кодифицировалась (систематизировалась в грамматиках и словарях), это уже не было очевидно, то слово болобол закрепилось в виде балабол – в соответствии с акающим произношением, а не происхождением. Абсолютно то же самое мы наблюдаем в случае глагола тараторить, который тоже восходит к редуплицированному *tortoriti, и должен бы писаться как тороторить.
Это не уникальные случаи. Например, исторически правильнее было бы писать колач, а не калач (это родственник колеса), корокатица, а не каракатица (это родственник окорока), пором, а не паром (ср. чешское prám и польское prom).
Но, конечно, хотя мы и знаем, что с этимологической точки зрения эти написания ошибочны, они были кодифицированы, и менять их уже никто не будет. Если же вдруг кто-то вздумает восстановить историческую справедливость собственными силами и начать писать болобол, тороторить, колач, корокатица и пором, летучие отряды граммар-наци быстро объяснят ему, что он безграмотный и не знает русского языка.
Краткое резюме
Этимологически правильно было бы писать болобол и тороторить, это редуплицированные звукоподражательные образования (*bolbolъ и *tortoriti), но в своё время специально обученные люди, занимающиеся кодификацией орфографии, были обучены недостаточно хорошо, так что эти слова мы пишем в соответствии с произношением, а не происхождением. А теперь, когда специально обученные люди обучены лучше, мы об ошибке знаем, но исправлять её уже поздно: все привыкли именно к такому написанию.
Задавались ли вы когда-нибудь вопросом, почему мы пишем помощник, а говорим /помошник/?
Начать следует с того, что праславянский звук *ť /ть/ по-разному отразился в славянских языках:
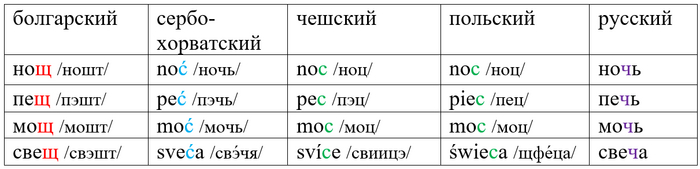
При этом в русском наряду с мочь (существительное, а не глагол, как, например, во всю мочь) есть и мощь. Наряду с помо́чь есть и по́мощь. Наряду с ночь – всенощный. Это яркий маркер церковнославянизмов. Церковнославянская книжная культура пришла к нам из Болгарии, так что неудивительно, что по-церковнославянски будет нощь, пещь, мощь и свѣща. Церковнославянское щ /шт/ на Руси читали по-своему, как /шч/, впоследствии – /щ/.
Правило можно сформулировать следующим образом: если в русском слове, у которого есть болгарский родственник с -щ- и/или сербохорватский с -ć- и/или польский/чешский с -c-, мы находим -ч-, то это слово исконное. Если в таком слове мы находим -щ-, то это церковнославянское заимствование.
Получается, что ночь, мочь, помочь – исконные слова, а всенощный, мощь и помощь – заимствования. Теперь давайте посмотрим на помощника:

Становится ясно, что помощник – такой же церковнославянизм, как и помощь. Точнее, был бы таким же, если бы произносился так же, как писался.
Исходя из таблицы, мы бы ожидали, что по-русски должно быть помочник. И такая форма действительно присутствует в памятниках:
А нашимъ царскимъ воеводамъ и всякимъ приказнымъ людемъ и инымъ всякимъ, хто имяня ни буди, того нашего отамана Керстонъ Родо и его товарищи и помочники въ наши пристанищи, гдѣ ни буди, на морѣ и на земли, въ береженьѣ и чести держати, запасу или что имъ надобе безъ зацѣпки, какъ торгъ подыметъ, продати и не обидити. [Царская жалованная грамота корабленику (корсару) Керстеню Роде, предоставляющая ему действовать на море против польского короля, его подданных, пособников и друзей, с тем чтобы в пользу царя поступал третий корабль и лучшая пушка с каждого из других захваченных Керстенем Роде судов (1570.03.30)]
Кроме того, формы с -ч- обнаруживаются в других восточнославянских языках: памочнік в белорусском, помічник в украинском.
И здесь нужно вспомнить об одном фонетическом изменении, охватившем только часть русских говоров, а именно о переходе -чн- > -шн-. В литературное русское произношение -шн- проникло в случае лишь нескольких слов (конечно, нарочно, скучно, яичница и т.д.), однако в ряде говоров распространено гораздо шире (молошный, мушной, коришневый и т.д.). В говорах с этим переходом слово помочник, естественно, стало звучать как /помошник/. Именно так, как мы его и произносим в современном литературном русском.
Таким образом, расхождение написания и произношения слова помощник обусловлено тем, что пишем мы его по-церковнославянски, а произносим по-русски (причем с переходом -чн- > -шн-).
Сегодня поговорим о случае, когда «учёные скрывают» — это не фигура речи, а факт.
Словарь Макса Фасмера, напечатанный в 1953–1958 гг. по-немецки, по сей день остаётся этимологическим словарём русского языка №1. Почти сразу после выхода словарь по достоинству оценили советские учёные, и было принято решение перевести его на русский. Переводчиком стал молодой и очень талантливый этимолог Олег Николаевич Трубачёв, в дальнейшем прославившийся амбициозным проектом «Этимологический словарь славянских языков». Учёные чаще пользуются русским переводом, а не немецким оригиналом в том числе потому, что Трубачёв снабдил текст Фасмера важными дополнениями и комментариями. Однако несколько словарных статей редакторы из перевода вычеркнули, о чём, впрочем, сообщается в предисловии.
Давайте же восстановим историческую справедливость. Первое пропущенное слово:
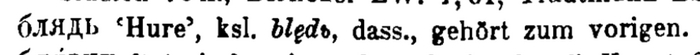
Перевод:
блядь ‘шлюха’, церковнославянское блѧдь ‘то же’, относится к предыдущему.
Предыдущей является словарная статья о глаголе блясти, которую цензура не вычеркнула. Подробнее историю этих слов см. в отдельном посте.

Второе пропущенное слово (о котором я тоже уже писал подробнее):

Перевод (ошибки автора не исправляю):
еба́ть, ебу́ ‘futuere’, в инфинитиве также еть, ети (из *jeb-ti), украинское єбу́, єба́ти, є́ти, болгарское еба́ (Младенов 158), сербохорватское jèbēm, jèbati, словенское jȇbam, jébati, древнечешское jebu, чешское jebi, jebati, польское jebać, верхнелужицкое jebać ‘обманывать’, нижнелужицкое jebaś ‘обманывать’. || Родственно древнеиндийскому yábhati, греческому οἰφέω, οἰφάω, οἴφω, см. Uhlenbeck Aind. Wb. 235, Berneker EW. 1, 452, Meillet-Vaillant 216. Ненадёжно связывать с фракийским ἕβρος ‘племенной козёл’ и ‘река во Фракии’ у Гесихия (см. Fick KZ. 42, 83 и далее). Ругательство ёб тв. м., возможно, означало первоначально «я твой отец», а затем «я бы мог быть твоим отцом» и подчёркивало неопытность и молодость оскорбляемого (согласно Зеленину, Табу 2, 18 и далее). Однако ср. также схожее ругательство в новогреческом.

Предположение Зеленина, думаю, вряд ли стоит рассматривать всерьёз:) Переходим к третьему и четвёртому словам:

пизда́, украинское пизда́, болгарское диалектное пи́зда, чакавское pīzdȁ, словенское pízda, чешское pizda, польское pizda, нижнелужицкое pizda, полабское péizda ‘ягодицы’. || Родственно древнепрусскому peisda ‘ягодицы’, албанскому piθ, определённая форма piδi ‘женские половые органы’, см. G. Meyer Alb. Wb. 336, Jokl IF. 30, 198 и далее, Trautmann BSl. 211, Rozwadowski IF. 5, 353 и далее, Walde-Hofmann 2, 273. Прочие сопоставления ненадёжны: древнеиндийское pīdáyati ‘он давит, угнетает, мучит’, греческое πιέζω ‘я давлю’ (Rozwadowski c.l., Pedersen KZ. 38, 418, Uhlenbeck Aind. Wb. 167 и далее). Менее убедительны сравнения с польским гидронимом Pisia, сербохорватским pìšati ‘mingere’, нововерхненемецким pissen (Brückner KZ. 45, 52, Zeitschr. 6, 302, IFAnz. 26, 44, Machek Mnema, Zubatý, 418) или с древнеиндийским pásas ‘membrum virile’, греческим πέος ‘мужской половой член’, латинским penis или литовским pisù, pìsti ‘coire’ (см. Prusík KZ. 35, 600 и далее), см. пиха́ть. Из славянских языков заимствованы литовское pyzdà, латышское pīzda (см. M-Endz. 3, 236).
пизделя́пнуть ‘сильно ударить’, тамбовское (РФВ. 68, 402). К ля́пнуть. Первая часть, может быть, связана с предыдущим словом?
И наконец последнее (и о нём я уже писал):

ху́й, род.п. хуя́ ‘membrum virile’. Сопоставляется со словом хвоя́ с другим аблаутом и сравнивается с литовским skujà ‘ёлочная иголка’, латышским skuja ‘еловая ветка’, возможно, также с албанским hu ‘кол, membrum virile’, определённая форма гегская – huni, тоскская huru, см. Pedersen Jagić-Festschr. 218 и далее, Berneker EW. 1, 408, Barić Alb. Stud. 1, 29. Lehmann KZ. 41, 394, Ильинский ИОРЯС, 20, 3, 103. Против этого без достаточных оснований Uhlenbeck IF. 17, 96, Petersson KZ, 46, 145.
Как видите, иногда учёные действительно скрывают от широкой публики важные научные открытия.
Сегодня мы поговорим о таком замечательном ложном друге переводчика как сербохорватское и словенское ponos /по́нос/ «гордость». Как так вышло, что слово, столь похожее на наш русский понос, имеет совершенное иное значение?

Дело в том, что слово понос образовано от глагола понести(сь), а глагол этот многозначен даже в русском литературном языке, а если привлечь данные письменных памятников, говоров и других славянских языков, то окажется, что спектр его значений крайне широк. Так, «Словарь русских народных говоров» (том 29, стр. 268–270) отмечает у слова понос целых 20 значений, более или менее очевидно связанных с ношением.
Угадаете, какое из них реализовано в следующем контексте?
Понос такой, братцы, что паруса не удержать.
Правильно, здесь понос – этот попутный ветер, который несёт судно.
А тут?
Надо грузило потяжелее, велик понос стоит.
Конечно, в этом случае понос – течение, несущая(ся) вода.
Или здесь:
Поносы начинают дарить за третьим блюдом – за горячим.
Это свадебный дар. В общем-то, от того же корня, но с другой приставкой, образовано слово подношение.
Ну и последний пример:
Захотелось на поносе мне мяса лебединого.
Здесь понос – беременность. Тут тоже несложно подобрать однокоренные: вынашивать, быть на сносях и собственно понести («А царица молодая, дела вдаль не отлагая, с первой ночи понесла»).
Откуда же взялось у слова понос значение «диарея»? Думаю, это достаточно очевидный случай, достаточно вспомнить однокоренной глагол пронести, тоже, кстати, многозначный, на чём строится известный анекдот:
Штирлиц шел по коридору генерального штаба. Мимо пробежал Мюллер. "Пронесло", – подумал Штирлиц. "Тебя бы так пронесло!" – подумал Мюллер.
Кстати, в русских памятниках и говорах слово пронос вполне известно в значении «понос». То же и в украинском литературном.
Теперь перейдём к значению «гордость». На самом деле оно не ограничивается сербохорватским и словенским. В русском произведении XVII века «Сказание о явлении чудотворного креста господня, что в Муромском уезде на реке на Унже» глагол поноситися явно употреблён в значении «гордиться»:
Иоаннъ поносяся богатствомъ, а Логинъ хваляся отчествомъ.
То же мы находим в более позднее время и в говорах:
Что ж ты, Васенька, поносишься собой?
Появление этого значения вполне объяснимо в свете однокоренного прилагательного заносчивый. Просто, в отличие от сербохорватского и словенского, оно не попало в русский литературный язык, и теперь такой замечательный ложный друг переводчика как ponos нас забавляет. Впрочем, работает это в обе стороны. Так, словенское grd, родственник нашего слова гордый значит «некрасивый, уродливый».
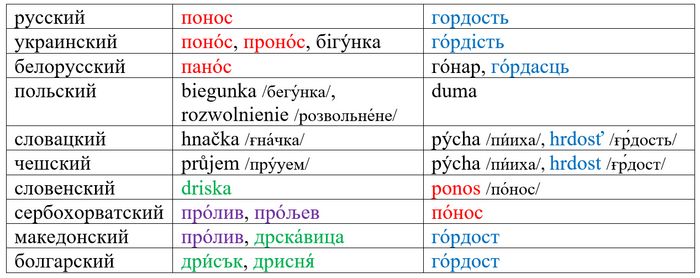
Ну и напоследок исключительно в развлекательных целях приведу список основных обозначений поноса и гордости в славянских языках.
Довольно очевидно, что мы пользуемся десятичной системой счисления в связи с древней манерой считать на пальцах рук. Весьма вероятно, что счёту на пальцах обязана своим появлением и шестидесятеричная система, которую мы применяем при счёте времени (большой палец одной руки считает фаланги остальных пальцев той же руки, а пальцы другой руки отсчитывают дюжины).
Однако существовали и более сложные системы. Древние римляне умели считать на пальцах сотни и, вероятно, тысячи, на что указывают некоторые места из античных произведений. Но подробного античного описания этой системы не сохранилось. Первая дошедшая до нас инструкция по такому счёту на пальцах принадлежит перу английского монаха Бе́ды Достопочтенного (672/673–735).
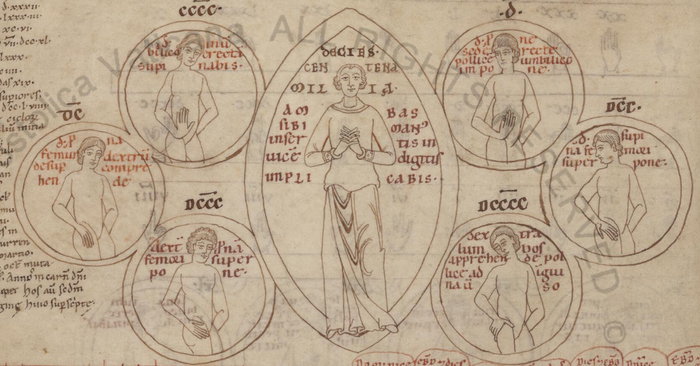
В трактате «О счёте времён» (De temporum ratione) Беда даёт подробное описание такой системы. Более того, сохранились иллюстрированные рукописи, которые позволяют очень хорошо себе её представить. Далее я даю иллюстрации по рукописи Urb.lat.290 из Ватиканской апостольской библиотеки (лист 31).
Итак, единицы предлагается отсчитывать на мизинце, безымянном и среднем пальцах левой руки (на иллюстрации рука повёрнута ладонью к считающему). Для 1–6 пальцы предлагается ставить на середину ладони, а для 7–9 ближе к её верху.

Десятки следует показывать путём различных комбинаций указательного и большого пальцев левой же руки.

Сотни показываются аналогично десяткам, но на правой руке:

Тысячи аналогично единицам, но на правой руке:

Таким образом на пальцах обеих рук можно показать числа от 1 до 9999. Некоторые положения пальцев, конечно, довольно причудливы и требуют определённой сноровки.
Однако Беда решил не ограничивать себя столь малым числом и предложил несколько дополнительных жестов для бóльших чисел. Тут уже просто пальцев не хватило и пришлось задействовать тело.
Жесты для 10 000–40 000 предполагается показывать ладонью левой руки на груди:

Для 50 000–90 000 переходим к животу и бёдрам.

Для 100 000–900 000 используются те же жесты, но правой рукой. Наконец миллион показывается сплетёнными пальцами обеих рук.
Где предполагалось использование такой сложной пальцевой системы? В первую очередь в вычислениях. Дело в том, что Европа на момент написания трактата Беды пользовалась непозиционной системой – римскими цифрами, с которыми арифметические действия в столбик осуществлять куда сложнее, чем с привычными нам арабскими. Система Беды уже частично является позиционной, кроме того, она помогает осуществлять вычисления в уме.
Вторая область применения, описанная самим Бедой, – секретный жестовый язык. Каждой букве присваивается номер в соответствии с алфавитным порядком (A – 1, B – 2, C – 3) и побуквенно можно показать любое слово на пальцах.
P.S. При вычислении не в уме, а с возможностью записи, римские цифры неплохо справляются со сложением (и чуть хуже с вычитанием). Например, нам нужно сложить XVIII и VII. Записываем все цифры этих чисел от больших к меньшим: XVVIIIII. Затем VV превращаются в X, а IIIII в V. Ответ – XXV. Если нужно вычесть VII из XVIII, зачёркиваем все цифры из VII в XVIII. Остаётся XI. Правда, конечно, при таких вычислениях 4 и 9 нужно записывать как IIII и VIIII, а не IV и IX.
P.P.S. На написание поста меня вдохновила книга Себа Фалька «Светлые века. Путешествие в мир средневековой науки», покупку которой мне проспонсировали пикабушники.
На первый взгляд, вопрос из заголовка звучит абсурдно, ведь обе буквы выглядят совершенно идентично. Однако транслит в адресной строке подсказывает: первая Х – кириллическая, а вторая X – латинская.

Мы знаем, что как кириллический, так и латинский алфавиты являются потомками греческого. Соответственно, наша буква Х (ха) и латинская X (икс) – это греческая Χ (хи) в практически неизменном начертании. Но если мы произносим эту букву так же, как греки – /х/, то откуда взялось латинское прочтение /кс/?
Чтобы понять это, следует начать с того, что греки позаимствовали свою письменность у финикийцев. В случае, когда финикийский и греческий звуки были идентичны, греки сохранили функцию буквы неизменной:
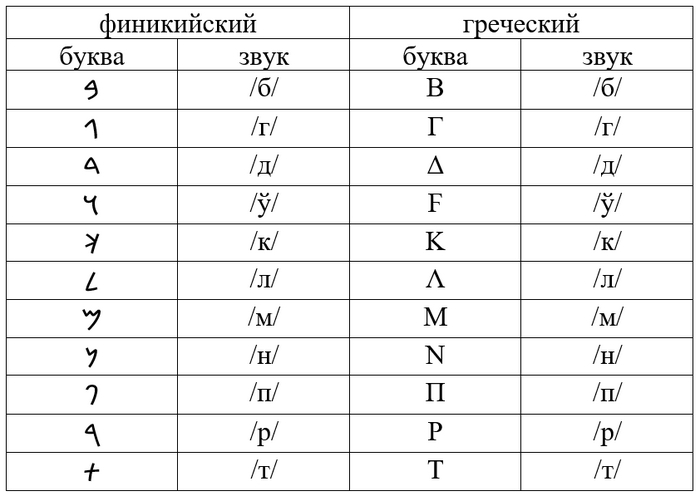
В финикийском алфавите были буквы только для согласных, так же, как и в родственных еврейской и арабской письменностях. Благодаря особой структуре семитских языков, читающий всё равно мог понять, о чём идёт речь. Для греческого языка такой принцип подходил плохо, слишком велика в нём была роль гласных. Зато в финикийском языке было куда больше согласных, чем в греческом, то есть, имелись «лишние» буквы, которым греки нашли применение.
В принципе, первый шаг сделали уже сами финикийцы: буквы йод и вав стали со временем использоваться для записи не только согласных /й/ и /ў/, но и долгих гласных /ии/ и /уу/. Греки взяли ещё четыре буквы, обозначавших согласные, которых не было в греческом и начали записывать ими гласные:

Комментарий к таблице: /’/ (В Международном фонетическом алфавите – ʔ) – это звук, который можно услышать между гласными в русском не-а; h – как в английском hat; /х/ и /‘/ в финикийском были глухим и звонким фарингальными (МФА /ħ/ и /ʕ/), то есть, произносились в гортани.
Ещё одну букву, Ω /оо/, греки создали на основе Ο. По какой-то причине придумывать отдельные буквы для долгих /аа/, /уу/ и /ии/ они не стали.
Кроме того, в финикийском были аффрикаты /ц/ и /дз/, которые отсутствовали в греческом. Греки могли буквы для этих звуков смело выкинуть или использовать для обозначения каких-то других звуков, но, по-видимому, /ц/ и /дз/ они воспринимали не как слитные звуки, а как сочетание двух, и идея записывать сочетание «согласный + с» им понравилась, так что они сохранили финикийские буквы и нашли применение для них, обозначая одной буквой сочетания /зд/ и /кс/, которые аффрикатами не являются. Более того, придумали новую букву для /пс/, но об этом ниже.
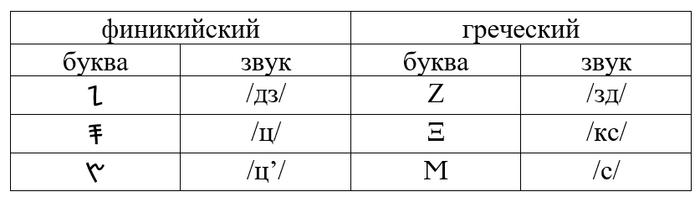
Комментарий к таблице: знак ’ здесь и ниже обозначает фарингализацию.
Некоторые другие финикийские буквы тоже получили в греческом новую функцию:

Как я рассказывал раньше, в греческом было три придыхательных согласных: /пˣ/, /тˣ/, /кˣ/. И только один из них, /тˣ/, сразу получил свою финикийскую букву. Для /пˣ/ греки придумали букву Φ, вероятно на основе лишней коппы (Ϙ), которая в греческом быстро вышла из употребления (но зато дала латинскую Q).
Сложнее была история /кˣ/. Греки придумали две новых буквы, Χ и Ψ, но использовали их по-разному в зависимости от региона. На западе Χ читалась как /кс/, а Ψ – /кˣ/. На востоке иначе: Χ – /кˣ/, а Ψ – /пс/.
Ещё в XIX веке немецкий учёный А. Кирхгоф выделил четыре группы вариантов древнегреческой письменности:
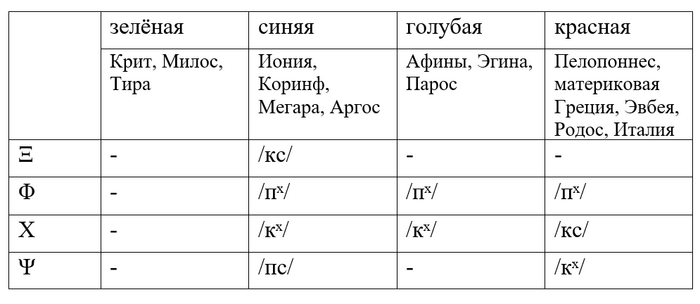
На карте:
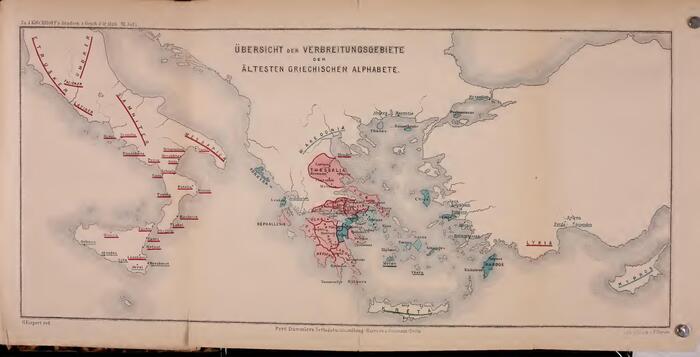
«Синий» вариант используется в современном греческом с поправкой на то, что /пˣ/ и /кˣ/ стали со временем произноситься как /ф/ и /х/. Когда славяне заимствовали греческий алфавит, буква Χ читалась уже как /х/, поэтому наша Х произносится именно так. А вот римляне заимствовали свой алфавит из греческого в «красном» варианте. По этой причине латинская буква X читалась как /кс/, но, как я уже писал раньше, благодаря забавному выверту исторической фонетики, в современном испанском это /х/, как в русском.
Литература:
Kirchhoff A. Studien zur Geschichte des griechischen Alphabets. Berlin, 1877.
Matthaiou A.P. Local Scripts // Encyclopedia of Ancient Greek Language and Linguistics. Vol. 2. Leiden, Boston, 2014. Pp. 379–385.
Swift N. The Origin of the Greek Alphabet // Encyclopedia of Ancient Greek Language and Linguistics. Vol. 1. Leiden, Boston, 2014. Pp. 94–100.
В 1902 году немецкий учёный Фридрих Делич опубликовал работу «Babel und Bibel», посвящённую заимствованию некоторых библейских мифов из вавилонских сказаний. Несложно заметить, что в русском переводе, «Вавилон и Библия», часть созвучия теряется. Почему же в некоторых русских словах мы находим -в- там, где в западноевропейских языках - -б-? Особенно хорошо это заметно в именах греческого или библейского происхождения:

Как и в случае с колебанием -т- / -ф-, о котором я писал раньше, дело в том, каким путём эти слова попали к нам из греческого.
В классическом древнегреческом была следующая система взрывных согласных:
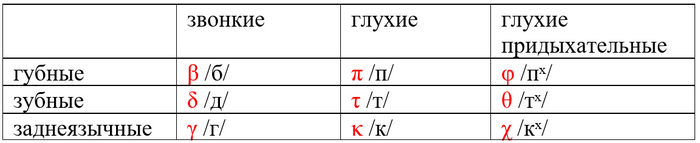
Взрывные (смычные) – это такие согласные, при произнесении которых органы речи смыкаются, а потом резко размыкаются. В противоположность им спиранты (фрикативные) произносятся без смычки, между органами речи остаётся пространство. Разницу легко почувствовать, если произнести /к/ (взрывной) и /х/ (фрикативный).
Как я уже рассказывал, в начале нашей эры греческие придыхательные перешли в спиранты: φ стал произноситься как ф, θ как первый звук в английском thin, а χ как х. Звонкие согласные изменялись параллельным образом: β из /б/ превратился в /в/, δ стал звучать как /ҙ/ (первый звук в английском the), а γ – как южнорусском произношении слова город.
Такой переход (спирантизация) – одно из самых распространённых фонетических изменений в языках мира. Это неудивительно, ведь для него достаточно лишь начать менее «тщательно» произносить взрывные согласные.
Но вернёмся к греческому. После спирантизации греческая система согласных сильно изменилась, а написание осталось, как правило, прежним:
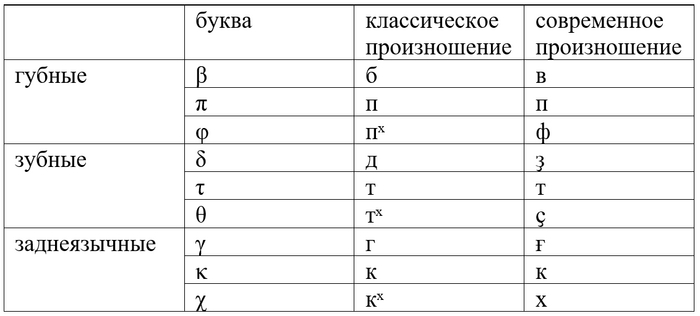
Какое-то время греки жили без звонких взрывных согласных (б, д, г), но в Средневековье обзавелись новыми, поскольку глухие п, т, к озвончились после носовых (м, н). Например, πέντε «пять» стало произноситься не как /пэ́нтэ/, а как /пэ́ндэ/, λάμπω «я сверкаю» не как /ла́мпо/, а как /ла́мбо/. Написание, опять же, осталось прежним. Вторым источником звонких стали заимствования, причём для их записи в современном греческом используются диграфы μπ, ντ, γκ: μπαλέτο /бале́то/ «балет», ντάμα /да́ма/ «дама», γκαράζ /гара́з/ «гараж».
А вот так по-гречески пишется Бобруйск:
Осуществлялся процесс спирантизации, по-видимому, долго и неравномерно. Первые признаки можно найти уже в некоторых текстах VI–V веков до н.э., когда, например, вместо ῥάβδους (вин.п. мн.ч.) «палки» мы находим написание ῥάυδους и так далее. Однако повсеместным спирантное произношение становится только примерно к IV веку н.э.
Когда римляне завоевали греческие колонии в Италии, а затем и саму Грецию, они были пленены греческой культурой и заимствовали в латынь уйму слов. При этом греческие β, δ, γ передавались как b, d, g: βούβαλος > bubalus «буйвол», διάλογος > dialogus «беседа».
Славяне же стали массово заимствовать из греческого значительно позже, особенно активно после принятия христианства (крещение Болгарии – 864 г., крещение Руси – 988 г.). К тому времени греки уже произносили β, δ, γ как спиранты. Неудивительно, что при освоении греческого алфавита славяне использовали букву Β для передачи звука /в/, а вот для /б/ пришлось придумывать особое решение – путём «разгибания» верхней дужки В была получена новая буква, Б. Соответственно греческое β передавалось как в, поэтому Βαβυλών стал у нас Вавилоном, а не Бабилоном. Для греческих δ и γ точных эквивалентов не было, поэтому они передавались взрывными /д/ и /г/.
В эпоху Возрождения в Европе интерес к Античности и греческому языку резко вырос, а его изучение облегчилось благодаря турецкому завоеванию Византии, которое привело к бегству многих книжников в западноевропейские страны. Эти книжники привезли с собой рукописи, а также современное им греческое произношение. Те филологи, которые учились непосредственно у них, также читали античные тексты с произношением XV века. Самым известным из таковых филологов был немец Иоганн Рейхлин (1455–1522), который в письме папе Льву X хвастался: «я первым из всех вернул греческое в Германию».
С началом Реформации греческий стал важен и в религиозном плане. Протестанты хотели вернуться к истокам христианства, а Новый Завет был написан на греческом. Здесь на передний план выходит фигура Эразма Роттердамского (1466–1536), который полагал что при чтении греческих текстов желательно стараться приблизиться к античному произношению. Надо сказать, что эразмово чтение несколько анахронично, оно не соответствует древнегреческой фонетике в полной мере. Однако именно эта система победила и является основной при обучении древнегреческому в университетах (за исключением самой Греции), а также при передаче грецизмов на современные европейские языки.
Коротко разницу между эразмовым и рейхлиновым произношениями в их русских вариантах можно описать следующим образом (Славятинская М.Н. Учебник древнегреческого языка. М., 2003. С. 31):

В Петровскую эпоху в русский язык стали активно проникать западноевропейские заимствования, многие из которых имели греческие корни. Греческий, конечно, передавался по-эразмовски. Это привело к появлению у нас дублетов – случаев, когда этимологически один греческий корень в одном русском слове произносится через -б-, а в другом – через -в-. Яркий пример – Аравия, но араб. Несложно догадаться, что первое слово мы взяли из греческого напрямую, а второе – через западноевропейское посредство. При этом ранее существовало и слово арав, а в XVIII веке можно найти и Арабию:
И егда того ради Ираклий посла на аравов воеводу своего с воинством, арави же и срацыни, избравши онаго Махомета воеводою, поразиша трижды римская воинства и изгнаша их из Сирии. [А. Лызлов. Скифская история (1692)]
Если же Рим столь долго оное пренебрегал, сколь долго упражнялся в пролитии крови, то хватился он за торг, как скоро отдохнул от сего упражнения: благополучная Арабия привлекала тогда к себе римских граждан. [Д. И. Фонвизин. Торгующее дворянство (1766)]
Аналогичным образом слово Вавилон пришло к нам непосредственно из греческого, а вот Библия – из западноевропейских языков, иначе мы бы говорили *Вивлия. И по той же причине у нас вместо вивлиофики теперь библиотека.

Оговорюсь, что Новиков выбрал для названия своей серии слово вивлиофика как нарочито архаичное: в XVIII веке общеупотребимым уже было современное библиотека.
Сие мудреное слово (которого выговорить я не могу, да и написать едва мог с великою трудностию) поставил я шутя и нарочно вам в угождение: ибо оное слово, сказывают, взято из глубокой древности и не знаю кем-то вытащено на свет; но ведаю то, что оно дерет уши, также что оно ни французское, ни русское; поставлено же оно вместо весьма употребительного во Франция и в России слова библиотека. Библиотеку все знают, а вивлиофики никто не разумеет. [Н. И. Новиков. Кошелек. Еженедельное сочинение 1774 года (1774)]
Литература:
Déniz A.A. Spirantization // Encyclopedia of Ancient Greek Language and Linguistics. Vol. 3. Leiden, Boston, 2014. Pp. 315–316.
Dillon M. Erasmian Pronunciation // Encyclopedia of Ancient Greek Language and Linguistics. Vol. 1. Leiden, Boston, 2014. Pp. 568–570.
Kazazis J., Chairopoulos P. History of Teaching of Ancient Greek in Germany // Encyclopedia of Ancient Greek Language and Linguistics. Vol. 2. Leiden, Boston, 2014. Pp. 162–174.
Краткое резюме: всё дело в том, что в греческом буква β первоначально обозначала звук /б/, который впоследствии перешёл в /в/. В заимствованиях из греческого напрямую в русский эта буква передавалась как -в-, а если посредником выступал один из западноевропейских языков, то как -б-.

