
Об их отношениях можно было сказать



Какие к друг другу отношения имеют эти фотографии?
Автор фотографий и фотограф - я. 📸
Показать полностью
3
Какие к друг другу отношения имеют эти фотографии?
Автор фотографий и фотограф - я. 📸
Обычно все знают самое базовое применение LIMIT - ограничение строк выдачи в запросе.
LIMIT 10 -> показать 10 строк
Но применение LIMIT не ограничивается только ограничением :-).
Есть интересные кейсы по использованию LIMIT в своих запросах.
Об этом чуть ниже.
А пока подписывайся на мой канал На связи: SQL Там я публикую посты про особенности и нюансы SQL. Этот канал про то, как не бояться баз данных, понимать, что такое JOIN, GROUP BY и почему NULL ≠ 0. Его я веду с нуля подписчиков. Присоединяйся!

И так, какие же кейсы есть с применением LIMIT
LIMIT + OFFSET
Многие помнят про LIMIT, но забывают про то, что можно еще применять сдвиг.
SELECT *
FROM users
ORDER BY id
LIMIT 10 OFFSET 20;
Этот запрос вернёт 10 строк, начиная с 21-й.
Такой прием применяется, например, в постраничной выдаче результатов запроса.
Но этот кейс имеет и минусы: OFFSET все равно просматривает первые 20 строк, чтобы добраться до нужных. При больших объемах OFFSET работает медленно.
LIMIT в UPDATE и DELETE
Да, да - в этих операторах тоже можно использовать LIMIT, не только в SELECT
DELETE FROM logs ORDER BY created_at ASC LIMIT 1000;
Так чистят таблицу порциями, чтобы не завалить базу огромным удалением.
LIMIT в подзапросах
Об этом часто помнят, т.к. подзапрос является запросом, а в запросах использование LIMIT - вполне привычное дело.
Найдем самый дорогой заказ:
SELECT *
FROM orders
WHERE id = (SELECT id FROM orders ORDER BY price DESC LIMIT 1);
Это иногда проще, чем возиться с MAX() и джойнами.
LIMIT vs FETCH … WITH TIES
В некоторых СУБД (например, SQL Server, Oracle) есть фича:
SELECT *
FROM products
ORDER BY price DESC
FETCH FIRST 3 ROWS WITH TIES;
Такой запрос вернёт не просто 3 строки, а все строки, у которых цена такая же, как у третьей записи.
(например, если на третьем месте несколько товаров с одинаковой ценой).
LIMIT показывает первые N строк после сортировки
А вот WITH TIES говорит: «Выдай все строки, которые наравне с последней по значению сортировки».
В других СУБД такой синтаксис можно реализовать через LIMIT + подзапрос с оконной функцией RANK()
LIMIT 0
Очень полезный трюк.
SELECT * FROM users LIMIT 0;
Вернёт пустую таблицу, но со всеми названиями и типами столбцов.
Это часто используют для генерации схемы в BI-инструментах или в тестах
LIMIT в CTE (PostgreSQL)
Можно ограничивать данные прямо на уровне общего табличного выражения (CTE), чтобы уменьшить нагрузку:
WITH top_orders AS (
SELECT * FROM orders ORDER BY price DESC LIMIT 100
)
SELECT * FROM top_orders WHERE customer_id = 42;
Так мы сначала берём только 100 дорогих заказов, а потом фильтруем по клиенту.
В итоге LIMIT — это не просто «дай 10 строк», а инструмент для оптимизации, постраничной навигации, аккуратных обновлений и даже для защиты от перегруза.
Подписывайся на мой ТГ канал На связи: SQL, чтобы узнавать/вспоминать еще больше нюансов SQL запросов.
ORDER BY — штука вроде бы простая («отсортируй строки»), но там есть много нюансов, про которые мы просто не помним или не пользуемся.
Вообще мы даже своими смартфонами не всегда (да, что уж - никогда) не пользуемся на полную мощность.
В своем канале На связи: SQL рассказываю про некоторые забытые нюансы языка SQL, особенности и необходимую теорию, чтобы любой начинающий мог свободно познакомиться с этим языком и применить его в дальнейшем для своих задач. Канал создан недавно, с 0 подписчиков, но уже активно наполняется контентом. Подписывайся!

Блок с ORDER BY предназначен для сортировки результата выборки.
По умолчанию сортировка ASC (по возрастанию). Можно явно писать:
ORDER BY age ASC -- от младших к старшим
ORDER BY age DESC -- от старших к младшим
2. Можно сортировать сразу по нескольким столбцам:
ORDER BY country, city
Сначала сортируются страны, внутри них — города.
3. Можно писать не имя, а номер колонки в SELECT:
SELECT name, age
FROM users
ORDER BY 2 DESC; -- сортируем по age
Но это считается «плохим тоном» — лучше явно указывать названия. Хотя мне очень нравится это использовать, особенно, когда в селекте не просто имя столбца, а вычисление.
4. NULL в ORDER BY требует особого внимание.
NULL в разных БД обрабатывается по-разному.
В PostgreSQL:
ASC → NULL идут в конце
DESC → NULL идут в начале
можно явно писать:
ORDER BY age ASC NULLS FIRST;
ORDER BY age DESC NULLS LAST;
В MySQL и SQL Server правила отличаются:
в MySQL NULL всегда считаются «меньше всего» (т.е. идут первыми в ASC).
в SQL Server можно управлять через ISNULL()/COALESCE().
В MySQL и SQL Server нельзя использовать NULLS FIRST или NULLS LAST при сортировке,
Для SQL Server используем:
ORDER BY ISNULL(age, 9999) ASC;
ORDER BY COALESCE(age, 9999) ASC;
Здесь NULL мы заменяем на большое число (9999), и оно уходит в конец сортировки по возрастанию.
А если хотим NULL в начало — ставим что-то маленькое, например -1.
Для MySQL есть поведение по умолчанию:
При ASC → NULL идут первые
При DESC → NULL идут последние
А если нужно наоборот, то делаем хитрость с IS NULL:
ORDER BY age IS NULL, age ASC;
Здесь age IS NULL вернёт 1 для NULL и 0 для обычных значений.
SQL сначала отсортирует по этому условию (0 → 1), а потом уже по age.
5. Можно сортировать не только по полям, но и по функциям.
ORDER BY LENGTH(name) DESC;
ORDER BY purchase_amount * discount;
6. Случайная сортировка - имеет место быть. Но очень "дорога" в использовании на больших объемах.
-- PostgreSQL / SQLite
ORDER BY RANDOM()-- MySQL
ORDER BY RAND()
Часто случайная сортировка используется при тестировании на небольших объемах.
- хотим показать пользователю случайный товар в магазине
- хотим проверить, как работает приложение, не завися от конкретного порядка записей
- рекомендательные системы: в выдачу добавляем случайный товар, чтобы не зацикливать пользователя только на "популярных" товарах.
- игры или викторины: рандомная выдача вопросов.
7. Есть еще такое понятие как COLLATION (сравнение строк).
ORDER BY учитывает локаль (collation). Поэтому, например, русские буквы могут сортироваться по-разному в разных СУБД:
А может идти перед а, или наоборот.
Можно явно указать сортировку:
ORDER BY name COLLATE "C" -- по байтовому значению
ORDER BY name COLLATE "ru_RU" -- по русскому алфавиту
Представь, что у тебя есть список имён:
['Елена', 'елена', 'Жанна', 'Анна']
Когда ты пишешь в SQL:
SELECT * FROM users ORDER BY name;
база должна решить:
считать ли «Елена» и «елена» одинаковыми?
что идёт раньше: «Ж» или «А»?
как сравнивать буквы с диакритикой: «é» vs «e»?
Вот именно на эти вопросы отвечает collation.
То есть COLLATION — это как правило сортировки в библиотеке: от него зависит, где именно окажется твоя книга.
То есть, ORDER BY — это не просто «отсортировать», а ещё и про то:
куда денутся NULL
как сортируются строки (с учётом локали)
можно ли сортировать по выражениям или случайно
В моем ТГ канале На связи: SQL я знакомлю новичков с языком SQL и хочу, чтобы те, кто желает познакомиться с анализом данных с легкостью шли в это направление. Присоединяйся!
Всем привет, имеется инфраструктура с множеством вм MSsql для 1С. Хотим перенести это все на 1 сервер или кластер серверов для удобства администрирования и обновления. Сначала думали использовать кластер Postgres + patroni + etcd но как я понял (а я человек очень далёкий от 1с, в компании занимаюсь только инфраструктурой и linux) 1С не умеет разделять куда отправлять запросы на чтение, а куда на запись, соответственно балансировать запросы в кластере master/slave не получиться.
У нас имеется кластер proxmox ceph с RBD для нужд виртуализации, впринципе HA можно обеспечить только нахождением вм на ceph, ответ на вопрос хватит ли нам одного инстанса postgres без балансировки мне пока не известен.
Подскажите у кого был опыт сколько пользователей 1С способен обслуживать 1 инстанс postgres ? Какие решения кластеризации master master вы прикручивали к 1С? Или лучше как вы организовывали шардирование базы для 1с? Есть ли польза от pgbouncer для 1С при использовании postgres?

Продолжаю тему разборов задач с собеседований по SQL. В этот раз выложу полное содержание, чтобы пост не удалили.
Итак, в базе данных есть таблица CLIENTS, содержащая три строки:

И есть таблица INVOICES, в которой две строки:
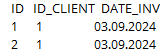
И сама задача звучит так: какое количество строк вернёт указанный ниже запрос:
SELECT * FROM CLIENTS WHERE EXISTS (SELECT COUNT(*) FROM INVOICES WHERE ID_CLIENT = CLIENTS.ID)
Какой бы вариант Вы выбрали?
Здесь нужно было заметить неправильное использование EXISTS.
Оператор EXISTS используют для проверки того, возвращается ли что-то подзапросом, указанным в скобках. Как правило, в скобках для оператора EXISTS/NOT EXISTS пишут:
SELECT *
или:
SELECT 1
В задаче выше нарочно допущена ошибка (в EXISTS нарочно написано SELECT COUNT).
SELECT COUNT всегда будет возвращать данные. Написанный в скобочках подзапрос всегда будет возвращать количество, хоть и иногда 0. Но данные-то есть. Ноль - это тоже данные. Поэтому EXISTS будет давать TRUE для каждой из трех строчек основного запроса.
Ещё больше интересных задач с собеседований я публикую в моем Телеграм-канале по SQL!
Здравствуй, уважаемый читатель!
Как насчёт очередной задачи с собеседования по SQL? Задача базового курса, поэтому поставил одну звезду уровня сложности из пяти.
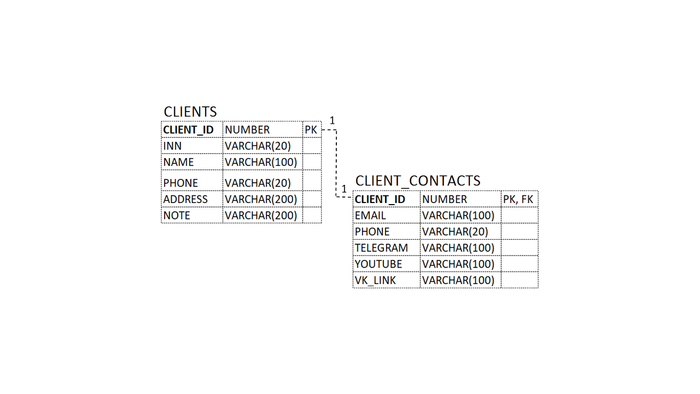
Дана схема данных (рисунок выше). Необходимо создать представление (VIEW) с названием CLIENTS_INFO, содержащее следующую информацию о клиентах: INN, NAME, PHONE.
Какая ошибка допущена в следующей SQL команде?
CREATE VIEW CLIENTS_INFO
AS SELECT INN, NAME, PHONE
FROM CLIENTS, CLIENT_CONTACTS
WHERE CLIENTS.CLIENT_ID = CLIENT_CONTACTS.CLIENT_ID

Посмотреть правильный ответ и найти еще больше интересных задач можно в моем Телеграм-канале.
Example Answer Structure
Question: What value will the following query return?
SELECT COUNT(*) FROM TMP_TABLE;
Answer:
To determine the result of the query SELECT COUNT(*) FROM TMP_TABLE;, we need to understand what the COUNT(*) function does in SQL. The COUNT(*) function counts the number of rows in a table, regardless of whether they contain NULL values or not.
Let's look at the data in the table TMP_TABLE:
column1column21212NULL131214NULLNULL1315
There are 5 rows in the table. The COUNT(*) function will count all these rows, including those with NULL values.
Therefore, the query:
SELECT COUNT(*) FROM TMP_TABLE;
will return the value 5.
This value is the total number of rows in the table TMP_TABLE, without any consideration of the content of the columns or whether they contain NULL values.
______
ChatGPT4o. Простите.

Здравствуй, уважаемый читатель! Спасибо, что заходишь ко мне на канал и изучаешь SQL со мной!
Недавно нашёл в интернете достаточно простую задачу с собеседования по SQL, в которой нужно было составить запрос к таблицам. Ссылку на источник размещу ниже. В своём Телеграм канале, где мы решаем разные задачи с собеседований и разбираем практические ситуации, я предложил всем поучаствовать в её решении. Надеюсь, тебе будет тоже интересно попробовать её решить. Ниже описание задачи.
В базе данных есть таблица анализов Analysis, имеющая следующие столбцы: an_id — ID анализа; an_name — название анализа; an_price — цена анализа; an_group — группа анализов. Есть, также, таблица заказов Orders: ord_id — ID заказа; ord_datetime — дата и время заказа; ord_an — ID анализа. Необходимо вывести название и цену для всех анализов, которые продавались 5 февраля 2020 и всю следующую неделю.
Тут сделай паузу и попробуй сначала сам решить задачу.
Итак, надеюсь, ты делал паузу и составил SQL-запрос. Далее будем решать вместе.
Напомню, что нужно было вывести список анализов и их цену, которые продавались 05.02.2022 и всю следующую неделю.
Первым решением напрашивается соединение таблицы анализов и таблицы продаж с применением условия на период. Кстати, именно это и указано в качестве ответа на задачу.
На самом деле, из-за того, что один анализ за выбираемый интервал времени мог быть продан сколько угодно раз (один и тот же анализ мог быть продан хоть тысячу раз и больше) заместо соединения таблицы анализов с таблицей заказов, я бы предложил использование EXISTS:
select a.an_name, a.an_cost from analysis a where exists (select 1 from orders where ord_an = a.an_id and ord_datetime between to_date('05.02.2022', 'dd.mm.yyyy') and to_date('05.02.2022', 'dd.mm.yyyy') + 7)
Благодаря тому, что мы не джоинили анализы с их заказами, в результирующей таблице анализы не замножатся по количеству присоединившихся к ним заказов. То есть в результате мы получим:
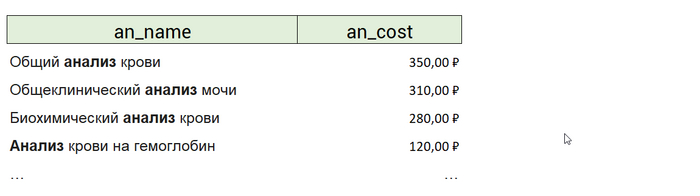
а не:
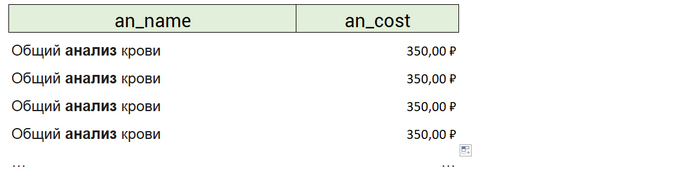
В примере, что я нашёл в интернете (ссылка ниже), помимо названий анализов и их стоимостей, выведен ещё и столбец с датами заказов. По условиям задачи вывод этого столбца не запрашивался. Не требовался вывод никакой информации о заказах/продажах. Поэтому и надобности в соединении я не усмотрел. Наоборот, это и потенциально замножит вывод анализов, которые покупали в запрашиваемый период, и прибавит лишнюю работу СУБД.
Ссылка на источник: https://tproger.ru/articles/5-zadanij-po-sql-s-realnyh-sobesedovanij
Поддержи статью лайком или подпиской!
Ещё больше интересных практических задач по SQL и задач с собеседований в нашем Телеграмм-канале и в интернете :)




