0 просмотренных постов скрыто



Создание анимированных видео в нейросети Stable Diffusion, пошаговое руководство
Друзья, всем привет, даже от меня вы уже не раз слышали, что в нейросетях сейчас можно делать буквально все: создавать тексты, генерировать музыку, делать дипфейки, создавать изображения и даже видео. Раньше генерировать видео можно было только в больших платных проектах типа Gen-2 от Runway или в пока еще бесплатном дискорд боте Pika Labs. Локальные решения были плохими или требовали топовых видеокарт.
Но времена меняются и сообщество создало открытое и доступное решение, которое позволяет создавать прекрасные анимированные видео прямо в нашем любимом Stable Diffusion в интерфейсе Automatic 1111. Об этом решении сегодня и пойдет речь.
Что нам понадобится:
Нейросеть Stable Diffusion в интерфейсе Automatic 1111 версии 1.6 или старше;
Расширение AnimateDiff;
Любимая модель семейства 1.5, у меня epiCRealism и подходящий промпт.
В этом гайде я не буду заострять внимание на установке Automatic 1111, она подробно описана на странице гитхаба, или посмотрите первые 5 минут из моего видео Чистая установка нейросети Stable Diffusion в интерфейсе Automatic 1111, но пока можете не скачивать SDXL модель, сегодня речь пойдет только про 1.5 модели и лоры движений к ним. Про модели движения для SDXL я расскажу в следующий раз, так что не забудьте оценить эту публикацию и оставить комментарий, так я увижу, что тема действительно интересна.
Установка расширения
Automatic 1111 у вас установлен и готов к работе. Осталось установить расширение которое и позволит нам создавать анимированные генерации. Расширение называется AnimateDiff, это порт одноименного исследовательского проекта, там можно скачать и отдельную от Automatic версию, но возможностей в ней намного меньше как и удобства использования.
Для установки расширения переходите на вкладку Extensions, затем Install from URL и просто вставляем в первое поле ссылку https://github.com/continue-revolution/sd-webui-animatediff и жмем Install. Ждем окончания установки и перезагружаем автоматик.
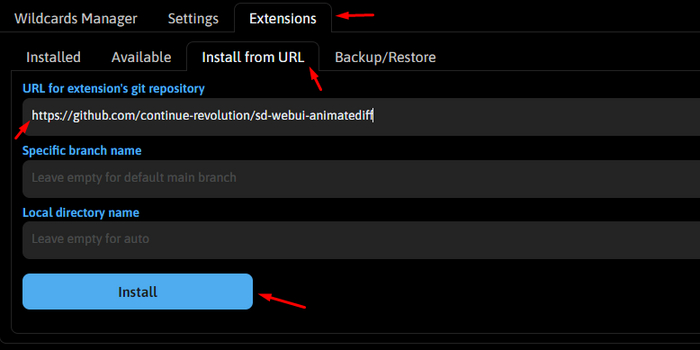
Но это еще не все, теперь надо скачать модели движения, проще всего это сделать с гугл диска. Скачивайте mm_sd_v15_v2.ckpt и всю папку MotionLoRA. Модель mm_sd_v15_v2.ckpt размещаем тут stable-diffusion-webui\extensions\sd-webui-animatediff\model, а лоры как обычно кладем в stable-diffusion-webui\models\Lora, можно прям в папке MotionLoRA, так даже удобнее, к лорам мы вернемся позже.
Почти все, осталось зайти в Settings/Optimization и активировать галочку Pad prompt/negative prompt to be same length. И нажать Apply Settings. Но скорее всего вы это сделаете когда будете второй раз перечитывать гайд, не понимая почему у вас анимация состоит из двух разных кусочков в одной гифке.

Ура, все готово, у нас должен появится аккордеон с заголовком AnimateDiff. Если у вас не появился, попробуйте еще раз перезагрузить автоматик. А если появился, то копируйте любой запрос со страницы модели которую используете, ставьте настройки как у меня на скрине ниже и запускайте генерацию.
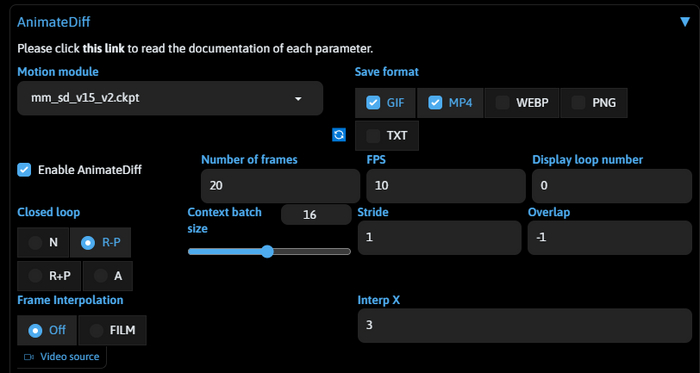
Я же создам анимашку по своему промпту, это персонаж-маскот одного из моих проектов, так что весь гайд нас будет сопровождать одна и та же девушка по имени Дженна. Вот что получилось у меня.
Как это работает
Специально обученная на видео модель встраивается в уже существующую модель Stable Diffusion 1.5 во время генерации и таким образом задает направление движения согласно данным на которых была обучена. Схожим образом работает и ControlNet. Это позволяет использовать любые модели Stable Diffusion 1.5 созданные сообществом как основу для вашего видео. Эта техника будет работать и с аниме моделями и с фотореалистичными, ниже вы увидите пример с тем же самым промптом что и девушка на пляже, но на другой модели.
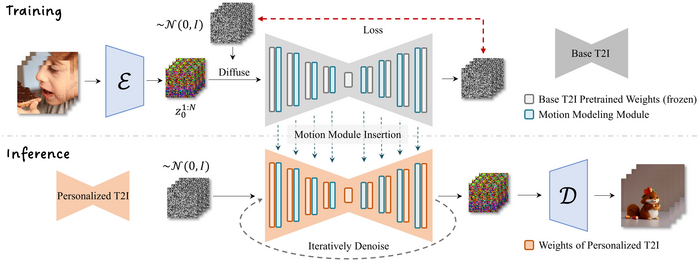
Cекрет этой технологии очень прост, главное достижение, оно же главное проклятье, все кадры генерируются на "одном листе", это позволяет достичь консистетности на видео, потому что все кадры создаются из одного замороженного латентного пространства. Но это же накладывает ограничения по производительности, потому что это единое полотно занимает много видеопамяти. Если у вас меньше 6гб видеопамяти, пытаться даже не стоит. Оптимально 12гб.

Это влияет и на работу сида, если вы думали, что сначала сгенерируете картинку, найдете классный сид, а затем включите AnimateDiff и картинка просто станет анимированной, то вынужден вас огорчить, с включенным расширением результат будет совсем другой. Ваш сид будет использован при построении всего большого полотна со всеми кадрами и это выдаст совсем другой результат. Так что подбирать сид придется случайным образом просто генерируя пока не найдем тот самый.
Настройки расширения
Я не буду рассказывать сейчас про все настройки и функции, такие как стилизация видео, или автоматическая смена промпта, чтобы делать аналоги лупбеков, это все темы для отдельных больших гайдов. Сейчас я расскажу лишь про самые основные и полезные.

Селектор моделей я думаю понятен и без слов, а вот на форматах остановимся подробнее, MP4 самый удобный для дальнейшего использования формат, и сохранится он в лучшем качестве, но он не отображается в браузере для предпросмотра, а GIF отображается, поэтому я генерирую и то и другое обычно.
Еще обратите внимание, что png info (информация о генерации) не записывается в форматы отличные от png, а это значит что если вы не поставите галочку на png либо на txt, то просто не сможете восстановить информацию о генерации потом. Рекомендую каждый раз сохранять отдельно финальную генерацию в виде png.
Number of frames - сколько всего будем генерировать кадров, чем больше - тем дольше. К тому же более длинные ролики получаются "рваными". Оптимально 16.
Context batch size - размер окна контекста генерации, зависит от модели. В нашем примере модель обучена на видео по 16 кадров и лучшего всего генерит именно их, нормально если меньше, отвратительно если больше.
FPS - количество кадров в секунду, оптимально 8-16, можно интерполировать в других программах позже.
Closed loop - режим закольцовывания видео, N - никакого, R-P - режим вычитания, расширение попробует вычесть кадры и закольцевать видео; R+P режим добавления, расширение попробует добавить кадры чтобы закольцевать видео; A - агрессивный режим, расширение попробует закольцевать видео форсированно, иногда приводит к артефактам, а иногда к хорошим результатам как ниже, тут склейка почти не видна.
Все остальные настройки нам мало интересны или задействуются в других режимах работы. Перейдем к самому вкусному!
Моушен Лоры
Наверное одна из самых классных вещей - это специальные лоры движения которые совместимы только с той самой моделью mm_sd_v15_v2.ckpt, с другими они попросту не работают.
Каждая из 8 лор обучена на свой собственный тип движения: Zoom In - приближение; Zoom Out - отдаление; Pan Left - смещение в лево; Pan Right - смещение вправо; Pan Up - смещение вверх; Pan Down - смещение вниз; Rolling Anti-Clockwise - вращение против часовой стрелки; Rolling Clockwise - вращение по часовой стрелке. Используя эти лоры вы можете воплотить практически любую режиссёрскую задумку.
Подключение лор
Подключаются в промпт моушен лоры так же просто как и обычные, открываете вкладку Lora, и просто кликайте на лору с желаемым эффектом. Вес рекомендуется поставить 0.7, на высоком весе будет больше артефактов, но вы вольны с этим экспериментировать. Посмотрим как работают лоры на примере с девушкой и салютом из начала публикации, я не буду менять запрос, только подключу по очереди разные лоры на движение. Не забудьте переключить Closed loop в режим N, чтобы получить больше движения при использовании лор.
Zoom In - приближение
Zoom Out - отдаление
Pan Down - смещение вниз
Pan Up - смещение вверх
Pan Left - смещение влево
Pan Right - смещение вправо
Rolling Anti-Clockwise - вращение против часовой стрелки
Rolling Clockwise - вращение по часовой стрелке
Самые крутые конечно это приближение и отдаление, некоторые портят композицию и надо поиграться с весом, потому что смещение влево заметно меньше, чем на том же весе смещение вправо, но в целом это фантастический инструмент для творчества доступный теперь и локально.
Секреты и советы
Используйте простые промпты. Моушен модель обучалась на видео из дата сета WebVid-10M, я приведу парочку примеров пар видео - описание, чтобы вы имели представление.
Lonely beautiful woman sitting on the tent looking outside. wind on the hair and camping on the beach near the colors of water and shore. freedom and alternative tiny house for traveler lady drinking.
Billiards, concentrated young woman playing in club
И вот так вот целый дата сет, где-то ролики с быстрой сменой кадров и описанием в одно предложение, а где-то практически статичные с большим художественным описанием. Так что если вы думали, что можно будет задать например конкретное движение машины в вашем видео, или еще какие-то более конкретные значения, то скорее всего у вас ничего не выйдет. Используйте более "художественные описания".
Не превышайте 16 кадров. Модель тренировали на видео из 16 кадров, поэтому не смотря на все костыли, видео длиннее все равно будут дергаться.
Не используйте несколько лор одновременно. Каждая лора добавляет больше шума и в результате мешает работе моушен модели, то же самое касается и контролнета, его можно использовать, но каждый слой будет уменьшат движение.
Если на вашем видео проявляется логотип шаттерстока, то проработайте негативный промпт или поменяйте негативный эмбединг. Особенно это заметно при использовании моушен лор, и не всегда удается решить до конца на этапе генерации.
Используйте Topaz Video AI. Все видео в посте прогнаны с такими настройками:
Все, что вы любите - работает! Вы можете использовать с этим расширением ControlNet, и Hires. fix, но не советую ставить больше увеличение больше чем в 1.3-1.5, даже на мощных видеокартах. Вы можете использовать ADetailer, но делать этого не стоит, потому что будет нежелательная на видео шевеленка даже с низким деноизнгом. Вы можете использовать любой фейсвап и сделать что-то подобное со своим лицом:
Ну и конечно экспериментируйте с моделями, не все одинаково хорошо работают, на некоторых есть странная серая дымка, но большинство топовых моделей с цивита отлично себя показали.
Друзья, а на этом у меня все, из этого гайда вы узнали как создавать короткие анимированные ролики из своих генераций, поняли как работает технология, познакомились с моушен лорами и теперь можете самостоятельно создать небольшую короткометражку, или даже что-нибудь по круче. Делитесь своими результатами в комментариях и в нашем чатике нейро-операторов.
Я рассказываю больше о нейросетях у себя на YouTube, в телеграм, на Бусти, буду рад вашей подписке и поддержке. До встречи на стримах, ближайший уже в понедельник, подпишитесь чтобы не пропустить.
Всех обнял, Илья - Nerual Dreming.
Показать полностью
7
17

Китайская компания DEEP Robotics объявила о создании робота с четырьмя ногами, оснащённого колёсами
Эти колёса необходимы для обеспечения хорошей проходимости на сложной местности и для устойчивого передвижения на высокой скорости.
😉 Представьте, что через десять лет эта машина сможет не только бежать или ехать, но и преследовать вас. И, возможно, будет оснащена огнемётом. А ещё может быть, что во время этого она будет выполнять сальто, просто потому, что способна на это.
Показать полностью

FaceFusion — замена лица на фото и видео. Полное руководство по DeepFake'ам и портативная RU версия
Привет! В этом видео я расскажу вам о революционном инструменте FaceFusion, который позволяет создавать невероятные видео с заменой лиц! Будь то замена лица на гифке или полноценное видео, FaceFusion делает это быстро и качественно. 🎭 Вы узнаете, как работает эта технология, как ей пользоваться в портативной версии, и если у вас есть видеокарта с 8+ ГБ видеопамяти, я покажу вам, как запустить FaceFusion на CUDA или DirectML! 🎨
Ссылки из видео:
🔗 Скачать FaceFusion Portable: https://t.me/neuroport/21
🎓 Клуб по нейросети Фокус: https://fooocus.ru/
🎨 Сайт с гифками: https://giphy.com/
🛠️ Конвертор webp в mp4: https://ezgif.com/webp-to-mp4
📢 Наш новый канал с портативками: https://t.me/neuroport
Мои ссылки:
📺 YouTube канал: https://www.youtube.com/@nerual_dreming
📢 Подпишись на основной телеграм, чтобы ничего не пропустить: https://t.me/neuro_art0
🎨 Наша онлайн нейросеть для создания изображений: https://artgeneration.me/
📱 Подпишись сразу на все мои нейро-каналы в телеграм: https://t.me/addlist/LQ-fUTyhVjEzYjIy
Показать полностью


Чингисхан завёл аккаунт на Twitch
Стримы, которые мы заслужили
Источник: 📼 @txt2vid
Показать полностью


Hentai too...("Заветные слова" в 4K) Ч.1
Хентай с сюжетом
Words Worth [1999-2000] [uncen] [5 of 5] апскейл с помощью нейронной сети

Железо
Ноутбук i5 7300hq GTX 1060(6g) 16gb RAM SSD 960EVO
для рендера Topaz Video Enhance AI
Исходник Video: MPEG4 Video (H264) 628x480 23.976fps [V: Shinkiro-raw
Выход Video: MPEG4 Video (H264) 3840x2160 23.976fps 9597kbps
Заливаю в облако и чуть позже для друзей Капитана Воробья
Worth [1999-2000] [uncen] [5 of 5] https://cloud.mail.ru/public/djVK/2JkoqVE6A
русская дорожка и сабы прилагаются (для ценителей качественного сюжета)
Sailor Moon в 4K https://cloud.mail.ru/public/YyB6/vQG8YHUVS ( буду заливать постепенно, но чуточку позже, осталось 2 овы Words Worth 2002 года отрендерить и приступлю)
Картинки для аппетита





Показать полностью
7

Обзор FaceFusion - перевоплощение популярного дипфейка Roop. Портативная версия в конце статьи
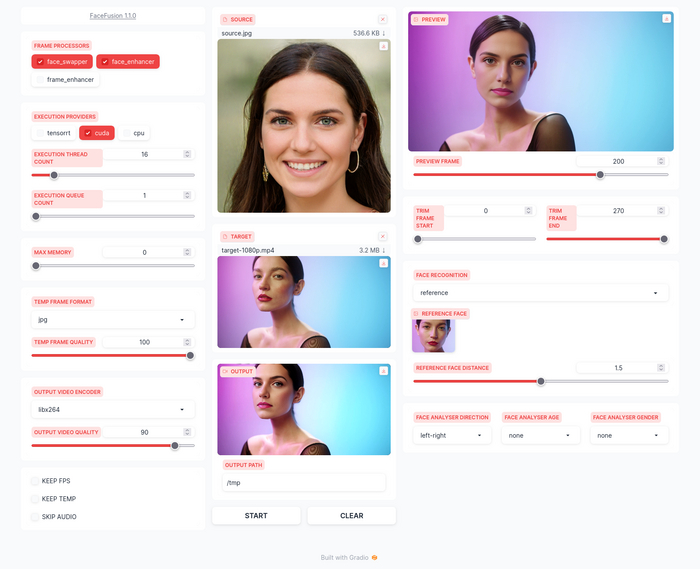
FaceFusion - это продукт одного из разработчиков популярного дипфейка Roop. Дело в том, что у них произошел разлад, проект Roop закрался, а команда разошлась.
В целом, FaceFusion - это тот же самый Roop, только с интерфейсом на базе Gradio, который многие знают по Stable Diffusion от Automatic1111
Тем не менее множество функций тут вынесены из командной строки в интерфейс.
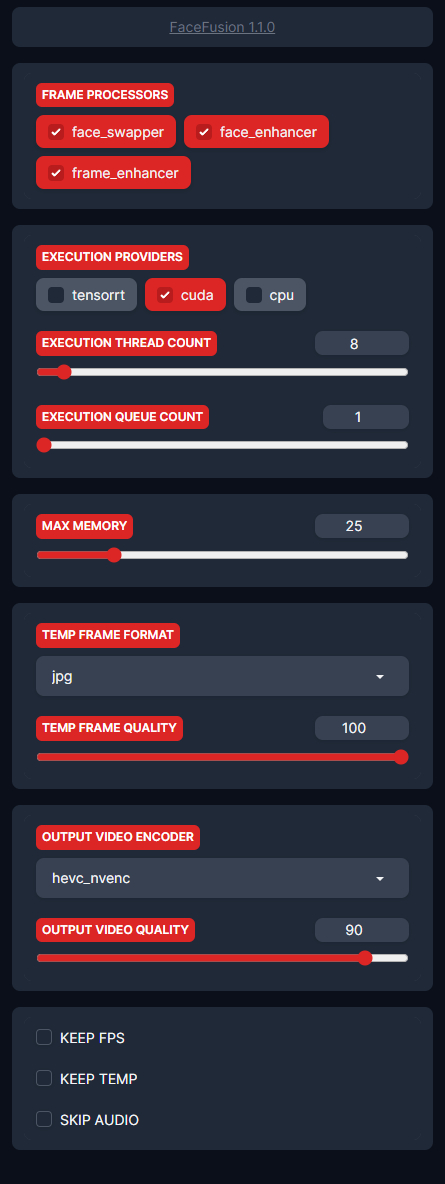
FRAME PROCESSORS - этот модуль отвечает за обработку кадров.
face_swapper - просто замена лица
face_enhancer - улучшение лица (через GFPGAN)
frame_enhancer - новая опция, апскейлит весь кадр.
EXECUTION PROVIDERS - тут вы выбираете ваш бэкенд, через что будет идти обработка. На видеокартах Nvidia это Cuda либо TensoRT, на AMD это DirectML (DML), если запускать на Windows.
Остальные же параметры в блоке EXECUTION отвечают за скорость обработки. Больше потоков - больше скорость, больше потребление видеопамяти. Поэтому выставляйте в меру, большое количество потоков может привести к вылету либо к замедлению работы.
MAX MEMORY - лимит потребления оперативной памяти.
OUTPUT VIDEO ENCODER - через какой енкодер будут собраны кадры в видео, после замены лица. Для видеокарт Nvidia можно использовать NVENC, так как он базируется на аппаратном ускорении.
KEEP FPS, KEEP TEMP, SKIP AUDIO - Отвечают за то, чтобы Сохранить фпс оригинального видео, оставить временную папку с раскадровками и пропустить аудио.
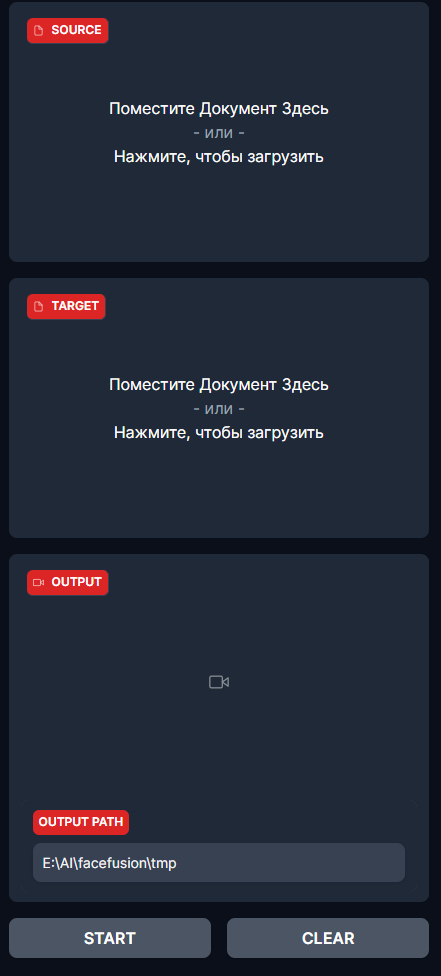
Средний блок отвечает за выбор файлов с которыми мы будем работать.
SOURCE - фото с лицом, на которое будем менять
TARGET - фото или видео, в котором будем менять лицо
OUTPUT PATH - где будет сохранено видео. Также в Output появится итоговое видео
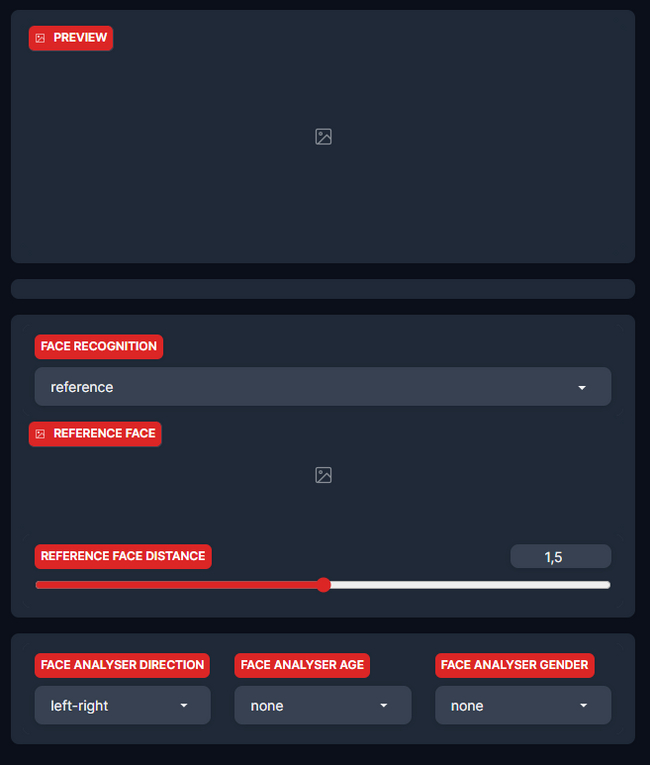
Третий блок содержит в себе:
PREVIEW - Тут вы можете посмотреть как будет выглядеть замена.
FACE RECOGNITION - выбор распознавания лиц. Либо на основе референса, либо все лица.
REFERENCE FACE - тут как раз и будут лица, распознанные на кадре из превью. Выбирая их, вы выбираете какое лицо будет меняться в кадре.
Оставшиеся параметры отвечают за настройки анализа лиц.
Что касается скорости работы - я не заметил разницы с последней версией Roop. Все примерно точно так же, шустро, но можно и шустрее (Refacer и Rope тому примеры)
Как обычно, я сделал портативную версию с запуском в 1 клик. Пока что готова версия для Nvidia, версия для AMD будет позже, ссылку на нее оставлю у себя в Телеграм канале.
Скачать портативную версию можно по ссылкам:
Мое облако | Яндекс Диск
Особенности портативной сборки:
- Запуск в 1 клик, не надо ничего устанавливать
- Удалена 18+ цензура.
- Обновлены библиотеки CUDA (Cudnn 8.9.4)
После открытия программы, откройте в браузере адрес, который будет написан в консоли (обычно http://127.0.0.1:7860)
Последующие обновления, а так же другие дипфейки можно найти у меня в Телеграм канале, а пообщаться на тематику всего, что связано с нейронками - можно в нашем чате.
Показать полностью
4

Deep Live Cam — нейросеть для дипфейков в реальном времени
Всем привет!
В этой статье познакомимся с Deep-Live-Cam - это инструмент для замены лиц в реальном времени и создания видеодипфейков с использованием всего одного изображения.
Софт включает встроенную проверку на недопустимые материалы и поддерживает GPU ускорение для улучшенной производительности.
Также расскажу, как не париться с установкой и запустить Deep Live Cam в один клик.
Всё, что нам понадобится, чтобы завести Deep Live Cam - это веб-камера и видеокарта Nvidia или AMD с более чем 6-ью Гб видеопамяти.
P. S. Если вы используете смартфон как веб-камеру то, к сожалению, программа просто не будет распознавать устройство. Возможно, в будущем это пофиксят, было бы очень удобно!
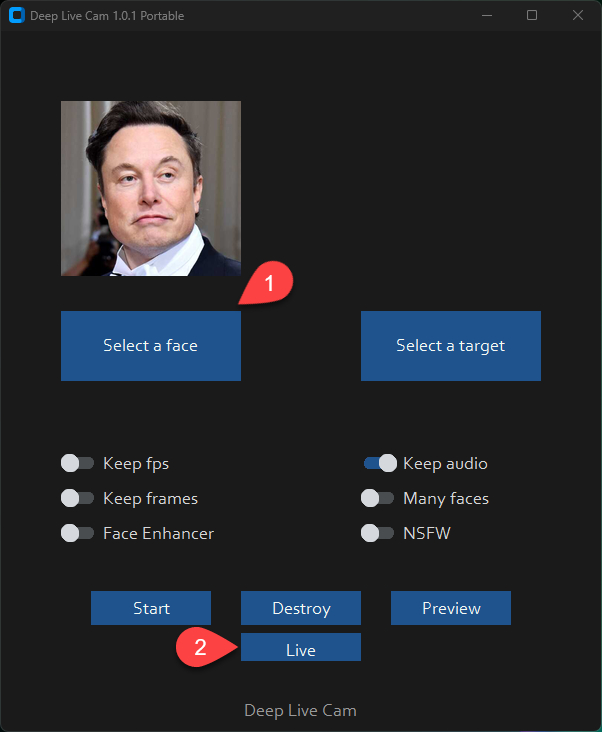
Интерфейс Deep Live Cam
Интерфейс Deep-Live-Cam интуитивно понятен и позволяет легко управлять основными функциями программы. Рассмотрим основные элементы интерфейса и их назначение.
Select a face - выбор исходного изображения с лицом, которое будет использовано для замены.
Live - включить дипфейк в реальном времени.
Preview - скрыть окно с превью видео.
По факту, это всё, что нужно для замены лица в реальном времени. Удивительно, что понадобится всего одна фотография!
Ещё я использовал Face Enhancer для апскейла лица на видео.
В одно мгновение я стал настоящим Томми Шелби!
Когда вы запускаете эту программу в первый раз, она загружает некоторые модели размером ~300 МБ. Так что проявите немножко терпения :3
Вот как это выглядит без апскейла:
Превращаемся в Папича:
Без апскейла и keep frames:
И тут мне пришла в голову идея превратиться в Шрека:
И с этим Deep Live Cam справляется отлично, главное подобрать хорошее исходное изображение.
Если хотите добавить превью в OBS, то просто добавьте захват окна и выберите Preview:
В заключение хочется сказать, что Deep Live Cam - крутая технология, которая открывает большое пространство для творчества, что может пригодиться блогерам и тем, кто создаёт контент.
Поэтому используйте ПО исключительно в позитивном ключе, придерживаясь этики и закона:
Не используйте лица людей без их явного согласия.
Избегайте применения для обмана или введения в заблуждение других лиц.
Воздержитесь от использования в коммерческих целях без соответствующих разрешений.
Не создавайте контент, порочащий репутацию или унижающий достоинство других людей.
Не применяйте технологию для создания фальшивых новостей или дезинформации.
Избегайте использования в целях политической пропаганды или манипуляции общественным мнением.
Не используйте для создания порнографического контента без согласия.
Воздержитесь от применения в ситуациях, где требуется подтверждение личности (например, при онлайн-экзаменах или собеседованиях).
Не используйте для обхода систем безопасности или аутентификации.
Избегайте создания контента, нарушающего авторские права или интеллектуальную собственность.
Помните, что ответственность за его использование лежит на пользователе. Применяйте технологию этично, уважая права и достоинство других людей.
Чтобы установить Deep Live Cam, достаточно скачать нашу портативную версию с установкой в один клик.
Перед установкой отключите антивирус, он ругается на самораспаковывающийся архив. Если переживаете, то скачивайте 7z-архив, который нужно просто разархивировать в любое удобное место
Подписывайтесь на 👾Нейро-Софт, канал с портативными версиями ваших любимых нейросетей!
Показать полностью
8