


Как обучить русскоязычную модель рассуждений - LRM?
Ранее на моем YouTube-канале уже были видео о моделях рассуждений — OpenAI o1/o3, DeepSeek R1. Эти модели обучены с помощью стратегии reinforcement learning находить решения для задач, требующих логических рассуждений. Способность строить цепочки рассуждений, ведущих к решению поставленной задачи, открывают возможность применения таких моделей в математике, программировании и других подобных направлениях.
Однако упомянутые модели имеют одно ограничение — они выполняют рассуждения на английском языке. И даже если вы укажете в промпте требуемый язык ответа, отличный от этих двух, то только вывод модели будет на этом языке, а вот сама цепочка останется на том, на котором модель обучена “думать”. Соответственно, чтобы заставить модель думать на русском, нужно применять файнтюнинг.
Есть интересный пример — коллекция моделей R1 Multilingual от японской компании Lightblue, которая ранее создала открытый мультиязычный файнтюнг Llama 3 - Suzume. Эта новая коллекция содержит модели рассуждений на базе DeepSeek-R1-Distill-Qwen, дистиллированных с помощью DeepSeek R1 версий Qwen. Что более важно - эти модели получены путем файнтюнинга на мультиязычном CoT (Chain-of-Thoughts), и данные CoT опубликованы на HuggingFace.
Датасет содержит данные на более чем 30 языках, включая русский. Данные получены следующим образом:
Выполнена выборка промптов из открытых англоязычных датасетов с последующим переводом на различные языки. Для перевода использовалась GPT-4o, которая, кстати, хорошо показала себя при создании моего собственного датасета и русскоязычного файнтюна Llama 3 на нем. Далее авторы мультиязычного CoT-датасета сгенерировали ответы на полученные промпты с помощью deepseek-ai/DeepSeek-R1-Distill-Llama-70B восемь раз, и отфильтровали блоки <think> не на том языке, либо с нарушениями правил языка или логическими ошибками. Это достаточно интересный момент, так как разработчики полностью опубликовали код для генерации своего датасета, включая фильтрацию сгенерированных цепочек рассуждений. Если с автоматическим определением языка цепочки все достаточно просто, то для проверки ее соответствия нормам языка и, самое главное, логической корректности, пришлось опять-таки задействовать LLM. Принцип такой же, как и при использовании модели-судьи для выполнения автоматизированных evaluation-тестов.
Пример оценочного промпта из кода проекта:
fluency_system_message = f"""You are a {language} fluency evaluation AI. Given a piece of text, give the fluency and naturalness of the {language} in the text a score from 1-5. Only include your final number in your output."""
То есть модель-судья выставляет оценку от 1 до 5 правильности и естественности сгенерированного текста. Почему-то разработчики использовали GPT-4o-mini, хотя у нее самой, на мой взгляд, есть проблемы с мультиязычностью. Возможно, более правильной оценки можно добиться, используя тот же DeepSeek V3. В итоговый датасет попали только те ответы, у которых наилучшая оценка по пятибалльной шкале.
После этого датасет готов к файнтюнингу моделей рассуждений — дистиллированных на R1 версий Qwen. Для файнтюнинга моделей от 1.5 до 14B авторы использовали llamafactory (код доступен в репозитории на HF по ссылке выше) и достаточно скромные GPU-мощности: всего лишь около 10 минут на восьми NVIDIA L20. Т.е. Вы вполне можете взять GPU поменьше — например, из доступных моделей в облаке подошли бы две RTX 4090 или A10, или одна V100 - и за несколько часов достичь того же результата.
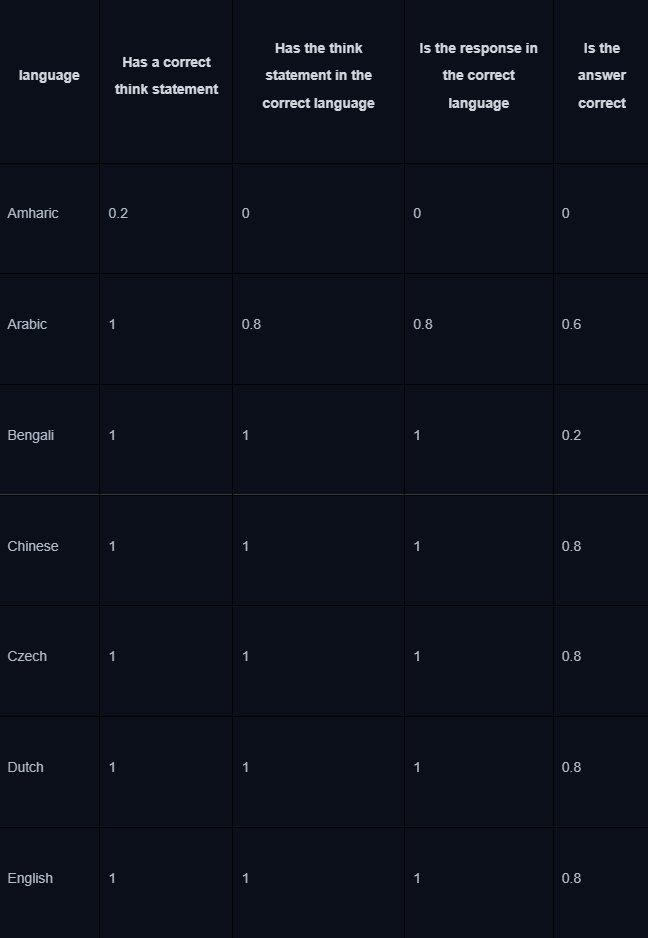
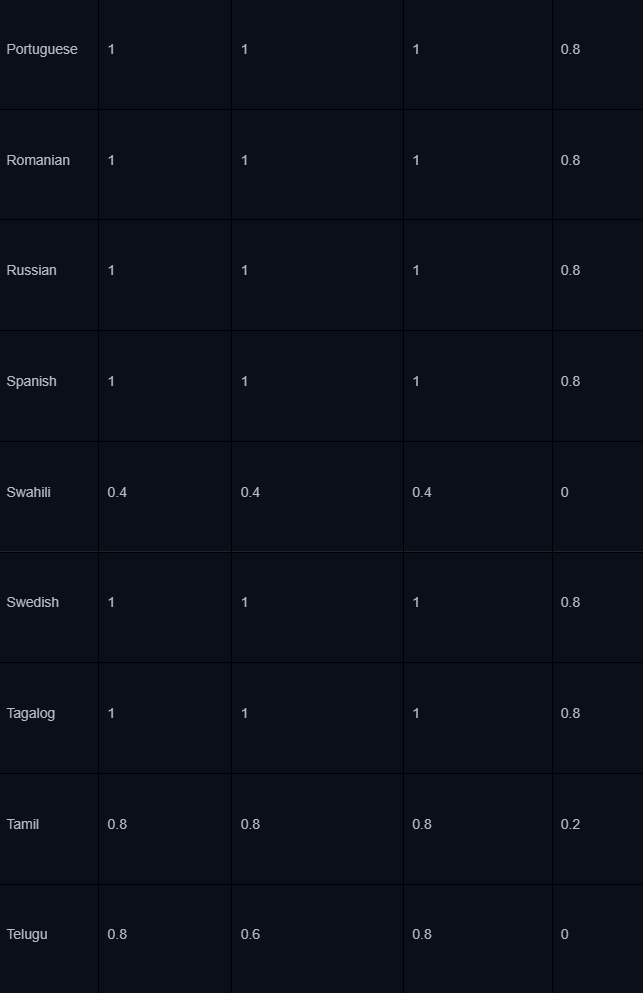
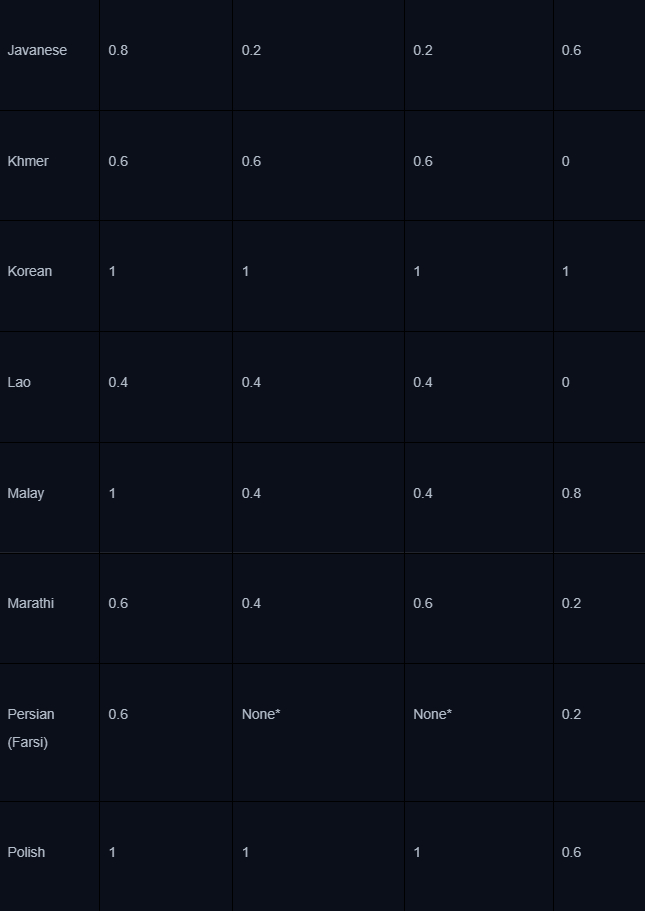
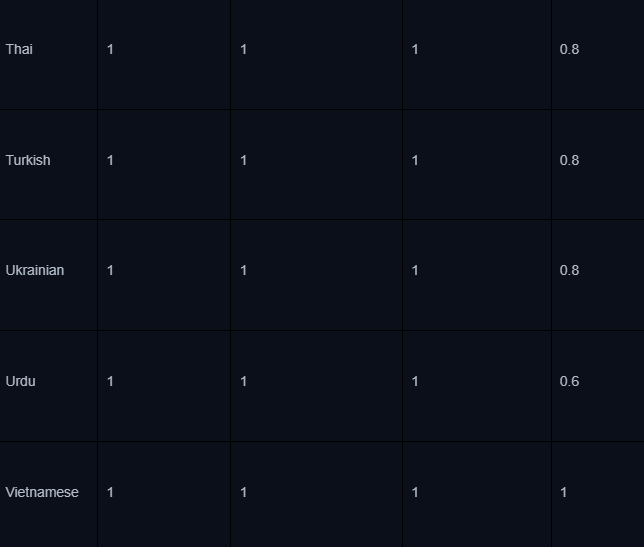
В остальном это обычный SFT-файнтюнинг в одну эпоху, без квантизации. Отдельно стоит отметить процесс evaluation — код можно найти здесь. Ниже — таблица оценок полученных моделей рассуждений для промптов на разных языках. Из нее можно сделать вывод, что модели генерируют более корректные цепочки на таких языках, как английский, немецкий, испанский и другие, наличие которых в корпусе базовой модели, можно предположить, было относительно высоким. Их оценка около 0.8, тогда как у менее распространенных в цифровом пространстве языков она ниже, например, 0.2 у тамильского.
Хорошая новость, что на русском модели научились генерировать цепочки мыслей достаточно неплохо, судя по результату evaluation — даже при том, что в датасете всего 54 примера на русском.

Лига программистов
2.2K постов12K подписчика
Правила сообщества
- Будьте взаимовежливы, аргументируйте критику
- Приветствуются любые посты по тематике программирования
- Если ваш пост содержит ссылки на внешние ресурсы - он должен быть самодостаточным. Вариации на тему "далее читайте в моей телеге" будут удаляться из сообщества