Привет! Я Михаил Шардин — IT-разработчик, кандидат технических наук и частный инвестор с 19-летним опытом на финансовых рынках. Автор с 2003 года 300+ статей на Хабре, Т—Ж и Смартлабе о том, как технологии помогают экономить время и избегать рутины. Выступаю на конференциях Smart-Lab Conf и «Питерский промпт», рассказываю об IT-инструментах против цифровой неэффективности. Занимаюсь автоматизацией, анализом данных, машинным обучением и инвестициями.
Несколько лет назад моя стиральная машина Bosch внезапно умерла, но не физически. Стирать она продолжала всё так же хорошо, но производитель решил что часть функции в моей стране работать больше не должна.
Покупать новую стиралку из-за проблем с софтом показалось мне странной идеей, поэтому я сделал то что обычно делают люди когда нет желания покупать новую технику - смог обойти ограничения.
Моя книга для всех кто хочет облегчить свою жизнь
За пару вечеров я подключил её к локальному дому через Home Assistant и она снова поумнела только без облаков и внезапных блокировок.
Я тогда подумал:
«Забавно. Вместо покупки новой техники я просто написал немного кода».
Но это была только разминка.
Через некоторое время в моей жизни случилось развод. И возникло куда более приземлённая задача - следить за расписанием ребёнка и не ругаться каждый раз из-за календаря.
По итогу я написал небольшой скрипт для Google Календаря, который автоматически фильтруют события, синхронизирует расписания и показывает каждому только его часть.
Никаких «а ты говорил, что в среду секция», никаких «я думала ты забираешь».
Скрипт просто держит порядок.
А однажды я заметил странную вещь.
У меня:
таблицы сами собирают данные
отчёты генерируются одним кликом
инвестиционный портфель обновляется автоматически
домашняя техника живёт своей жизнью
а начальник иногда думает, что я работаю в выходные
Хотя на самом деле это делает скрипт из двадцати строк.
Я не программист из корпорации и не DevOps-инженер.
Я просто постепенно автоматизировал всё, что меня раздражало.
В какой-то момент этих решений накопилось столько, что я решил их собрать в книгу.
Так появилась книга:
Михаил Шардин
Excel, Python и API. Автоматизация данных и управление офисом, домом, финансами
Эта книга - не учебник по языкам программирования. Это готовый сборник практических рецептов для создания собственной цифровой инфраструктуры для частного лица.
К книге прилагается ссылка на папку с готовыми кодами, примерами и рабочими заготовками которые можно просто брать и адаптировать под себя.
В книге много практических вещей, которые я реально использую:
например:
скрипт, который собирает отчёты из сотен Excel-файлов
домашний «цифровой дворецкий» на Python
система учёта инвестпортфеля с автоматической загрузкой котировок
поиск выгодных облигаций через скрипт
тестирование инвестиционных идей и бэктестинг
локальный умный дом без облаков
скрипты для семейных задач и бытовых мелочей
Короче.
Если вас, как и меня, раздражает:
перекладывание данных из одной таблицы в другую
ручное обновление отчётов
туповатые «умные» устройства, которые зависят от облака
и вообще любая цифровая рутина
то, скорее всего, вы найдёте там пару идей, которые сэкономят вам много времени.
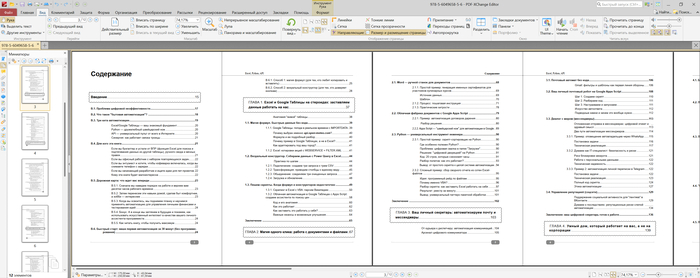
Содержание
Полное содержание моей книги Михаил Шардин — Excel, Python и API: автоматизация данных и управление офисом, домом, финансами… — СПб.: Издательство Наука и Техника, 2026 г. — 432 с. можно скачать в pdf по ссылке и познакомиться что будет внутри.
В понедельник в 13:01 мою маму добавили в рабочий чат в Telegram. Группа называлась точно так же, как клиника, где она проработала больше десяти лет уже будучи на пенсии и из которой уволилась около пяти лет назад.
Скрин списка чатов Telegram
В чате были знакомые фамилии с реальными фотографиями, а ещё деловой тон, обсуждение «приказов Минцифры», «стажа» и «пенсии». А уже через сорок пять минут этот же чат превратился в поток угроз, оскорблений, фейковых уведомлений о входе в «Госуслуги» и попытку оформить на неё десятки микрозаймов.
Ни один рубль украден не был — но не потому, что схема не работала.
То, что я увидел в этот день, было не просто мошенничеством. Это была тщательно срежиссированная постановка: фальшивые коллеги, заранее подготовленные диалоги, правильная терминология, давление авторитетом и временем. Слово «оцифровка» стало наживкой. «Госуслуги» — оружием. А страх потерять стаж, пенсию и «оказаться вне реестров» — рычагом.
Но эта история — не про деньги. Это история о краже личности в прямом эфире. О том, как за считаные минуты человека лишают ощущения безопасности, контроля и достоинства. Я пишу её не как айтишник. Я пишу её как сын, который в реальном времени вытаскивал мать из цифровой ловушки — и понял, насколько беззащитными мы все оказались перед новой формой насилия.
Дальше — по шагам. Без эмоций. Только факты, механика и выводы для того чтобы в следующий раз вы сами такой чат сразу просто закрыли.
Акт I. Театр марионеток (время 13:01 – 13:23)
Этот этап — самый важный. Здесь ещё никого не грабят, не пугают уголовными делами и не просят «срочно перевести деньги». Здесь строят сцену. Аккуратно, методично, почти незаметно.
Вход в доверие через «работу»
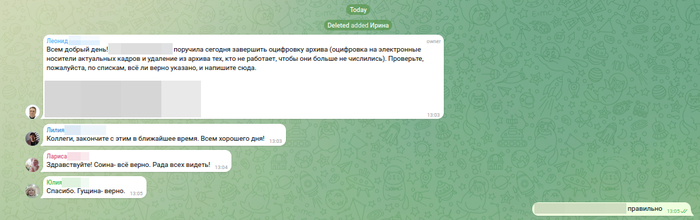
Всё начинается с добавления в закрытый групповой чат Telegram. Не личное сообщение, не звонок, а именно рабочая группа.
Название группы совпадает с реальным названием клиники. Не «что‑то похожее», не с ошибкой в слове, а ровно так, как она называлась в документах и на табличке у входа. Почти сразу появляется сообщение от «администратора». Тон — вежливый, деловой, без суеты. Никаких ссылок, никаких требований. Просто задача. «Надо проверить списки». Всё максимально буднично.
Скрин первого сообщения администратора
Использование реальных данных
Дальше в чате появляются списки. Полные ФИО. Реальные даты рождения. Имена людей, которые действительно работали вместе много лет назад. Участники чата отвечают — коротко, по делу: «верно», «подтверждаю», «всё правильно».
Аватары — с фотографиями этих людей. Для человека без паранойи это выглядит убедительно. Для человека старшего поколения — почти неопровержимо.
Психологические крючки
Только после этого в разговор осторожно вводятся триггеры. Очень аккуратно, без давления:
«Удаление из архива»
«Чтобы не было проблем со стажем»
«Были случаи, когда урезали пенсию»
«Приказ сверху, по линии Минцифры»
Скрин чата с этими формулировками
Обратите внимание: ни одного слова о деньгах. Ни переводов, ни карт, ни «безопасных счетов». Только бюрократия.
Это хорошо поставленный спектакль, где жертву сначала делают участником «рабочего процесса», а уже потом — объектом атаки. Пока человек думает, что он сотрудник, а не цель, защита отключена.
Акт II. Технический капкан (время 13:23 – 13:27)
На этом этапе спектакль резко меняет декорации. Если в первом акте зрителю показывали «работу», то здесь на сцену выводят «технологии». И это важно: для человека, который хотя бы краем уха слышал про IT, слово «бот», «подтверждение», «ключ» звучит убедительно. Кажется, что дальше начинается не психология, а техника. На самом деле — это всё та же постановка.
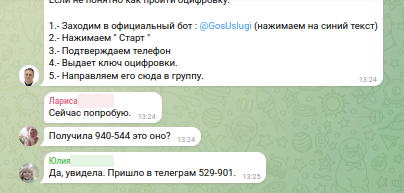
Фальшивый «официальный бот»
В чат выкладывают ссылку на якобы официальный бот «Госуслуг». Название выглядит почти безупречно: @gosuslugi. Глаз цепляется за знакомое слово, мозг дорисовывает остальное сам.
Название бота в чате (@GosUslugi)
Реальный username в профиле (@Di24gubBot)
На деле ссылка ведёт на сторонний бот t.me/Di24gubBot. Но чтобы это заметить, нужно либо специально проверять, либо уже быть настороже. Это не взлом. Это UI‑обман.
Эффект толпы в действии
Дальше включается социальное давление. «Коллеги» начинают задавать вопросы: что нажимать, куда заходить. Почти сразу другие «коллеги» отписываются: «получилось», «пришёл код», «отправила».
Скрин общего чата
Самое важное — всё происходит публично, в общем чате. Не в личке. Не скрытно. На глазах у всех. Это классическая техника: если десять человек уже сделали одно и то же — значит, это безопасно.
Мозг экономит энергию и отключает критическое мышление. Зачем сомневаться, если «все прошли»?
Что произошло на самом деле
С технической точки зрения произошло простое действие: пользователь нажал «Поделиться контактом» и передал номер телефона боту. Никакого взлома, никакого «доступа к Госуслугам» в этот момент не было.
Так называемый «код», который просят отправить в чат, — не код доступа и не подтверждение входа. Это элемент спектакля. Реквизит, создающий ощущение процесса и контроля.
Ключевой вывод здесь неприятный: все персональные данные у мошенников были ещё до начала атаки. Этот этап был нужен не для получения информации, а для психологического переключения жертвы — из роли «сотрудника» в роль «объекта операции».
Технический капкан захлопывается тихо. И именно поэтому он работает.
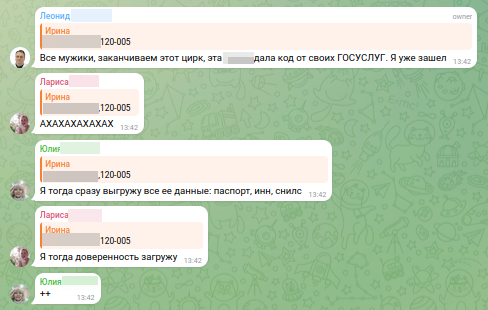
Акт III. Срыв масок и шоковая терапия (время 13:42)
Этот акт — самый короткий по времени и самый разрушительный по эффекту. Сценарий, который полчаса выстраивали аккуратно и почти интеллигентно, ломается за секунды. Маски сбрасываются демонстративно. Именно так и задумано.
Мгновенная трансформация
Вежливый «кадровик», который ещё недавно писал канцелярским языком, исчезает. Его место занимает поток агрессии. Мат. Оскорбления. Троллинг, рассчитанный на максимальное эмоциональное зацепление. Сообщения летят одно за другим — быстро, без пауз, без логики.
Это выглядит как истерика. Но это не эмоции. Это инструмент.
Скрин агрессивных сообщений
Унижение здесь показательное: «ты уже всё потеряла», «мы всё видим», «ты сама виновата». Человека не просто пугают — его лишают опоры, статуса, роли. Он больше не «сотрудник». Он — объект давления.
Цель психологического удара
Задача этого этапа проста и цинична: вызвать панику. Не страх — именно панику. Состояние, в котором мозг перестаёт анализировать и начинает действовать рефлекторно.
В этом состоянии человек:
не проверяет факты
не читает мелкий текст
не сомневается
срочно ищет «живого человека», который скажет, что делать
Именно поэтому следующий шаг — звонок. Не чат, не бот, не сообщение. Голос. Прямая линия давления.
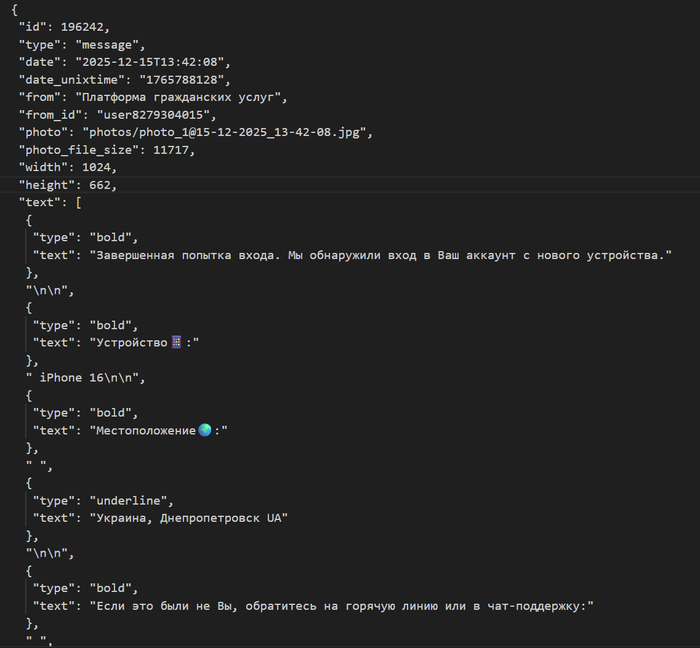
Фейковые «уведомления»
Параллельно в чат и личные сообщения начинают сыпаться «уведомления»:
«Вход в Госуслуги с iPhone 16»
«Геолокация: Украина, Днепропетровск»
«Загружена генеральная доверенность»
Одно из сообщений бота
Технический скрин фейкового уведомления
Формулировки подобраны идеально. Современно, страшно, «технически». Расчёт на то, что человек не знает, как именно выглядят настоящие уведомления, но понимает общий смысл.
В МФЦ в 15:16
Когда я с мамой в 15:16 сидя уже в МФЦ узнали:
входов в «Госуслуги» не было (на фото мой вход сразу когда я оказался рядом с мамой)
доверенностей не оформлялось
никаких действий не происходило
Но в 13:42 это знание недоступно. Потому что шоковая терапия работает только здесь и сейчас. И именно в этот момент система либо ломает человека — либо даёт сбой.
Акт IV. Сценарий Б: кредитная бомбардировка (время 13:53 и следующие сутки)
Когда шоковая атака не ломает человека сразу, у мошенников включается запасной план. Он менее эффектный, но куда более изматывающий. Это атака не на эмоции, а на выносливость.
Массовая подача заявок в МФО
В ход идут уже имеющиеся данные: ФИО, дата рождения и номер телефона — все эти данные были у них и до атаки. Этого достаточно, чтобы запустить автоматическую рассылку заявок в микрофинансовые организации. Никаких разговоров, никаких «подтверждений личности». Просто скрипт, который отправляет десятки заявок в разные МФО.
Важно понимать: это не точечная попытка украсть деньги. Это ковровая бомбардировка. Расчёт на то, что хотя бы где‑то система даст сбой, скоринг будет лояльным, а кредит — одобренным.
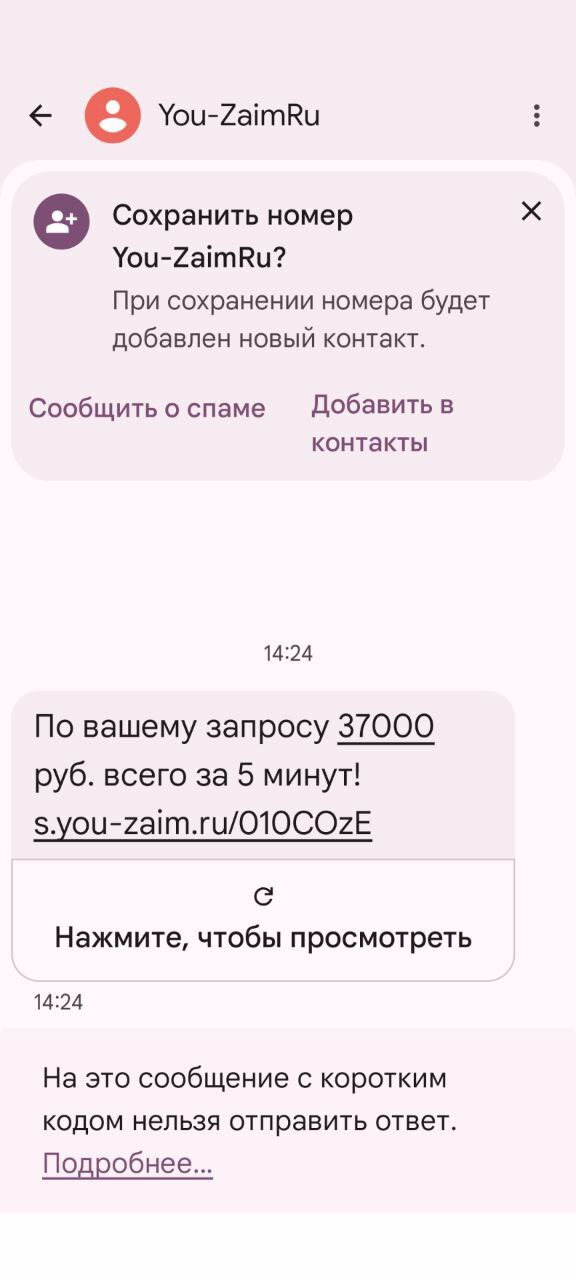
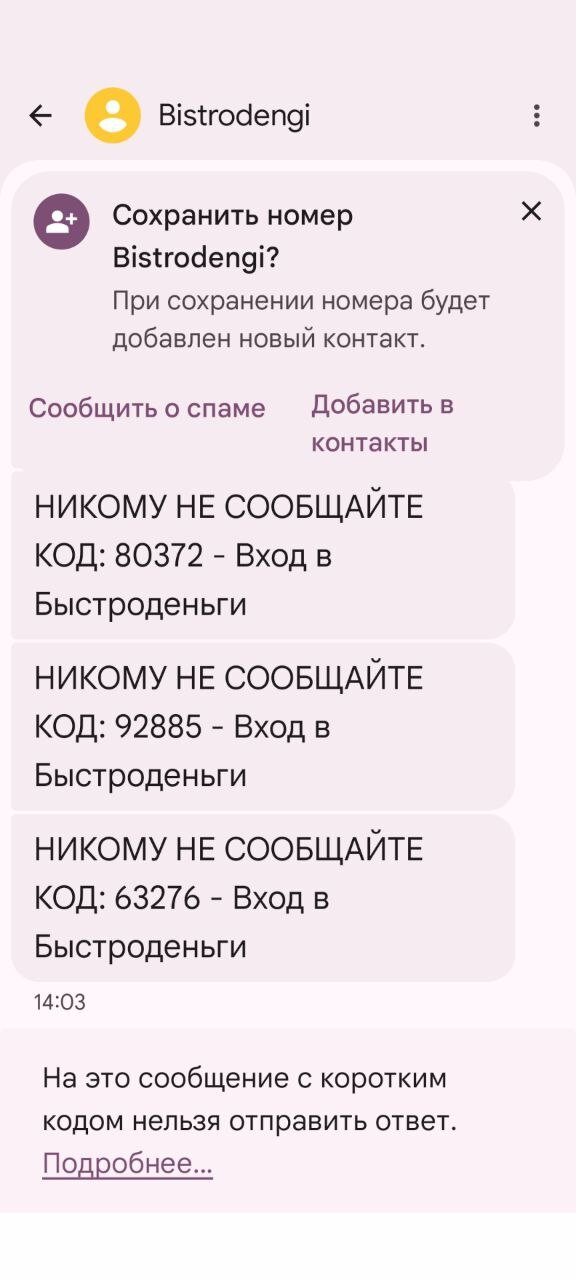
Поток СМС как оружие
Через несколько минут начинается вторая волна — СМС. Десятки сообщений подряд. Коды подтверждения. Уведомления «заявка принята», «заявка одобрена».
Пример СМС
Представьте, что вы получаете около двадцати таких сообщений за короткое время. А теперь представьте, что вам 72 года. Телефон вибрирует без остановки, каждое сообщение — про деньги, долги, обязательства.
Пример СМС
Количество здесь — ключевой фактор. Не важно содержание каждого отдельного сообщения. Давление создаёт сам поток. Срочность, множественность, ощущение, что процесс уже идёт и его невозможно остановить.
Пример СМС
Почему деньги не украли
Деньги не украли не потому, что схема была слабой. А потому что в этот раз система дала сбой — с их стороны.
Пример СМС
Мы быстро доехали до МФЦ. Был оформлен самозапрет на кредиты. Запрет на сделки с недвижимостью был установлен заранее — ещё до этой истории, как мера «на всякий случай».
Сценарий Б рассчитан на то, что человек устанет раньше, чем разберётся. И именно поэтому он опасен. Он не пугает — он давит до тех пор, пока не сломает.
Чёрный список: технические следы атаки
Этот раздел — для поисковых роботов, специалистов по безопасности и тех, кто прямо сейчас гуглит подозрительный номер или ссылку. Я оставляю эти «цифровые отпечатки» здесь, чтобы разорвать цепь анонимности. Скрипты меняются, но паттерны и идентификаторы часто живут дольше, чем фальшивые аккаунты.
Технические артефакты атаки:
Фейковый бот «Госуслуг»: внешне он копирует дизайн, но его username выдает подделку: @Di24gubBot (ID: 8279304015). Обратите внимание на механику: ссылка содержала start=aladin... — это реферальный «хвост», по которому скрипт понимает, какую именно жертву нужно обрабатывать.
Аккаунты-кукловоды: имена и фото украдены у реальных людей. Но Telegram ID — это уникальный цифровой паспорт аккаунта, который не подделать.
ID 8571326145 — координатор атаки. Сначала втирается в доверие, затем оказывает давление, в финале — глумится над жертвой.
ID 8279304015 (Бот) — фальшивые «Госуслуги». Собирает номер телефона и перехватывает код авторизации Telegram.
ID 5081257726 (Группа) — создана исключительно для спектакля.
ID 8593742198 и 8578455336 — отыгрывают роль коллег, которые «уже всё прошли». После взлома жертвы мгновенно меняют тон на издевательский («доверенность загружу», «паспорт выгружу»).
ID 8438081199 — аккаунт‑скрипт, который молча добавил жертву в группу в самом начале (действие invite_members).
Если вы видите эти ID в своих логах или черных списках — блокируйте.
Серые лидогенераторы: похоже большая часть сайтов из списка ниже — это не сами кредиторы, а агрегаторы. Они собирают персональные данные и перепродают их реальным МФО, создавая лавинообразный эффект спама.
Ниже приведен список доменов и отправителей — их системы были использованы в автоматизированной рассылке заявок без согласия жертвы. Если вам пришло СМС от этих сервисов без вашего запроса — ваши данные уже «прогоняют» по скрипту. Хотя некоторые из сайтов (например, nadodeneg.ru) — легальные МФО, зарегистрированные в реестре ЦБ.
Эту таблицу создал я, чтобы обзванивать все организации в день сразу после атаки. Чтобы написать официальные письма или нанять юриста для взаимодействия по мошенничеству.
Но как оказалось многие из них даже не имеют телефона на сайте.
Многие имеют юридическую привязку к ИП, зарегистрированному менее года назад.
Было ещё несколько, уже на следующий день пришли.
Что делать, если вы попали в такую ситуацию
В информационной безопасности есть понятие — план реагирования на инциденты. Когда атака уже началась, эмоции — ваш враг. Действуйте по сухому алгоритму. Это чек‑лист для минимизации ущерба.
1. Не кормите тролля
Как только вежливый тон сменился на угрозы, мат или требования — немедленно прекращайте диалог. Не пытайтесь оправдываться, не шутите в ответ, не угрожайте полицией. Любая ваша реакция дает злоумышленникам время и информацию. Ваша задача — разорвать соединение. Блокируйте пользователя, выходите из группы, удаляйте себя из чата.
2. Изоляция периметра: не звоните «в поддержку» Номера телефонов, которые вам подсовывает фейковый бот или присылают «коллеги» в чате — это SIP‑телефония мошенников. Позвонив туда, вы попадёте не в службу безопасности, а на второй уровень социальной инженерии, где вас «дожмут» голосом. Настоящая поддержка Госуслуг или банка никогда не звонит через мессенджеры и не просит диктовать коды.
3. Поход в МФЦ Если вы передали код или перешли по ссылке, считайте, что ваша цифровая личность скомпрометирована.
Срочно идите в МФЦ. Ваше физическое присутствие с паспортом — это «мастер‑ключ», который перекрывает любой удаленный доступ.
В МФЦ сбросьте пароль, настройте вход по TOTP и, главное, запросите историю входов. Убедитесь, что там нет посторонних устройств.
4. Превентивные патчи безопасности Эти действия нужно выполнить всем, не дожидаясь атаки. Это ваша «цифровая прививка»:
Самозапрет на кредиты. Оформляется через реальные Госуслуги. Даже если мошенники украдут ваши данные, автоматический скоринг отклонит заявку.
Запрет на сделки с недвижимостью без личного присутствия. Это закрывает уязвимость с продажей квартиры через украденную или поддельную ЭЦП электронную подпись.
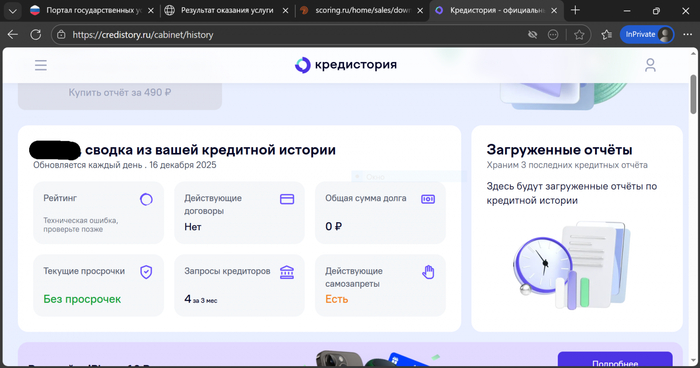
5. Аудит и мониторинг (проверка БКИ) Закажите выписку из Бюро кредитных историй (через Госуслуги это бесплатно дважды в год).
Смотрите не только на выданные кредиты, но и на запросы.
Если видите лавину запросов от МФО (как в списке выше) — значит, ваши данные попали в бомбер. Сами по себе запросы денег не крадут, но это сигнал: нужно мониторить ситуацию.
Один из 4х сайтов, которые я смотрел уже на следующие сутки
6. Цифровая криминалистика. Прежде чем удалять чат у себя, сделайте экспорт истории или скриншоты. В Telegram Desktop есть функция Export Chat History. Сохраните всё: ID ботов, никнеймы, номера телефонов, время сообщений. Возможно эти логи — единственное доказательство если дело дойдет до реального финансового ущерба. Факты лучше эмоций.
Заключение: почему это важно
Это не история о «глупости» или «доверчивости». И точно не про «пожилых людей, которые плохо разбираются в технологиях». В этой истории нет ни одного примитивного хода. Здесь нет «переведи деньги», «назови код» или «безопасного счёта» в лоб. Здесь работает профессионально выстроенная цифровая атака, в которой человек — не слабое звено, а цель.
Это история о том, как ломают не через уязвимости в софте, а через уязвимости в привычках. Через то, что для нас кажется нормальным и безопасным:
рабочий чат
знакомые фамилии
служебный тон
«приказ сверху»
формальные процедуры
цифровые сервисы государства
С точки зрения IT это не взлом. Это профессональная социальная инженерия: сценарий, роли, тайминги, резервные планы, автоматизация. Настоящая модель, где пользователь — конечная точка, а его психика — интерфейс.
Сегодня это врач.
Завтра — бухгалтер с доступом к счетам.
Послезавтра — учитель с данными учеников.
Инженер. Кадровик. Айтишник. Любой, кто привык выполнять рабочие процессы и доверять «системе».
Важно понять главное: мошенники больше не атакуют «человека вне социальной системы» — они атакуют человека внутри системы. Они не просят выйти из роли. Они используют её.
Единственный реальный барьер — знание сценария.
Если вы один раз увидели эту схему целиком: рабочий чат → доверие → «техника» → шок → давление → изматывание и она больше не работает так, как задумано. Магия исчезает.
Именно поэтому такие истории нужно фиксировать, разбирать и публиковать. Не ради хайпа. Не ради жалости.
А ради того, чтобы в следующий раз — увидев знакомый шаблон — вы просто закрыли чат и прекратили диалог.
Под статьёй были комментарии с предположениями, что текст сгенерирован нейросетью. И я считаю важным это прояснить.
Текст статьи написан лично мной, на основе событий этого понедельника, 15 декабря 2025 года, которые произошли с моей мамой 72 года. Это не художественный и не сгенерированный материал, а изложение конкретной жизненной ситуации.
Хотя нейросеть действительно использовалась, но только для редакторской правки — для улучшение формулировок и читаемости. К созданию содержания, фактов и выводов нейросеть не допускалась.
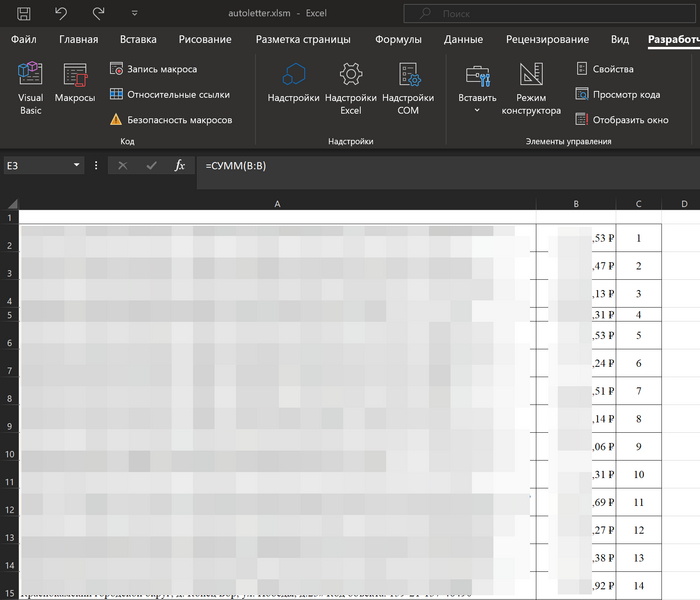
Иногда бывают такие задачи за которые браться не хочется - например на фотографии реальная пачка документов около 700 страниц для которой надо составить сопроводительное письмо - то есть сделать опись документов. По примерной прикидке - ручной работы на целый день как минимум.
Реальная фотография с документами
Ситуацию несколько облегчает то, что на эти распечатанные документы есть исходные Excel файлы. В итоге поиск и написание решения заняло около часа и в случае повторной работы займёт около 5 минут собственного времени.
Часть 1: Visual Basic for Applications (VBA)
Visual Basic for Applications (VBA) – это язык программирования, который позволяет автоматизировать задачи и создавать макросы для приложений Microsoft Office. Проще говоря, VBA помогает пользователям автоматизировать повторяющиеся задачи, такие как создание отчетов, форматирование документов и многое другое.
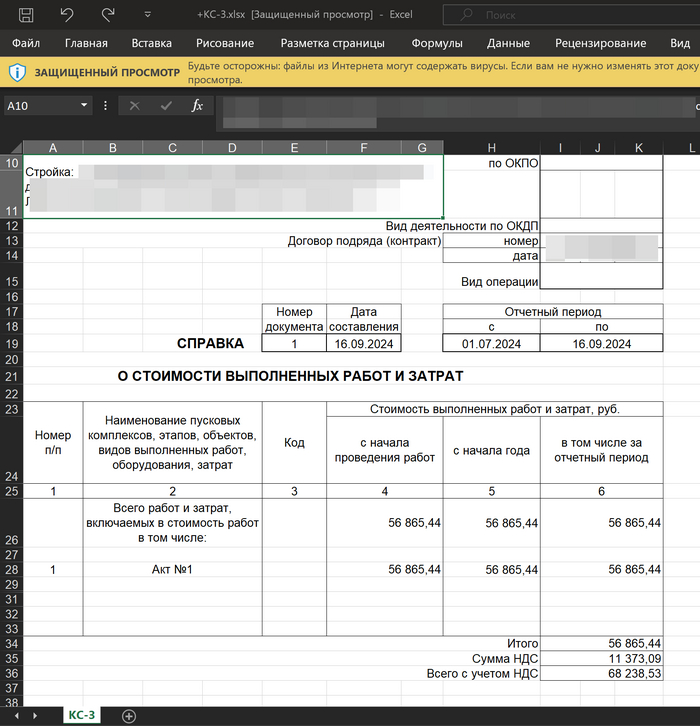
В данном случае преимуществом было то, что все документы однотипные и созданы по шаблону - по форме КС-3. Форма КС-3 относится к документации в сфере строительства и представляет собой "Справку о стоимости выполненных работ и затрат".
Эта форма для каждого адреса хранилась в файле который назывался "+КС-3.xlsx": внутри основного каталога было множество подкаталогов и файл имел две очень важные ячейки:
Ячейка A10 - содержала название.
Ячейка I36 - содержала стоимость.
Во всех документах эти ячейки не меняются и данные можно автоматически собрать в Экселе при помощи скрипта, который обходит основной каталог и все вложенные:
Sub CopyDataFromFiles() Dim FileSystem As Object Dim objFile As Object Dim objFolder As Object Dim wbSource As Workbook Dim wsSource As Worksheet Dim wsDest As Worksheet Dim DestRow As Long Dim FileExt As String Dim FilePath As String Dim DestColumn As Long
Set FileSystem = CreateObject("Scripting.FileSystemObject") Set wsDest = ThisWorkbook.Sheets(1) ' Данные будут скопированы на первый лист DestColumn = 2 ' Столбец B
Application.ScreenUpdating = False
' Вызов рекурсивной функции для обработки каждого файла ProcessFiles FileSystem.GetFolder(ThisWorkbook.Path), wsDest, DestColumn
Application.ScreenUpdating = True End Sub
Sub ProcessFiles(ByVal objFolder As Object, ByVal wsDest As Worksheet, ByVal DestColumn As Long) Dim objFile As Object Dim wbSource As Workbook Dim wsSource As Worksheet Dim DestRow As Long
' Пройтись по каждому файлу в каталоге For Each objFile In objFolder.Files If InStr(objFile.Name, "+КС-3.xlsx") > 0 Then ' Открытие исходную рабочую книгу Set wbSource = Workbooks.Open(objFile.Path) ' Установка исходного рабочего листа Set wsSource = wbSource.Sheets(1) ' Данные будут скопированы на первый лист
' Найти следующую доступную строку на листе DestRow = wsDest.Cells(wsDest.Rows.Count, DestColumn).End(xlUp).Row + 1
' Копировать значение из ячейки A10 исходного листа в следующую доступную строку на целевом листе wsDest.Cells(DestRow, 1).Value = wsSource.Range("A10").Value
' Копировать значение из I36 исходного листа в следующую доступную строку на целевом листе. wsDest.Cells(DestRow, DestColumn).Value = wsSource.Range("I36").Value
' Закрыть исходную книгу без сохранения изменений wbSource.Close SaveChanges:=False End If Next objFile
' Рекурсивная обработка подкаталогов For Each objFolder In objFolder.SubFolders ProcessFiles objFolder, wsDest, DestColumn Next objFolder End Sub
Результат работы скрипта - созданная таблица:
Половина работы сделана - адреса и суммы уже автоматически собраны в одну таблицу.
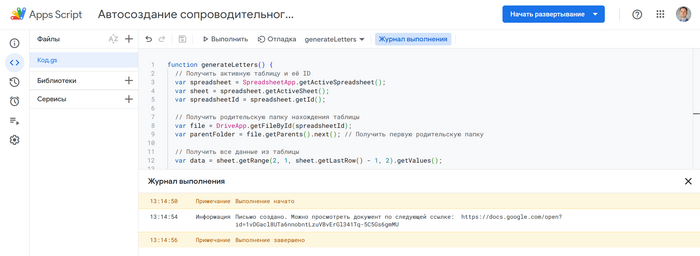
Часть 2: Google Apps Script
Google Apps Script – это язык программирования, созданный компанией Google для работы с различными сервисами Google, такими как Gmail, Calendar, Drive и другими. Он позволяет разработчикам создавать скрипты, которые могут автоматически выполнять определенные задачи например, управление файлами, создание отчётов - на самом деле практически любые действия.
Как сделать генерацию сопроводительного письма по готовой таблице средствами VBA я не стал разбираться, потому что был хорошо знаком с подобным решением для гугл скриптов.
Так что я перенёс таблицу из Экселя в Гугл таблицу и написал скрипт, который генерирует текст письма по простому шаблону:
function generateLetters() { // https://pikabu. ru/story/kak_ya_pri_pomoshchi_dvukh_skriptov_smog_avtomaticheski_sgenerirovat_opis_dokumentov_dlya_700_stranits_11812093
// Получить активную таблицу и её ID var spreadsheet = SpreadsheetApp.getActiveSpreadsheet(); var sheet = spreadsheet.getActiveSheet(); var spreadsheetId = spreadsheet.getId();
// Получить родительскую папку нахождения таблицы var file = DriveApp.getFileById(spreadsheetId); var parentFolder = file.getParents().next(); // Получить родительскую папку
// Получить все данные из таблицы var data = sheet.getRange(2, 1, sheet.getLastRow() - 1, 2).getValues();
// Создать новый Google Документ в той же папке, что и таблица var doc = DocumentApp.create('Автосозданое сопроводительное письмо'); var docFile = DriveApp.getFileById(doc.getId()); parentFolder.addFile(docFile); // Добавить документ в родительскую папку
var body = doc.getBody();
// Обработать каждую строку в таблице for (var i = 0; i < data.length; i++) { var Description = data[i][0]; // Колонка A (описание) var price = data[i][1]; // Колонка B (цена)
// Добавить описание в виде параграфа var paragraph = body.appendParagraph(''); paragraph.appendText((i + 1) + ". ").setBold(true); paragraph.appendText(Description + ":");
// Создать маркированный список для каждого документа body.appendListItem("Справка КС-3 на сумму " + price + " руб. - 2 экз."); body.appendListItem("Акт приемки законченного строительством ХХХХХХХ - 1 экз."); body.appendListItem("Акт выполненных работ – 2 экз."); body.appendListItem("ЛСР - 2 экз."); body.appendListItem("ЛСР НЦС - 2 экз."); body.appendListItem("Единичные расценки стоимости работ на 1 стр - 1 экз."); body.appendListItem("Расчёт затрат на командировочные расходы на 1 стр - 1 экз.");
// Добавить пустую строку между секциями body.appendParagraph(""); }
// Сохранить и закрыть документ doc.saveAndClose();
// Получить URL документа var docUrl = doc.getUrl(); console.log(`Письмо создано. Можно просмотреть документ по следующей ссылке: ${docUrl}`); }
Процесс генерации занял 4 секунды:
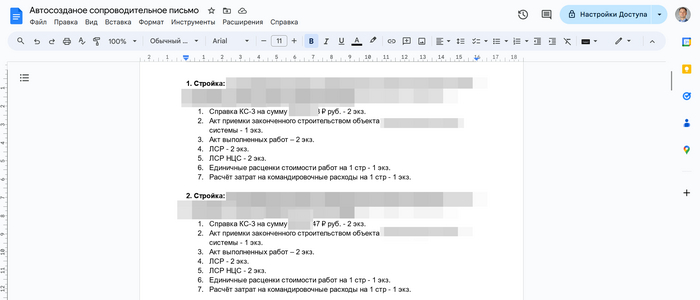
После этого проверил цель всей работы - созданное сопроводительное письмо и сразу с форматированием:
Итоги
В целом при помощи двух программных «костылей» смог автоматически генерировать опись документов для любой толщины папки и любого количества файлов.
Home Assistant позиционирует себя как локальную систему. Но я столкнулся с ситуацией, когда локальная функция (Samba) не работает из-за облачного сбоя. При этом я вообще не использую облако. В статье описываю как обошёл эту проблему за 5 минут, когда за день разобрался в причине.
Мне очень нравится Home Assistant как система управления умным домом, потому что она позволяет не зависеть от облаков и от падений интернета. Это не просто слова - с 2017 года я использую умный дом в обычной двухкомнатной хрущевке, и в основном всё работает. Но это скорее тестовый полигон для меня - я сам там не живу и поэтому очень ценю то что Home Assistant можно настроить один раз и если не обновлять, то несколько лет всё может спокойно проработать. А на этих новогодних каникулах у меня было время и я решил полностью обновить все дополнения и прошивки. Как оказалось зря - паранойя безопасности ломает определение Home Assistant как автономного сервиса, который можно использовать локально.
В первых числах января 2026 решил удаленно обновить все зависимости - за несколько раз всё обновилось, но мне ещё понадобилось включить дополнение Samba share, чтобы из под Windows проверить пару конфигов, которые не хотели работать. А я отключил Samba share ещё год назад. Удаленно не смог включить - всё какая-то ошибка вылазила, хотя все остальные компоненты работают. Пришлось ехать на квартиру и думал что может быть Raspberry Pi 3 2015 года уже старая стала или флешка сдохла. У меня было ещё несколько запасных - прихватил и чистую флешку и новый микрокомпьютер 2017 года и новый блок питания.
"Стенд проверки"
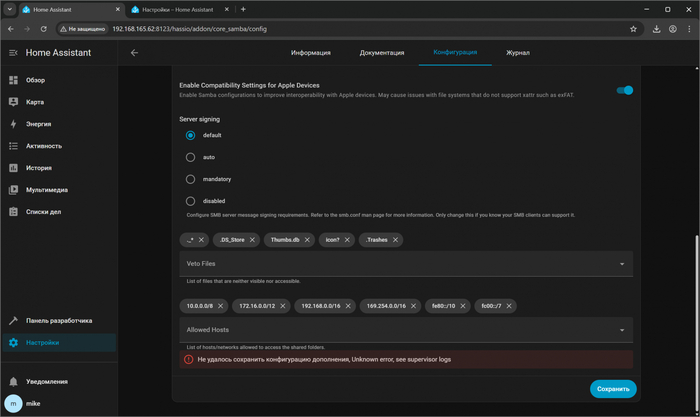
Поставил чистую систему - в 2026 году это происходит через Raspberry Pi Imager, хочу с Windows компьютера подключиться, а там та же ошибка Не удалось сохранить конфигурацию дополнения, Unknown error, see supervisor logs. И непонятно из-за чего.
Ошибка Home Assistant Не удалось сохранить конфигурацию дополнения, Unknown error, see supervisor logs
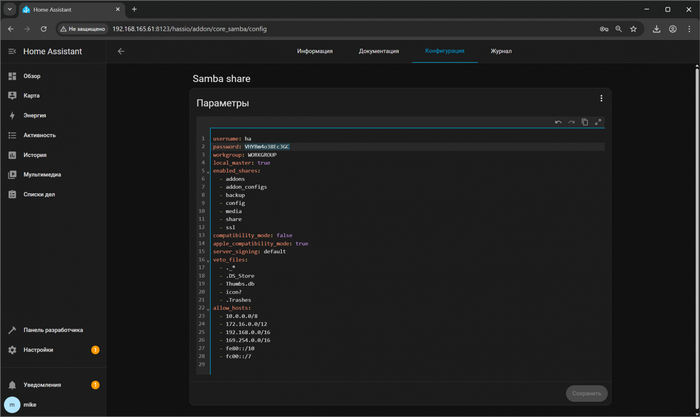
Только в логах на чистой системе подробно рассмотрел что WARNING (MainThread) [supervisor.utils.pwned] Can’t fetch HIBP data: Timeout
Стал разбираться и оказалось что Home Assistant абсолютно все пароли проверяет на скомпромитированность через онлайн сервис, а поскольку мы в России, то этот сервис не даёт ответа видимо из-за санкций или политики, а в интерфейсе ничего внятного не пишет - просто неизвестная ошибка.
И я в своём полностью локальном Home Assistant не могу к нему по локальной сети подключиться из-за того что этот онлайн сервис HIBP не отвечает. Сервис HIBP (Have I Been Pwned) проверяет были ли заново создаваемые пароли в утечках данных.
Но какая-то нестыковка кажется с заявленной полной локальностью Home Assistant?
Home Assistant пользуется этим сервисом и это нельзя отключить для проверки безопасности паролей. Но я даже не знал что такая проверка есть, а у сервиса проблемы с доступностью в России из-за санкций или Роскомнадзора, что вызывает ошибки и блокирует работу всей домашней системы.
Поскольку у меня уже был физический доступ к SD карте - раз я приехал на удаленную квартиру, на которой установлен Home Assistant, то решил через физическое подключение к Linux провести все манипуляции, потому что функция PwnedConnectivityError блокирует абсолютно всё.
SD карта, подключенная к Linux
Нашёл проблему в файле pwned.py, он файл лежит внутри контейнера Supervisor, в моём случае по адресу admin:///media/mike/hassos-data/docker/overlay2/0e05ec32ffef35caed1b7184eefcfdda5eb1a35ad60e68e5d14f3a73996b18ea/diff/usr/src/supervisor/supervisor/utils.
Картридер в Ubuntu
Но у вас будет другой путь, надо искать внутри внутри контейнера Supervisor: /usr/src/supervisor/supervisor/utils/pwned.py
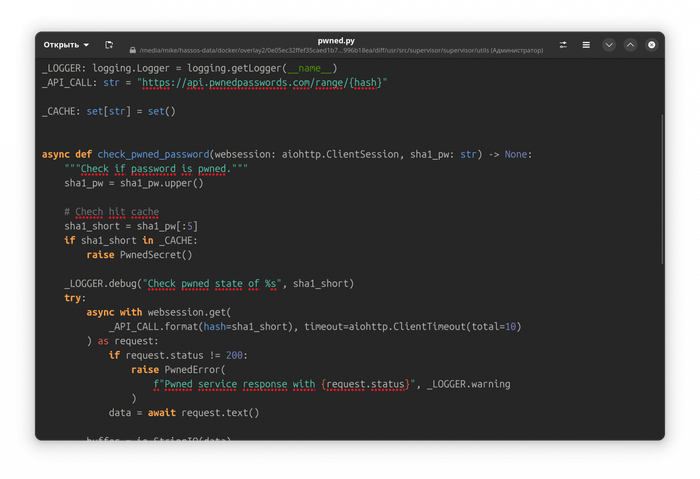
async def check_pwned_password(websession: aiohttp.ClientSession, sha1_pw: str) -> None: """Check if password is pwned.""" sha1_pw = sha1_pw.upper()
# Chech hit cache sha1_short = sha1_pw[:5] if sha1_short in _CACHE: raise PwnedSecret()
_LOGGER.debug("Check pwned state of %s", sha1_short) try: async with websession.get( _API_CALL.format(hash=sha1_short), timeout=aiohttp.ClientTimeout(total=10) ) as request: if request.status != 200: raise PwnedError( f"Pwned service response with {request.status}", _LOGGER.warning ) data = await request.text()
buffer = io.StringIO(data) for line in buffer: if not sha1_pw.endswith(line.split(":")[0]): continue _CACHE.add(sha1_short) raise PwnedSecret()
except (aiohttp.ClientError, TimeoutError) as err: raise PwnedConnectivityError( f"Can't fetch HIBP data: {str(err) or 'Timeout'}", _LOGGER.warning ) from err
async def check_pwned_password(websession: aiohttp.ClientSession, sha1_pw: str) -> None: """Check if password is pwned.""" return None
""" sha1_pw = sha1_pw.upper()
# Chech hit cache sha1_short = sha1_pw[:5] if sha1_short in _CACHE: raise PwnedSecret()
_LOGGER.debug("Check pwned state of %s", sha1_short) try: async with websession.get( _API_CALL.format(hash=sha1_short), timeout=aiohttp.ClientTimeout(total=10) ) as request: if request.status != 200: raise PwnedError( f"Pwned service response with {request.status}", _LOGGER.warning ) data = await request.text()
buffer = io.StringIO(data) for line in buffer: if not sha1_pw.endswith(line.split(":")[0]): continue _CACHE.add(sha1_short) raise PwnedSecret()
except (aiohttp.ClientError, TimeoutError) as err: raise PwnedConnectivityError( f"Can't fetch HIBP data: {str(err) or 'Timeout'}", _LOGGER.warning ) from err """
После того как внёс изменения и вставил SD карту обратно в Raspberry Pi все пароли стало успешно сохранять и работоспособность полностью восстановилась.
Работоспособность сохранения паролей восстановилась
Мне кажется подобные решения очень сильно бьют по новичкам, которым реально сложно разобраться в подобных системах и ещё больше вопросов вызывает то что Home Assistant всегда был полностью локальной автономной системой, которую можно было настроить даже на даче и тут вылазит такая фишка.
Вообще мне кажется что стремление к безопасности — это хорошо, но вот делать зависимость от внешнего API для базовых локальных функций — это архитектурная ошибка.
Каждый день мимо двери моего подъезда проходят десятки людей. Иногда это знакомые соседи, но чаще - курьеры или случайные гости.
Домофонная камера всё записывает, но вручную пересматривать часы видео бессмысленно. Мне стало интересно: можно ли разово прогнать архив записей через алгоритмы компьютерного зрения и посмотреть, как быстро GPU справится с такой задачей.
Это был чисто экспериментальный проект: не «система слежки», а тест производительности и возможностей CUDA в связке с dlib и face_recognition.
На словах всё выглядело просто, а на деле пришлось пройти целый квест из несовместимых программ, капризных драйверов и упрямой библиотеки распознавания лиц. Но в итоге я собрал рабочее окружение и хочу поделиться опытом - возможно, это поможет тем, кто столкнётся с похожими проблемами.
Часть 1: Битва за dlib с CUDA-ускорением на Ubuntu
dlib - это популярная библиотека на Python для компьютерного зрения и машинного обучения, особенно известная своим модулем распознавания лиц. Она умеет искать и сравнивать лица. Однако «из коробки» через pip она работает только на CPU, что для задач с большим объёмом данных ужасно медленно.
У меня видеокарта NVIDIA GeForce RTX 5060 Ti 16 ГБ и здесь на помощь приходит CUDA-ускорение - технология NVIDIA, позволяющая выполнять вычисления на графическом процессоре видеокарты. Для распознавания лиц это критично: обработка видео с несколькими тысячами кадров на CPU может занять часы, тогда как с GPU - минуты. CUDA задействует сотни параллельных потоков, что особенно эффективно для матричных операций и свёрточных сетей, лежащих в основе face_recognition.
Именно поэтому моя цель была не просто «запустить dlib», а сделать это с полной поддержкой GPU.
Эта часть рассказывает о том, как простая, на первый взгляд, задача превратилась в двухдневную борьбу с зависимостями, компиляторами и версиями ПО.
Расписываю по шагам - может быть кто-то найдёт эту статью через поиск и ему пригодится.
1. Исходная точка и первая проблема: неподходящая версия Python
Задача: установить face_recognition и его зависимость dlib на свежую Ubuntu 25.04.
Предпринятый шаг: попытка установки в системный Python 3.13.
Результат: ошибка импорта face_recognition_models. Стало ясно, что самые свежие версии Python часто несовместимы с библиотеками для Data Science, которые обновляются медленнее.
Решение: переход на pyenv для установки более стабильной и проверенной версии Python 3.11.9. Это был первый правильный шаг, решивший проблему с совместимостью на уровне Python.
2. Вторая проблема: dlib работает, но только на CPU
Предпринятый шаг: после настройки pyenv и установки зависимостей (numpy, opencv-python и т.д.), dlib и face_recognition успешно установились через pip.
Результат: скрипт анализа видео работал ужасно медленно (несколько минут на одно видео). Мониторинг через nvidia-smi показал 0% загрузки GPU.
Диагноз: стандартная установка dlib через pip скачивает готовый бинарный пакет ("wheel"), который собран без поддержки CUDA для максимальной совместимости. Чтобы задействовать GPU, dlib нужно компилировать из исходного кода прямо на моей машине.
3. Третья, главная проблема: конфликт компиляторов CUDA и GCC
Предпринятый шаг: попытка скомпилировать dlib из исходников с флагом -DDLIB_USE_CUDA=1.
Результат: сборка провалилась с ошибкой. Анализ логов показал, что cmake находит CUDA Toolkit 12.6, но не может скомпилировать тестовый CUDA-проект. Ключевая ошибка: error: exception specification is incompatible with that of previous function "cospi"
Диагноз: мой системный компилятор GCC 13.3.0 (стандартный для Ubuntu 25.04) был несовместим с CUDA Toolkit 12.6. Новые версии GCC вносят изменения, которые ломают сборку с более старыми версиями CUDA.
4. Попытки решения конфликта компиляторов
Шаг №1: установка совместимого компилятора. Я установил gcc-12 и g++-12, которые гарантированно работают с CUDA 12.x.
Шаг №2: ручная сборка с указанием компилятора. Я пытался собрать dlib вручную, явно указав cmake использовать gcc-12:
Результат: та же ошибка компиляции. cmake, несмотря на флаги, по какой-то причине продолжал использовать системные заголовочные файлы, конфликтующие с CUDA.
Шаг №3: продвинутый обходной маневр (wrapper). Я создал специальный скрипт-обертку nvcc_wrapper.sh, который должен был принудительно "подсовывать" nvcc (компилятору NVIDIA) нужные флаги и использовать gcc-12. Результат: снова неудача. Ошибка 4 errors detected in the compilation... осталась, что указывало на фундаментальную несовместимость окружения.
Капитуляция перед реальностью Несмотря на все предпринятые шаги - использование pyenv, установку совместимого компилятора GCC-12 и даже создание wrapper-скриптов - dlib так и не удалось скомпилировать с поддержкой CUDA на Ubuntu 25.04.
Похоже проблема была не в моих действиях, а в самой операционной системе. Использование не-LTS релиза Ubuntu для серьезной разработки с проприетарными драйверами и библиотеками (как CUDA) - это путь, полный боли и страданий.
Принял решение установить Ubuntu 24.04 LTS, для которой NVIDIA предоставляет официальную поддержку CUDA Toolkit 12.9 Update 1.
Часть 2: чистый лист и работающий рецепт
Установил Ubuntu 24.04 LTS - систему с долгосрочной поддержкой, для которой NVIDIA предоставляет официальный CUDA Toolkit и драйверы. Это был шаг назад, чтобы сделать два вперёд.
Но даже на чистой системе путь не был устлан розами. Первые попытки установки нужной версии Python через apt провалились (в репозиториях Noble Numbat её просто не оказалось), что вернуло меня к использованию pyenv. После нескольких итераций, проб и ошибок, включая установку CUDA Toolkit и отдельно cuDNN (библиотеки для нейросетей, без которой dlib не видит CUDA), родился финальный, работающий рецепт.
Проверка pyenv. Скрипт начинается с проверки наличия pyenv. Это позволяет использовать нужную версию Python (3.11.9), а не системную, избегая конфликтов.
Установка системных библиотек. Для компиляции dlib из исходного кода необходимы инструменты сборки (build-essential, cmake) и библиотеки для работы с математикой и изображениями (libopenblas-dev, libjpeg-dev). Скрипт автоматически их устанавливает.
Важно: скрипт предполагает, что CUDA Toolkit и отдельно cuDNN уже установлены по официальным инструкциям NVIDIA для вашей системы - они по ссылкам.
Создание чистого venv. Создаем изолированное виртуальное окружение, чтобы зависимости нашего проекта не конфликтовали с системными. Скрипт удаляет старое окружение, если оно существует, для гарантированно чистой установки.
Ключевой момент: установка dlib. Это сердце всего процесса. Команда pip install dlib с особыми флагами:
--no-binary :all: — этот флаг принудительно запрещает pip скачивать готовый, заранее скомпилированный пакет (wheel). Он заставляет pip скачать исходный код dlib и начать компиляцию прямо на вашей машине.
--config-settings="cmake.args=-DDLIB_USE_CUDA=1" — а это инструкция для компилятора cmake. Мы передаем ему флаг, который говорит: «При сборке, пожалуйста, включи поддержку CUDA».
Именно эта комбинация заставляет dlib собраться с поддержкой GPU на Ubuntu 24.04 LTS чтобы использовать видеокарту, а не в стандартном CPU-only варианте.
# --- Проверка наличия pyenv --- if ! command -v pyenv &> /dev/null; then echo -e "\n\033[1;31m[ERROR] pyenv не найден. Установи pyenv перед запуском.\033[0m" exit 1 fi
echo -e "\n[INFO] Выбор версии Python $PYTHON_VERSION_TARGET через pyenv..." pyenv local $PYTHON_VERSION_TARGET echo "[INFO] Текущая версия Python: $(python --version)"
# --- Проверка системных библиотек --- echo -e "\n[INFO] Проверка и установка системных библиотек для dlib..." sudo apt update sudo apt install -y build-essential cmake libopenblas-dev liblapack-dev libjpeg-dev git
# --- Очистка и создание виртуального окружения --- if [ -d "$VENV_DIR" ]; then echo "[INFO] Удаление старого виртуального окружения '$VENV_DIR'..." rm -rf "$VENV_DIR" fi
echo "[INFO] Создание виртуального окружения '$VENV_DIR'..." python -m venv "$VENV_DIR"
Камера, смотрящая на лифтовой холл. Фото из интернета
После победы над зависимостями у меня есть полностью рабочее окружение с CUDA-ускорением. Настало время применить его к реальным данным. Мои исходные данные - это архив видеозаписей с двух IP-камер, которые пишут видео на сетевой накопитель Synology Surveillance Station (есть аналоги). Для приватности я заменю реальные имена камер на условные:
podiezd_obshiy\ - камера, смотрящая на лифтовой холл.
dver_v_podiezd\ - камера из домофона, направленная на улицу.
Внутри каждой папки видео отсортированы по каталогам с датами в формате ГГГГММДД с суффиксом AM или PM. Сами файлы имеют информативные имена, из которых легко извлечь дату и время записи: podiezd_obshiy-20250817-160150-....mp4.
Камера из домофона, направленная на улицу. Здесь качество гораздо лучше потому что камера цифровая, а не аналоговая как у меня из квартирного домофона. Это фото из интернета
Я использовал стандартную библиотеку argparse. Она позволяет задавать ключевые параметры прямо из командной строки:
--model: выбор детектора лиц (hog или cnn).
--scale: коэффициент масштабирования кадра. Уменьшение кадра (например, до 0.5) ускоряет обработку, но может пропустить мелкие лица.
--skip-frames: количество пропускаемых кадров. Анализировать каждый кадр избыточно и медленно; достаточно проверять каждый 15-й или 25-й.
Скрипт находит все .mp4 файлы в указанной директории и запускает основной цикл, обрабатывая каждый видеофайл.
1. Детекция лиц: HOG против CNN
face_recognition предлагает два алгоритма детекции: HOG (Histogram of Oriented Gradients) и CNN (Convolutional Neural Network). HOG - классический и очень быстрый метод, отлично работающий на CPU. CNN - это современная нейросетевая модель, гораздо более точная (особенно для лиц в профиль или под углом), но крайне требовательная к ресурсам.
Раз я так боролся за CUDA, выбор очевиден - будем использовать cnn. Это позволит находить лица максимально качественно, не жертвуя скоростью.
2. Уникализация личностей
Как скрипт понимает, что лицо на двух разных видео принадлежит одному и тому же человеку? Он преобразует каждое найденное лицо в face_encoding - вектор из 128 чисел, своего рода уникальный «цифровой отпечаток».
Когда появляется новое лицо, его «отпечаток» сравнивается со всеми ранее сохраненными. Сравнение происходит с определенным допуском (tolerance). Установил его равным 0.6 - это золотая середина, которая позволяет не путать разных людей, но и узнавать одного и того же человека при разном освещении или угле съемки.
3. Умный подсчет: один файл - один голос
Простая логика подсчета привела бы к абсурдным результатам: если курьер провел у двери 30 секунд, его лицо могло бы быть засчитано 50 раз в одном видео. Чтобы этого избежать, я ввел простое, но эффективное правило: считать каждое уникальное лицо только один раз за файл.
4. Создание красивых иконок
Чтобы в кадр попадала вся голова с прической и частью шеи, я добавил в функцию create_thumbnail логику с отступами. Она берет размер найденного лица и увеличивает область кадрирования на 50% по вертикали и горизонтали. Так превью в отчете выглядят гораздо лучше и живее.
5. Генерация наглядного HTML-отчета
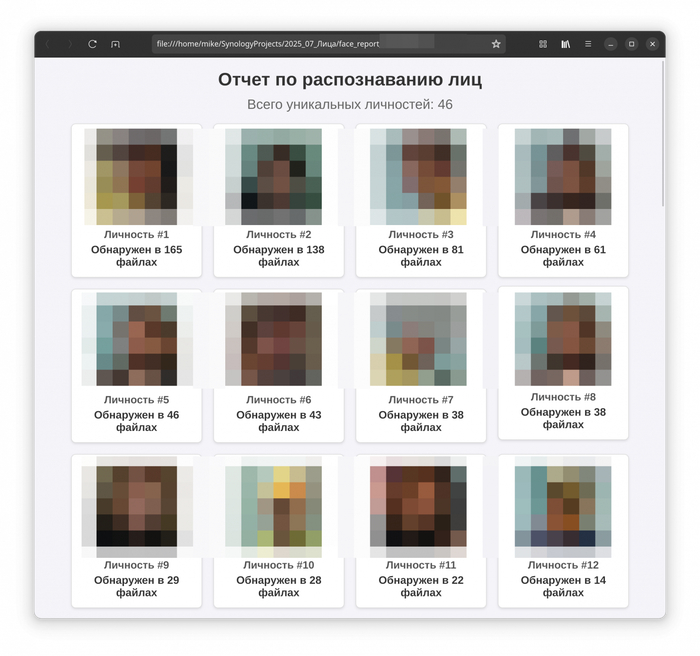
Финальный штрих - вся собранная информация (иконки, количество появлений) упаковывается в красивый и понятный HTML-отчет. Никаких сложных фреймворков: с помощью f-string и небольшого блока CSS генерируется страница, на которой все уникальные личности в этом эксперименте отсортированы по частоте появлений.
Часть 4: результаты и выводы
Для эксперимента я посчитал уникальных людей в выборке. Скрипт я запускал разово, отдельно для каждой камеры - это не постоянно работающий сервис, а скорее любопытная исследовательская игрушка.
Результаты оказались наглядными, но и показали пределы технологии. Качество распознавания напрямую зависит от исходного видео: камера домофона с узким углом и посредственным сенсором даёт мыльную картинку, на которой детали лица часто теряются. Для сравнения, камера 2,8 мм 4 Мп в лифтовом холле (широкоугольный объектив и матрица с разрешением 2560×1440) выдаёт значительно более чёткие кадры - глаза, контуры лица и текстура кожи читаются лучше, а значит, алгоритм реже ошибается.
Но и здесь есть нюанс: один и тот же человек в куртке и без неё, в кепке или с распущенными волосами, зачастую определяется как разные личности - видимо надо где-то крутить настройки. Поэтому цифры в отчёте стоит воспринимать не как абсолютную истину, а как любопытную статистику, показывающую общее движение людей, а не точный учёт.
Заключение
От простой идеи - «разово прогнать архив записей через алгоритмы компьютерного зрения и посмотреть, как быстро GPU справится с такой задачей» - я прошёл путь через череду технических ловушек: несовместимые версии Python, упёртый dlib, капризы CUDA и GCC.
К тому же это не сервис, а исследовательская проверка возможностей GPU.
Идея отказаться от использования Яндекс Алисы в системе умного дома возникла у меня после новости о принятии Госдумой законопроекта, касающегося штрафов за поиск и доступ к экстремистским материалам в интернете. Казалось бы, при чём тут голосовой помощник? Однако Яндекс входит в реестр организаторов распространения информации, что означает определённые юридические и технические обязательства по хранению и передаче данных.
Хотя я не ищу ничего, выходящего за рамки интересов приколов на Пикабу, желание иметь полностью автономный, локально работающий умный дом - без зависимости от интернета и облачных сервисов - стало для меня ещё актуальнее.
Тем более что сейчас единственным слабым звеном в моём умном доме остается Яндекс Алиса - которая требует постоянного интернет-соединения даже для выполнения простейших команд управления локальными устройствами.
В этой статье я расскажу, как и на что планирую заменить Алису, чтобы сохранить привычный голосовой контроль, но без сторонних подключений и рисков для приватности.
Конфигурация моего умного дома: чем будем управлять
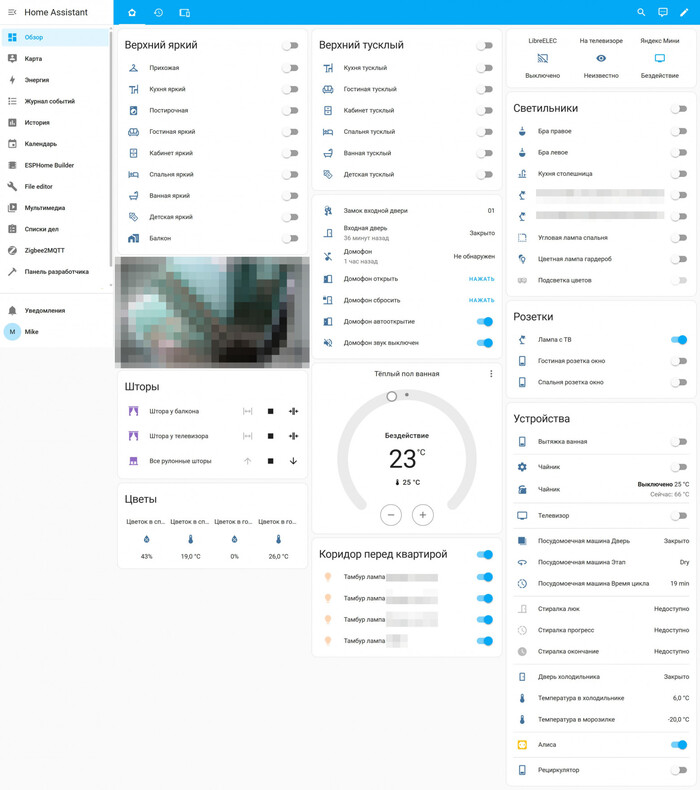
Мой Home Assistant в "человеко читаемом" виде
Мой умный дом строился с прицелом на автономность, надежность и открытые стандарты - так, чтобы управление работало даже при полном отсутствии интернета. На данный момент архитектура системы выглядит следующим образом.
Мозг системы: центральный контроллер - это Raspberry Pi 4 Model B с 2 ГБ оперативной памяти, установлен в 2022 году. На него установлена Home Assistant OS - полноценная операционная система, заточенная под локальное управление умным домом - подробнее описывал в другой статье. Вся логика автоматизаций, интерфейс управления и интеграции работают исключительно локально, без необходимости в сторонних облаках.
Извиняюсь за скриншот, но с прокруткой только PicPick под Windows умеет делать - и вот результат :(
Протоколы связи: большая часть устройств использует Wi-Fi через прошивку ESPHome - это 17 модулей: от простых температурных датчиков до управляющих реле в светильниках.
Ключевую нагрузку по управлению берет на себя Zigbee-сеть: 42 устройства, объединённые с помощью USB-донгла Sonoff Zigbee 3.0 Plus и интеграции Zigbee2MQTT. Это датчики, реле освещения и другие элементы.
Все эти устройства уже управляются локально, без облачных зависимостей - кроме стиралки Bosch, купленной ещё в 2022 году.
Теоретический минимум: из чего состоит локальный голосовой помощник
Однако чтобы убрать колонку Яндекса и заменить Алису на полностью автономного голосового помощника, нужно понять, из каких компонентов он состоит. Это не “одна программа”, а целая цепочка взаимодействующих модулей, каждый из которых выполняет свою задачу:
ESP32-S3-BOX-3. Фото из интернета
Микрофон и динамик («Уши и рот» системы) - это устройства, которые слышат пользователя. Не должно быть колхоза из датчиков. Устройство должно выглядеть современно и не портить интерьер.
В моем случае я присматриваюсь к двум: компактный M5Stack ATOM Echo для комнат и более продвинутый ESP32-S3-BOX для гостиной.
Официальный комплект для разработки умных динамиков ATOM Echo M5Stack
Они захватывают звук и отправляют его на сервер для дальнейшей обработки.
100% новый ESP32-S3-BOX-3 ESP32-S3-BOX-3B модуль комплекта разработки приложений AIOT 2,4 ГГц Wi-Fi + Bluetooth 5
Wake Word движок: нужен, чтобы система слушала нас постоянно, но реагировала только по ключевой фразе (например, «Привет, пирожок!»). Используем OpenWakeWord - полностью локальный и настраиваемый.
Speech-to-Text (STT): этот модуль превращает речь в текст. Здесь смотрю на Whisper от OpenAI - пишут что это один из самых точных и устойчивых к шуму движков, работающий прямо на локальном сервере. Про его выбор чуть ниже.
Распознавание намерений (Intent Recognition): после получения текста нужно понять смысл команды. Эта задача ложится на встроенный в Home Assistant механизм Assist, который сопоставляет текст с действиями и сущностями в системе.
Text-to-Speech (TTS): чтобы система могла отвечать голосом, нужен синтез речи. Я планирую использовать Piper - современный, быстрый, качественный, легко интегрируется как Add-on в HA. Как вариант RHVoice - тоже отличный вариант, но Piper сейчас является де-факто стандартом в сообществе HA за простоту и качество.
Wyoming Protocol: связующее звено. Простой, но мощный протокол, через который все эти модули общаются между собой и с Home Assistant.
Речь в текст: почему именно такой стек?
Давайте будем честны: моя Raspberry Pi 4 с 2 ГБ памяти - отличный мозг для автоматизации, но для тяжелых вычислений, таких как распознавание речи в реальном времени, её мощности не хватит.
Поэтому, помимо «ушей» в виде ESP32-S3-BOX и M5Stack ATOM Echo, в систему придется докупить отдельный мини-ПК. Это может быть недорогой китайский NUC-подобный компьютер, который возьмет на себя самую ресурсоемкую задачу - преобразование речи в текст (Speech-to-Text (STT)).
Самый главный вопрос - что на нем будет крутиться? Выбор STT-движка определяет, насколько умным и гибким будет наш ассистент.
Speech-to-Phrase (от Open Home Foundation): это самый легковесный вариант. Он не распознает речь, а просто ищет точное совпадение с заранее заданными фразами. К тому же это не конкретный движок, а концепция pipeline в HA. По умолчанию он использует тот же Whisper, но его самую легкую модель, чтобы хоть как-то работать на слабых устройствах вроде RPi. Плюс: минимальные требования к железу. Минус: абсолютная негибкость. Система поймет «включи свет на кухне», но проигнорирует «сделай на кухне посветлее». Это не интеллект, а поиск по словарю.
Rhasspy: ветеран мира локальных ассистентов. Мощный, но сложный в настройке комбайн. Главный аргумент против него сегодня: проект развивается медленнее, чем экосистема Home Assistant. Пока Rhasspy остается монолитной системой, связка Assist + Wyoming-протокол ушла далеко вперед в плане гибкости и интеграции.
Whisper от OpenAI - современный стандарт транскрипции. Понимает естественную речь в свободной форме, работает с русским языком. Различные модели (tiny, base, small, medium) позволяют балансировать между скоростью и качеством. Активно развивается, поддерживается сообществом HA, появляются оптимизированные версии вроде distil-whisper. Это выбор на перспективу.
Как избавится от голосового помощника Алисы
Поскольку я нахожусь в активном поиске оптимального решения и уже закупаюсь компонентами, то буду признателен за ваши комментарии, критику и предложения.
Вариант 1: простой и дешевый
Лично для себя я не рассматриваю этот вариант, однако этот путь подойдёт тем, кто хочет попробовать локальное голосовое управление с минимальными затратами времени и денег. Как раз, чтобы "пощупать" концепцию и понять, насколько она жизнеспособна.
M5Stack ATOM Echo. Микроразмер. Фото из интернета
Или если вы только планируете сделать умный дом - можно изначально заложить более мощное железо - чтобы всё было на одном севере.
Все компоненты - Home Assistant, распознавание речи (STT) и синтез голоса (TTS) - работают прямо на Raspberry Pi. Один микрофон, одна точка входа, минимум зависимости.
То есть:
[M5Stack ATOM Echo] ← Wi-Fi → [Raspberry Pi 4 (HA + STT + TTS)]
Если брать мой случай:
Уже есть: Raspberry Pi 4 (2 ГБ) с установленной Home Assistant OS.
Нужно купить: M5Stack ATOM Echo (примерно 1 400 рублей). Это крошечное устройство с микрофоном, динамиком и Wi-Fi - почти готовый китайский мини-клон Алисы.
Настройка:
Прошивка ATOM Echo: через ESPHome. Готовый YAML-конфиг для голосового ассистента легко найти в официальных примерах.
TTS: Устанавливаем Add-on Piper - быстрый и качественный синтезатор, особенно с голосами на русском.
Плюсы этого решения:
Минимальные вложения - только 1 400 рублей и немного времени.
Простота - всё работает на одном устройстве.
Быстрый старт - можно реализовать за один вечер.
Минусы:
Скорее всего заметная задержка из-за слабого железа.
Нагрузка на Home Assistant - может тормозить работу системы во время STT.
Плохо масштабируется: один микрофон - ещё приёмлимо, но два и больше будут проблемой.
Вариант 2: «правильная» архитектура с заделом на будущее
Это мой приоритетный путь - вынести ресурсоёмкие задачи обработки речи на отдельный сервер, а Raspberry Pi остаётся заниматься только управлением умным домом. Подход масштабируемый, стабильный и в моём случае надеюсь что будет в разы быстрее.
ESP32-S3-BOX. Фото из интернета
Схема сложнее:
[Пользователь]
↓ говорит
[ESP32-S3-BOX / M5Stack ATOM Echo] ← микрофон + wake word ("Привет, пирожок!")
↓ захватывает аудио
(по Wi-Fi)
↓
[Мини-ПК: Whisper STT-сервер]
↓ распознаёт речь в текст (Whisper STT)
↓
[Home Assistant на Raspberry Pi 4]
↓ определяет намерение (Assist)
↓ выполняет команду
↓ (опционально)
[Мини-ПК: Piper TTS]
↓ синтезирует голосовой ответ
(по Wi-Fi)
↓
[ESP32-S3-BOX / M5Stack ATOM Echo] ← динамик
↓ озвучивает ответ
[Пользователь]
Железо:
Уже есть Raspberry Pi 4 (2 ГБ) - Home Assistant, Zigbee, автоматизации.
Примерно 14 т.р.: Mini PC (Intel N100 или N95) - сервер обработки голоса.
Примерно 6 т.р. ESP32-S3-BOX - «умный» ассистент для гостиной.
Примерно 1,4 т.р. M5Stack ATOM Echo - недорогие ассистенты для других комнат.
Сервер обработки голоса (Mini PC): Устанавливаем легкий Linux (Debian/Ubuntu Server), затем - Docker и Docker Compose. В docker-compose.yml разворачиваем сразу три контейнера:
Whisper - для распознавания речи (STT).
Piper - синтез речи (TTS).
OpenWakeWord - «ключевая фраза» для активации.
С мощностями N100 можно использовать модель Whisper уровня small или даже medium, получая более точное и быстрое распознавание речи, чем на Pi.
Настройка Home Assistant: на Raspberry Pi в этом случае не используется голосовых add-on'ов - только интеграция через Wyoming:
Заходим в Настройки → Устройства и службы → Добавить интеграцию.
Добавляем Wyoming Protocol трижды — для каждого из сервисов (Whisper, Piper, WakeWord), указав IP и порты Mini PC.
Создаём Voice Pipeline, выбираем нужные сервисы из выпадающих списков.
Спутники (ESP32-S3-BOX и ATOM Echo): прошиваются через ESPHome. У ESP32-S3-BOX можно задействовать экран: отображать статус («Слушаю», «Думаю», «Выполняю»), добавляя интерактивности.
Плюсы:
Ожидаемая быстрая реакция.
Ожидание распознавания сложных фраз.
Не грузит Home Assistant.
Масштабируемость: добавляем спутники - и всё.
Минусы:
Дороже (нужен Mini PC).
Потребуются базовые навыки Linux и Docker.
Вариант 3: дорого и сложно
Можно полностью избавиться от Raspberry Pi 4 с 2 ГБ памяти и абсолютно всё перевести на новый мощный сервер. RAM видимо выбрать 16-32 ГБ чтобы с запасом на все. Может быть даже купить NVIDIA VRAM 6 ГБ, но это тогда сильно увеличит стоимость и можно будет забыть о безвентиляторности.
Сборка в mini-ITX. Фото из интернета
Можно тоже будет использовать Home Assistant OS или Linux (Ubuntu/Debian) + Docker.
Правда это большая работа - много устройств. Пока склоняюсь к второму варианту.
Заключение: свобода выбора
Переход на локального голосового ассистента - это не просто технический эксперимент, а осознанный шаг к созданию по-настоящему приватного и независимого умного дома.
Первый вариант - это отличная, почти бесплатная возможность «пощупать» технологию и понять ее ограничения. Второй - полноценное решение, которое по скорости и качеству скорее всего не уступит Алисе, при этом полностью оставаясь под контролем. Третий вариант - если есть бюджет.
Все пути ведут к одной цели - избавлению от «облачного рабства». До сентября ещё есть время. А расставание с Алисой может быть не только экологичным, но и очень увлекательным!
У многих есть старые гаджеты которыми уже сложно пользоваться из‑за их возраста, но они до сих пор работают, причём выкинуть их жалко, а дорого уже не продать. У меня так валялся планшет Amazon Fire HD 6 (Ariel), он 2014 года. На досках объявлений такой стоит около тысячи рублей — ищется по фразе «amazon fire планшет».
Первоначально Amazon Fire HD 6 (Ariel) 2014 года выглядел вот так. 1 ГБ ОЗУ, 8 ГБ памяти, экран 6 дюймов
Как‑то раз я увидел в магазине фоторамку и сразу же подумал про этот старый планшет. Но конечно, самое простое было просто купить готовую фоторамку. Или попробовать без всякой перепрошивки воспользоваться Fire Toolbox чтобы получить расширенный контроль над системой. Но FireOS заточена под amazon, а для меня это не актуально.
А ещё мне было интересно не только увеличение скорости от чистого Android вместо FireOS, но и сам процесс перепрошивки, потому что раньше были времена, когда я активно менял прошивки (ROMs) на своем основном телефоне, экспериментировал с ядрами и модами.
Конечно, рационально — это глупость. Но если вы любите ломать железо — вам сюда. И мне снова захотелось пройти этот квест от получения полного доступа через уязвимость до установки чистого Android.
Но! Если вы не уверены — не повторяйте, так как есть риск превращения планшета в кирпич, всё делается на свой риск. Изначально никакие данные не сохраняем - предполагается что планшет уже сброшен до заводских настроек, а нужные данные сохранены.
Подготовка рабочего окружения
Прежде чем препарировать планшет нужно подготовить компьютер. Подойдёт и на Windows, но мне проще было на Ubuntu.
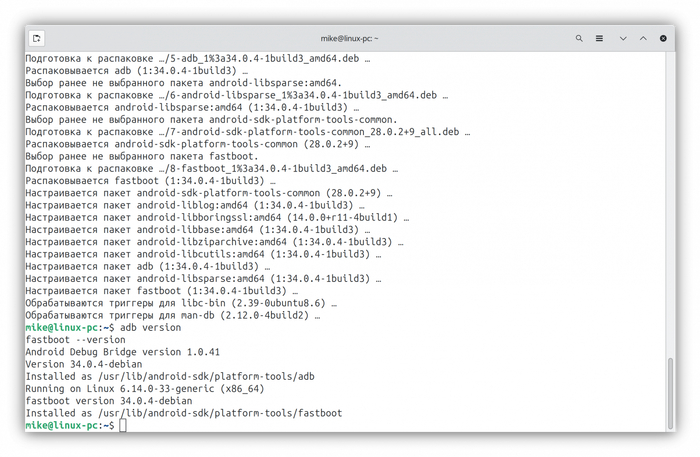
Понадобятся adb и fastboot. В Ubuntu 24.04 установка инструментов:
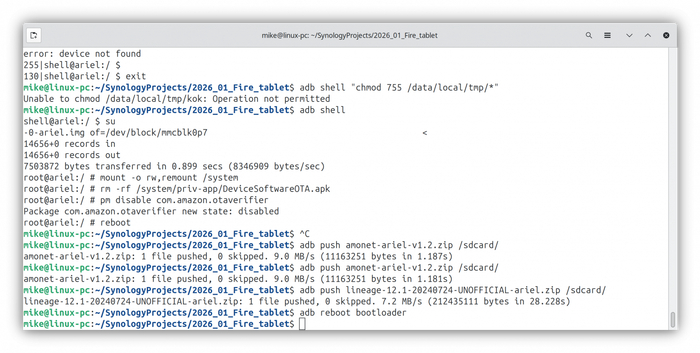
Более новые прошивки блокируют получение полного доступа к планшету получение root‑прав, поэтому надо откатиться на определенную версию, для Amazon Fire HD 6 (Ariel) это версия FireOS 4.5.3.
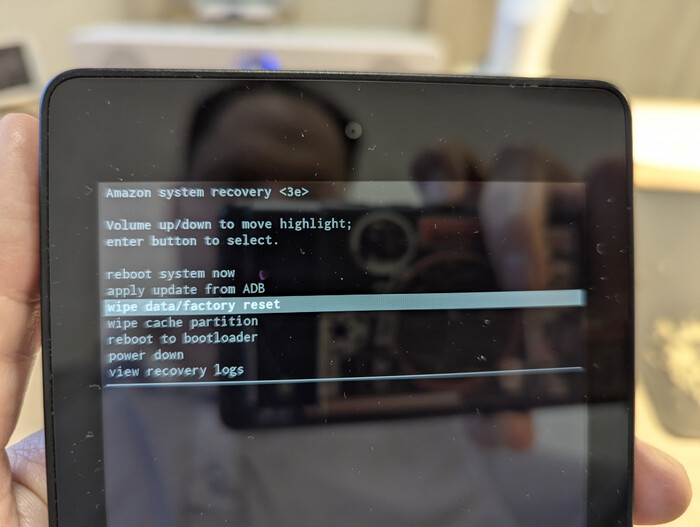
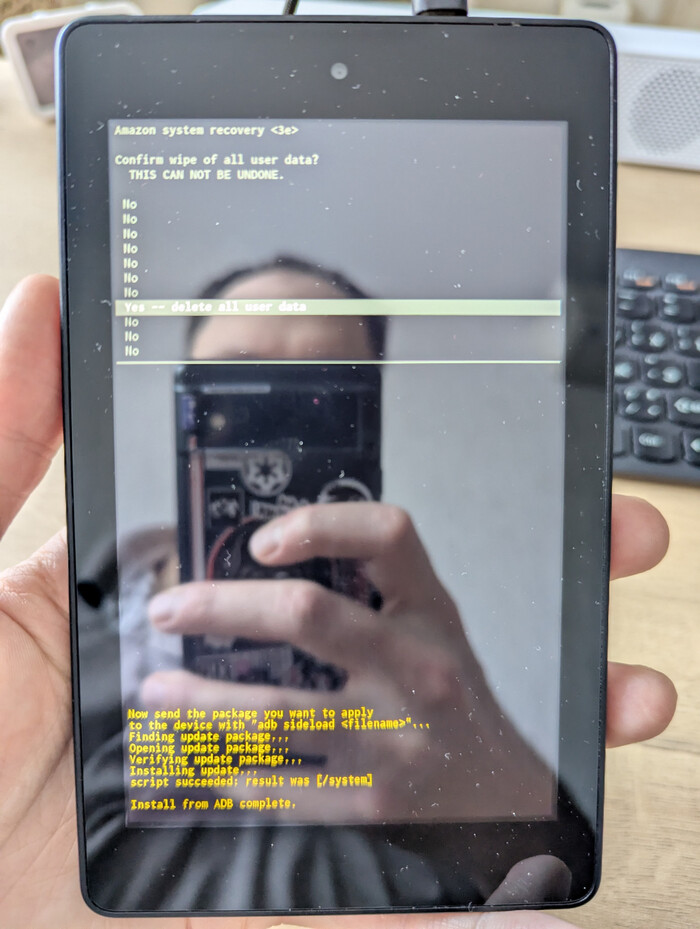
Перезагрузите планшет в режим восстановления — для этого используйте сочетание клавиш увеличить громкость и питание.
Выберите опцию «Применить обновление через ADB» и подключите планшет к компьютеру.
Опция «Применить обновление через ADB» в списке
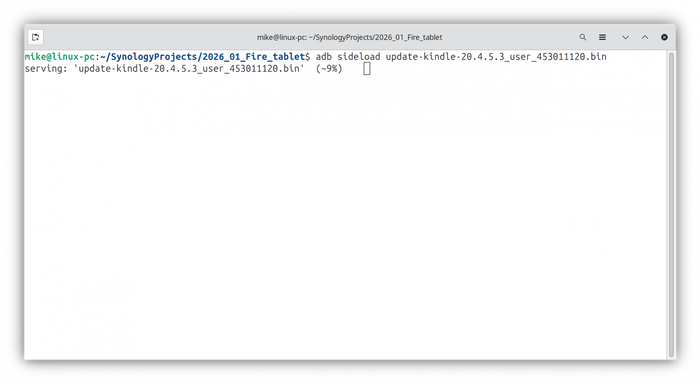
Скачайте update-kindle-20.4.5.3_user_453011120.bin и откройте терминал в той же папке, куда вы загрузили обновление, введите в терминале: adb sideload update-kindle-20.4.5.3_user_453011120.bin
Все файлы (прошивки, amonet, скрипты) лучше искать на профильных ветках XDA или 4PDA по имени файла, так как ссылки со временем умирают.
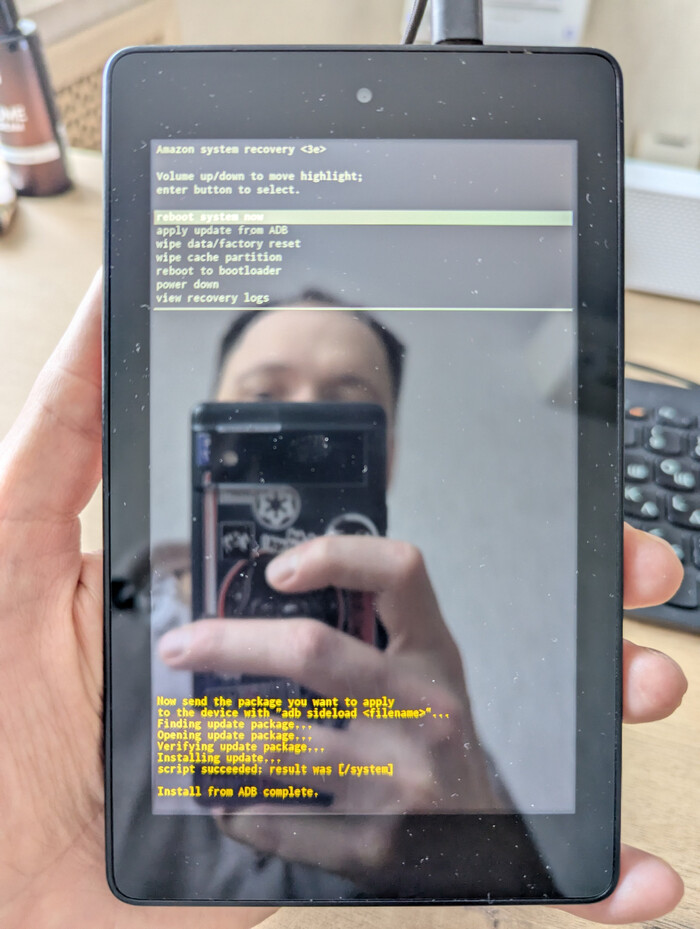
Процесс заливки старой прошивки
Планшет в режиме Recovery с прогрессом загрузки. Главное — не отключайте USB кабель!
Отправка update-kindle-20.4.5.3_user_453011120.bin на планшет
После прошивки делаем wipe data/factory reset и wipe cache partition в том же меню.
wipe data/factory reset
Для сброса надо выбрать правильное подтверждение
При первой загрузке НЕ подключаем Wi-Fi, иначе он снова обновится.
После «обновления» выглядит так:
Скриншот FireOS 4.5.3
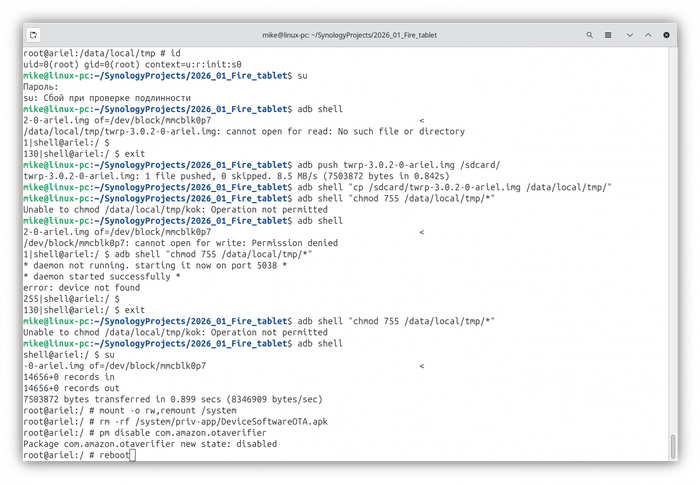
Получение root-прав через метод Dirty Cow
Есть несколько способов получить права суперпользователя, которые позволяют изменять системные файлы и удалять предустановленные приложения, а также дают абсолютный контроль над устройством.
Сделаем всё через скрипты, используя уязвимость ядра.
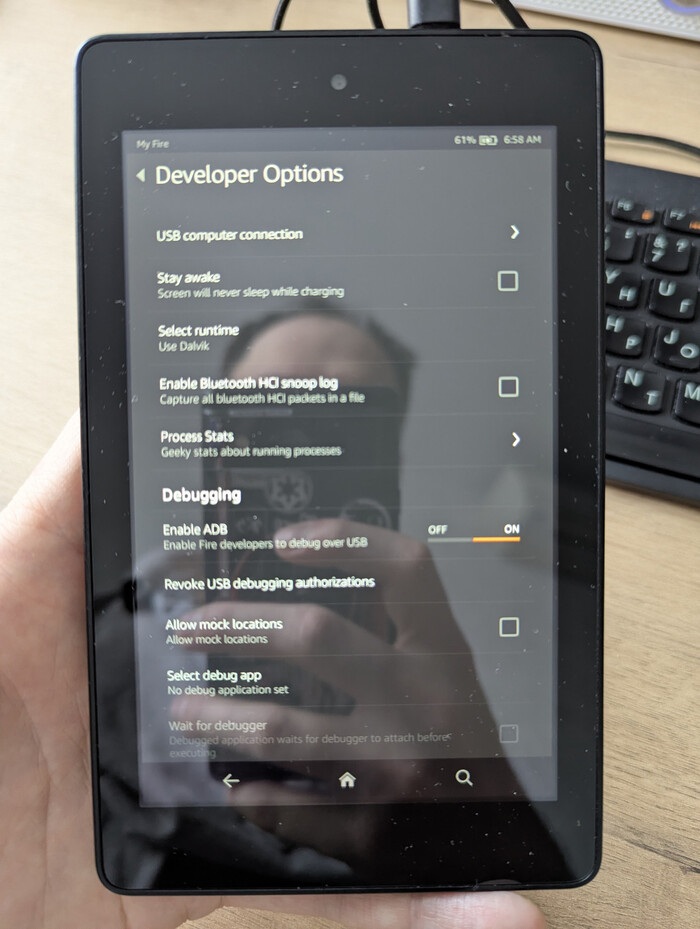
Меню разработчика на FireOS 4.5.3
Включаем на планшете «Отладку по USB» (тыкаем в серийный номер 7 раз).
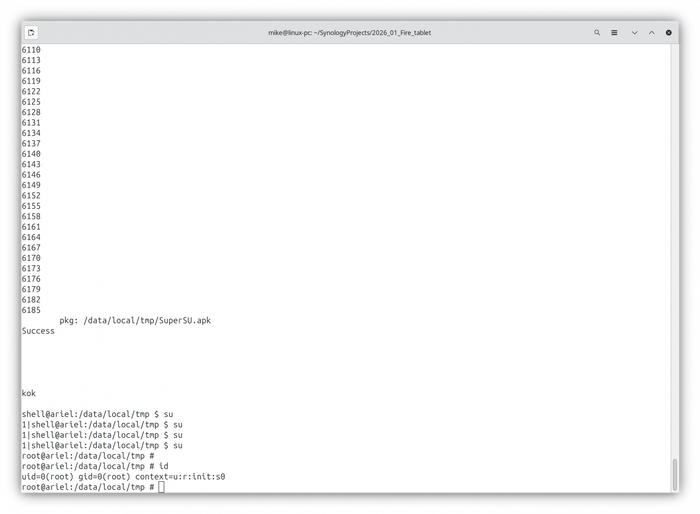
В консоли начнется магия с перебором адресов памяти. Если все прошло успешно, вы увидите заветное Success и kok.
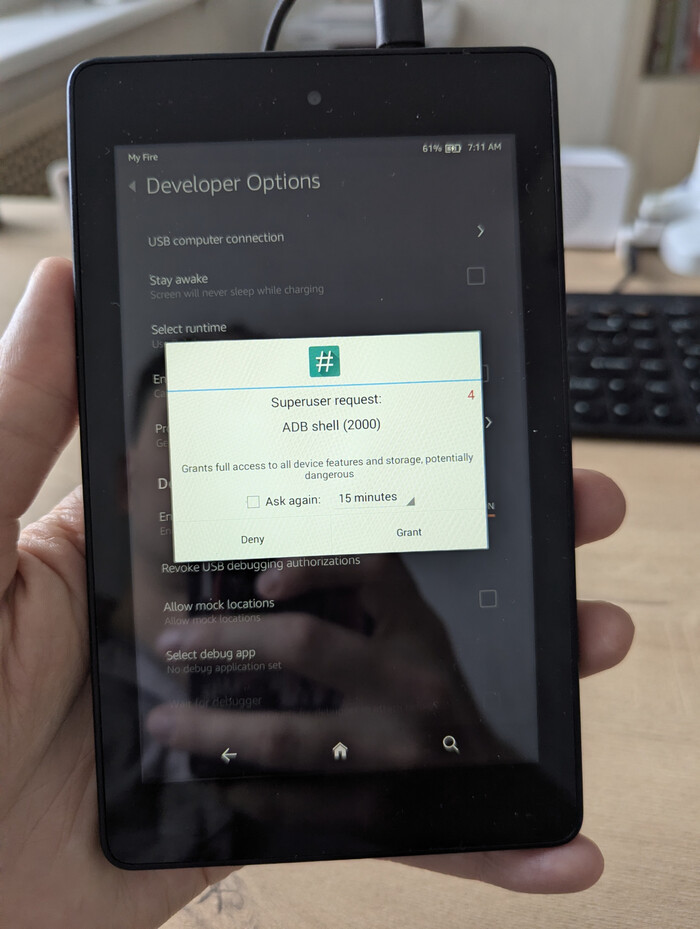
Убедитесь, что всё сработало, получив доступ к корневой оболочке: введя su.
Должно появиться всплывающее окно SuperSU, указывающее на то, что ADB запрашивает права суперпользователя. Просто подтвердите этот запрос и убедитесь, что символ $ изменился на # в консоли (скриншот чуть ниже).
Всплывающее окно SuperSU
Dirty Cow эксплойт сработал
SuperSU в списке приложений FireOS 4.5.3
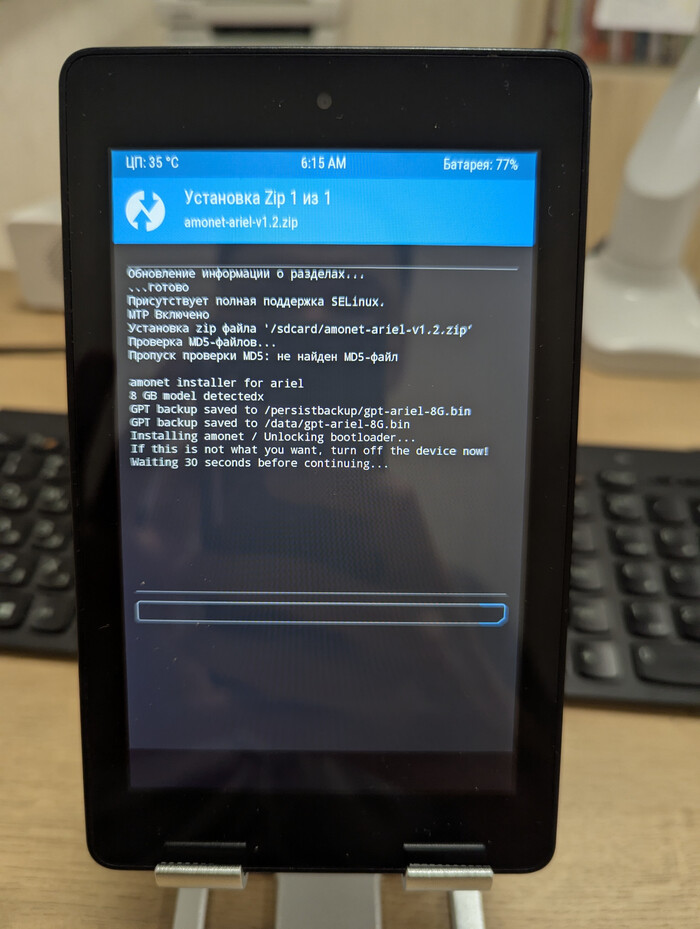
Установка TWRP и отключение OTA
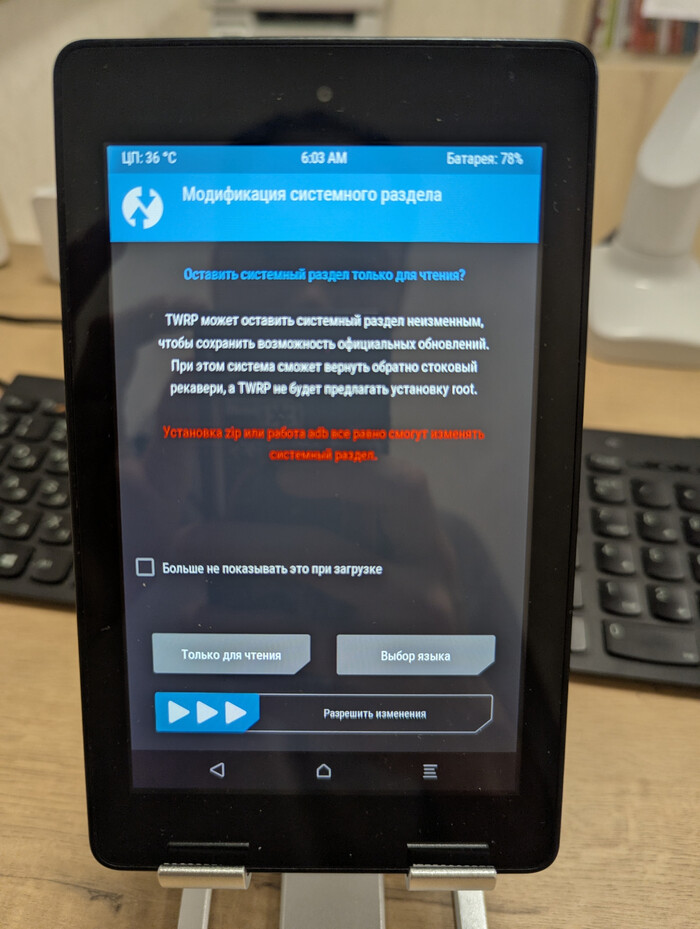
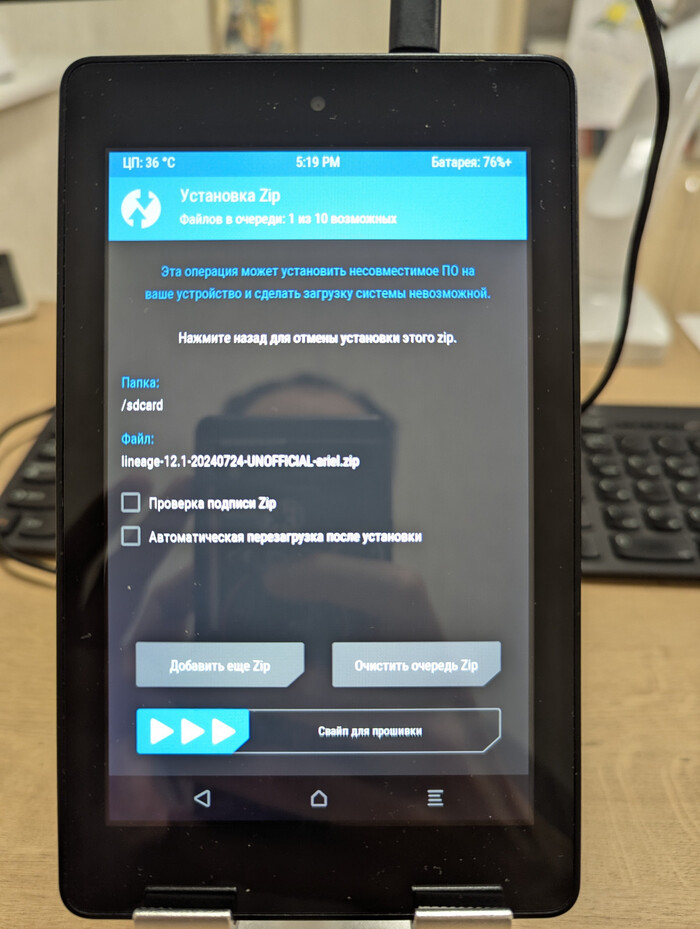
Чтобы Amazon вновь не пробрался на устройство отключаем обновления и ставим загрузчик восстановления TWRP, который заменяет стандартный раздел восстановления вашего устройства. Это нужно для установки сторонних прошивок, ядер, создание полных резервных копий (бэкапов) системы, очистки разделов, управление файлами и многое другое, что недоступно в заводском режиме восстановления.
Скрипт сам все сделает и перезагрузит устройство в обновленный TWRP. Теперь путь для кастомных прошивок открыт.
Установка LineageOS и финал
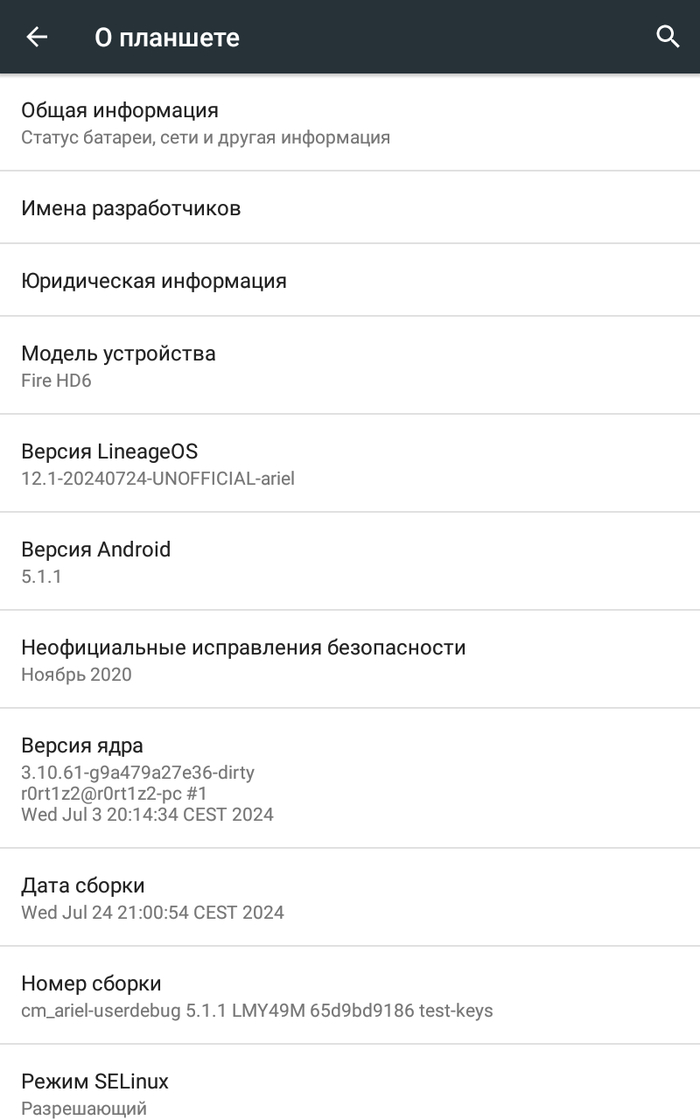
Родная FireOS заточена под amazon, но если использовать устройство как фоторамку все эти функции абсолютно не нужны. Я выбрал LineageOS 12.1 (Android 5.1). Да, в 2026 году когда на пикселях самая последняя версия Android 16 иметь пятую версию Android немного странно, но это буквально максимум который можно выжать из Amazon Fire HD 6 (Ariel), 2014 года 1 ГБ ОЗУ, 8 ГБ памяти, экран 6 дюймов.
И единственный разумный сценарий для Android 5 в 2026 году это локальное, офлайн‑ или изолированное устройство без чувствительных данных без веб‑серфинга и с минимальным набором приложений. В моём случае планшет используется именно так — как автономная фоторамка и потенциальный узел локальной домашней автоматизации, а не как персональное устройство.
Тем более что LineageOS легкая и идеально подходит для задачи «просто показывать картинки».
Закидываем на устройство фотографии, создаём плейлист.
Настраиваем Timers (чтобы экран был активен только в то время, когда кто-то есть в комнате).
Результат:
Итоговый вид. Старый планшет за 0 рублей выглядит не хуже специальных рамок за 7 / 15 тысяч
Ещё как часы может использоваться через Qzey: Большие Часы на Экран
Заключение
Конечно, если смотреть прагматично, то столько усилий ради того чтобы просто показывать картинки это неоправданно. А часы, с обновлением времени через интернет стоят около полутора тысяч рублей на китайской площадке. Ведь пришлось понижать прошивку, эксплуатировать уязвимости ядра, получать права суперпользователя, ломать загрузчик, ставить кастомную прошивку.
Но цель этого была не только в фотографиях. Во‑первых я дать вторую жизнь планшету, который уже давно отжил своё. А во‑вторых результатом стал полноценный android который можно использовать в домашней автоматизации, например подобным образом.
А решить проблему с постоянной зарядкой батареи тоже можно при помощи автоматизации или физическим вмешательством — так у меня уже был опыт когда пару лет назад я взял старый Nexus 7 планшет и извлек батарею — теперь он от 220В через зарядку работает. Не очень просто было, но теперь планшет без батареи. Так что думаю с Amazon Fire HD 6 (Ariel) тоже можно справится.
Nexus 7 3G работает без батареи
Причём на планшете с полностью вырезанной батарей идёт «разряд батереи» — планшет думает что батарея на исходе и выключается примерно через 12 часов, а ведь он запитан на постоянно от 5В. Но это не проблема статьи про Amazon Fire HD 6 (Ariel) — там пока всё на месте.
Конечно, этот путь не для всех, но если у вас есть подобный старый планшет и интерес потратить вечер на то чтобы поковыряться в системе, то такие действия вполне оправданы.
У меня три велосипеда — два взрослых и один детский.
Горный и шоссейный я использую для тренировок по своей системе и для покатушек вместе с пермским сообществом «Веловторник», а иногда и с другой группой — Porter Cycling Club. На детском катается мой ребенок.
Один из моих велосипедов
Групповые покатушки часто заканчиваются поздно вечером или даже ночью — неудобно сначала отвозить велосипед обратно на работу, пересаживаться на машину и только потом ехать спать. Да и детские прогулки, где я сопровождаю ребенка, стартуют в квартире.
Проблема с хранением
Пару лет назад, делая ремонт, я подумывал о месте хранения для велосипедов. Хотелось эффективно разместить их на балконе. Но было не до того, тем более меня выручал офис за городом.
Когда ситуация изменилась, я начал с поиска различных решений. Моя лоджия нестандартной формы — пятиугольной. Ее общая площадь примерно 8 м².
Среди вариантов были настенные крепления, для которых велосипед обычно вертикально ставят на одно колесо, а также потолочные подъемники и напольные стойки.
Мне нужно было что-то компактное и устойчивое, и я выбрал другой способ, который предполагает крепление каждого велосипеда за педаль в сочетании с небольшими подставками для колес. Сам железный конь при таком раскладе располагается горизонтально и под небольшим углом к стене.
Такой подход позволяет максимально использовать пространство, обеспечивая при этом устойчивость каждого велосипеда и легкий доступ к нему. По сути, его не нужно переворачивать на одно колесо — достаточно приподнять над полом и подвесить. Друг над другом у меня по такой схеме вместилось бы три велосипеда.
Установка креплений
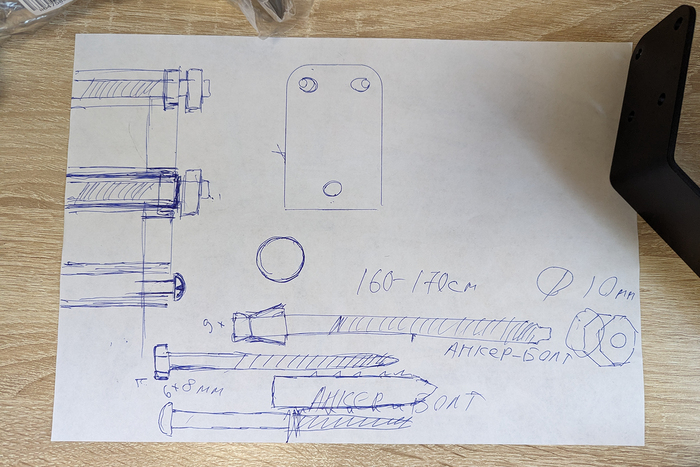
Существенной проблемой было то, что вагонка на балконе несет декоративную функцию. На кирпичную стену на расстоянии 40—60 см друг от друга установлены металлические вертикальные направляющие, и именно на них закреплены тонкие дощечки, которые вряд ли выдержали три велосипеда.
Это значило, что крепить инвентарь придется глубоко, именно в кирпич. А между вагонкой и стеной 3—4 см. Из-за этого стандартные крепления мне бы не подошли: слишком короткие. Пришлось от них отказаться.
Взамен я купил и использовал клиновые анкеры 80 × 170 мм. Они очень длинные, и их как раз хватает, чтобы покрыть расстояние между кирпичной стеной и вагонкой. Для крепления подставок я использовал дюбель-гвоздь ХПС 8 × 100 мм.
Штатный вариант крепления велосипеда, в котором я заменил анкеры
За помощью в установке креплений я обратился к мастеру-ремонтнику. Он нарисовал для меня схему, где наглядно показал, что и как собирается делать, и реализовал этот план на практике. Сначала просверлил отверстия в вагонке, затем — в кирпиче и на длинных анкерах повесил крепления, закрутив их с двух сторон болтами.
По плану педаль велосипеда должна была плотно лечь на плечо крепления. От соскальзывания ее бы защитили загнутые концы, которые видны на картинке. Но в моем случае крепления расположились не под нужным углом — в таком случае педаль бы висела и вся конструкция была бы неустойчивой.
Мастер помог мне все загнуть.
Схема установки креплений. Изнутри гайка, потом крепление, а снаружи тоже гайка
Для красоты я поменял обычные гайки на колпачковые
Результат
При помощи специалиста я визуально разделил стену на три горизонтальные зоны и в каждой установил крепление для велосипеда. Это позволило зацепить за каждое одну педаль железного коня и компактно разместить инвентарь на лоджии, при этом сэкономив место на полу.
Вероятность того, что велосипед сорвется со стены, крайне мала. Педали цепляются за подставку, как за крючок, а упоры для колес дают дополнительную опору.
Для меня такая система оказалась удобной. Если на улице сухо, я не мою колеса после прогулки, а сразу ставлю велосипед на крепление. По грязи стараюсь не кататься или просто проезжаю по луже, перед тем как пойти домой.
Если после прогулки в лесу образовалась сильная грязь на раме, протираю ее на улице влажными салфетками, а потом заношу велосипед в квартиру. Велосипеды начинаю развешивать, начиная с верхнего яруса, а снимаю, начиная с нижнего. Я доволен своим решением. Пока полет нормальный.
Привет, пикабушники! Недавно столкнулся с задачей, от которой у любого глаза на лоб полезут: нужно было сравнить два огромных списка адресов. Проблема в том, что адреса были записаны как попало, без каких-либо нормальных идентификаторов. Один и тот же адрес мог выглядеть так:
"д. Малое Шилово, ул. Березовая, д. 7" и "Березовая 7_М Шилово"
"п. Ласьва, ул. Весенняя, д. 5" и "Весенняя 5_Ласьва"
"д. Новая Ивановка, ул. Солнечная, 18" и "д.Новая Ивановка, ул.Солнечная, 18"
Задача стояла так: "В реестре поданных объектов отметить все согласованные объекты (из общего списка согласованных)".
Руками это делать - вообще не вариант. Поэтому решил запилить скрипт на Python. Какие есть варианты?
Fuzzy matching (нечеткое совпадение): алгоритмы, которые сравнивают строки, учитывая опечатки, разный порядок слов и сокращения.
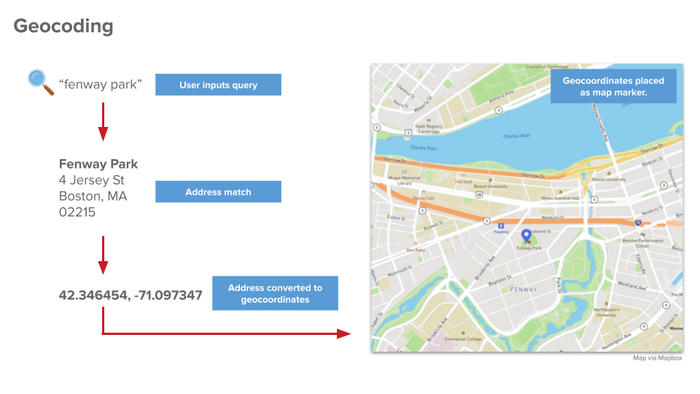
Геокодинг: преобразование текстового адреса в координаты.
Fuzzy matching мне показался более подходящим. Он не требует, чтобы адрес был на карте (а вдруг объект еще строится?), и хорошо справляется с разными вариантами написания.
картинка не совсем в тему, но прикольная, про fuzzy logic
Геокодинг, конечно, тоже можно использовать, но он может быть неточным, особенно в деревнях. Да и не все адреса на картах есть.
Как я это сделал:
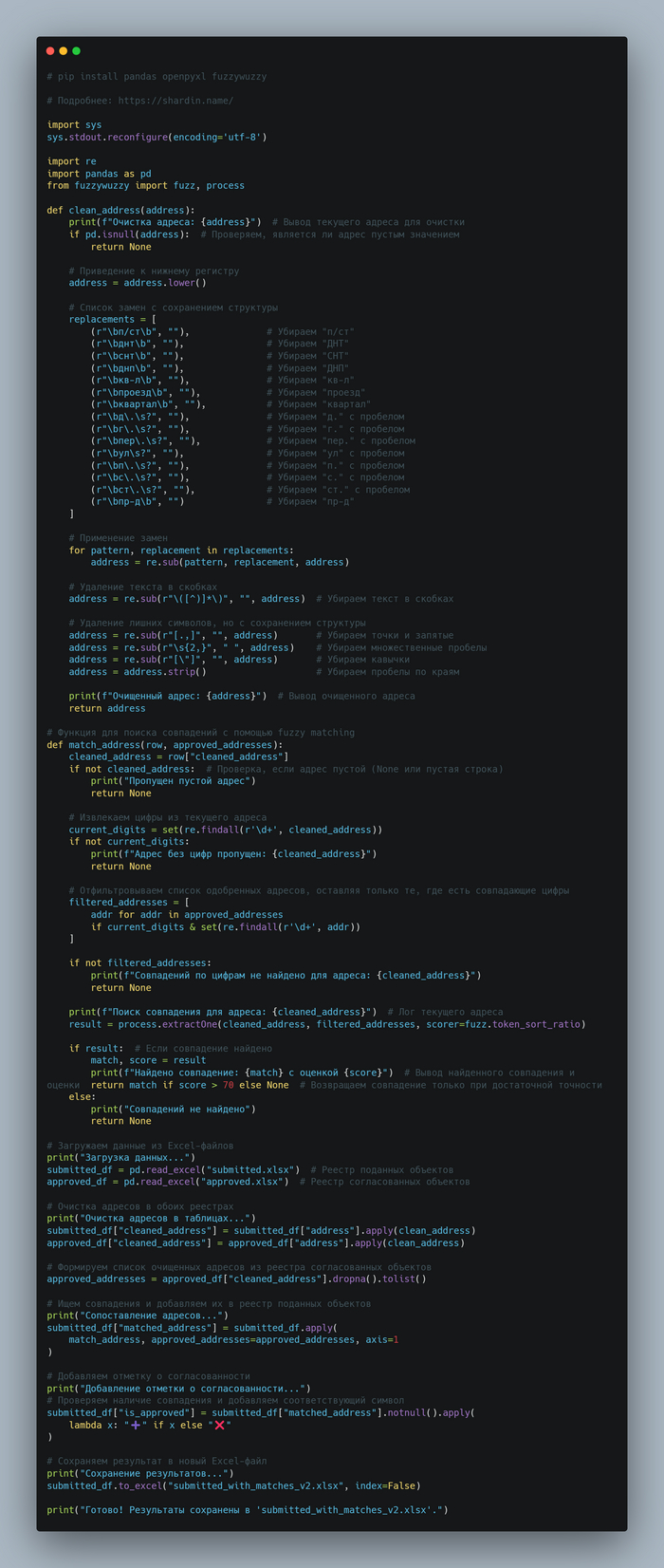
Подготовка данных: Сначала нужно привести адреса к единому формату. Убрать лишние пробелы, точки, запятые, сокращения типа "д.", "ул.", "г.". Для этого использовал Python с библиотеками pandas, openpyxl и fuzzywuzzy. (pip install pandas openpyxl fuzzywuzzy)
Fuzzywuzzy magic: Библиотека fuzzywuzzy использует алгоритм Левенштейна, чтобы определить, насколько строки похожи. Я использовал fuzz.token_sort_ratio, которая сортирует слова по алфавиту перед сравнением, чтобы порядок слов не мешал. Еще добавил фильтрацию по цифрам в адресе, чтобы ускорить процесс.
Скрипт: Скрипт загружает данные из Excel, чистит адреса, ищет совпадения с помощью fuzzywuzzy, помечает согласованные объекты плюсиком "➕", а несогласованные - крестиком "❌", и сохраняет результат в новый файл.
Profit! Автоматизация сэкономила кучу времени и нервов. Скрипт легко адаптировать под другие задачи, где нужно сравнивать текст.
Что можно улучшить:
Комбинировать fuzzy matching с геокодингом для большей точности.
Добавить обработку большего количества сокращений и вариантов написания.
















![Ошибка Home Assistant WARNING (MainThread) [supervisor.utils.pwned] Can’t fetch HIBP data: Timeout](https://cs19.pikabu.ru/s/2026/01/06/05/lenuxbyy.jpg)