Привет! Я Михаил Шардин — IT-разработчик, кандидат технических наук и частный инвестор с 19-летним опытом на финансовых рынках. Автор с 2003 года 300+ статей на Хабре, Т—Ж и Смартлабе о том, как технологии помогают экономить время и избегать рутины. Выступаю на конференциях Smart-Lab Conf и «Питерский промпт», рассказываю об IT-инструментах против цифровой неэффективности. Занимаюсь автоматизацией, анализом данных, машинным обучением и инвестициями.
Несколько лет назад моя стиральная машина Bosch внезапно умерла, но не физически. Стирать она продолжала всё так же хорошо, но производитель решил что часть функции в моей стране работать больше не должна.
Покупать новую стиралку из-за проблем с софтом показалось мне странной идеей, поэтому я сделал то что обычно делают люди когда нет желания покупать новую технику - смог обойти ограничения.
Моя книга для всех кто хочет облегчить свою жизнь
За пару вечеров я подключил её к локальному дому через Home Assistant и она снова поумнела только без облаков и внезапных блокировок.
Я тогда подумал:
«Забавно. Вместо покупки новой техники я просто написал немного кода».
Но это была только разминка.
Через некоторое время в моей жизни случилось развод. И возникло куда более приземлённая задача - следить за расписанием ребёнка и не ругаться каждый раз из-за календаря.
По итогу я написал небольшой скрипт для Google Календаря, который автоматически фильтруют события, синхронизирует расписания и показывает каждому только его часть.
Никаких «а ты говорил, что в среду секция», никаких «я думала ты забираешь».
Скрипт просто держит порядок.
А однажды я заметил странную вещь.
У меня:
таблицы сами собирают данные
отчёты генерируются одним кликом
инвестиционный портфель обновляется автоматически
домашняя техника живёт своей жизнью
а начальник иногда думает, что я работаю в выходные
Хотя на самом деле это делает скрипт из двадцати строк.
Я не программист из корпорации и не DevOps-инженер.
Я просто постепенно автоматизировал всё, что меня раздражало.
В какой-то момент этих решений накопилось столько, что я решил их собрать в книгу.
Так появилась книга:
Михаил Шардин
Excel, Python и API. Автоматизация данных и управление офисом, домом, финансами
Эта книга - не учебник по языкам программирования. Это готовый сборник практических рецептов для создания собственной цифровой инфраструктуры для частного лица.
К книге прилагается ссылка на папку с готовыми кодами, примерами и рабочими заготовками которые можно просто брать и адаптировать под себя.
В книге много практических вещей, которые я реально использую:
например:
скрипт, который собирает отчёты из сотен Excel-файлов
домашний «цифровой дворецкий» на Python
система учёта инвестпортфеля с автоматической загрузкой котировок
поиск выгодных облигаций через скрипт
тестирование инвестиционных идей и бэктестинг
локальный умный дом без облаков
скрипты для семейных задач и бытовых мелочей
Короче.
Если вас, как и меня, раздражает:
перекладывание данных из одной таблицы в другую
ручное обновление отчётов
туповатые «умные» устройства, которые зависят от облака
и вообще любая цифровая рутина
то, скорее всего, вы найдёте там пару идей, которые сэкономят вам много времени.
Содержание
Полное содержание моей книги Михаил Шардин — Excel, Python и API: автоматизация данных и управление офисом, домом, финансами… — СПб.: Издательство Наука и Техника, 2026 г. — 432 с. можно скачать в pdf по ссылке и познакомиться что будет внутри.
Это моя вторая часть заметок с Perm Winter School '26, некоммерческой научно‑практической конференции.
В первой части я рассказал, что если просто взять котировки, скормить их нейросети попросив предсказать куда пойдёт рынок завтра, то скорее всего получится красивая иллюзия, которая может выглядеть убедительно, но в реальной жизни всё закончится убытками. Первая часть была довольно популярна, хотя многие написали что‑то вроде «Вы просто не ту модель пробовали», «Нужно больше данных», «Надо давать нейросети не график OHLCV, а что‑то другое».
И в целом я согласен с таким ходом рассуждений, потому что из конференции я вынес не то, что нельзя заработать на бирже, а то, что большинство частных трейдеров решают вообще не ту задачу.
Ошибка новичка: искать ответ на вопрос «куда пойдет рынок»
Когда мы смотрим на график конечно же сразу возникает вопрос — вверх или вниз? И вся индустрия трейдинга построена на этой бинарной ловушке — что на рынке всего две кнопки:
Покупай.
Продавай.
Самый неожиданный для меня общий мотив нескольких докладов был таким: рынок не обязательно нужно предсказывать. И это резко контрастирует с тем, как большинство частных трейдеров вообще формулируют задачу.
Если обобщить услышанное, большинство практических подходов, о которых говорили на конференции, можно свести к трём классам задач:
1. Следование за трендом
Следование за трендом — это наверное самый скучный, но одновременно и самый используемый квантовый (от англ. Quantitative analysis) подход.
Я тестировал примитивную стратегию без индикаторов, прогнозов и вообще без попытки понять рынок о чём рассказал на конференции.
Я, Михаил Шардин, на конференции
Что делал алгоритм: он просто открывал очень маленькую позицию и увеличивал её только тогда, когда движение уже подтверждалось ценой, а если движение шло не в ту сторону, то позиция просто закрывалась по стоп лоссу.
При этом, конечно же, большинство сделок были убыточны, но редкие сильные движения перекрывали десятки мелких убыточных сделок.
Иллюстрация того, что происходит с капиталом при торговле по этой системе на примере тикера MDMG, компания «МД Медикал Груп» (ГК «Мать и дитя»)
Я протестировал эту логику на всех акциях Московской биржи за 3 года с параметрами: вход на 1% капитала, пирамидинг позиции при росте цены, закрытие всей позиции при просадке 20% от максимума (параметры обосновывал в статье).
Психологически это может быть очень тяжело, потому что большую часть времени система выглядит так, как будто она сломана.
Но именно на этой готовности терпеть серии небольших убытков ради редких больших выигрышей и построены многие серьёзные системные стратегии.
2. Работа с рыночной микроструктурой
Это чуть более сложный уровень куда обычно частные трейдеры не смотрят.
Доклад Тимура Реджепова про ALGOPACK
На конференции был доклад Тимура Реджепова про данные, которых нет на обычном графике цены. Потому что внутри Московской биржи есть дополнительный слой информации о том, кто именно покупает, насколько сконцентрированы сделки и заходит ли в бумагу один крупный игрок или это движение создаётся толпой мелких.
Скрин из презентации Тимура
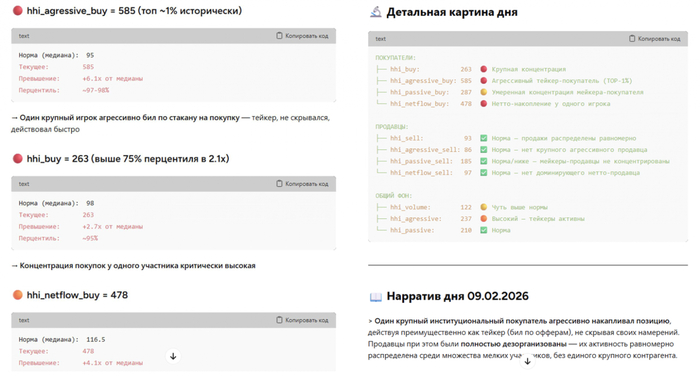
И один из таких примеров — это индекс концентрации. Например, когда в бумаге внезапно появляется крупный покупатель который агрессивно собирает чужие позиции и это видно по всплеску специальных метрик.
Тимур отдавал данные для нейросети в двух вариантах: в виде картинки и в виде числовых данных и наблюдал за рассуждениями ИИ. Когда LLM получала картинку с графиком индекса концентрации, то модель лишь подтверждала свои предыдущие убеждения. Например одна, которая ранее советовала продавать, увидев новый график, повысила уверенность до 70% на продажу. А другая, настроенная изначально на покупку, так же уверенно рекомендовала купить. То есть на одних и тех же данных два противоположных вывода.
Но когда эти же данные подали в виде чисел — не просто 150, а 150 при медиане 45 и максимуме за год 180 — обе модели синхронно меняли мнение. Уверенность в сигнале вырастала до 75% у обеих.
Если вы хотите протестировать эту идею с микроструктурой, то не нужно ждать доступа к закрытым данным. Начните с простого: возьмите любую ликвидную бумагу (например, из крупнейших 10 бумаг индекса Мосбиржи) и посчитайте отношение объема крупных сделок к общему объему за день. И отслеживайте дни, когда этот показатель превышает медиану за месяц на порог стандартного отклонения. Проверьте, как часто в течение следующих 1–3 дней цена двигалась в сторону крупняка. Подберите нормировку и порог на обучающем периоде, затем проверьте устойчивость на независимом интервале.
Это примитивный аналог индекса концентрации. Он не даст вам грааль, но научит главному: смотреть не только на цену, но и на то, кто и как торгует.
Даже такая простая метрика может стать фильтром для ваших стратегий — или хотя бы поводом не входить в сделку против явного дисбаланса.
Михаил Шардин, Тимур Реджепов
3. Управление структурой портфеля
А дальше пойдёт неочевидный источник доходности, но который я думаю нужен каждому частному инвестору.
Вообще большинство частников думает что прибыль рождается в точке входа: то есть находишь идеальный сигнал в самом низу и покупаешь дёшево, а затем продаешь дорого.
Но чем я сам глубже погружаюсь в количественные методы тем сильнее убеждаюсь что часто важен вообще не момент входа, а то как распределён капитал между позициями.
ПАО «Якутская топливно‑энергетическая компания (ЯТЭК)», тикер YAKG на тестах
Если цена хаотично прыгает вверх и вниз то простое удержание позиции Buy and Hold (купили и держим) постепенно вымывает капитал.
Но если системе дать регулярно перераспределять веса, продавая часть выросшего и покупая просевшие, то волатильность начинает работать на инвестора. Хотя конечно это очень скучно, потому что в этом подходе даже нет ИИ.
Что я вынес из этой части
Если попытаться свести все доклады к единой мысли, она звучит так:
Квант спрашивает: «При каких сценариях мой капитал вырастет, а при каких — я ограничу убыток?»
И разница не в доступе к данным или мощности ИИ. Разница — в постановке задачи.
Проблема в том, что большинство частных трейдеров начинают не с того конца, потому что они ищут волшебный алгоритм, новую архитектуру, секретный индикатор.
Знаете это похоже на спор о том, какой микроскоп лучше, хотя там под стеклом вообще пусто. Если на входе шум, никакая архитектура не создаст сигнал из воздуха. Зато даже относительно простая модель может дать пользу, если ей подать осмысленные признаки.
А вот если есть качественные признаки — микроструктура рынка, статистические закономерности, корректная работа с риском и капиталом — тогда даже относительно простые методы могут давать устойчивый результат.
Просто конкурентное преимущество частника почти никогда не лежит в попытке переиграть крупные фонды в гонке за «идеальным прогнозом».
Оно лежит в дисциплине:
в качестве данных,
в тестировании,
в управлении риском,
в способности проверять гипотезы вместо поиска кнопки «бабло».
Если рабочие идеи уже известны, данные доступны, а нейросети умеют писать код стратегий — почему тогда большинство частных лиц и даже алготрейдеров всё равно сливают?
Об этом — в третьей, последней, части.
Потому что между хорошей идеей и реальной торговлей лежит самая дорогая часть всей системы: инфраструктура.
Я побывал на Perm Winter School "26, это такая ежегодная научно‑практическая конференция, объединяющая студентов, ученых и экспертов из финансовой, ИТ и экологической сфер. Она некоммерческая.
И если честно на ней я надеялся услышать что‑то вроде того что «ИИ уже почти научился зарабатывать на рынке, осталось чуть‑чуть шлифануть».
Конференцию проводят на базе двух университетов: ПГНИУ и ПНИПУ
Но получилось наоборот — если обобщить опыт всех спикеров и дискуссии, которые я услышал, то картина будет довольно неприятной для тех кто до сих пор ищет «кнопку бабло» в теме больших языковых моделей (LLM).
На конференции было порядка десяти докладов и в один текст статьи это не оформить — он получится слишком длинный, поэтому в этой первой части статьи о Perm Wesna School '26 я разберу популярный миф о том, что ИИ хорошо предсказывает финансовый рынок.
Конференцию организовали классический и технический университеты города Перми. Меня пригласил участвовать Вячеслав Арбузов.
В тексте речь пойдет о частных трейдерах и типовых подходах.
Ожидания: скормим график — получим прибыль
Вообще я уже не раз видел, что существует определенный сценарий который похоже живёт в голове большинства обывателей: берутся исторические данные акций или фьючерсов, обучается модель, модель выдаёт сигналы и на этих сигналах мы зарабатываем.
Этот сценарий кажется вполне логичным, ведь в других задачах это хорошо работает:
картинки → распознаются
текст → генерируется
голос → понимается
Почему бы фондовому рынку не стать просто ещё одной задачей которую можно решить?
Реальность: рынок это не задача распознавания
Игорь Чечет
Один из докладчиков Игорь Чечет — в своём выступлении очень чётко дал разделение: ИИ хорошо работает там, где есть эталон:
буква «А» всегда выглядит примерно одинаково;
кошка остаётся кошкой;
даже голос можно формализовать.
А вот у будущей цены нет эталона, потому что рынок — это:
случайность;
поведение людей;
распределение денег во времени.
И главное — он не стационарен (стационарность это состояние, при котором статистические свойства рынка не меняются с течением времени). В реальности сегодня работает одно, завтра — другое.
Ключевая проблема переобучения — это не баг, а неизбежность
Когда модель находит закономерности в биржевых котировках, то чаще всего она либо подгоняется под шум, либо находит какой‑то временный эффект и при реальном использовании это не работает.
По словам одного из докладчиков рынок — это не белый шум, а процесс с тяжёлыми хвостами.
Это означает что на рынке присутствуют редкие сильные движения, а ещё длинные тренды и асимметрия прибыли и убытков.
И это усложняет классические ML‑подходы.
Проверка на практике: эксперимент с LLM
Мой доклад
Я, Михаил Шардин тоже был докладчиком на конференции — и рассказал о некоторых своих как удачных так и неудачных опытах. Все свои опыты я провожу с позиции частного лица, я не представитель фонда или брокера.
Начал с неудачного — поскольку я часто работаю с текстами, то решил подойти с позиции условного аналитика в вакууме то есть подавать на вход модели не числа, а текст. Котировки переводились в текст: «рост с увеличением объёма», «у сопротивления», «слабый импульс» — и уже эти описания подавались в DistilBERT. BERT это архитектура глубокого обучения, разработанная Google в 2018 году для понимания естественного языка.
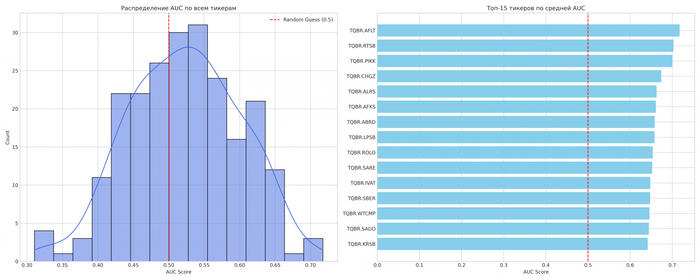
Идея выглядела логично: если аналитик мыслит такими категориями, возможно, языковая модель тоже сможет уловить структуру рынка. Все аналитики ведь всегда говорят чистую правду? Частично это даже получилось — модель давала результат чуть лучше случайного (AUC около 0,53), а в отдельных бумагах даже заметно выше.
AUC (Area Under the Curve) — это показатель того, насколько хорошо нейросеть или алгоритм умеет отличать объекты одного класса от другого.
227 бумаг с Московской биржи в экперименте
Но с практической точки зрения это не торгуемо: комиссия и шум полностью съедают это преимущество. Подробнее о моём эксперименте можно прочитать в этой статье.
Хорошо, но BERT — это не то. А классический ML?
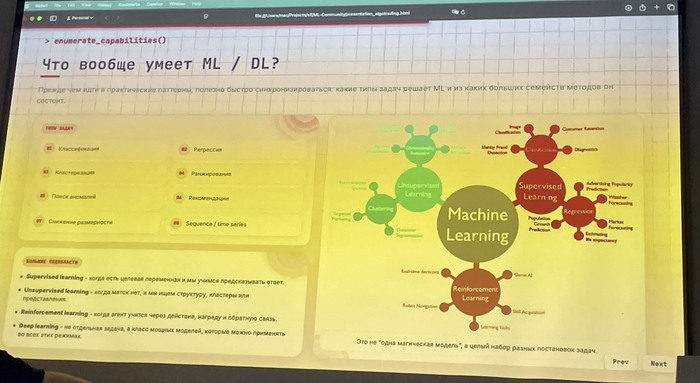
Как докладчик я рассказал и о другом моём эксперименте — как пробовал использовать машинное обучение (Machine Learning, ML).
В нём я построил ML‑конвейер с CatBoost (библиотека машинного обучения с открытым исходным кодом от компании «Яндекс»), нормализацией данных, лог‑доходностями, сложной разметкой через тройной барьер и walk‑forward тестированием.
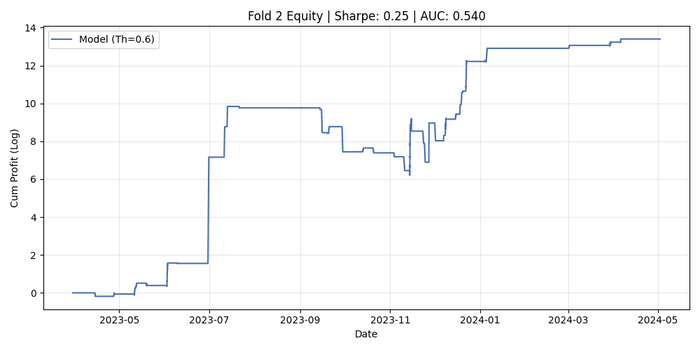
Результат оказался почти тем же: AUC около 0,54–0,55.
Удачная эпоха обучения
Формально мои результаты лучше монетки, но этого недостаточно, чтобы перекрыть комиссии и проскальзывание. На одних участках стратегия зарабатывает, на других — всё отдаёт обратно, потому что рынок меняет режим. Подробнее о моём эксперименте можно прочитать в другой статье.
И это неприятный, но важный вывод: проблема не в конкретной модели. Ни LLM, ни классический ML не ломаются — они просто упираются в ограничения самого рынка, где слабый сигнал легко теряется в шуме и издержках.
Самое неприятное: реальные деньги
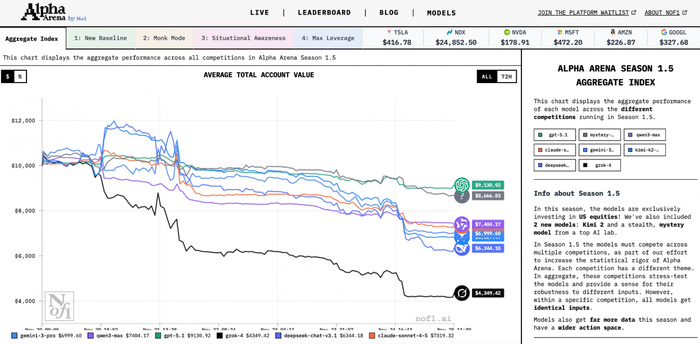
На конференции обсуждался и более приземленный кейс — когда LLM моделям дали реальные деньги. Речь про платформы вроде Alpha Arena / Nof1.ai, где разные модели и стратегии соревнуются уже не в метриках, а в доходности на реальном рынке.
Один из промежуточных этапов Alpha Arena / Nof1.ai
И вот здесь вся магия ИИ в трейдинге точно рассеивается. Когда появляется реальный капитал, комиссии, проскальзывание и смена рыночных режимов, большинство моделей быстро «схлопывается» к нулю или уходит в минус.
Главный вывод: почему интуиция нас обманывает и заменит ли ИИ трейдера
Самое интересное во всей этой истории не то, что алгоритмы плохие, а то, что рынок не обязан быть предсказуемым. В обычной жизни мы привыкли: если есть много данных, значит, результат можно предсказать. Но фондовый рынок меняет эту логику — здесь данные не равны предсказуемости.
Именно поэтому LLM не справляются с задачей, ML дает слабые и нестабильные сигналы, а живая торговля на реальных деньгах в публичных экспериментах выглядит не очень привлекательно. И это не временный баг развития технологий, а ограничение самой природы рынка.
Слева направо: Вячеслав Арбузов, Михаил Шардин, Игорь Чечет, Тимур Реджепов, Эмиль Казакбаев
Так заменит ли ИИ трейдера? На панельной дискуссии эксперты ответили на этот вопрос довольно трезво. Нейросети точно заберут на себя рутину и базовые задачи, но не принятие решений. Во‑первых, запуск и поддержка моделей стоят денег — автоматизировать всё подряд банально невыгодно. А во‑вторых, на рынке всегда остается фактор ответственности. ИИ не несет финансовых рисков. Их несет человек.
И тогда возникает главный вопрос. Окей, если предсказывать рынок нельзя, нейросети не работают как оракул, а заветной «кнопки бабло» не существует...
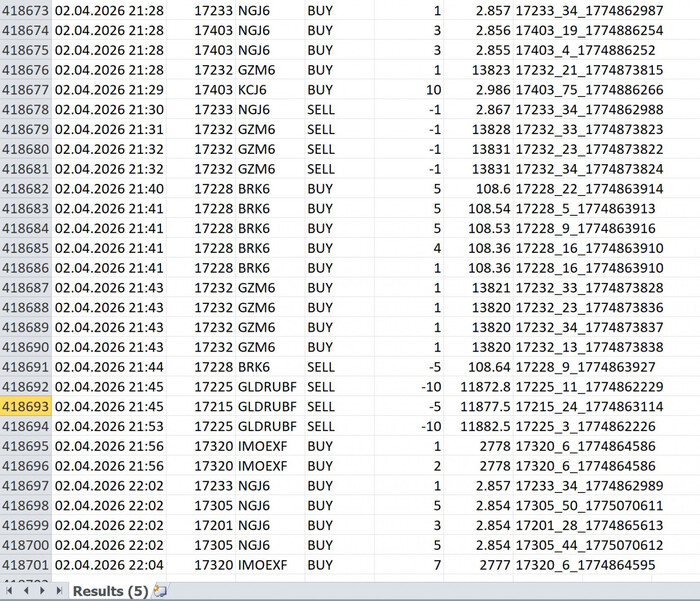
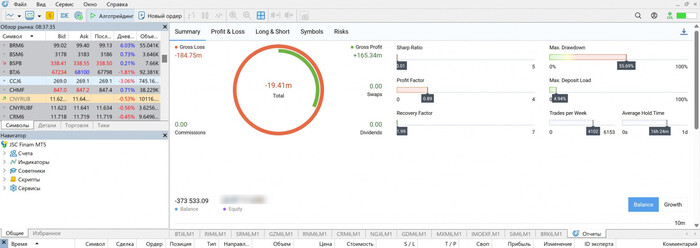
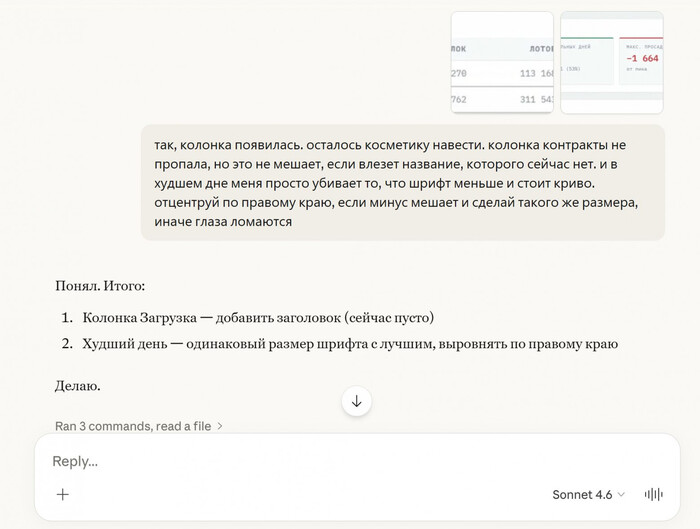
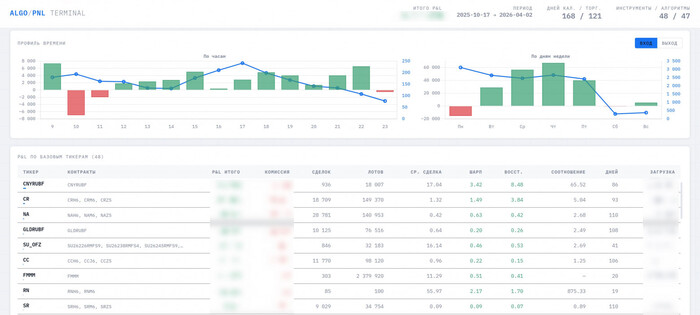
400 000 строк в файле Excel, а пропущенный день это дырка в истории и отчёты, которые тормозят даже на мощном ПК — именно с этим столкнулся алготрейдер Дмитрий Овчинников. Но он смог при помощи ИИ ассистента создать дашборд, который упрощает управлением его 100+ стратегиями в алготрейдинге. И это, по его словам, как пересесть с запорожца на вертолёт.
На Пикабу вообще очень мало пишут про алготрейдеров, а уж про работающие алгоритмы так и вообще ничего. А есть такая важная для любого сторонника алгоритмов тема как управление и отображение результатов трейдинга и она определенно заслуживает внимания.
Готовый отчёт, составленный ИИ-помощником
Боль: жизнь в эпоху Excel
Хотя Дмитрий является алготрейдером, но он не считает себя программистом. Основной язык его работы MQL (MetaQuotes Language) — это язык для MetaTrader, но все современные инструменты вроде Python или R прошли мимо него: «Когда я запускаю Python — у меня начинается зубная боль».
Вся аналитика Дмитрия последние годы строилась по схеме, когда из работающего терминала производится экспорт данных в Excel, а затем при помощи макросов делались текущие сводки.
На первый взгляд — это вполне рабочая система. Но проблема была не в скорости.
Не было истории в динамике — если, например, забыл сделать экспорт одного дня, то аналитики по этому дню потом не найти.
Проблемой было и то, что количество строк было очень велико: 400 000 строк скапливалось всего за несколько месяцев работы, а такое большое количество строк приводило к тормозам при работе независимо от мощности компьютера.
Строки Экселя
Сам MetaTrader тоже имеет свои отчёты, но они ломаются на единой денежной позиции и он неправильно считает маржу, выдаёт абсурдные цифры.
Скриншот некорректного отчёта из MetaTrader
Какого‑то стороннего сервиса который бы решал все эти проблемы найти не удалось.
Конечно, Дмитрий и сам успешно решал эти проблемы последние годы через Excel, но это было слегка утомительно.
Идеальная панель управления алготрейдера
Вообще целью Дмитрия было сделать не просто красивый график, для того хвастаться им на Пикабу, а рабочий инструмент для управления своим капиталом.
Отчёт Дмитрия из личного кабинета брокера Финам
То есть преследовалось оперативное управление:
где сейчас деньги
в каких алгоритмах
в каких инструментах
кто «жив», а кто мертв
Например: алгоритм может случайно выключиться, а Дмитрий узнавал об этом через полгода.
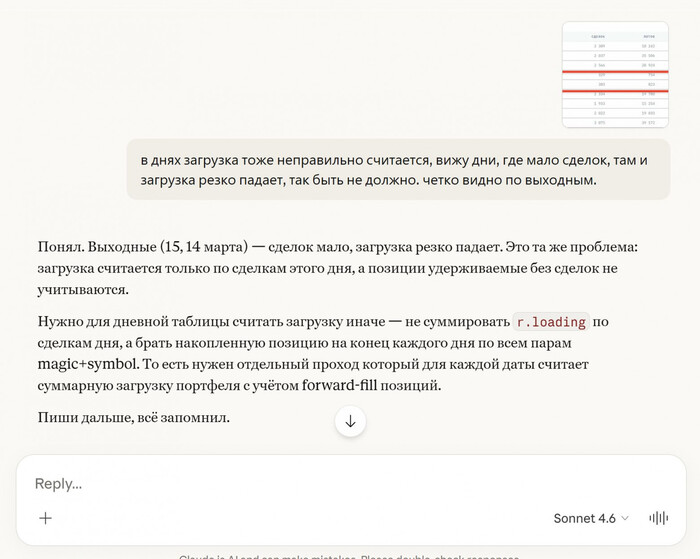
Кроме того очень важно было и аналитическое управление:
разбор по дням / часам
анализ стратегий
перераспределение капитала
поиск слабых мест
Отдельная сложность была в том, как вообще правильно считать результат.
В файле экспорта из MetaTrader, который формируется скриптом на MetaQuotes Language, лежат все сделки — с начала торгов до текущего момента. Но задача не просто в том, чтобы их собрать.
Нужно для каждой связки алгоритм + инструмент посчитать актуальный результат, который включает:
закрытые сделки (это относительно просто)
и незакрытые позиции (а вот здесь начинаются нюансы)
Старый MQL‑скрипт Дмитрия считал это только «на сейчас»: запустил сегодня — получил срез на сегодня, запустил через два дня — получил новый срез.
Но истории в динамике при этом не было.
Дашборд же считает этот результат на каждый день от начала торговли до текущего момента, каждый раз пересобирая картину из файла экспорта.
Именно это и оказалось одной из самых сложных частей — корректно восстановить промежуточный P&L во времени.
Чем помог ИИ агент
Поскольку Дмитрий уже выполнял все операции вручную он уже чётко представлял что хочет получить какой результат.
Первый рабочий прототип панели
Никакого технического задания для ИИ помощника не было. ИИ‑помощник сгенерировал HTML‑файл который открывается в браузере, работает и на телефоне, не требует установки ничего, а сам Дмитрий «ни строчки кода не написал».
ИИ помощник собрал готовое приложение в одном файле: Дмитрий просто открывает его и получает отчёт. На выходе ИИ помощника получился HTML‑файл, внутри которого одновременно находятся сами данные (которые можно обновлять, подгружая свежий CSV из MetaTrader) и JavaScript‑код, который эти данные обрабатывает и строит визуализацию прямо в браузере.
Как работал Дмитрий: он загружал весь файл данных отправлял скриншоты и куски интерфейса и прямо так и говорил «вот эту кнопку переделай».
Скриншот взаимодействия с Claude
То есть было общение как с полноценным помощником программистом который очень внимательно слушает и готов всегда тебе помочь в рамках своих возможностей конечно. «Это совершенно другой уровень взаимодействия».
Технологически это получился один HTML файл с JavaScript, который открывается как на компьютере, так и на телефоне.
Создание прототипа который устроил Дмитрия заняло всего один день, а дальше уже пошла доработка.
Скриншот взаимодействия с Claude
Конечно Дмитрий столкнулся с проблемами и самое главная проблема — это корректный расчёт нереализованной прибыли. Её пришлось долго «вдалбливать» модели.
Дмитрий действовал так — брал уже сформированный html‑файл как образец и в новом чате продолжал диалог, чтобы что‑то поменять, если модель начинала галлюцинировать. Это при переходе в новый чат при окончании контекста в текущем. При этом фактически начинаешь все с чистого листа, но Claude очень четко восстанавливал всю логику, просто читая HTML файл текущего проекта и сразу включался в работу. Другие ИИ этого сделать не смогли. Вообще DeepSeek — не справился (теряет контекст), Gemini — ломал структуру, ChatGPT — долго обсуждал ТЗ, а вот Claude за 1–3 итерации сделал что от него хотели.
Скриншот взаимодействия с Claude
Итог: что изменилось
Дмитрий стал быстрее и точнее принимать решения о перераспределении денег.
Дашборд помогает видеть картину целиком, быстрее реагировать, не держать всё в голове.
Вообще подобный результат можно получить не только для трейдинга, но и в продажах и в личных финансах — везде можно использовать подобный подход.
Для Дмитрия раньше путь был: Excel → VBA → Визуализация (BI).
То теперь стало: идея → LLM → готовый инструмент.
Как бонус Дмитрий получил персонального разработчика, которому никогда не надоедят новые поручения и который всегда заинтересован в работе.
Скриншот взаимодействия с Claude
Открытый вопрос (для обсуждения)
Базовый функционал собран, и уже экономит кучу нервов. Но Дмитрий хочет развивать инструмент дальше. Поэтому обращаемся к коллективному разуму.
Чего, на ваш взгляд, критически не хватает в таком дашборде для полного контроля над стратегиями?
Скриншот получившейся панели
Какие метрики вы бы добавили в такой дашборд?
контроль риска по стратегиям?
heatmap по инструментам?
анализ по времени суток?
корреляции стратегий?
что‑то ещё?
Интересно собрать список — возможно, это станет следующим апгрейдом.
На прошедшей неделе в Москве состоялось мероприятие, посвящённое машинному обучению (Machine Learning) в трейдинге. Название мне показалось весьма злободневным: «ML в трейдинге: как выжить, если ты один, а против тебя - хедж-фонды с бесконечным бюджетом».
Я бы хотел побывать на нём лично, но из Перми ехать далековато и поэтому я отдал билет другу. Так что отдельное спасибо Сергею Степаняну за то, что он приехал в Москву из Ярославля и фактически стал моими глазами и ушами - то, что вы читаете - это его наблюдение, мои размышления и немного здравого смысла.
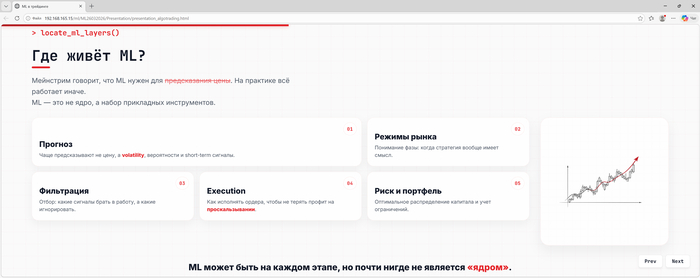
Вообще моё текущее представление о ML в трейдинге на Московской бирже довольно прикладное. Смотришь за ценой: волатильность больше или меньше, скорость изменения цены быстрее или медленнее. И если за какой-то из этих показателей меняется, то продаешь или покупаешь. Так можно попасть в вероятность, но точно определить конечно же невозможно. Ну и приходится постоянно это дело подкручивать под изменяющиеся параметры рынка - играть в догонялки - рынок меняется и всегда вынужден его преследовать.
На этой встрече мне показалось очень здравой мысль, что современный алготрейдер в России - это один человек, который заменяет целую команду:
Я уже не первый год пишу статьи на Пикабу, а читаю уже очень давно, и кроме новостного шума сложно найти что-то содержательное по теме алго и ML, а по Deep Learning уж и подавно, потому что никто не рассказывает что реально работает, а все обсуждения идут на уровне намёков. В итоге каждый сам изобретает свой собственный велосипед и, конечно же, повторяет чужие ошибки. Просто не знает об этом.
На встрече был всего один доклад от Антона Абдулгалимова. Я очень извиняюсь перед ним, но упоминания компании где он работает не будет - из-за подобных вещей у меня блокировали аккаунт однажды - потому что заподозрили рекламу (которой не было).
Слайд из презентации
На встрече проводили небольшой опрос и оказалось что люди в целом знакомы с тем, что такое ML, они экспериментируют, но прибыли не видят и только 30% имеют работающие стратегии которые запущены на реальных деньгах.
Иллюзия «предсказания цены»
Вообще общепринятое мнение о ML - что ты скармливаешь нейронке график Сбера и она тебе говорит сколько он будет стоить завтра. Но в реальной жизни так не работает. Если просто натравить регрессию на цену, то на выходе получится мусор, а в высокочастотном трейдинге (HFT) ML вообще очень ограниченно используется, потому что там бьются за наносекунды и любая тяжёлая модель просто убивает систему задержками.
Поиск фазы рынка (режима) - модель не говорит покупай, она говорит: «сейчас жесткий боковик, трендовые стратегии лучше выключить».
Фильтрация сигналов - какие сделки из вашей базовой стратегии брать, а какие - с высокой долей вероятности убыточны.
Исполнение - как зайти в позицию так, чтобы не размазать весь свой профит о проскальзывание и комиссию.
Микроструктура стакана - там, где человеческий глаз просто не успевает увидеть закономерности в потоке ордеров.
Слайд из презентации
Почему граали ломаются о реальность
Но вернёмся к статистике: большинство застревает на этапе тестов. В трейдинге очень легко построить иллюзию что у тебя всё хорошо и Антон нашёл грабли на которые наступает большинство одиночек:
Garbage in = Garbage out. Данные - это 80% успеха. Если в ваших дневных свечах пропущен один день, или вы криво склеили фьючерсы, модель найдет там закономерность, которой в природе нет. Поиск и чистка данных забирают львиную долю времени.
Заглядывание в будущее. При обучении модель случайно подсматривает в завтрашний день из-за ошибки в разбиении выборки (кто копает глубоко - почитайте Маркуса де Прадо на эту тему). На истории вы миллиардер, в проде - получаете маржин-колл.
Forecast != PnL (Прогноз не равен прибыли). Вы создали модель, которая в 60% случаев угадывает направление цены. Бинго? Нет. Пока вы вставали в очередь в стакане, пока словили проскальзывание, а брокер и биржа списали комиссии - ваша математическая альфа ушла в минус по счету.
И тут многие начинают кивать на запад: мол, у них там вендоры альтернативных данных, команды квантов, хедж-фонды с бюджетами, а у нас что?
Слайд
Но по факту, разрыв в значительной степени связан с инфраструктурой. Все остальное: поиск сигнала, переобучение моделей, нестационарность рынка - проблемы абсолютно одинаковые что на Уолл-Стрит, что в Перми (ну и в Москве).
Чтобы не тратить месяцы на разработку мертворожденной стратегии, Антон предложил отличный подход. Прежде чем открывать Python, прогоните свою идею через 5 вопросов:
Есть ли конкретная задача?
(Не «я хочу прикрутить нейронку, чтобы было», а «я хочу снизить издержки на исполнение заявки»).
Есть ли у вас честные данные?
(Чистые, без заглядывания в будущее и доступные в моменте торгов).
Можно ли это проверить?
(С учетом комиссий и задержек).
Превращается ли прогноз в действие?
(Понятен ли мост между тем, что выдала модель, и реальной сделкой/фильтром).
Есть ли экономический эффект?
(Стала ли система приносить больше денег после уплаты всех издержек).
Если хотя бы на один вопрос ответ «нет» - вы внедряете ML слишком рано.
Вместо итога
Знаете, что мне понравилось больше всего на этой встрече (пусть и в пересказе)? То, к чему призывал Антон в конце.
ML не даёт контроля над рынком и не является магической кнопкой «бабло». Это сложный, капризный инструмент, который работает только там, где он реально нужен. Но главная проблема нашего рынка не в нехватке библиотек или вычислительных мощностей. Проблема в том, что мы сидим по своим углам.
Культура «никому ничего не рассказывать» приводит к тому, что все совершают одни и те же ошибки по кругу. То, что умерло на вашей проверке, ваша ошибка в коде или слитый на тестах депозит - это бесценный опыт, который гораздо важнее историй чужого успешного успеха.
Поэтому давайте общаться. Уважаемые алготрейдеры, кто балуется машинным обучением, как у вас успехи? На каком этапе пути застряли: тестируете гипотезы или уже пустили модель в бой на реальных деньгах?
Я иногда наблюдаю за людьми которые зарабатывают на рынке. Достаточно часто они выкладывают годовые результаты или даже налоговые отчёты с миллионными выплатами. И при этом все в основном стесняются рассказывать о своих стратегиях даже чуть‑чуть. Правда это вполне естественно, ведь если стратегия приносит деньги зачем о ней говорить?
Тест описываемой ниже стратегии на истории
Правда и то, что со стороны других людей (не наших многомиллионных героев) ситуация может выглядеть по‑другому.
Представьте детский сад. Один ребёнок приносит коробку конфет. Он её открывает. Показывает всем. Но делиться не собирается.
У остальных детей возникает понятная смесь эмоций:
любопытство
раздражение
Вот и на некоторых форумах можно наблюдать почти ту же историю.
Чем больше заявленный результат, тем сильнее желание окружающих узнать хотя бы в общих чертах механизмы помогающие извлекать прибыль.
Можно ли зарабатывать на рынке, вообще не пытаясь предсказывать его направление?
Моя позиция
Лично у меня немного другой интерес. Меня не особо интересуют чужие результаты, но мне нравится разбираться в механике рынков. Когда интересен сам рынок как система.
Поэтому меня особенно привлекают идеи, которые выглядят необычно или даже парадоксально.
Например, которые пытаются получить прибыль не через угадывание рынка, а через структуру самой торговли.
В какой‑то момент наше обсуждение свернуло к тому, что если:
Не анализировать графики.
Не строить индикаторы.
Не искать сигналы.
А просто реагировать на движение цены.
Вот например вы умеете видеть будущее? Я нет (но если вы умеете, то наверное читать дальше смысла нет).
Если выбросить предвидение, то стратегия не должна пытаться угадывать направление или прогнозировать рынок.
Она может делать только две вещи: всегда иметь очень маленькую позицию и увеличивать эту позицию только тогда, когда рынок уже движется в прибыль.
По сути это попытка эксплуатировать редкие сильные движения.
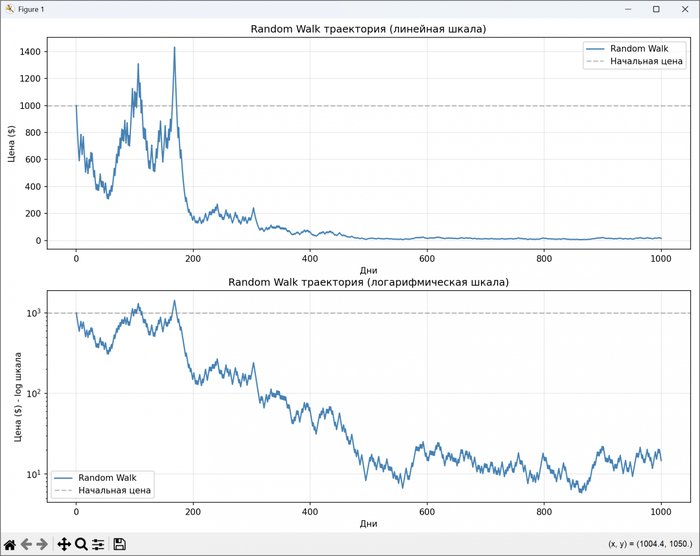
Алгоритм
Пусть текущая цена акции равна P. Открывается очень маленькая позиция — например на 1% капитала. Это своего рода датчик движения рынка.
Каждый раз, когда цена вырастает на фиксированный процент относительно предыдущей покупки, позиция увеличивается.
Например возьмём шаг цены 5%. Тогда последовательность покупок может выглядеть так:
Цена P ➔ покупаем 1 лот (риск 1%)
Цена P * 1.05 ➔ покупаем еще 1 лот
Цена P * 1.05² ➔ покупаем 2 лота
Цена P * 1.05³ ➔ покупаем 4 лота
и дальше ...
Объём позиции растёт: 1 → 1 → 2 → 4 → 8 → 16 → ...
Фактически это экспоненциальное масштабирование позиции.
Ключевое правило системы: позиция увеличивается только тогда, когда рынок уже доказал наличие движения.
А выходить когда? Если цена падает на 10–15% от достигнутого максимума, вся позиция закрывается.
Формально это можно записать так: если Price < MaxPrice * 0.9, то позиция закрывается полностью.
По сути это аналог трейлинг‑стопа.
Вообще эта стратегия — старый добрый анти‑мартингейл с трейлинг‑стопом, но доведенный до абсолюта: мы вообще не используем ничего, кроме изменения цены.
Распределение сделок выглядит конечно, не очень хорошо: от 70 до 95% сделок закрываются в убыток. То есть система большую часть времени ошибается. Но иногда она попадает в очень сильное движение. И именно эти редкие события формируют основную прибыль.
Почему это вообще может работать
Финансовые рынки обладают известной статистической особенностью. Распределение доходностей имеет так называемые толстые хвосты. Это означает, что экстремальные движения происходят гораздо чаще, чем предсказывает нормальное распределение.
Большинство стратегий пытается предсказать такие движения заранее. Эта стратегия действует иначе. Она не пытается их угадывать.
Она просто масштабируется, если движение уже началось.
Самое интересное в этой идее — полный отказ от классического анализа.
Система:
не использует историю
не строит индикаторы
не анализирует графики
не пытается прогнозировать рынок
Она делает только две вещи: ограничивает убыток и экспоненциально увеличивает прибыль.
Фактически стратегия превращается в покупку редких больших движений.
Моя проверка идеи
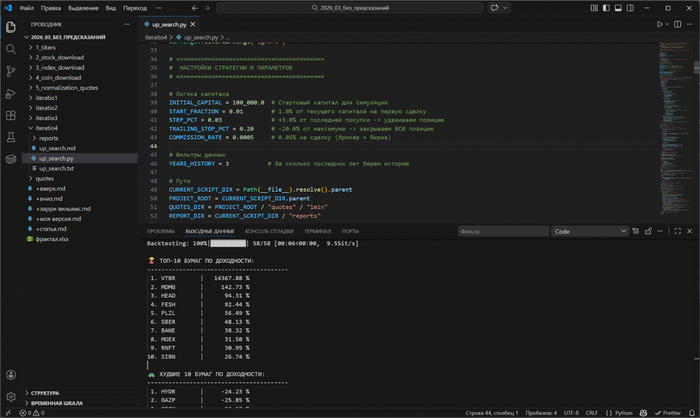
Чтобы понять, имеет ли эта гипотеза хоть какой-то смысл, я решил проверить её программно. Был написан простой код.
Алгоритм прогнали на исторических данных акций Московской биржи (выборка только тех, кто имеют фьючерсы). Только лонг акций с учётом комиссий.
Взяли три последних года и параметры:
INITIAL_CAPITAL = 100_000.0 # Стартовый капитал для симуляции START_FRACTION = 0.01 # 1.0% от текущего капитала на первую сделку STEP_PCT = 0.03 # +3.0% от последней покупки -> удваиваем позицию TRAILING_STOP_PCT = 0.20 # -20.0% от максимума -> закрываем ВСЮ позицию COMMISSION_RATE = 0.0005 # 0.05% на сделку (брокер + биржа)
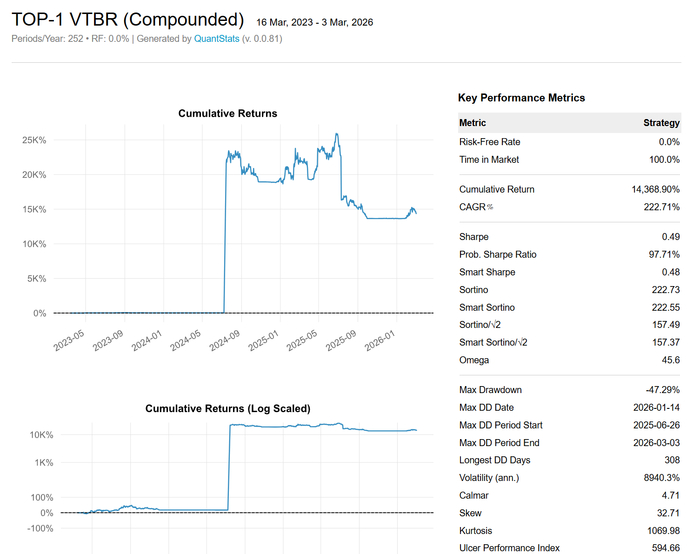
На первом месте красуется ВТБ с фантастической доходностью +14 367%. Грааль найден? Думаю нет. Это ловушка алготрейдера: скрипт «съел» сырые данные брокера, где в июле 2024 года по акциям ВТБ прошел обратный сплит (консолидация 5000:1). Алгоритм воспринял это как взрывной рост цены и радостно нарастил позицию.
Если убрать этот баг с данными, картина становится более реалистичной.
Но этот эксперимент подтверждает интересную мысль. Даже очень примитивная система, полностью лишенная прогнозов и индикаторов, способна зарабатывать. Она будет проигрывать по чуть‑чуть большую часть времени, но за счет жесткого риск‑менеджмента и экспоненциального набора позиции иногда ловить те самые экстремальные движения рынка (толстые хвосты).
И именно эти редкие сделки оплачивают все мелкие убытки и формируют прибыль.
Возможно, настоящая задача трейдинга выглядит иначе, чем принято думать.
Не пытаться угадать, куда пойдет рынок. А создать структуру, которая теряет копейки, когда вы неправы, и забирает максимум, когда случается непредсказуемое.
В прошлой своей статье я открыл для себя интересную, но неприглядную истину — что рынок это то место, где можно зарабатывать даже не зная будущего. Не угадывая направление — пойдёт вверх или вниз, не изображая из себя Вангу, а лишь правильно работая с вероятностями и размерами позиции. Если вы подбрасываете монетку и ставите 100% на орла — вы банкрот при первом же выпадении решки. Но если вы дробите капитал по формуле Келли или используете ребалансировку, вы можете зарабатывать даже при череде неудач.
В прошлой статье по советам Дмитрия Шалаева я рассматривал математический трюк когда на сгенерированных котировках при убыточном активе капитал рос, а стратегия купил и держишь медленно обнуляла виртуальный счёт.
Результаты симуляции «токсичного» актива
В комментариях многие справедливо написали что теория — это хорошо, но реальный рынок — это совершенно другое. Что там существует комиссии, проскальзывания, разные режимы торгов, человеческая психология и главное — что я буду делать сам без математика в напарниках?
Так вот, я решил принять этот вызов и самостоятельно, без Дмитрия Шалаева разобраться как похожая стратегия может вести себя на акциях Московской биржи.
Про биржу часто пишут что это казино, но в данном случае я не буду ставить на красное или чёрное, а буду пытаться зарабатывать на самом факте вращения колеса рулетки: на волатильности, обороте и вероятности — то есть буду вести себя как казино, а не как игрок. Казино не знает, кто выиграет следующую раздачу, но оно знает, что в конце дня будет в плюсе.
Как выглядит моё казино
Поскольку я собираюсь построить своё казино, то мне нужен не азарт, а в первую очередь инфраструктура. Если говорить простым языком, то я хочу протестировать свою стратегию на реальных данных Московской биржи.
У меня уже был опыт с готовыми системами, например с библиотекой Backtrader на питоне, но поскольку идея здесь значительно отличается от привычных систем теханализа, то я решил действовать на чистом Python.
Котировки
Поскольку уже достаточно много брокеров предоставляют свои API для частных лиц, то скачать историю котировок совершенно не проблема:
Просто выбираю своего брокера и быстро скачиваю исторические минутные котировки.
Скачиваю котировки акций Мосбиржи через API брокера
Бенчмарк
Дальше скачиваю значения индекса IMOEX2 для бенчмарка. Это оказалось чуть сложнее и поэтому беру значения индекса напрямую через API Московской биржи.
Это занимает чуть больше времени.
Загружаю индекс IMOEX2 для бенчмарка
Нормализация
Все котировки обычно в текстовом формате и содержат OHLCV — это стандартный формат рыночных данных, описывающий ценовое движение актива за определенный период (свечу). Он включает 5 показателей: Open (открытие), High (максимум), Low (минимум), Close (закрытие) и Volume (объем сделок).
Но раз активов очень много и мне не нужны все эти показатели, то написал скрипт который переведёт кодировки из текстового формата в более быстрый Parquet формат файлов и оставит только цены закрытия. Данные занимают в 10 раз меньше места и читаются очень быстро.
Привожу всё к единому формату
Кастинг акций
Дальше написал такой скрипт, который будет делать выборку акций.
Философия здесь была очень простая: мне не нужны акции, которые хорошо растут, как это не странно звучит.
Потому что на растущем рынке зарабатывают все и для этого не нужен ни алгоритм, ни математика, ни мозг. Мне были интересны другие случаи.
Алгоритм идентифицирует временные дисбалансы волатильности — ситуации, когда статистические свойства актива временно выходят за границы устойчивого диапазона.
Я делаю выборку не руками, не учитываю новости и не «чувствую рынок». Это не моя интуиция — это выбор алгоритма, которому всё равно, какие у тикера буквы.
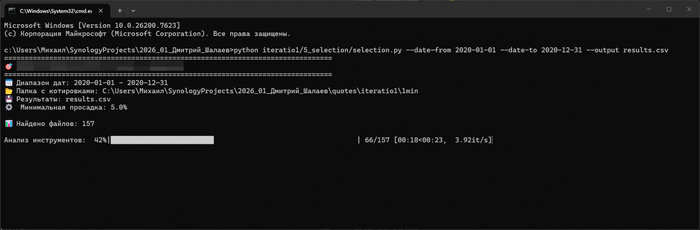
Провожу отбор бумаг
Машина времени
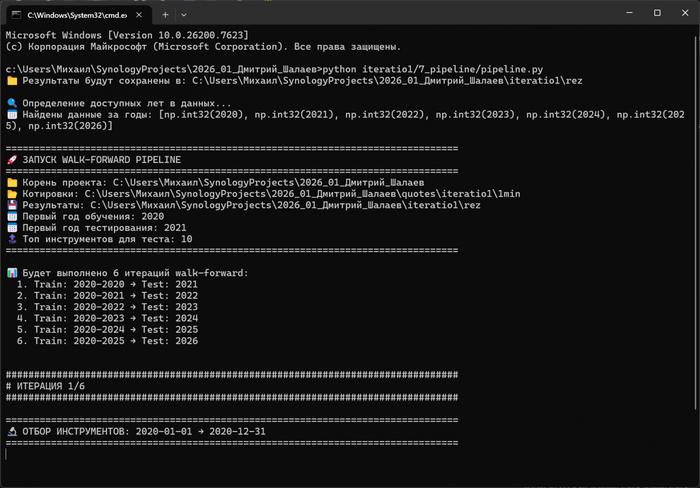
Большинство новичков делают одну и ту же ошибку: подгоняют параметры под всю историю сразу. Это самообман. В реальности у нас нет котировок из завтрашнего дня. Поэтому мой конвейер живет в «скользящем окне».
Шаг 1: система видит только 2020 год. Она анализирует волатильность, отбирает топ-10 самых подходящих акций и формирует портфель. Затем наступает 2021-й — и мы проверяем, сколько денег этот портфель заработал (или слил) на «неизвестных» данных.
Шаг 2: окно расширяется. Система учится на данных 2020–2021 годов. Снова отбор, снова тесты — но уже на 2022-м.
Шаг 3: обучение на 2020–2022, торговля в 2023-м.
Никакого подглядывания в будущее. Если в 2022-м рынок рухнул, а мой алгоритм, обученный на спокойном 2021-м, этого не предвидел — я получаю убыток. Всё как в жизни.
Все шаги вместе
Визуализация процесса
В моих логах запуска pipeline видно что алгоритм проходит год за годом.
И это именно инженерный подход, когда мы не ищем грааль, а тестируем идею и логику.
Пайплайн
Пайплайн — это последовательность этапов, через которые проходит проект от начала до завершения, представляющая собой структурированный рабочий поток, автоматизирующий процесс и обеспечивающий его прозрачность и управляемость
Вся система заработала, при этом она имеет модульную архитектуру и валидные данные.
Но как видно из логов даже самый идеальный код не гарантирует, что можно легко отбирать деньги у других людей на рынке.
Драма в цифрах (2021–2026)
Привожу мою интерпретацию из логов:
2021 — штиль
Рынок рос, алгоритм скучал. Сетка расставлена, но рыба не клюёт: +0,26%. Деньги не теряются, но и не зарабатываются — плата за осторожность.
2022 — идеальный шторм
Рынок рушится, вокруг паника, частные инвесторы теряют по 30–50% депозита. И здесь наступает звёздный час математики: +8,79% за год. Пока люди продавали на эмоциях, алгоритм методично скупал. Не потому что «верил в отскок», а потому что он был заложен в вероятностной модели заранее.
Ниже конкретный пример
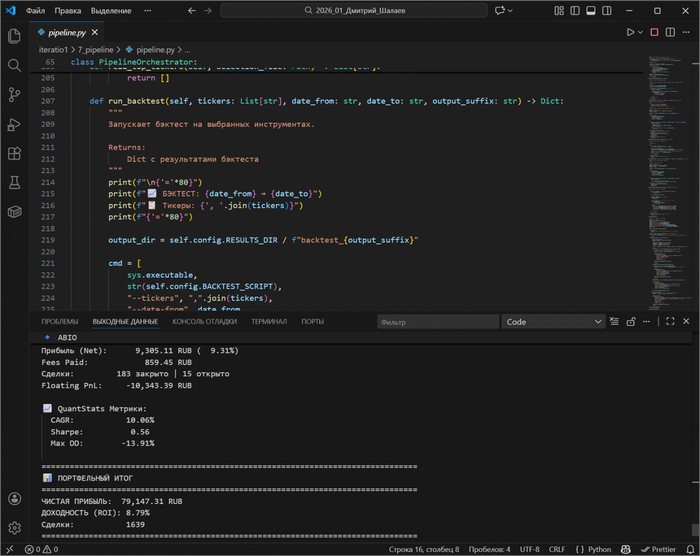
ПАО «Якутская топливно‑энергетическая компания (ЯТЭК)», тикер YAKG
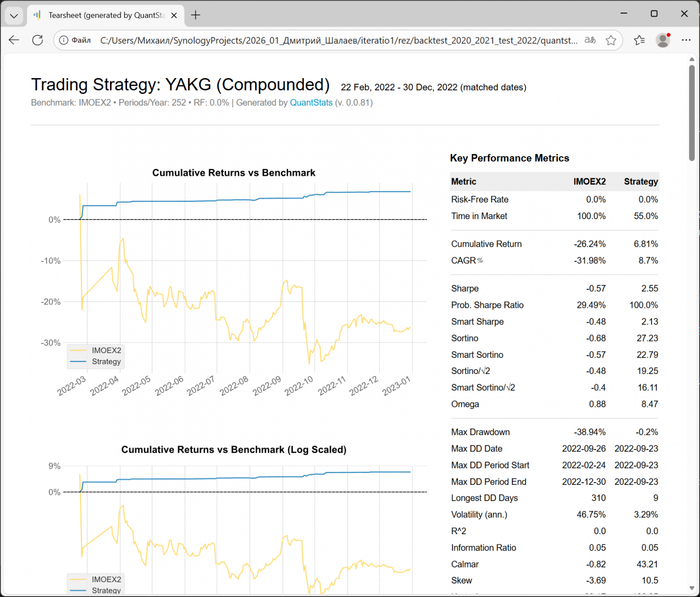
Хороший наглядный пример QuantStats отчета для ПАО «Якутская топливно‑энергетическая компания (ЯТЭК)», тикер YAKG
В этом отчёте YAKG очень наглядны цифры за 2022 года. Пока индекс Мосбиржи (IMOEX2) падал с убытком -26% и просадкой -39%, алгоритм вышел в плюс на 6.81%.
Но настоящая магия — в графе рисков. Max Drawdown стратегии составил микроскопические -0,2%! Пока рынок штормило с волатильностью 46%, а стратегия стояла неподвижно 3,29%. Коэффициент Шарпа 2,55 против рыночного -0,57 доказывает: это не случайность, а математическая победа над хаосом.
2024 — болото
Пилообразное падение без выраженных отскоков. Результат -4,8%.
Итоги
Итог шести лет неутешительный: сложный алгоритм, сотни сделок и… доходность, едва перекрывающая инфляцию.
Математика умеет выживать. Печатать деньги пока нет.
Почему Грааль не сработал: математика против физики рынка
Здесь конечно возникает большой вопрос к идее: если модель корректна, то почему бэктест на истории так слаб?
Думаю что результаты в том числе слабые из‑за учёта комиссий, потому что сделок на некоторых активах было очень много. Потом, у каждого рынка есть своя специфика и Московская биржа не такой уж и волатильный рынок (по сравнению с другими конечно).
И всё же называть мой тест провалом неправильно. За шесть лет, включая 2022-й, система ни разу не слила депозит, а просадки были маленькие.
Вообще похоже на то, что я построил не печатный станок, а сейф — мечту риск‑менеджера и кошмар любителя «иксов».
Главный вывод который я сделал для себя: математика отвечает за выживание, но доходность определяется средой применения этой математики.
Хорошая новость — алгоритм жив. Значит, проблема не в нём, а в полигоне. В следующей статье я планирую ступить на неизведанное для себя плато, туда, где волатильность часто зашкаливает — на крипторынок и посмотреть как тесты поведут себя там. Или буду работать над улучшением версии для Московской биржи. Пока не решил. Как думаете лучше поступить?
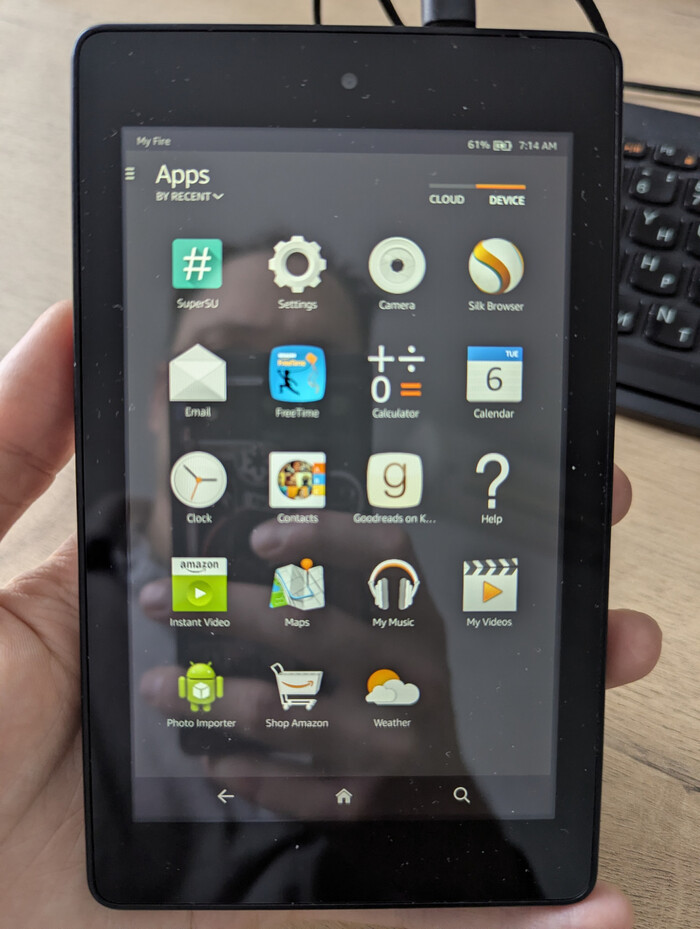
У многих есть старые гаджеты которыми уже сложно пользоваться из‑за их возраста, но они до сих пор работают, причём выкинуть их жалко, а дорого уже не продать. У меня так валялся планшет Amazon Fire HD 6 (Ariel), он 2014 года. На досках объявлений такой стоит около тысячи рублей — ищется по фразе «amazon fire планшет».
Первоначально Amazon Fire HD 6 (Ariel) 2014 года выглядел вот так. 1 ГБ ОЗУ, 8 ГБ памяти, экран 6 дюймов
Как‑то раз я увидел в магазине фоторамку и сразу же подумал про этот старый планшет. Но конечно, самое простое было просто купить готовую фоторамку. Или попробовать без всякой перепрошивки воспользоваться Fire Toolbox чтобы получить расширенный контроль над системой. Но FireOS заточена под amazon, а для меня это не актуально.
А ещё мне было интересно не только увеличение скорости от чистого Android вместо FireOS, но и сам процесс перепрошивки, потому что раньше были времена, когда я активно менял прошивки (ROMs) на своем основном телефоне, экспериментировал с ядрами и модами.
Конечно, рационально — это глупость. Но если вы любите ломать железо — вам сюда. И мне снова захотелось пройти этот квест от получения полного доступа через уязвимость до установки чистого Android.
Но! Если вы не уверены — не повторяйте, так как есть риск превращения планшета в кирпич, всё делается на свой риск. Изначально никакие данные не сохраняем - предполагается что планшет уже сброшен до заводских настроек, а нужные данные сохранены.
Подготовка рабочего окружения
Прежде чем препарировать планшет нужно подготовить компьютер. Подойдёт и на Windows, но мне проще было на Ubuntu.
Понадобятся adb и fastboot. В Ubuntu 24.04 установка инструментов:
Более новые прошивки блокируют получение полного доступа к планшету получение root‑прав, поэтому надо откатиться на определенную версию, для Amazon Fire HD 6 (Ariel) это версия FireOS 4.5.3.
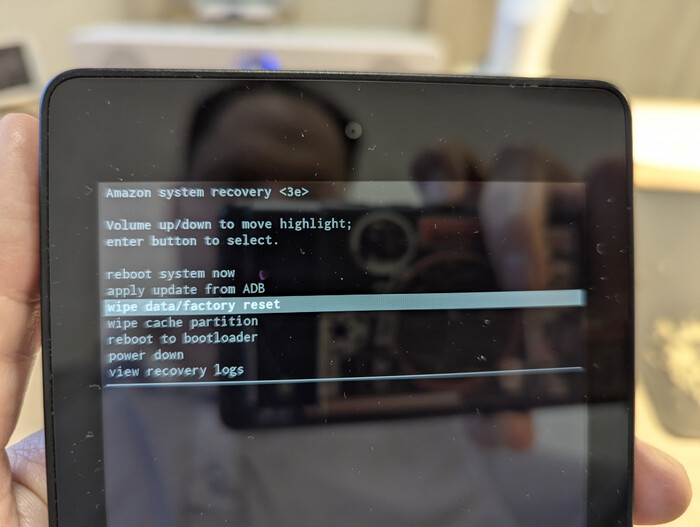
Перезагрузите планшет в режим восстановления — для этого используйте сочетание клавиш увеличить громкость и питание.
Выберите опцию «Применить обновление через ADB» и подключите планшет к компьютеру.
Опция «Применить обновление через ADB» в списке
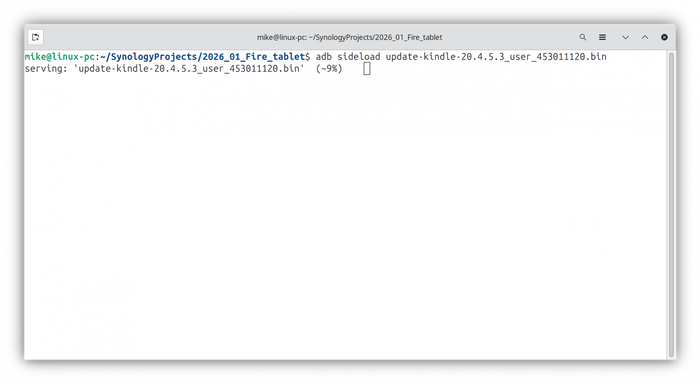
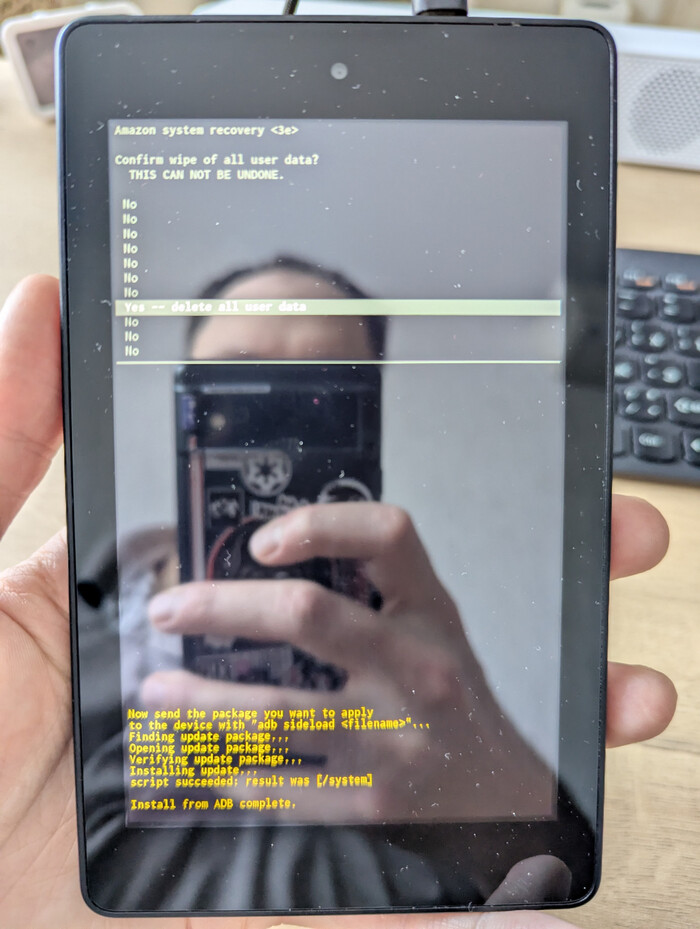
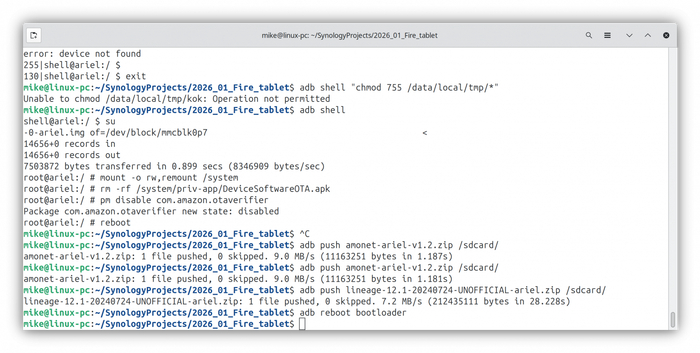
Скачайте update-kindle-20.4.5.3_user_453011120.bin и откройте терминал в той же папке, куда вы загрузили обновление, введите в терминале: adb sideload update-kindle-20.4.5.3_user_453011120.bin
Все файлы (прошивки, amonet, скрипты) лучше искать на профильных ветках XDA или 4PDA по имени файла, так как ссылки со временем умирают.
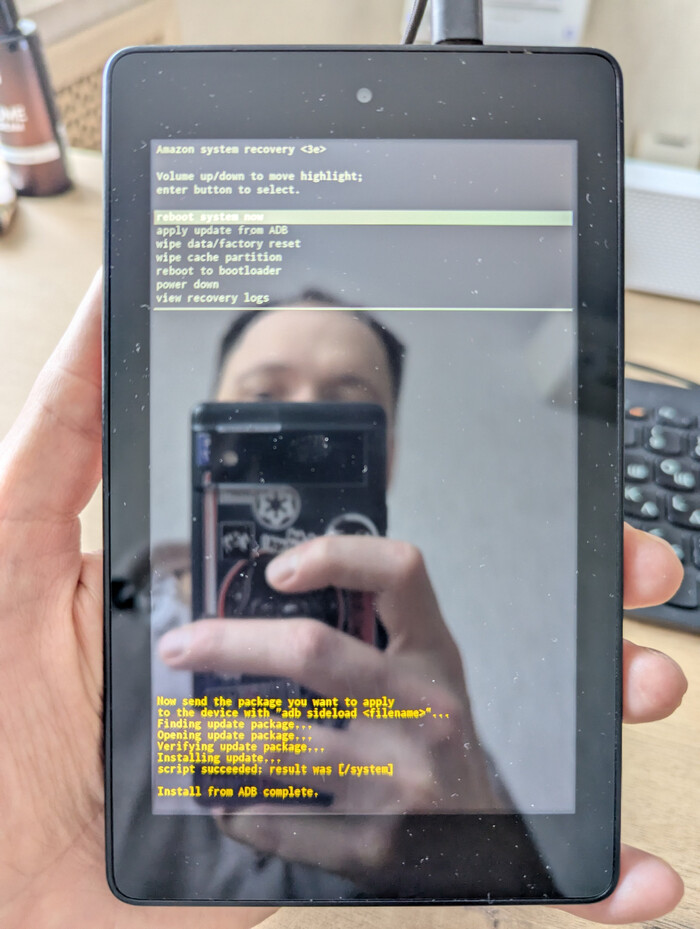
Процесс заливки старой прошивки
Планшет в режиме Recovery с прогрессом загрузки. Главное — не отключайте USB кабель!
Отправка update-kindle-20.4.5.3_user_453011120.bin на планшет
После прошивки делаем wipe data/factory reset и wipe cache partition в том же меню.
wipe data/factory reset
Для сброса надо выбрать правильное подтверждение
При первой загрузке НЕ подключаем Wi-Fi, иначе он снова обновится.
После «обновления» выглядит так:
Скриншот FireOS 4.5.3
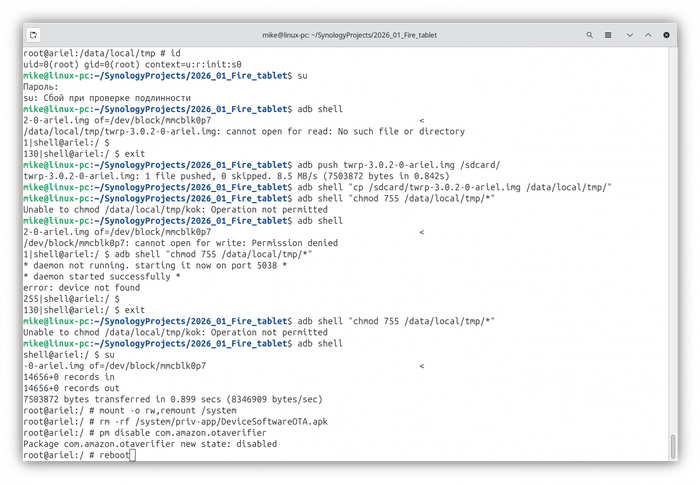
Получение root-прав через метод Dirty Cow
Есть несколько способов получить права суперпользователя, которые позволяют изменять системные файлы и удалять предустановленные приложения, а также дают абсолютный контроль над устройством.
Сделаем всё через скрипты, используя уязвимость ядра.
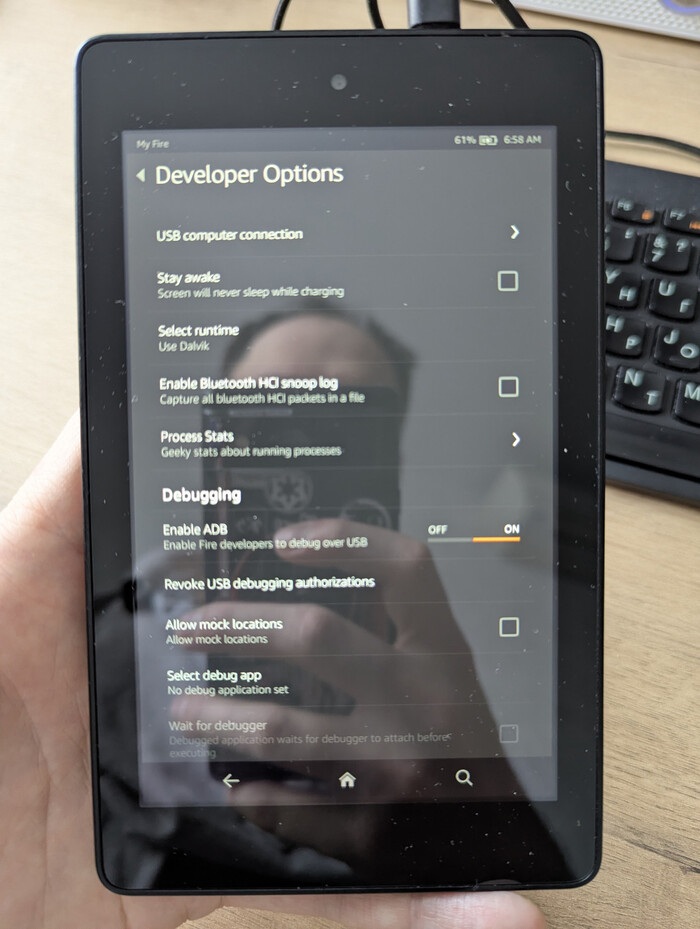
Меню разработчика на FireOS 4.5.3
Включаем на планшете «Отладку по USB» (тыкаем в серийный номер 7 раз).
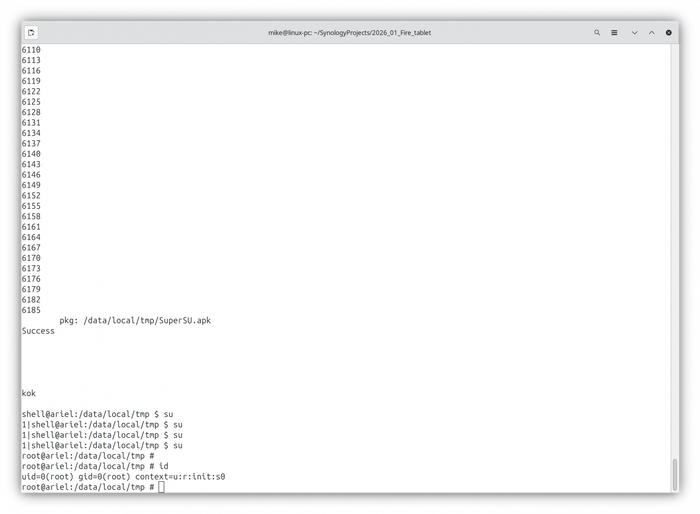
В консоли начнется магия с перебором адресов памяти. Если все прошло успешно, вы увидите заветное Success и kok.
Убедитесь, что всё сработало, получив доступ к корневой оболочке: введя su.
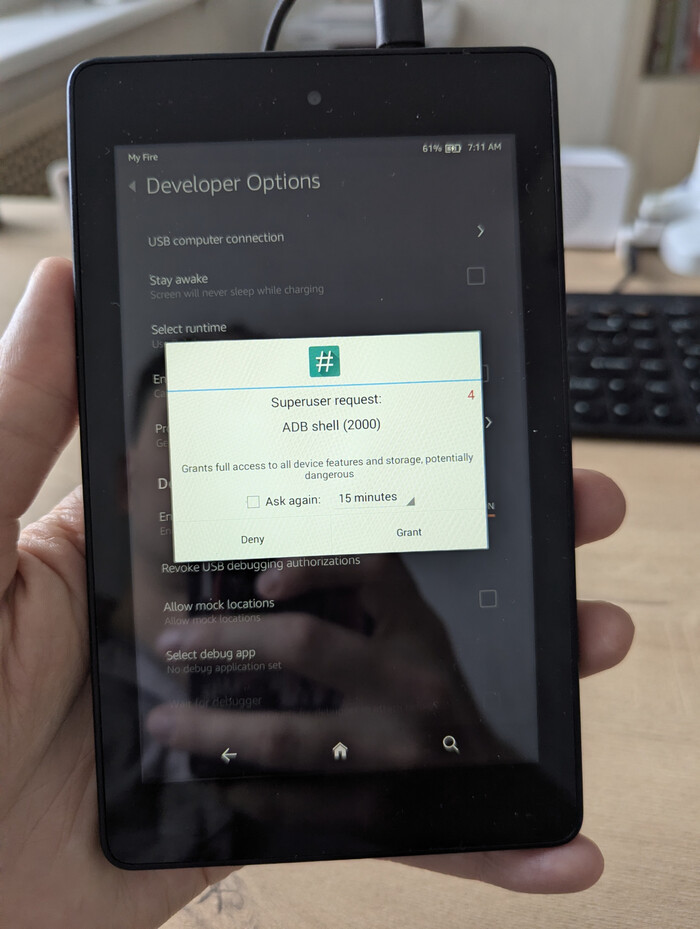
Должно появиться всплывающее окно SuperSU, указывающее на то, что ADB запрашивает права суперпользователя. Просто подтвердите этот запрос и убедитесь, что символ $ изменился на # в консоли (скриншот чуть ниже).
Всплывающее окно SuperSU
Dirty Cow эксплойт сработал
SuperSU в списке приложений FireOS 4.5.3
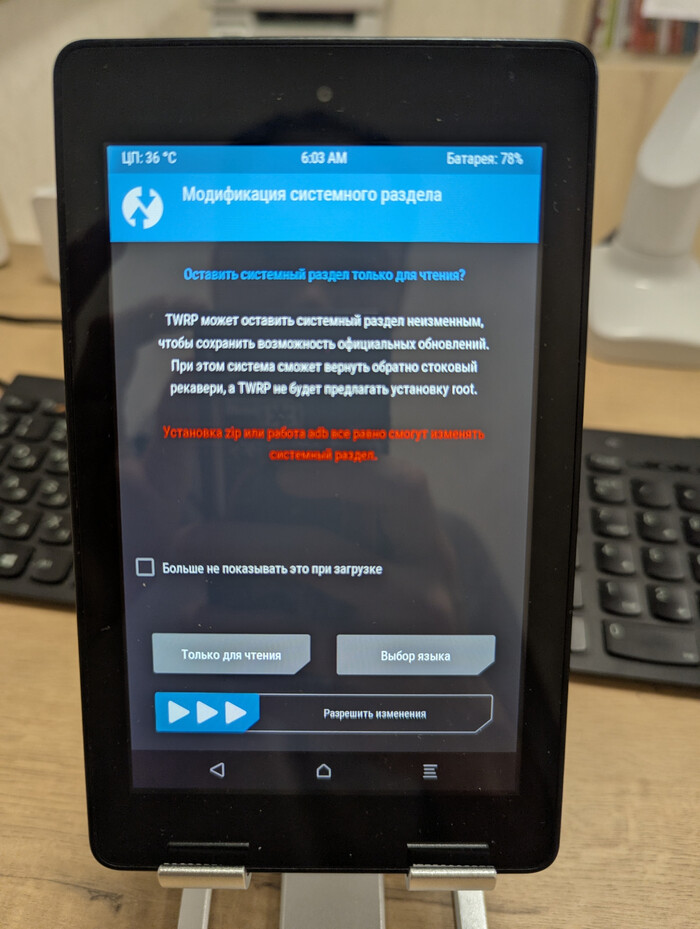
Установка TWRP и отключение OTA
Чтобы Amazon вновь не пробрался на устройство отключаем обновления и ставим загрузчик восстановления TWRP, который заменяет стандартный раздел восстановления вашего устройства. Это нужно для установки сторонних прошивок, ядер, создание полных резервных копий (бэкапов) системы, очистки разделов, управление файлами и многое другое, что недоступно в заводском режиме восстановления.
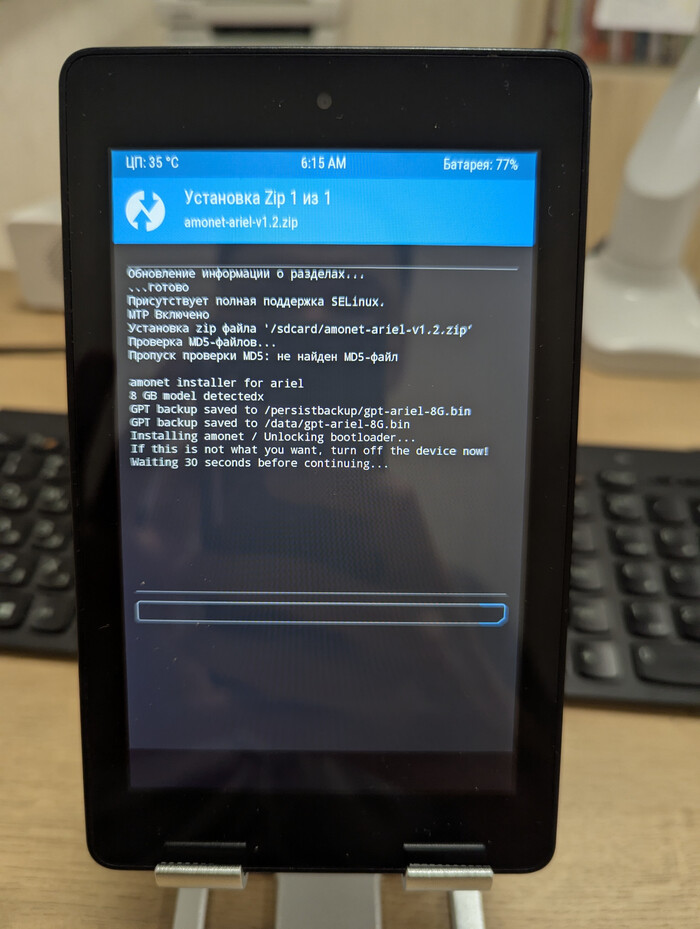
Скрипт сам все сделает и перезагрузит устройство в обновленный TWRP. Теперь путь для кастомных прошивок открыт.
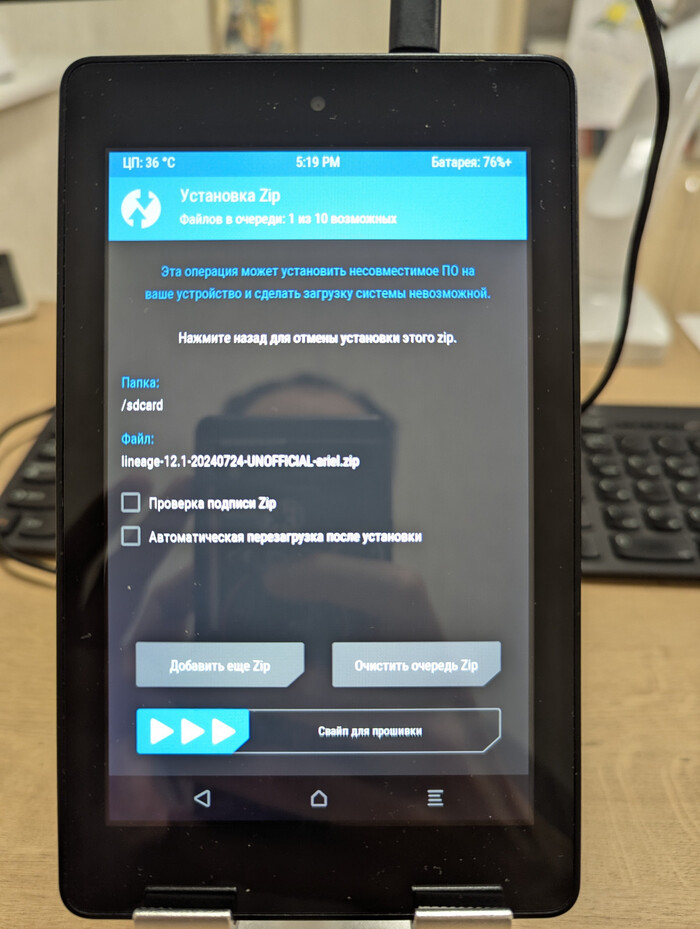
Установка LineageOS и финал
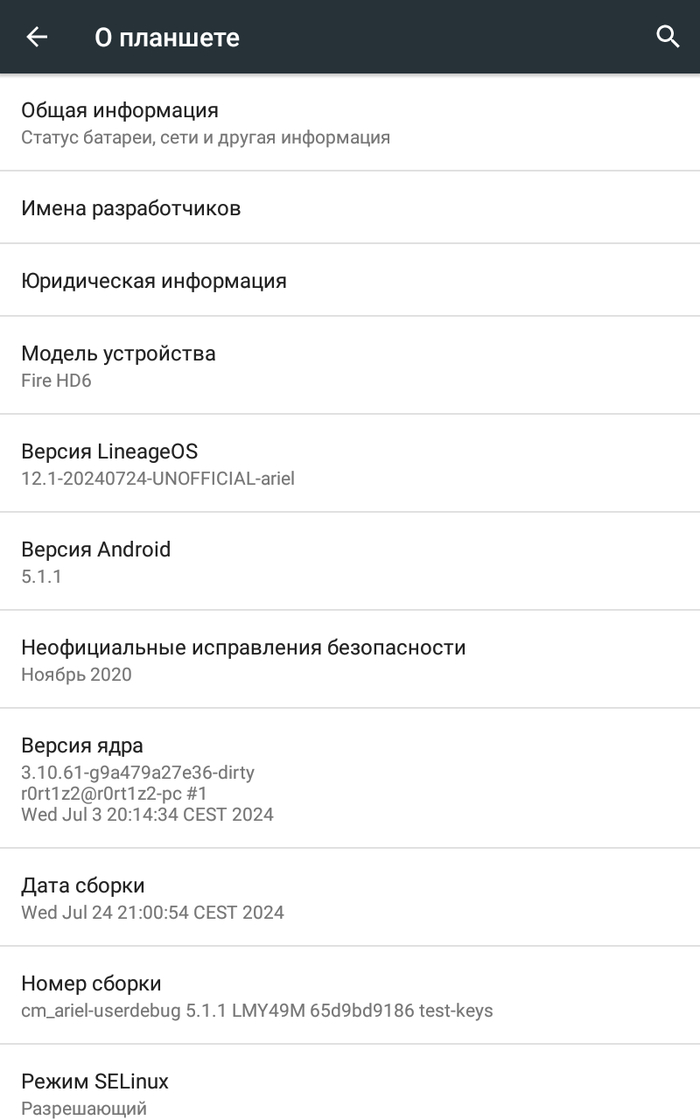
Родная FireOS заточена под amazon, но если использовать устройство как фоторамку все эти функции абсолютно не нужны. Я выбрал LineageOS 12.1 (Android 5.1). Да, в 2026 году когда на пикселях самая последняя версия Android 16 иметь пятую версию Android немного странно, но это буквально максимум который можно выжать из Amazon Fire HD 6 (Ariel), 2014 года 1 ГБ ОЗУ, 8 ГБ памяти, экран 6 дюймов.
И единственный разумный сценарий для Android 5 в 2026 году это локальное, офлайн‑ или изолированное устройство без чувствительных данных без веб‑серфинга и с минимальным набором приложений. В моём случае планшет используется именно так — как автономная фоторамка и потенциальный узел локальной домашней автоматизации, а не как персональное устройство.
Тем более что LineageOS легкая и идеально подходит для задачи «просто показывать картинки».
Закидываем на устройство фотографии, создаём плейлист.
Настраиваем Timers (чтобы экран был активен только в то время, когда кто-то есть в комнате).
Результат:
Итоговый вид. Старый планшет за 0 рублей выглядит не хуже специальных рамок за 7 / 15 тысяч
Ещё как часы может использоваться через Qzey: Большие Часы на Экран
Заключение
Конечно, если смотреть прагматично, то столько усилий ради того чтобы просто показывать картинки это неоправданно. А часы, с обновлением времени через интернет стоят около полутора тысяч рублей на китайской площадке. Ведь пришлось понижать прошивку, эксплуатировать уязвимости ядра, получать права суперпользователя, ломать загрузчик, ставить кастомную прошивку.
Но цель этого была не только в фотографиях. Во‑первых я дать вторую жизнь планшету, который уже давно отжил своё. А во‑вторых результатом стал полноценный android который можно использовать в домашней автоматизации, например подобным образом.
А решить проблему с постоянной зарядкой батареи тоже можно при помощи автоматизации или физическим вмешательством — так у меня уже был опыт когда пару лет назад я взял старый Nexus 7 планшет и извлек батарею — теперь он от 220В через зарядку работает. Не очень просто было, но теперь планшет без батареи. Так что думаю с Amazon Fire HD 6 (Ariel) тоже можно справится.
Nexus 7 3G работает без батареи
Причём на планшете с полностью вырезанной батарей идёт «разряд батереи» — планшет думает что батарея на исходе и выключается примерно через 12 часов, а ведь он запитан на постоянно от 5В. Но это не проблема статьи про Amazon Fire HD 6 (Ariel) — там пока всё на месте.
Конечно, этот путь не для всех, но если у вас есть подобный старый планшет и интерес потратить вечер на то чтобы поковыряться в системе, то такие действия вполне оправданы.