

Самая первая видеокарта
Если понравилось видео, можете подписаться на мой телеграмм канал t.me/neiro_kaa
Всех благодарю за просмотр и особенно комментарии:).
Приятного просмотра.
Показать полностью
Если понравилось видео, можете подписаться на мой телеграмм канал t.me/neiro_kaa
Всех благодарю за просмотр и особенно комментарии:).
Приятного просмотра.
Ну, как говорится, надейся на лучшее, готовься к худшему.
AMD прекращает поддержку оптимизацию игр для видеокарт серии 5000 и 6000. То-есть моя Radeon Rx 6600 уже больше не канает. Если вы хотели получить новые дрова чтобы в Батлу 6 гонять без проблем, то всё, лавочке прикрыта. Также больше не стоит ждать обновлений и новых функций, связанных с трассировкой лучей и FSR.
Напомню, что PlayStation 5 и многие портативные консоли вроде steam deck используют 6000 серию.
Связано это с тем, что AMD хотят сосредоточится на новых технологиях связанных с искусственным интеллектом.
Ладно 5000 серия, Nvidia свои GTX 1000 вот только сейчас официально прекращает поддерживать. Но 6000 вышли совсем недавно, последняя новая модель вышла всё 2 года назад, в октябре 2023 - Radeon RX 6750 GRE. Это вполне производительные карты, тянущие многие современные игры минимум на средних, некоторые и на высоких настройках, если тех оптимизированы.
И вот собираю я сейчас компьютер, и думаю выбрать Radeon Rx 9060tx 16 GB, может 9070 если за удачную цену. А тут такие новости. А если через пять лет, что так-то немного для железа, появится новая более популярная технология, и им тоже крылья подлежат?

Технология расширенного динамического диапазона (HDR) среди устройств отображения изначально появилась в телевизорах. Компьютерные мониторы обзавелись ей чуть позже. На сегодняшний день модели с поддержкой HDR можно встретить как среди топовых, так и в среднем ценовом сегменте. Чем отличаются разные стандарты HDR в мониторах?
Дебютный монитор с поддержкой HDR был выпущен в 2017 году — им стала модель от компании Dell. Тогда еще не существовало единых стандартов для мониторов, поэтому производители были вольны реализовывать технологию на свое усмотрение. Первые стандарты расширенного динамического диапазона для мониторов были разработаны в 2018 году организацией VESA. В 2019 году их список был расширен.

Кроме стандартов организации существуют собственные реализации производителей мониторов, а также комплексы стандартов от производителей видеокарт, куда тоже входят требования к HDR.
VESA DisplayHDR 400
Самый простой из стандартов VESA. Вопросов к реализации подсветки матрицы тут нет, поэтому экраны данного типа чаще всего оснащаются обычной краевой LED-подсветкой. Остальные требования тоже демократичные — стандартные 8 бит на каждый цветовой канал, а уровень свечения чёрного не должен превышать 0,4 нит.
По сути, отличие от обычных мониторов тут только в пиковой яркости: вместо типичных 250–300 нит требуются 400 нит. Из-за относительной простоты реализации DisplayHDR 400 — это один из самых распространённых стандартов, который встречается в мониторах и ноутбуках.
HDR10
Стандарт HDR, перекочевавший в мониторы из телевизоров. Использует 10-битное представление цвета, но не имеет жестких требований к реализации подсветки и пиковой яркости. Стоит отметить, что именно с этим стандартом в мониторах связано больше всего путаницы. Из-за отсутствия строгих требований шильдиком «HDR10» могут обладать мониторы с яркостью всего 250–300 нит. Как вы понимаете, настоящего HDR там и близко нет.

Более того, некоторые модели могут быть указаны как «HDR10 ready» или «HDR ready». Под этими словами подразумевается способность монитора принимать и выводить 10-битный сигнал, в то время как его матрица может быть обычной 8-битной. Такие модели к реальному HDR имеют еще меньше отношения.
Acer HDR350
Реализация от Acer, схожая со стандартом DisplayHDR 400. Главное отличие — более низкая яркость в 350 нит.

По рекомендациям компании Microsoft дисплей с HDR должен обладать яркостью не менее 300 нит, поэтому условно HDR350 в категорию расширенного динамического диапазона попадает. На практике эта реализация — одна из самых бюджетных.
VESA DisplayHDR 600
Более продвинутый стандарт VESA, который заметно отличается от базового DisplayHDR 400. Требует локального затемнения для разных зон, но не ограничивает его реализацию: это может быть как краевая подсветка, так и более продвинутая задняя. Чаще всего в продуктах данной категории встречается первый вариант.
Прочие требования по сравнению с DisplayHDR 400 тоже увеличены. Обязательна 10-битная глубина цвета, уровень свечения черного не выше 0.1 нит и пиковый уровень яркости не менее 600 нит. Из-за более сложной конструкции такие мониторы дороже решений c DisplayHDR 400.
VESA DisplayHDR 500
Произвольная от стандарта DisplayHDR 600, предназначенная для тонких экранов ноутбуков. Требования схожи с «родителем», за исключением яркости: здесь она должна быть не менее 500 нит.
VESA DisplayHDR 1000
Стандарт для топовых мониторов, которые предназначены для энтузиастов, профессионалов и создателей контента. Требует минимальный уровень свечения черного в 0.05 нит, который невозможно организовать без задней многозонной подсветки. К тому же, и пиковая яркость тут должна быть заметно выше: не менее 1000 нит. Обязателен и 10-битный цвет.
Из-за столь высоких требований мониторы с поддержкой стандарта требуют мощных диодов подсветки, расположенных сзади экрана, а также увеличенного количества зон. Поэтому такие модели получаются достаточно толстыми, тяжелыми и очень дорогими.
VESA DisplayHDR 1400
Самый продвинутый стандарт VESA, предназначенный для ультимативных решений. По сравнению с DisplayHDR 1000 повышены требования. Теперь пиковая яркость должна составлять от 1400 нит, а уровень свечения черного должен быть еще ниже — 0.02 нит. Стоит ли упоминать, что такую сертификацию получают только самые дорогие модели мониторов.
VESA DisplayHDR 400/500/600 TrueBlack
Серия стандартов для мониторов и экранов ноутбуков, выполненных по технологии OLED. В экранах данного типа каждая точка светится самостоятельно, поэтому в стандартах TrueBlack заметно повышены требования к уровню чёрного: его свечение не должен превышать 0.0005 нит.

Изменились и требования к задержке переключения подсветки. У серии обычных стандартов DisplayHDR она должна составлять не более восьми кадров, независимо от частоты обновления экрана. У линейки DisplayHDR TrueBlack — не более двух кадров. Между собой стандарты DisplayHDR 400/500/600 серии TrueBlack отличаются только пиковой яркостью — она должна составлять не менее 400, 500 и 600 нит, соответственно. Благодаря абсолютному черному цвету даже на такой яркости OLED экраны могут обеспечить уровень контрастности, сравнимый с мониторами DisplayHDR 1000/1400 на LED-подсветке.
Quantum HDR
Фирменная реализация HDR на топовых мониторах от Samsung. В основе лежит стандарт HDR10+ для телевизоров, разработанный этой же компанией. Аналогично прямому родственнику, использует 10-битную глубину цвета и умеет работать с динамическими метаданными.
Quantum HDR подразумевает использование квантовых точек в экране и технологии miniLED — разновидности задней подсветки, которая по сравнению с обычной многозонной подсветкой обладает увеличенным диодов и зон. За счет такой комбинации заметно снижается уровень свечения черного, а также заметно возрастает пиковая яркость.

Именно яркостью и отличаются разные реализации Quantum HDR. Она, в зависимости от модели монитора, может отображаться в названии технологии двумя способами:
Quantum HDR 1000/1500/2000/4000 обозначает пиковую яркость экрана в 1000, 1500, 2000 и 4000 нит, соответственно. Под Quantum HDR 12x/16x/24x/32x/40x подразумеваются множители базовой яркости, за которую принято значение в 100 нит. То есть, такие экраны могут достигать пиков в 1200, 1600, 2400, 3200 и 4000 нит, соответственно.
Для последних моделей таких мониторов вдобавок указывается технология «HDR10+ Gaming». Она является вариантом стандарта HDR10+ специально для игр, который совместим со всеми моделями с Quantum HDR.
Dolby Vision
Стандарт от Dolby Laboratories, помимо телевизоров иногда встречающийся в профессиональных мониторах. Работает с 10- или 12-битным цветом, поддерживает динамические метаданные. Требуемая пиковая яркость — от 1000 нит и выше.

Конкретный тип подсветки стандартом не упоминается, но экраны с такими характеристиками в обязательном порядке оснащаются задней LED-подсветкой с разделением на зоны, либо матрицами OLED.
NVIDIA G-Sync Ultimate
Топовый стандарт динамической синхронизации кадров от NVIDIA. Конкретные требования не указываются, но обязательны «HDR, потрясающая контрастность и кинематографичные цвета». Модели, прошедшие такую сертификацию, имеют от 600 нит пиковой яркости и 10-битную матрицу. Другой обязательный атрибут — многозонная LED-подсветка, либо OLED-экран.
AMD FreeSync Premium Pro
Старший стандарт динамической синхронизации кадров от AMD. Обязателен 10-битный цвет и от 400 нит пиковой яркости. Официальных требований к реализации подсветки нет. Но, как и в случае с конкурентом, все совместимые модели оснащаются или многозонной LED-подсветкой, или OLED-экраном.
Как правило, для любого монитора с G-Sync Ultimate или FreeSync Premium Pro может дополнительно указываться одна из сертификаций DisplayHDR.

Некоторые производители мониторов указывают в характеристиках HDR, но не упоминают о его принадлежности к какому-то стандарту. В таких случаях речь чаще всего идет о бюджетной реализации, не дотягивающей даже до спецификаций базового DisplayHDR 400.
Для вывода HDR-картинки на монитор нужен компьютер с относительно современной видеокартой. Дискретные модели, поддерживающие вывод HDR, начинаются со следующих линеек:
NVIDIA: серия GeForce GTX 900 и выше
AMD: серия Radeon RX 400 и выше
Intel: серия ARC
Помимо этого, вывод HDR поддерживают и встроенные видеокарты:
AMD: серия RX Vega и выше
Intel: серия UHD 600 и выше
На ПК должна быть установлена Windows 10 или Windows 11, а также кодеки из Microsoft Store для воспроизведения видео с 10-битной глубиной цвета — HEVC и VP9. Поддерживает его и перспективный AV1, хотя пока контента в нем мало.
В отличие от телевизоров, где HDR-контент обычно запускается автоматически, в ОС Windows режим HDR необходимо включить и отрегулировать вручную, следуя инструкции от Microsoft.
Поддержка Windows 10 прекратится в октябре 2025 г.
После 14 октября 2025 г. корпорация Майкрософт больше не будет предоставлять бесплатные обновления программного обеспечения из Центра обновления Windows, техническую помощь и исправления безопасности для Windows 10. Ваш компьютер по-прежнему будет работать, но мы рекомендуем перейти на Windows 11.
Контент, доступный на ПК в расширенном динамическом диапазоне — это видео и игры. HDR-фильмы доступны на стриминговых площадках Netflix, Amazon Video, Disney+, AppleTV+, HBO Max, а также Ultra HD Blu-ray дисках. Видеоролики с HDR можно найти на Youtube. Многие современные игры поддерживают HDR «из коробки», а на некоторые проекты можно установить соответствующие моды. Немного улучшить картинку в старых играх можно и с помощью технологии Auto HDR, присутствующей в Windows 11.

На словах звучит хорошо, но на деле у HDR под Windows достаточно много проблем. Стриминговые сервисы заточены под телевизионные стандарты HDR, поэтому могут некорректно отображать такой контент на ПК. Реализация HDR в некоторых играх тоже хромает, не всегда принося желаемый эффект.

Несмотря на то, что у Windows имеется настройка баланса яркости между SDR и HDR-режимами, на некоторых мониторах даже с ее помощью трудно добиться правильного отображения любого контента. В итоге картинка может казаться либо слишком тёмной, либо слишком светлой. Чаще всего таким грешат модели с простыми реализациями HDR, которые для достижения нужного эффекта жертвуют цветопередачей. Поэтому обычный SDR-контент может выглядеть на них даже лучше.

Также нужно помнить, что компьютерный монитор находится достаточно близко от глаз. Высокая яркость на близком расстоянии вредит им намного больше, чем на расстоянии нескольких метров, как в случае с телевизором. Особенно, если монитор используется в темноте.
Для удобства сравнения между собой, объединим требования разных стандартов HDR-мониторов в таблице.
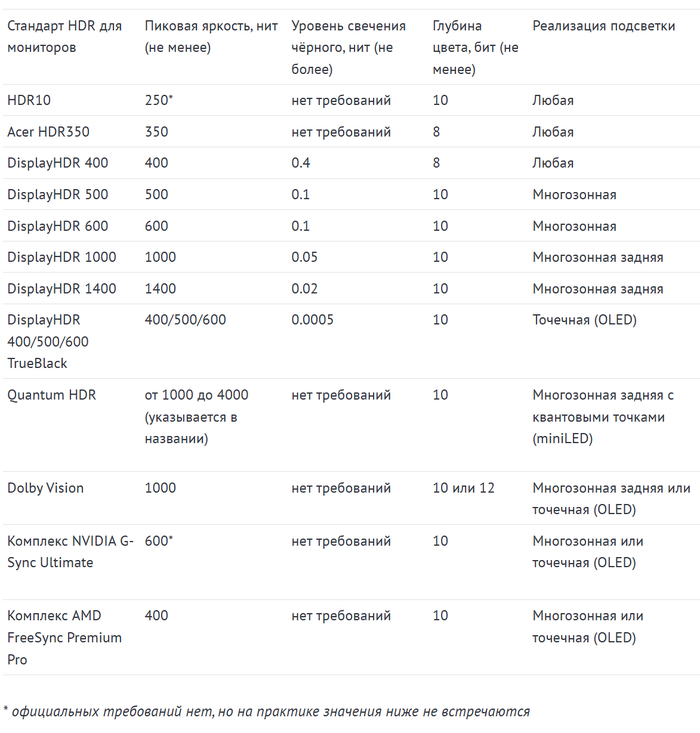
P/S
Кому интересно. Основные характеристики практически всех существующих мониторов с поддержкой HDR можно найти здесь.

Тематическое издание Wccftech со ссылкой на данные портала MyDrivers сообщает, что в сети появились первые результаты тестирования китайской видеокарты Moore Threads MTT S90.
Тесты провел блогер с ником Chaping. Стоит отметить, что в реальности он тестировал профессиональный графический ускоритель MTT S4000. Однако последний построен на базе того же GPU, что и MTT S90. При этом блогер сумел раздобыть для карты специализированные бета-драйверы, предназначенные для MTT S90.
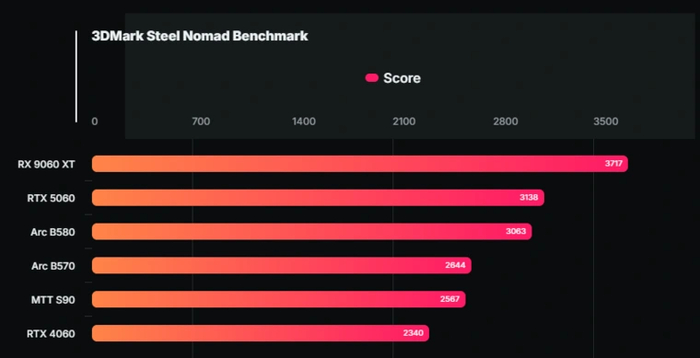
И в итоге китайская видеокарта смогла набрать 2567 баллов в бенчмарке 3DMark Steel Nomad, что на 10 % выше показателей GeForce RTX 4060 (2340 баллов). Помимо этого адаптер выдал весьма солидный результат в бенчмарке Unigine Valley.
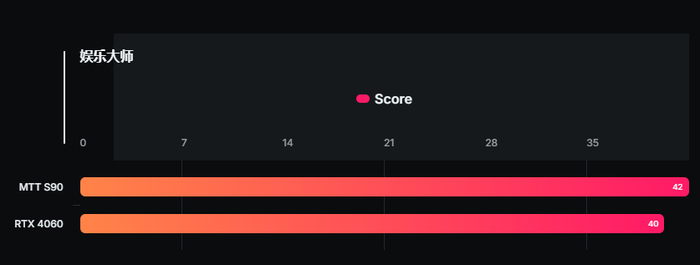
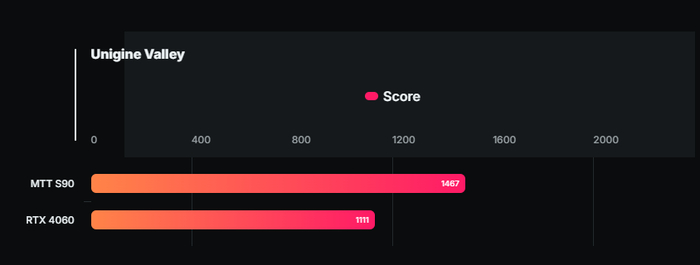
Здесь ему удалось набрать 1467 баллов, обогнав GeForce RTX 4060 (1111 баллов) на 32 %. Наконец, карта выдала 42 fps в Naraka: Bladepoint с разрешением 4К и высокими настройками графики. Для сравнения, GeForce RTX 4060 обеспечивает в аналогичном сценарии лишь 40 fps.
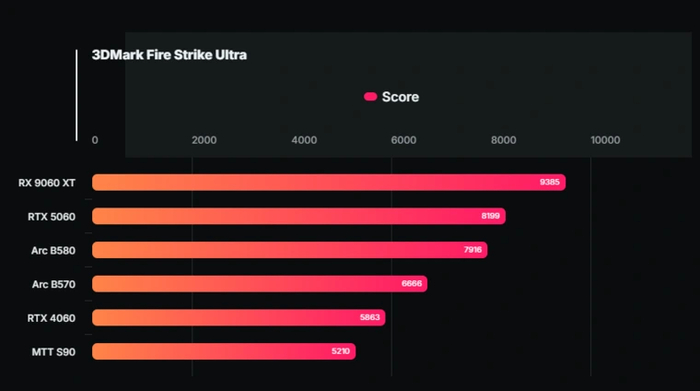
А вот в 3DMark Fire Strike Ultra вперед вырвалась видеокарта NVIDIA. MTT S90 набрала здесь 5210 баллов, что на 11 % меньше показателей GeForce RTX 4060.

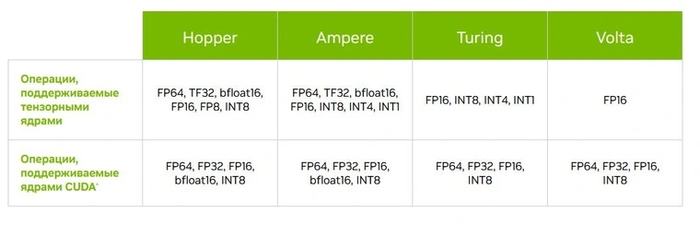
Выпуск серии видеокарт RTX20 в свое время стал важнейшим событием в сфере компьютерных технологий. Десктопные видеокарты впервые получили отдельные тензорные ядра. Что это такое? Как работают эти ядра и для чего используются?
Работа с графикой — специфическая задача для компьютерного «железа». Здесь требуется выполнять довольно однообразные команды с большим объемом данных. Архитектура CPU для этого подходит плохо. Из-за ограниченного числа ядер и АЛУ (арифметико-логических устройств) процессоры не могут быстро делать объемные операции по сложению и умножению.
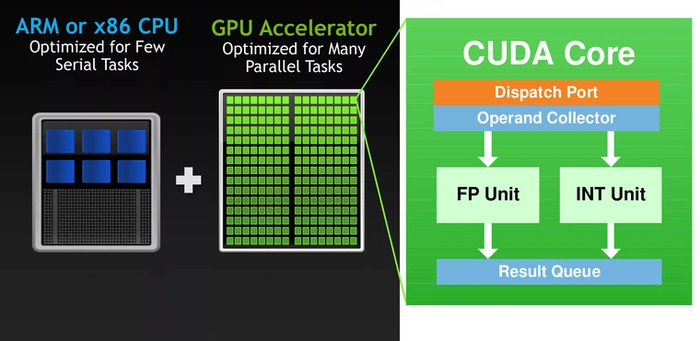
Был необходим максимальный параллелизм — одновременная обработка данных. Одним из решений стали CUDA-ядра — технология, созданная Nvidia больше десяти лет назад. Эти ядра создали специально для параллельной работы. На чипе помещались сотни и тысячи CUDA-ядер, а их число стало одним из критериев оценки производительности видеокарты.
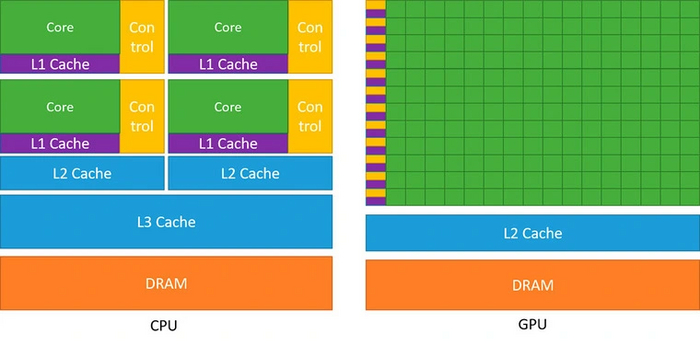
CUDA-ядра имеют высокоскоростной доступ к видеопамяти, так что обработка выполняется с минимальными задержками. Это важнейший показатель для быстрого вывода подготовленных кадров на монитор.
Однако обработка больших объемов данных нужна не только при выводе графики. Она требуется для научных вычислений, моделирования физических процессов и машинного обучения. Во всех этих задачах одна из главных операций — перемножение матриц.
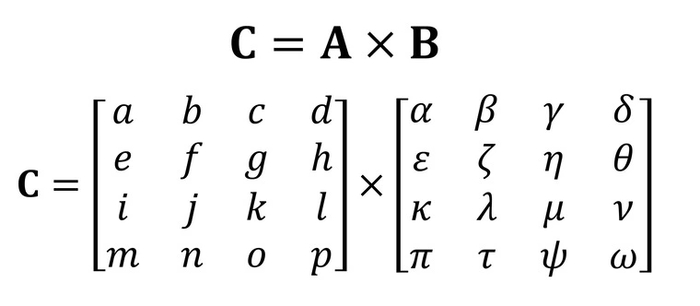
Задача непростая. Скажем, для решения вышеописанного примера нужны целых 64 умножения и 48 сложений. Не говоря о том, что промежуточные результаты нужно еще где-то хранить. Для операций чтения и записи нужны дополнительные регистры и достаточно скоростная кэш-память.
Может ли с этой задачей справиться CPU? Вообще-то, да. Специально для таких вычислений в процессорах начали появляться инструкции MMX, SSE и (самые совершенные) AVX. Однако видеокарты с их многочисленными CUDA-ядрами — более предпочтительный вариант. Они могут распараллелить большую часть простых операций сложения и умножения. Но даже для них задача просчета матриц оставалась трудоемкой. Решением стали тензорные ядра.
Одно такое ядро способно перемножить две матрицы за один такт. В то время как CUDA-ядрам требуется несколько тактов.
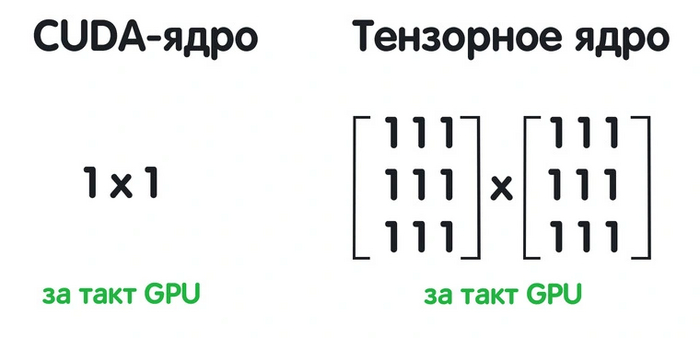
Первое тензорное ядро представляло собой микроблок, выполнявший суммирование-произведение матриц 4x4. Могли использоваться значения FP16 (числа с плавающей запятой размером 16 бит) или умножение FP16 с добавлением FP32.
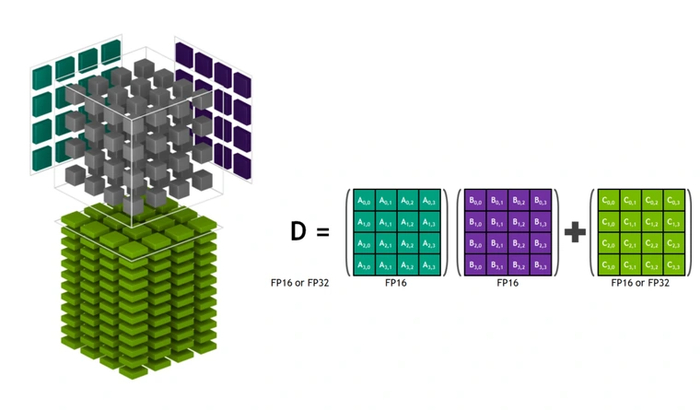
Размерность рабочих матриц невелика. Ядра при обработке реальных наборов данных обрабатывают небольшие блоки более крупных матриц, в итоге формируя окончательный ответ.
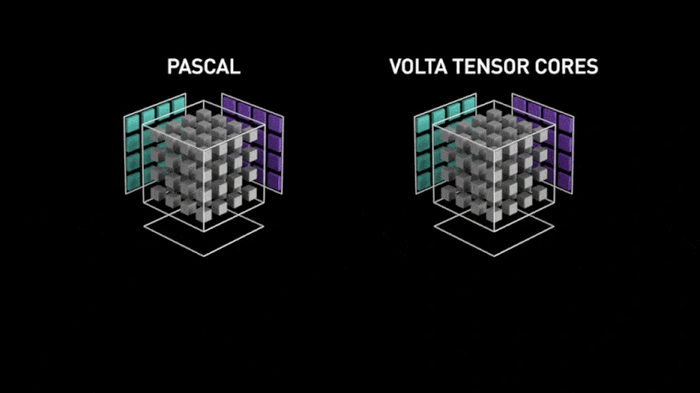
Решение оказалось крайне эффективным. Специалисты из Anandtech провели замеры производительности топовых решений от Nvidia — без тензорных ядер и с ними.

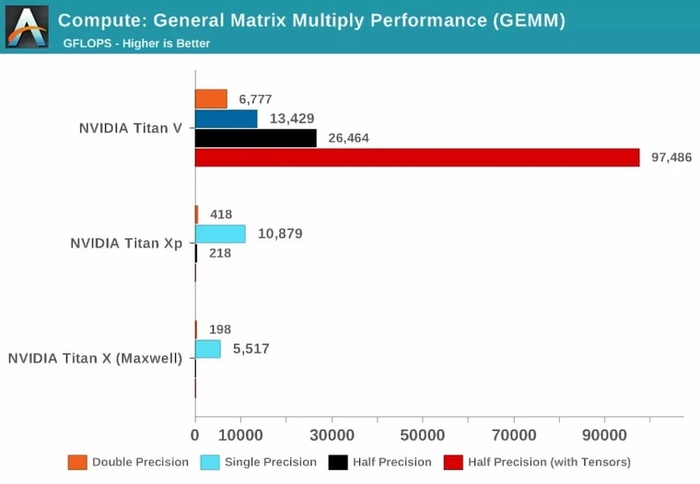
В операциях перемножения матриц (GEMM) прирост производительности с использованием тензорных ядер колоссальный.
Тензорная математика активно используется в физике и инженерии для решения всех видов сложных вычислений. Например, в механике жидкостей, электромагнетизме, астрофизике, медицине и климатологии. В суперкомпьютерах для этих задач обычно используют крупные кластеры с тысячами высокопроизводительных процессоров уровня Xeon Platinum или AMD Epyc. Однако видеоускорители стали неотъемлемой частью практически любого суперкомпьютера. Подавляющее число машин из рейтинга Top500 работают на базе решений от Nvidia.

Задача глубокого обучения в самом простом смысле — это работа с математическими выражениями. Простейший вариант — нейронная сеть, состоящая из одного слоя с двумя нейронами и линейными функциями активации. Представлена она вот таким умножением вектора на матрицу:
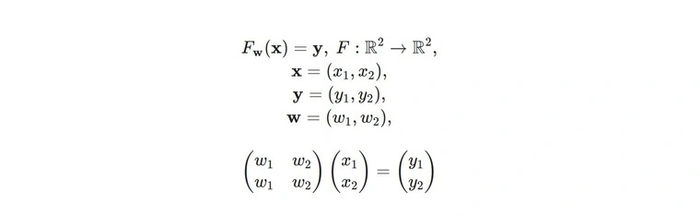
Задача обучения сводится к поиску наилучших коэффициентов W. То есть предполагаются матричные операции.
На практике нейросети чаще всего многослойные, и математические выражения получаются куда сложнее. Однако принципиально используются все те же действия — умножение и сложение матриц. Тензорные ядра как раз ориентированы на эти действия.
Самый яркий пример — суперкомпьютер, созданный Microsoft совместно c OpenAI. В нем использовали 10 тысяч графических процессоров Nvidia V100. Именно этот компьютер применили для обучения ChatGPT-3. Продукты Nvidia можно найти в Microsoft Azure, Oracle Cloud и Google Cloud.

Илон Маск для своего ИИ Grok также задействует продукцию Nvidia. Изначально это был кластер на 20 тысяч графических процессоров H100. Недавно для обучения версии GROK 3 миллиардер запустил суперкомпьютер с сотней тысяч NVIDIA H100! Теперь вы можете понять, почему NVIDIA стала самой дорогой компанией и продолжает наращивать прибыль.
Инференс — это запуск уже обученной модели, «скармливание» данных и получение результата. Процесс менее требователен к вычислительной мощности. Но здесь все так же используются матричные операции. Сюда входит распознавание текста (например, в голосовых помощниках), поиск объектов на изображении (распознавание лиц, номерных знаков), шумоподавление и не только.
Тензорные ядра и здесь предлагают высокую производительность. Они позволяют запускать «легкие» нейросети прямо на домашних видеокартах средневысокого ценового сегмента. Например, запустить Chat with RTX — тут достаточно RTX 30 или 40 серии с минимум 8 ГБ видеопамяти. Stable Diffusion также можно запустить локально на видеокартах. Однако производительность каждой модели зависит еще и от ПО. Оно не всегда в полной мере задействует те же тензорные или CUDA-ядра.
Один из самых доступных вариантов инференса нейросетей — технология DLSS. Специально обученная на игре нейросеть запускается на тензорных ядрах видеокарты, повышая разрешение картинки в реальном времени. Игрок, в свою очередь, получает более высокий FPS. DLSS 3 работает только на видеокартах серии RTX40.
Поскольку это авторская разработка «зеленых», то именно «тензорные ядра» можно найти лишь в продукции этой компании.
Впервые появились в Nvidia TITAN V в 2017 году — карта имела 640 ядер. После этого ядра стали неотъемлемой частью профессиональных ускорителей


С каждой новой архитектурой появлялось усовершенствованное поколение тензорных ядер. Так что сравнивать их число в рамках разных поколений некорректно. Есть и различия в поддерживаемых форматах данных. Первые ядра могли складывать матрицы с данными только FP16, а современные имеют поддержку куда больших форматов.
В десктопных и мобильных видеокартах технология стала доступна с приходом серии RTX20.
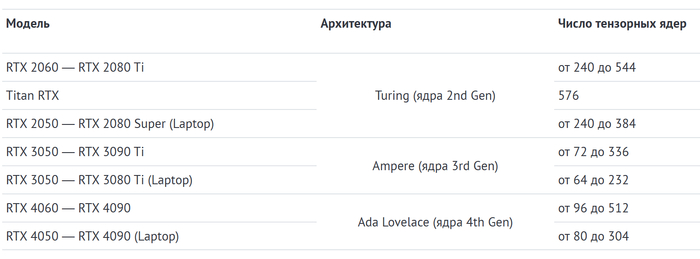
Именно благодаря тензорным ядрам пользовательские карты RTX можно использовать для работы с нейросетями. А также получить апскейл с использованием ИИ. Альтернативные технологии вроде XeSS и FSR базово специальных ядер не требуют.
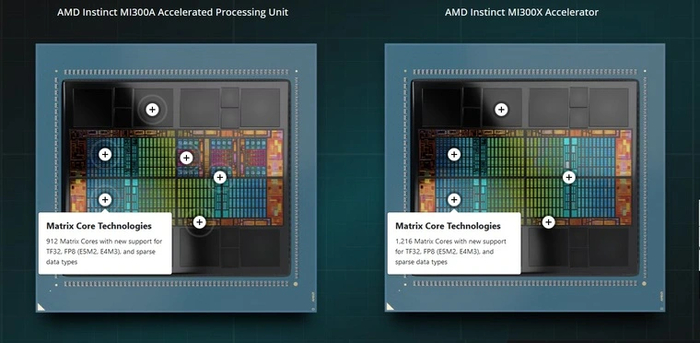
Компания «красных» на рынок ИИ вышла относительно недавно. Аналогом тензорных ядер у них является Matrix Core Technologies, которая появилась в архитектуре CDNA 3.

Ядра Matrix Core Technologies пока встречаются только в AMD Instinct MI300A (912 штук) и MI300X (1216 штук). Новые ИИ-ускорители планируют поставить в немецкие суперкомпьютеры Hunter и Herder — в 2025 и 2027 годах соответственно. Сейчас же у немцев работают суперкомпьютеры Hawk и JUWELS на базе Nvidia A100.
У «синих» используются ядра XMX (Xe Matrix Extensions), созданные специально для матричных вычислений. На них аппаратно работает и фирменный апскейлер Intel XeSS. Встретить ядра XMX можно в линейке видеокарт ARC.
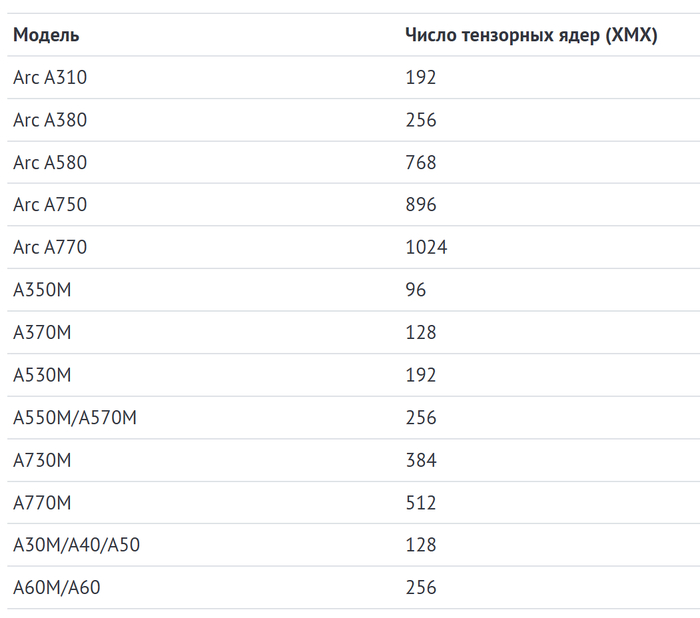

Ядра XMX используются и в Intel Xᵉ HPC 2, установленных в Data Center GPU Max. Графика Xe2-LPG будет встроена в процессоры Lunar Lake. Там также будут использоваться XMX-ядра для задач, связанных с работой ИИ.
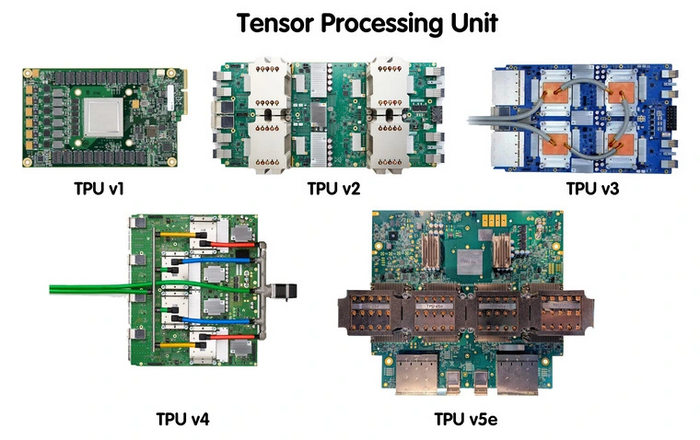
В компании не стали изобретать отдельные ядра, а нацелились сразу же на разработку полноценных плат. Они получили название TPU — Tensor Processing Unit. Эти платы специализируются на обработке матриц. Они подходят как для тренировки, так и выполнения нейросетей.

В марте 2025 года состоялся выход первых видеокарт AMD из долгожданной линейки Radeon RX 9000. Их основой стала архитектура RDNA четвертого поколения, в которой было сделано множество доработок как для улучшения производительности, так и для поддержки современных графических технологий.
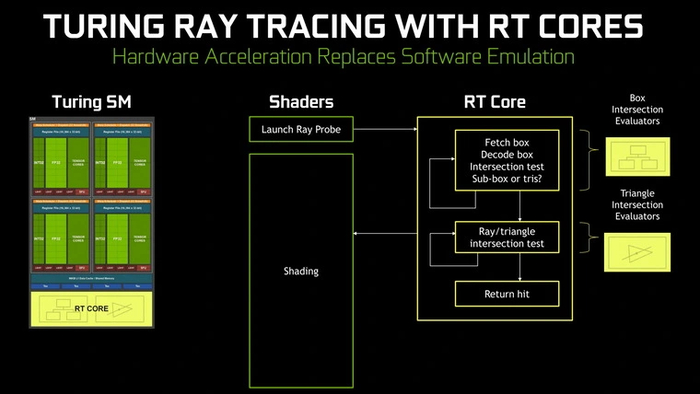
Направление развития технологий, использующихся для 3D-графики реального времени, не раз менялось. Его последний крупный поворот был совершен компанией NVIDIA в 2018 году, когда была представлена графическая архитектура Turing. Ориентация на трассировку лучей и сопутствующие технологии для ее адекватной работы потребовали добавления в графические процессоры новых блоков, которые не участвовали в традиционной растеризации.
Подобный подход был встречен прохладно. Линейку видеокарт RTX 2000 критиковали за низкий прирост «чистой» производительности, а первые реализации трассировки лучей в играх выглядели не очень впечатляюще. Многие сходились во мнении, что «Транзисторный бюджет, выделенный на RT-ядра и тензоры, потрачен зря. Лучше бы шейдеров добавили».
За этой ситуацией наблюдал и давний конкурент в лице AMD, который тогда разрабатывал новую графическую архитектуру под названием Radeon DNA. Решив, что для аппаратной трассировки лучей слишком рано, компания не стала наспех вносить какие-то изменения в RDNA. Летом 2019 года она выпустила первые видеокарты серии RX 5000, у которых поддержки этой новомодной технологии еще не было.
Но время шло, и менее чем через год после выхода RX 5000 появились слухи о следующей линейке NVIDIA — RTX 3000. Поняв, что для конкуренции без трассировки лучей никак, AMD стала работать над интеграцией технологии в архитектуру RDNA второго поколения. Но, в отличие от конкурента, компания не стала тратить на это огромный транзисторный бюджет. Она сделала собственные блоки Ray Accelerator проще, переложив часть работы по трассировке на универсальные шейдерные процессоры.
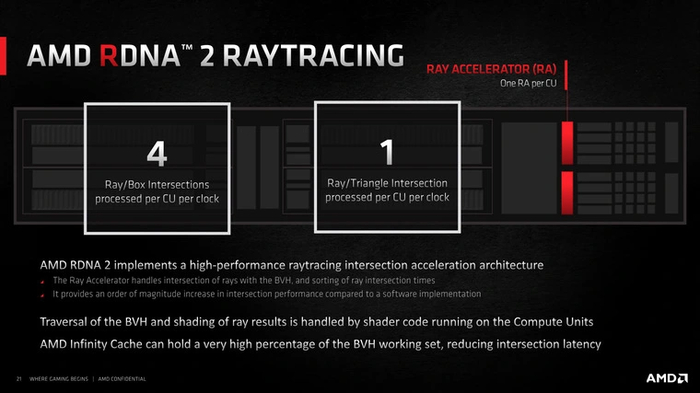
С выходом серий RTX 3000 и RX 6000 конкурирующие карты «зеленых» и «красных» явно отличались только производительностью трассировки — у решений от AMD она была заметно меньше. В 2022 году ситуация повторилась: хотя в линейке RX 7000 на архитектуре RDNA 3 производительность трассировки была улучшена, конкурировать в этом плане с RTX 4000 она не могла. А одновременное появление на рынке видеокарт третьего игрока в лице Intel, с ходу показавшего неплохие достижения в рейтрейсинге, усугубило ситуацию еще больше: AMD в этой тройке «лучистых» была явным аутсайдером.
Но компания понимала, что рано или поздно придется «раскошелиться» на производительное решение для трассировки лучей. Главной дилеммой было то, как при ограниченном транзисторном бюджете добиться в этом высокой производительности. И, похоже, AMD наконец ее решила. Встречайте — Radeon RX 9000 на новой графической архитектуре RDNA 4.

Базовым элементом в графических процессорах AMD являются вычислительные блоки Compute Unit (CU). В состав CU RDNA 4 входят 64 универсальных шейдерных процессора (SP), два планировщика исполнения, кэш нулевого уровня (L0), регистровый файл, блок трассировки лучей (RA), четыре текстурных блока (TMU), два ускорителя вычислений искусственного интеллекта (AI Accelerator) и другие вспомогательные блоки.
Как и прошлые поколения ГП AMD, графические чипы RDNA 4 состоят из шейдерных движков Shader Engine (SE). В каждом из них находится 16 CU, объединенных попарно в более крупные блоки Compute Engine (CE), а также блоки растеризации (ROP) и прочая обвязка. Всего один такой движок содержит:
16 вычислительных блоков CU (объединенных попарно в 8 блоков CE)
1024 шейдерных процессора SP
64 текстурных блока TMU
32 растровых блока ROP
16 RA-блоков для трассировки лучей
32 блока матричных вычислений AI Accelerator
Первым ГП на базе новой архитектуры стал Navi 48. Он включает в себя:
4 шейдерных движка SE
64 вычислительных блока CU
4096 шейдерных процессоров SP
256 текстурных блоков TMU
128 растровых блоков ROP
64 RA-блока для трассировки лучей
128 блоков матричных вычислений AI Accelerator
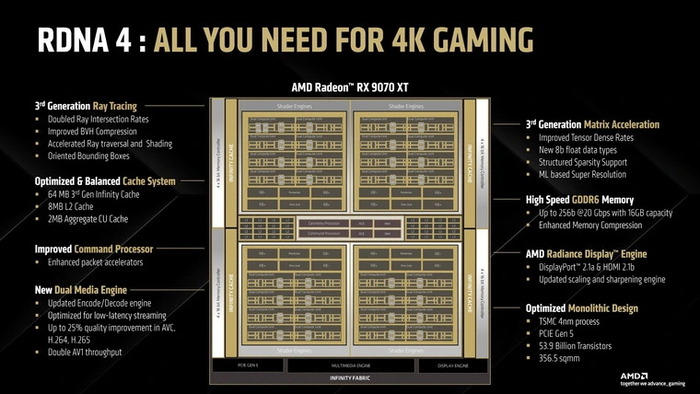
Как можно видеть по характеристикам, Navi 48 не является заменой флагманскому чипу Navi 31, на котором основаны модели серии RX 7900. Этот ГП — прямой последователь Navi 32, на базе которого в прошлом поколении видеокарт были выпущены RX 7700 XT и RX 7800 XT. Теперь для их замены предлагаются новинки в лице RX 9070 и RX 9070 XT. Обе оснащены 16 ГБ видеопамяти.

Аналогично чипу Navi 32, Navi 48 имеет 256-битную шину памяти GDDR6 и 64 МБ кэш-памяти Infinity Cache. Скорость работы в последней была увеличена, а кэш второго уровня заметно подрос — с 1 до 2 МБ на SE, что дает общий объем в 8 МБ на весь ГП. Вдобавок к этому появилась поддержка шины PCI-E 5.0 с полноценными 16 линиями, которая позволяет «общаться» видеокарте с системой вдвое быстрее, чем в прошлом поколении. Самое интересное в том, что в этот раз AMD не стала использовать для подобного ГП чиплетную компоновку, как в прошлом поколении. Navi 48 является монолитным чипом с площадью 356 мм2, что сравнимо с Navi 32. Но транзисторов в нем почти вдвое больше — 53,9 млрд против 28,1 млрд у предшественника. Новые вычислительные блоки, о которых мы расскажем далее, сделали ГП заметно сложнее, приблизив его по этому параметру к флагманскому чипу прошлого поколения Navi 31 с 57,7 млрд транзисторов.

Для производства нового ГП используется техпроцесс TSMC N4C — третье поколение 5 нм, оптимизированное для более низкой себестоимости выходной продукции. В связи с этим работа, проделанная AMD, впечатляет вдвойне: Navi 48 обладает рекордной плотностью транзисторов в 150 млн/мм2. Это на четверть больше, чем в чипах NVIDIA Blackwell на схожем техпроцессе TSMC 4N, которые используются в линейке видеокарт RTX 5000.
В основе чипов RDNA 4 лежат обновленные сдвоенные вычислительные блоки, получившие название Compute Engine. В целом, их устройство довольно схоже с Dual Compute Unit в архитектуре RDNA 3. В каждом CU содержится:
64 векторных блока для вычислений с плавающей запятой (FMA)
64 векторных суперскалярных блока, умеющих работать одновременно с целочисленными и плавающими вычислениями (FMA/INT)
16 трансцендентных блоков вычислений (TLU) для выполнения сложных инструкций
Четыре текстурных блока (TMU)
Два блока скалярных вычислений (SU)
Два блока матричных вычислений (AI Accelerator)
Блок загрузки/выгрузки данных (Load/Store)
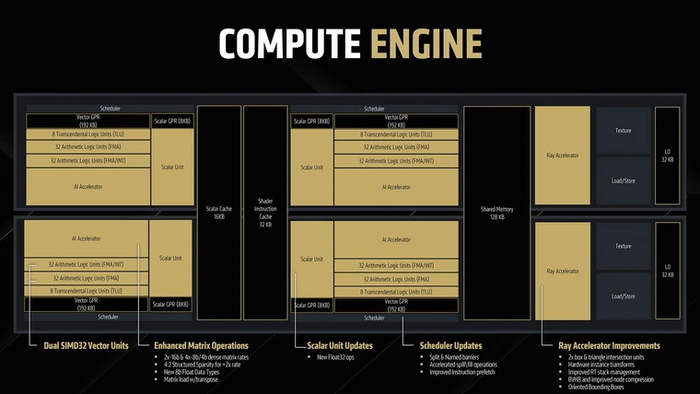
Вычислительные блоки в CU поделены на две части. Каждая из них имеет планировщик исполнения (Scheduler) и собственные регистровые файлы — 192 Кб для векторной и 8 Кб для скалярной вычислительной части. Помимо этого, CU обладает собственным кэшем L0 для данных объемом 32 Кб. При этом кэш шейдерных инструкций объемом 32 Кб и скалярный кэш объемом 16 Кб для обоих CU являются общими. А для эффективного обмена данными в процессе вычислений оба CU связаны 128 Кб общей памяти.
Как видим, AMD все так же считает количество шейдерных процессоров по суперскалярным вычислительным блокам, работающим с двумя типами вычислений — плавающими (FP32) и целочисленными (INT32). На самом же деле, как и в RDNA 3, блоков вычислений с плавающей запятой тут вдвое больше — не 64, а 128 на CU. Поэтому вычислительную мощность в терафлопсах у чипов с этими двумя родственными архитектурами сравнивать можно (без учета улучшений других блоков), а вот с более старыми на базе RDNA 2 — нельзя.
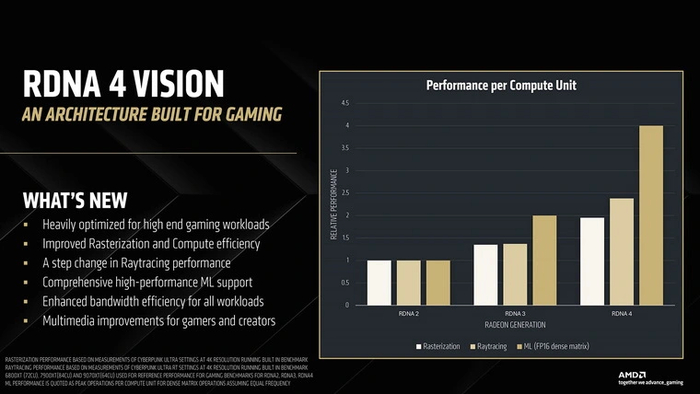
По диаграммам, представленным AMD, CU RDNA 4 до полутора раз быстрее вычислительного блока прошлого поколения в растеризации. А с блоком RDNA 2 разрыв двукратный. Но в этом сравнении стоит учитывать, что ГП RDNA 4 могут работать на заметно более высокой частоте, чем предшественники — до 3 ГГц и выше.
При задействовании трассировки лучей отрыв CU новой архитектуры еще более высокий. Рассмотрим, за счет чего это достигается.
Одна из самых главных и ожидаемых новинок в RDNA 4. AMD долго противилась необходимости делать сложные блоки для трассировки. Но наконец наступил момент, когда для сохранения конкурентоспособности видеокарт компании пришлось на это пойти. Встречайте — Ray Accelerators третьего поколения.
Первая реализация блоков трассировки в RDNA 2 умела просчитывать четыре пересечения луча с боксами иерархии ограничивающих объемов (BVH) либо одно пересечение с полигоном. В RDNA 3 темп расчетов остался тем же, но благодаря новой контрольной логике блоки стали работать до 80 % эффективнее. У RDNA 4 RA-блоки наконец «расширили», позволив им выполнять вдвое больше операций за такт — восемь пересечений с боксами либо два пересечения с полигонами.
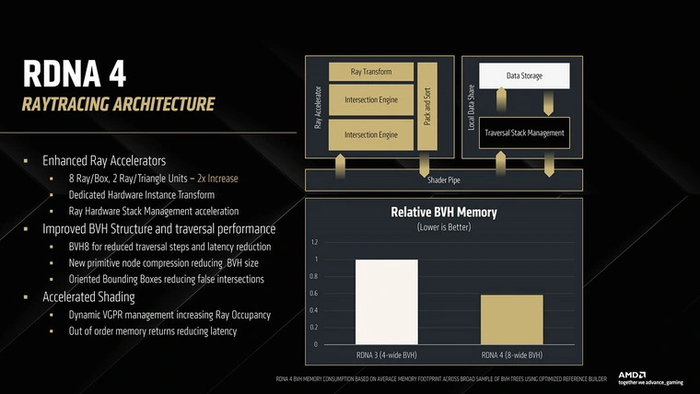
Теперь часть операций, необходимых для рейтрейсинга, ускорена аппаратно — для этого в составе Ray Accelerators появились выделенные блоки для преобразования экземпляров и управления стеком трассировки. Вычислительные ресурсы RA-блоков стали расходоваться экономнее благодаря технологии ориентированных боксов. Она предназначена для уменьшения объемов BVH, в которых необходимо просчитывать пересечения лучей за счет изменения их ориентации. При стандартном подходе эти объемы формируются в виде боксов, находящихся в пространстве строго вертикально или горизонтально. Ориентированные боксы можно размещать под любым углом, подгоняя их под форму и расположение объекта в кадре. Благодаря этому можно избавить RA-блоки от приличного объема ненужной работы.

Несмотря на перевод некоторых операций на отдельные аппаратные блоки, часть вычислений для трассировки все так же выполняется на шейдерах. Но и тут не обошлось без заметных улучшений. Шейдерные процессоры RDNA получили возможность внеочередного выполнения кода и динамические регистры. Благодаря этому они могут комбинировать расчеты для трассировки и выполнение шейдерного кода гораздо эффективнее, чем это было в предшествующей RDNA 3.
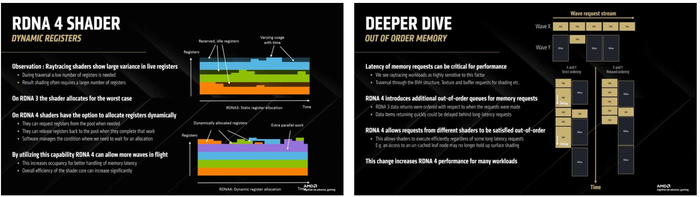
AMD заявляет, что производительность трассировки возросла вдвое благодаря всем улучшениям. На самом деле, учитывая заметную реорганизацию RT-конвейера, реальный прирост при большом количестве лучей в кадре может быть даже больше. Так что на видеокартах AMD наконец с достаточной производительностью можно будет использовать трассировку пути.

Вдобавок к этому подавление шумов, возникающих при трассировке, было переведено с шейдеров на выделенные блоки AI Accelerators. Давайте посмотрим, что они из себя представляют.
Именно так AMD называет новые блоки матричных вычислений. И не зря. В отличие от предшественников в RDNA 3, просто переназначавших SIMD векторных блоков для выполнения подобных операций, AI Accelerators являются самостоятельными вычислительными блоками — аналогично тензорным ядрам в ГП NVIDIA или матричным блокам XMX в ГП Intel.

По сравнению с блоками прошлого поколения, ИИ-ускорители обзавелись вдвое более широким конвейером и поддержкой расчетов низкой точности FP8/BF8. Но, что самое важное, они научились работать с разреженными вычислениями (sparse compute). Это позволяет увеличить темп исполнения расчетов еще в два или четыре раза, в зависимости от точности.

Благодаря этому общий прирост скорости матричных вычислений на одной частоте составляет от четырех до восьми раз. И не забываем, что на такие вычисления теперь не тратятся ресурсы шейдерных процессоров.
За счет совокупности всех улучшений, заметно повысивших производительность тензорных расчетов, блоки AI Accelerators стало возможным использовать не только для подавления шумов при трассировке, но и для работы нового алгоритма фирменной технологии повышения производительности FSR 4.
Технология масштабирования на основе глубокого обучения. Теперь это не только NVIDIA DLSS и Intel XeSS, но и AMD FSR четвертого поколения. Базовые техники ее работы схожи с FSR 2.х: это рендер кадров со сдвигом на основе векторов движения, а затем — комбинация временной информации из нескольких кадров и карты глубин для создания картинки целевого разрешения. Ключевое отличие в том, что для этого используются не расчеты на шейдерных процессорах, а нейросеть, работающая на ИИ-ускорителях.

Такое масштабирование заметно качественнее и гораздо внимательнее к деталям, чем упрощенная обработка FSR второго и третьего поколения.

Нейросеть FSR 4 предварительно обучена на игровых данных с помощью серверных ГП AMD. Это позволяет совершенствовать алгоритм ее работы с каждым новым выпуском драйверов.

Никуда не делась и поддержка генерации кадров, дебютировавшая в FSR 3. FSR 4 Frame Generation, как и ее предшественница, может вставлять один сгенерированный кадр между двумя отрендеренными на основе информации из оптического потока и векторов движения. На данный момент AMD не уточняет, как обрабатываются новые кадры при генерации. Судя по слайдам из официальной презентации, пока для этого используются универсальные шейдеры, как и в FSR 3.x. Но с будущими обновлениями и к этому процессу будут подключены ИИ-ускорители. FSR 4 использует API, обратно совместимый с FSR 3.1. Это значит, что ее интеграция в существующие игры с FSR третьего поколения будет довольно простой. Вдобавок к этому новая технология полностью совместима с нейронным рендерингом.

Чипы архитектуры RDNA 4 получили новый движок дисплея Radiance 2 Display Engine. Им поддерживается вывод изображения с помощью современных интерфейсов DisplayPort 2.1a и HDMI 2.1b. Главные улучшения: сниженное энергопотребление в режиме ожидания при использовании двух мониторов, новый блок повышения резкости и аппаратная поддержка технологии Flip Metering — той самой, которую NVIDIA использует в чипах Blackwell для мультигенерации кадров в DLSS 4. Не исключено, что AMD тоже готовит похожую технологию, но представит ее позже.

Чип Navi 48 получил мультимедийный движок с двумя кодировщиками и двумя декодерами. Качество кодирования популярных форматов H.264 и HEVC было заметно улучшено — на 25 и 11 %, соответственно. Это особенно заметно при низких битрейтах.

Для более «молодого» формата AV1 был увеличен максимальный битрейт и появилась поддержка B-кадров. Общая производительность мультимедийного движка по сравнению с прошлым поколением возросла более чем на 50 %.
Новую графическую архитектуру RDNA 4 можно охарактеризовать короткой фразой: «Все, чего нам так давно не хватало». AMD наконец заметно подтянула скорость работы с трассировкой лучей, оснастила чипы полноценными матричными ускорителями AI Accelerators, разработала собственную технологию масштабирования на основе глубокого обучения FSR 4, а также произвела множество других мелких доработок архитектуры, которые необходимы для эффективной работы с нейронным рендерингом.

Теперь видеокарты компании и при задействовании современных графических технологий могут практически наравне конкурировать с решениями от NVIDIA и Intel. Стоп, все же чего-то не хватает. Да, флагманского чипа! Но в этом поколении AMD вновь заявила, что «топовых видеокарт не будет». Такое уже было и в 2016 году при появлении видеокарт серии RX 400, и в 2019 году, когда была представлена линейка RX 5000.
Впрочем, как показывает история, каждый раз после подобных заявлений уже через год AMD собиралась и представляла ГП на базе доработанной архитектуры, конкурирующий с топами NVIDIA. И хотя сейчас «зеленые» с огромным чипом GB202 кажутся вне досягаемости, с RDNA 4 шанс у AMD есть. Удвоив возможности Navi 48 (что вполне реально с использованием текущего техпроцесса), она вполне может приблизиться к текущему флагману NVIDIA по скорости.
Вопрос в том, а нужно ли это компании? На данный момент — точно нет. Сейчас AMD сосредоточена на росте новой линейки «вширь». Во втором квартале 2025 года будут выпущены карты серии RX 9060, а затем ожидаются и бюджетные RX 9050. Если ценовая политика компании будет правильной, то за счет линейки RX 9000 к AMD вновь должна вернуться заметная часть рынка видеокарт, как это было несколько поколений назад.

Тестирование видеокарты MSI GeForce RTX 4060 Ti Gaming X Trio 8 Гб проводилось на следующей конфигурации:
Процессор: Intel Core i9-13900K;
Охлаждение: ID-Cooling ZOOMFLOW 360 XT
Термоинтерфейс: Arctic MX-4;
Материнская плата: ASUS ROG MAXIMUS Z690 APEX;
Память: 2 x 16Гб DDR5-6400, Team (SKhynix);
Видеокарта: MSI GeForce RTX 4060 Ti Gaming X Trio 8 Гб (2310 / 2670 / 2250 МГц (ядро/boost/память));
Накопитель: Samsung PM9A1 1Тб;
Блок питания: XPG CyberCore 1300W, 1300 Ватт.
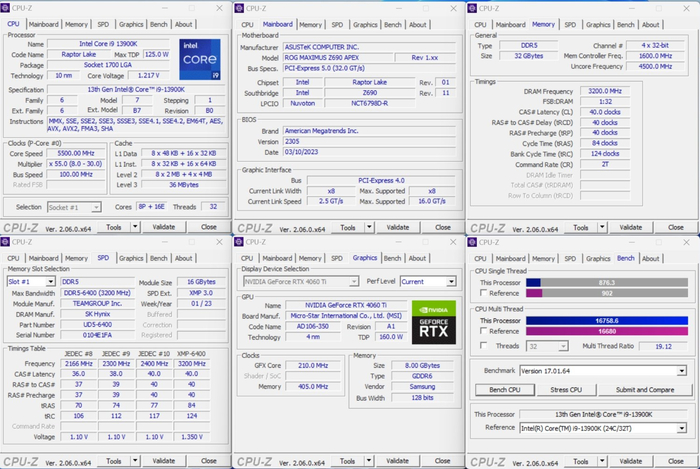
Температура в помещении находилась на уровне 22°C, уровень шума составлял 27.1 дБ.
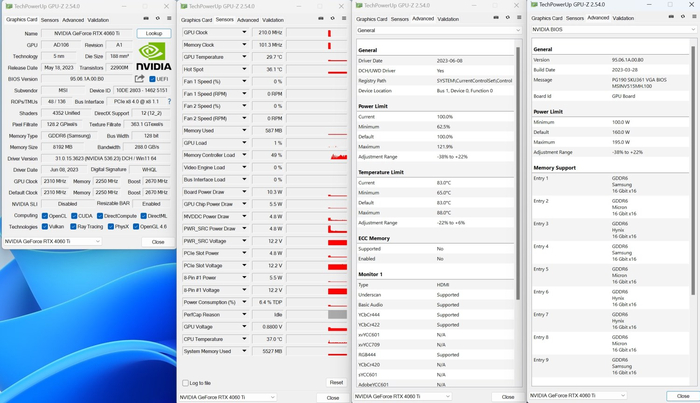
При внешнем осмотре карты можно было упустить ряд важных моментов, о которых нам рассказывают утилиты. Все они грустные. Начнём с интерфейса подключения. Теперь это PCI-e x8 Gen4, как на RTX 3050. Причём при взгляде на разъём это можно заметить по отсутствию дорожек к половине контактов.
Это мелочи потому, что, по сути, перед нами пропускная способность PCI-e x16 Gen3. Куда важнее, что шина памяти всего 128 бит, как на GTX 1650. Её пропускная способность оказывается очень маленькой для карты среднего уровня и почти вдвое меньше чем на RTX 3060Ti. И раз уж речь зашла о сравнении с RTX 3060Ti, то ещё снизилось количество CUDA ядер.
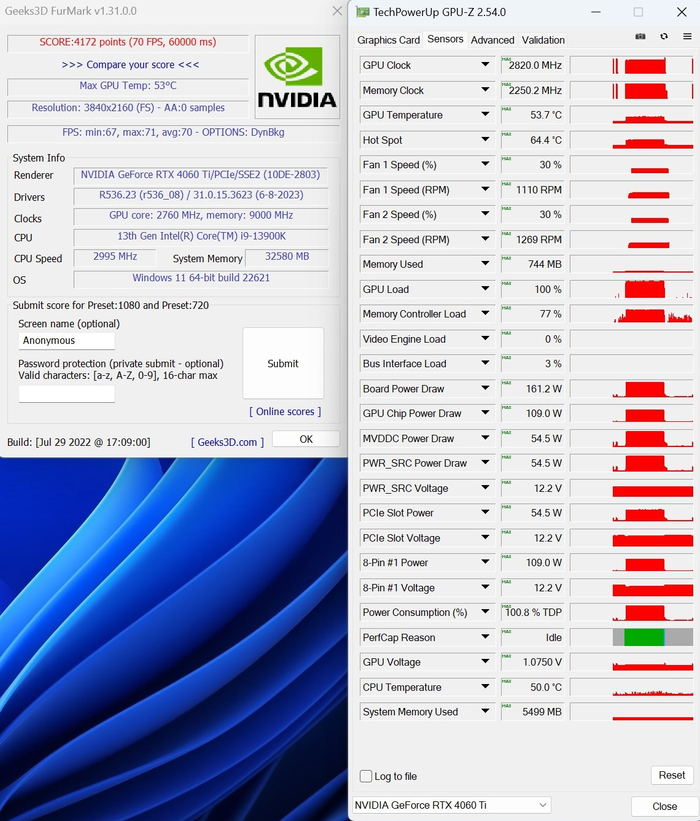
При отсутствии нагрузки вентиляторы здесь останавливаются. Такая схема используется не впервые и большой массивный радиатор может справиться даже с мощным чипом в пассиве, если частоты его падают до 300 МГц. При достижении 50°C вентиляторы запускаются. На 100% мощности вентиляторы раскручиваются до 2800 об/мин, шум при этом составляет 48 дБ с расстояния 1 м. В «бублике» вентилятор работает только на 30% от полной мощности, что составляет 1100 об/мин. Даже в таком режиме получается приемлемый уровень шума – 32,4 дБ на расстоянии 30 см. В «волосатом бублике» карта потребляет около 162 Вт. Это не мало, но смотря с чем сравнивать.
Сверху кожуха предусмотрена небольшая вставка с RGB-подсветкой двух логотипов. Также есть ещё два модуля с RGB-подсветкой спереди на кожухе. Подсветка настраивается через приложение MSI Center. Режимов работы очень много, можно всё настроить на свой вкус. Также есть синхронизация подсветки с материнской платой.
Пора переходить к тестированию.
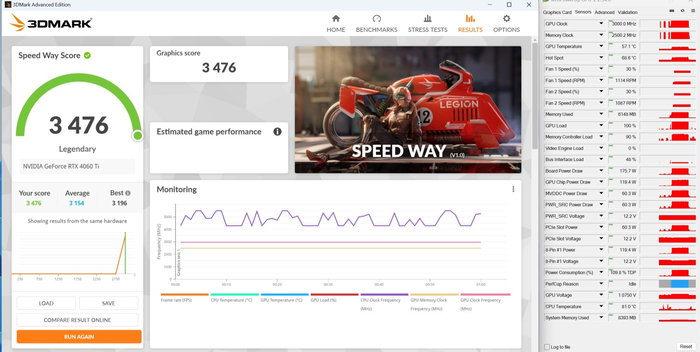
3DMark Speed Way:
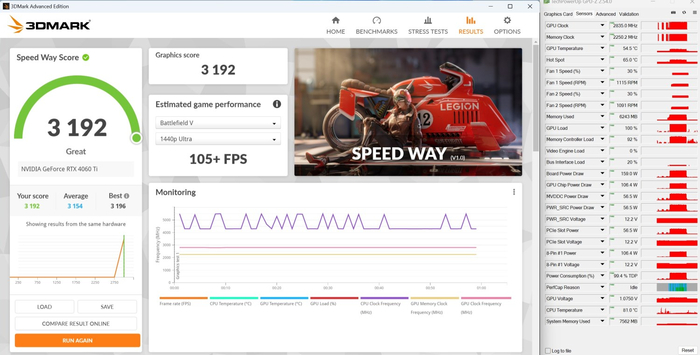
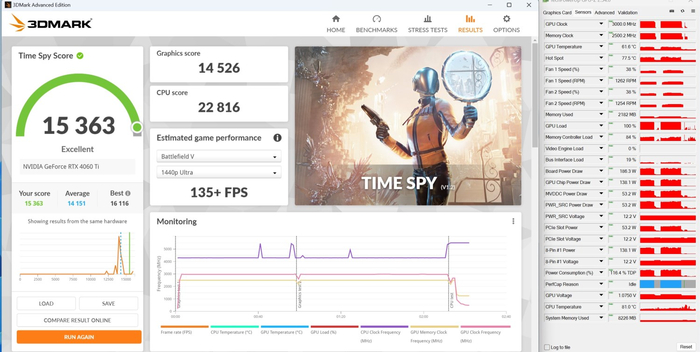
3DMark Time Spy:
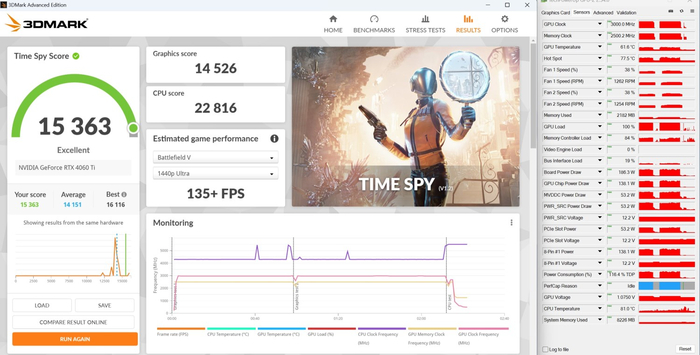
3DMark Port Royal:
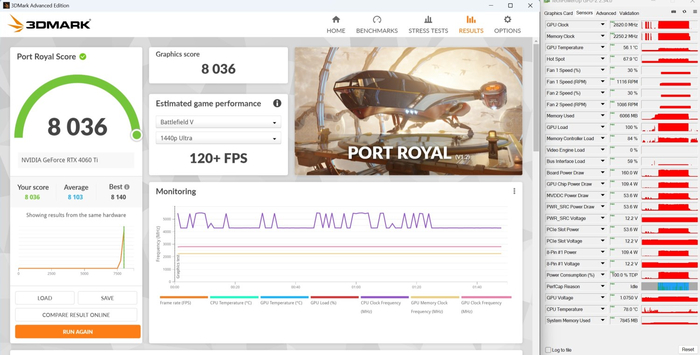
Superposition FHD Medium:

Superposition FHD High:

Superposition FHD Extreme:

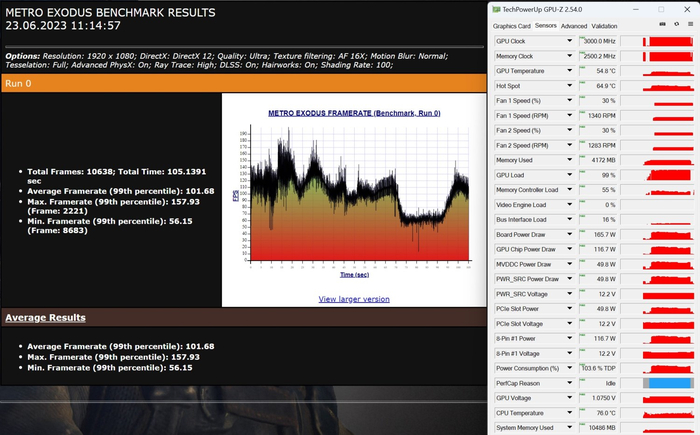
Metro Exodus FHD, RTX:
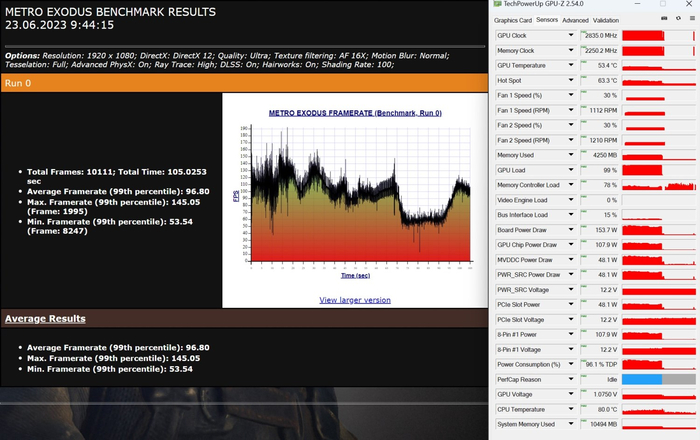
Metro Exodus FHD, RTX, DLSS OFF:
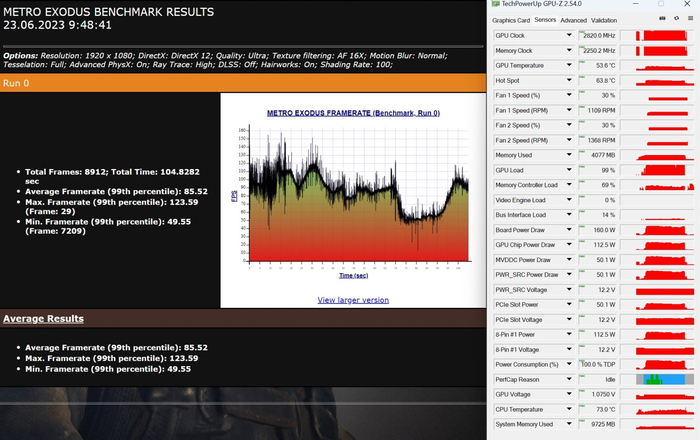
Metro Exodus QHD, RTX:
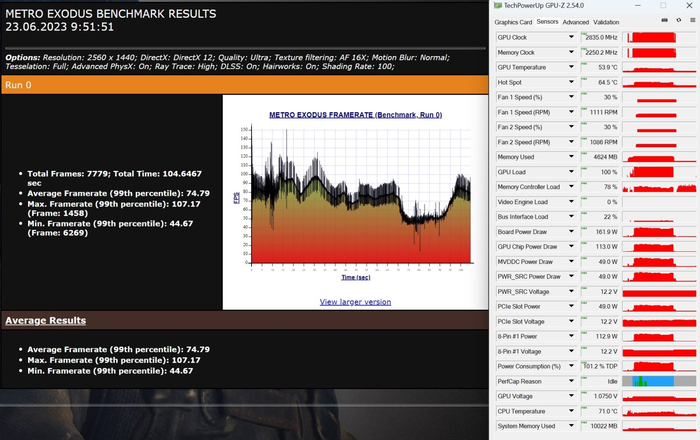
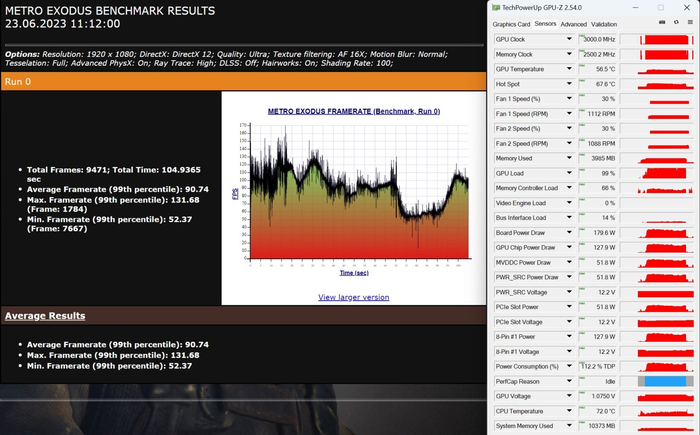
Metro Exodus QHD, RTX, DLSS OFF:
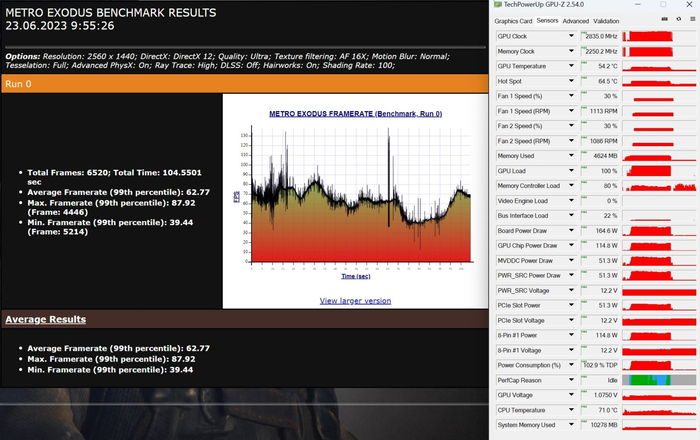
Cyberpunk 2077, FHD, трассировка минимальная:

Cyberpunk 2077, FHD, трассировка минимальная, DLSS OFF:

Cyberpunk 2077, QHD, трассировка минимальная.
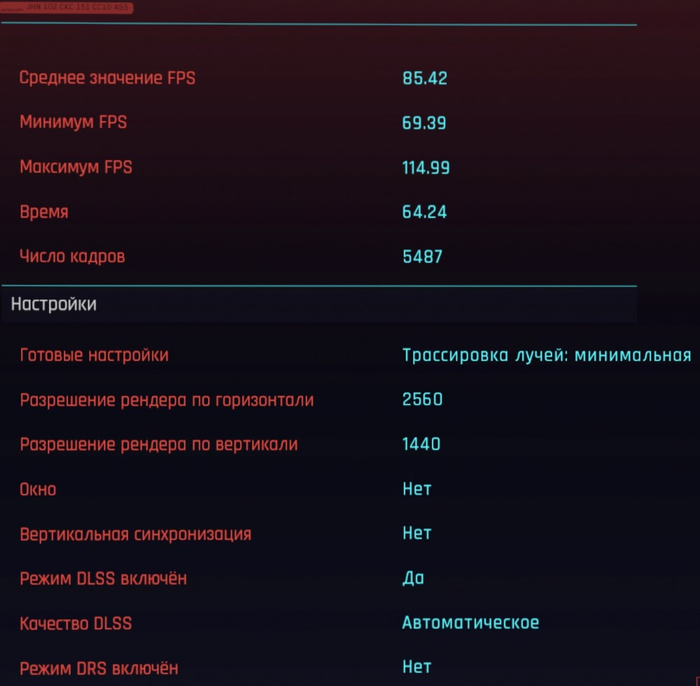
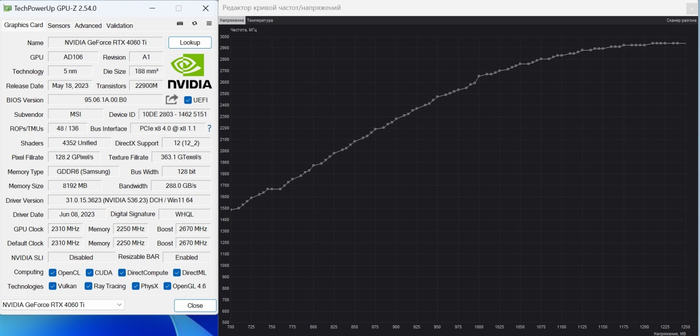
Разгон у видеокарты есть, причём неплохой. Она может легко уйти за 3 ГГц по чипу и при этом потребление может достигать практически 230 Вт. Именно поэтому здесь система охлаждения вполне соответствует.
При обычной игровой эксплуатации я бы всё же не разгонял карту потому, что нагрузка на VRM вырастает, а «выхлоп» на 5-10%. Однако здесь каждый будет решать сам.
3DMark Speed Way:
3DMark Time Spy:
Superposition FHD High:

Metro Exodus FHD, RTX:
Metro Exodus QHD, RTX, DLSS OFF:
В плане производительности карта находится на уровне RTX 3060 Ti и этому есть очевидные объяснения. Достаточно вспомнить про пропускную способность памяти. Я уже даже не говорю про её объём.
Посмотрим теперь на нагрев карты во время интенсивной нагрузки.
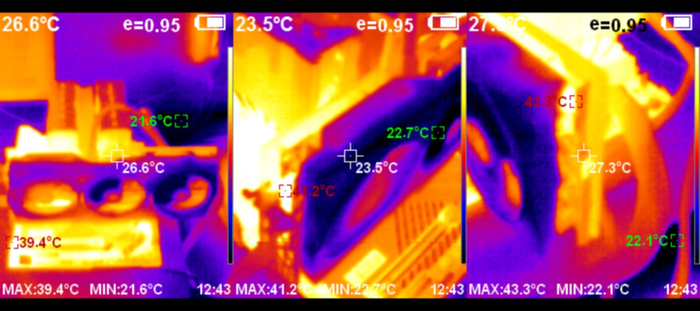
Каких-то высоких показателей температуры нет, и это объясняется габаритной системой охлаждения, которая обеспечивает низкую температуру и маленький уровень шума.
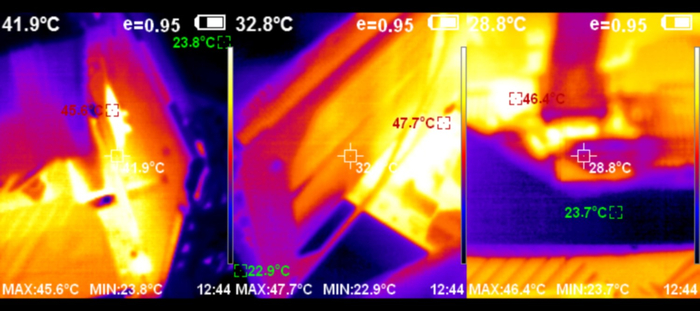
MSI RTX 4060Ti Gaming X Trio – это яркий представитель своего поколения видеокарт, основанных на графическом процессоре AD106. Картина чем-то напоминает MSI GeForce RTX 4070 Gaming X Trio потому, что там тоже была достаточно компактная плата и крупная система охлаждения. Большой кулер – это хорошо, но и здесь нужна мера. Карту же нужно размещать в корпусе и с более компактным устройством проблем меньше. Здесь кулер огромный, поэтому эта и без того не очень мощная карта получилась тихой и холодной. Печатная плата и подсистема питания полностью соответствуют потребностям графического процессора. Может всё показаться сильно упрощённым, но это так и задумывалось. Тем не менее, чип можно разогнать до 3 ГГц и даже заметно поднять частоту памяти, но всё это не сильно спасает. Играть уверенно можно только в разрешении FHD. В QHD нужно уже включать DLSS или играться с настройками качества картинки.
Больше всего вопросов не к самой карте потому, что она сама по себе сделана отлично, а к компании NVIDIA. Было бы отлично, если б этот комплект чипа и памяти назывался RTX 4050 и стоил в два раза дешевле, чем7продаются RTX 4060Ti. Тогда вопросов бы никаких не было, а NVIDIA можно было бы только поздравить.
Однако мы видим абсолютно другую картину, и у многих она вызывает недоумение. CUDA ядер стало меньше, шина памяти 128 бит, интерфейс PCI-e x8 – это всё элементы бюджетного решения, но никак не карты среднего уровня. Благодаря этому производительность фактически осталась на уровне RTX 3060 Ti, а стоимость заметно увеличилась.
Кроме этого, на вторичном рынке сейчас великое множество карт прошлого поколения и поэтому неудивительно, что наблюдается очень маленький спрос на карты 4000-серии среднего уровня. Тем более что на рынок вышли флагманские карты 5000-серии.

Видеокарты среднего ценового сегмента наиболее популярны среди игроков. Они обеспечивают хорошую графику при относительно невысокой стоимости. Среди моделей NVIDIA к таким картам относятся модели серии x060.
Пожалуй, лучшая реализация RTX 4060 Ti. Она работает практически без звука. Даже под полной нагрузкой уровень шума от карты не превышает 23.3 дБА. При этом модель остается довольно холодной — 56 °C на чипе и 64 °C в точке Hotspot. Секрет кроется в грамотном охлаждении чипа. Его реализуют пять тепловых трубок, габаритный радиатор и три вентилятора.

Подсистема питания графического чипа состоит из восьми фаз. Для ГП данного класса это солидный запас, даже с учетом разгона. В нем можно добиться неплохих результатов благодаря повышению лимита энергопотребления на 22 %.
Подсветки немного: наклонные полосы возле центрального вентилятора и логотип компании на торце. Видеокарта занимает два с половиной слота в системном блоке. Единственный минус — большая длина, целых 33 см. Перед покупкой убедитесь, что она влезет в корпус вашего ПК.

Габариты видеокарты составляют: 338 х 141 х 52 мм, вес – 1167г. Для сравнения те же характеристики у версии MSI GeForce RTX 4070 Gaming X Trio: размеры -– 338 х 141 х 52 мм, а вес – 1214г.

Карта по габаритам как более старшая версия, но по весу немного легче и это легко объяснимо, ведь памяти на два чипа меньше (и не только это). Все разъёмы задней панели и сам разъём PCI-e x16 закрыты чёрными пластиковыми заглушками.

Во внешнем оформлении мы видим узнаваемые черты. Схожим образом реализована подсветка на кожухе. Здесь, наконец, исчез разъём питания 12VHPWR, который используется на старших адаптерах. Вместо него всего один коннектор 8-pin PCI-e.
Карта занимает больше двух слотов расширения. Для усиления жёсткости конструкции в комплекте поставляется специальная стальная пластина, окрашенная в чёрный цвет.

Сзади видеокарты мы снова видим защитную пластину («бекплейт»). Она также выполняет функцию теплоотвода. Кроме этого, не ней заметны огромные прорези для того, чтобы воздух проходил радиатор насквозь свободно. Это свидетельствует о том, что сама печатная плата короткая и меньше участвует в распределении тепла.
Защитной плёнки снаружи нет, но она есть внутри. Термопрокладок тоже нет потому, что память GDDR6 холоднее, чем GDDR6X.

С обратной стороны платы мы можем заметить ШИМ-контроллер, а сама плата короче системы охлаждения больше чем в два раза. Танталовых конденсаторов в большом количестве на плате нет. Они твердотельные капсульные и все находятся спереди.

Кулер снимается очень просто. Для этого нужно сначала снять заднюю пластину, а затем открутить специальную монтажную рамку на четырёх винтах. После этого снимается кулер. Никакой дополнительной рамки спереди больше нет.
Сам кулер изготовлен по классической схеме. Две секции и пять тепловых трубок. За теплоотвод отвечает обычная медная никелированная пластина. Графический процессор контактирует с ней напрямую через термопасту, а с микросхемами памяти через термопрокладки.

Далее уже от теплосъёмной пластины расходятся тепловые трубки и пронизывают два массива алюминиевых рёбер радиатора. Трубки медные, никелированные диаметром 6 мм.

Сами пластины тоже достаточно крупные и их много. Поэтому радиатор очень похож на тот, что используется в MSI GeForce RTX 4070 Gaming X Trio, особенно это заметно по толщине. Все элементы здесь также пропаяны.
Акцент сделан на эффективность и возможность отвода большого количества тепла. Здесь это сделано с огромным запасом. В спецификации указано 160 Вт, а в BIOS стоит лимит на 195 Вт. Производитель похоже подгонял размеры кулера под стоимость устройства потому, что чувствуется солидный запас по мощности теплоотвода.

Пластиковый кожух чёрный с серыми вставками. Он крепится шестью винтами к специальным креплениям на радиаторе спереди. Если вы думаете, что вентиляторы крепятся к кожуху, то это не так. Здесь они также напрямую крепятся к специальным монтажным приспособлениям на радиаторе.

Кулер достаточно тихий и производительный. Здесь используются три вентилятора Power Logic PLD10010S12H с техническими характеристиками 12 В, 0.40 А. Максимальная скорость 2800 об/мин, а шум на расстоянии 1 м – 48 дБ.

Да, это немало, но обеспечивает сильный воздушный поток и солидный запас по мощности, ведь вертушки в нагрузке трудятся приблизительно на треть от максимальной мощности. Они также оборудованы специальной крыльчаткой TORX FAN 5.0. Спереди на всех есть серебристые наклейки с драконом MSI Gaming.

Судя по заявлениям производителя, они обеспечивают больший поток при той же скорости вращения и уровне шума. И это хорошо потому, что рёбра у радиатора расположены очень плотно друг к другу.

Над радиатором тоже поколдовали и верхние грани пластин выполнены волнообразно и расположены со сдвигом. Получается, как бы чешуя и сквозь не воздушный поток легче проникает и шума меньше.
Транзисторные сборки и катушки также охлаждаются этим радиатором, для чего на пластинах изготовлены специальные площадки, а в качестве термоинтерфейса выступает терморезинка.

Никакой дополнительной рамки тут нет. Память GDDR6 не такая прожорливая и поэтому питание для неё достаточно скромное. Поэтому мы видим всего одну фазу.

Слева находятся линии питания GPU, которых здесь также восемь, как на MSI RTX 4070 Gaming X Trio. Логику производителя понять можно. Чип потребляет меньше, значит и питание можно упростить, а если всё не такое горячее, то можно уменьшить печатную плату и сделать её более компактной.

ШИМ-контроллер распаяны сзади. Это та же самая микросхема uPI Semi uP9512R.

На каждую фазу приходится по одной транзисторной сборке ON Semiconductor NCP302150 на 50А и одной ферритовой катушке индуктивности. Силовые элементы распаяны все и пустых мест нет.

По центру размещен графический процессор NVIDIA AD106-350-A1, он же RTX 4060 Ti. Чип изготовлен на 50-й неделе 2022 года, но в NVIDIA долго думали над конечным продуктом. Это 188 кв. мм выполненных по 5 нм техпроцессу TSMC.

Четыре микросхемы памяти типа GDDR6 распаяны только спереди. Пустых мест нет и в BIOS платы не упоминаются более ёмкие чипы.

Используются микросхемы производства компании Samsung. Дополнительное питание подаётся на видеокарту через обычный разъём 8-pin PCI-e.

На задней панели расположен классический набор видеовыходов.

3x - Display Port;
1x – HDMI 2.1.
Ещё одна важная деталь. На этой видеокарте отсутствует переключатель двух режимов работы устройства: тихий и игровой.

