


Хватит парсить Excel вручную — я написал библиотеку, которая сделает это за вас
Всем привет 👋
Как часто вы парсите Excel-таблицы?
Лично я очень часто. И почти никогда эти файлы не выглядят так, что их можно без боли скормить pandas и сразу получить аккуратный DataFrame.
Думаю, многим знакома ситуация, когда:
- таблица начинается где-то с 7-й строки
- заголовок размазан на несколько рядов
- названия колонок незначительно отличаются от файла к файлу
Со временем я все больше усложнял и полировал код парсинга, стараясь сделать его читаемым и поддерживаемым.
Буквально пару недель назад, проводя код-ревью, меня внезапно накрыло осознание: огромный кусок логики наших мини-приложений - это чтение и парсинг Excel-файлов. При этом целая команда разработчиков решает одну и ту же задачу, но каждый по-своему.
Стало немного больно.
Поэтому я написал xlea
xlea - это легкая библиотека, которая в духе SQLAlchemy или pydantic позволяет декларативно описывать схему таблицы и парсить Excel-файлы без танцев с бубном.
Неважно:
- с какой строки начинается таблица - с первой или с двадцать пятой
- сколько строк занимает заголовок - одна или семь
Вы просто описываете схему, а дальше происходит магия.
Как это выглядит
Пример таблицы
Допустим, у нас есть Excel-файл, где таблица начинается где-то с пятой или десятой строки, это не принципиально.
Выглядит она, скажем, так:
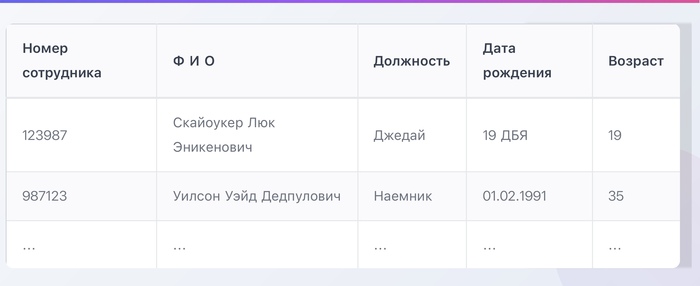
Предположим, нам нужны только:
- номер сотрудника
- ФИО
- возраст
При этом:
- ФИО может называться ФИО, Ф.И.О, Ф. И. О и как угодно еще
- возраст в одних файлах просто Возраст, а в других Возраст сотрудника
Описываем схему
Начнем со схемы:
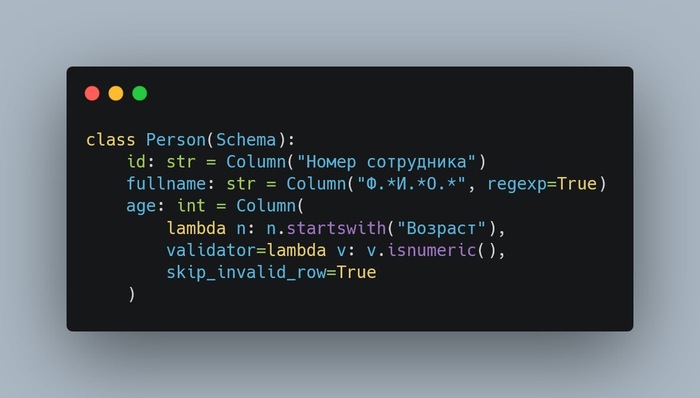
Мы создаем класс Person, наследуемый от Schema, и с помощью Column привязываем колонки таблицы к атрибутам:
id: колонка Номер сотрудника
fullname: ФИО, описанное через регулярное выражение
age: Возраст, который определяется через лямбда-функцию по имени столбца
Для age я также добавил валидатор: он проверяет, что значение числовое.
Если строка не проходит валидацию, она будет пропущена (skip_invalid_row=True).
По умолчанию, если значение не проходит валидацию, парсинг останавливается с ошибкой InvalidRowError.На этом схема готова, дальше можно парсить файл.
Парсим файл
Есть два варианта.
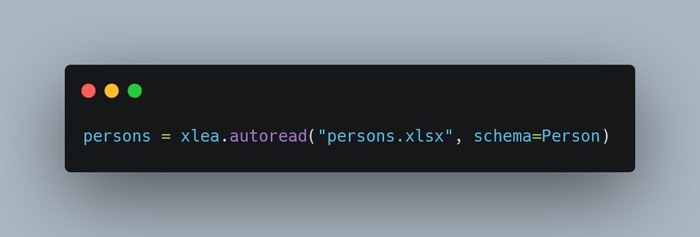
Вариант первый: автораспознавание.
В xlea встроены три ридера: openpyxl, xlrd и pyxlsb. Нужный выбирается автоматически по расширению файла:
Вариант второй: свой провайдер.
Можно реализовать протокол xlea.providers.proto.ProviderProto и передать его напрямую:
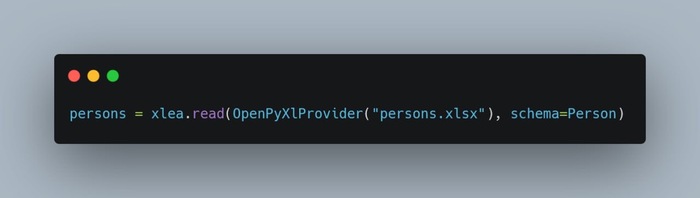
В протоколе нужно реализовать всего один метод - rows, который возвращает Iterable[Iterable].
То есть это может быть любой источник данных, не только Excel.
Таким образом, xlea полностью независима от конкретных ридеров. Вы можете:
- реализовать чтение любых форматов файлов
- расширять функциональность под свои нужды
Также можно подключить свой провайдер к механизму автораспознавания:

После этого autoread
будет использовать MyProvider для файлов с нужным расширением.
Результат парсинга - итератор объектов Person:
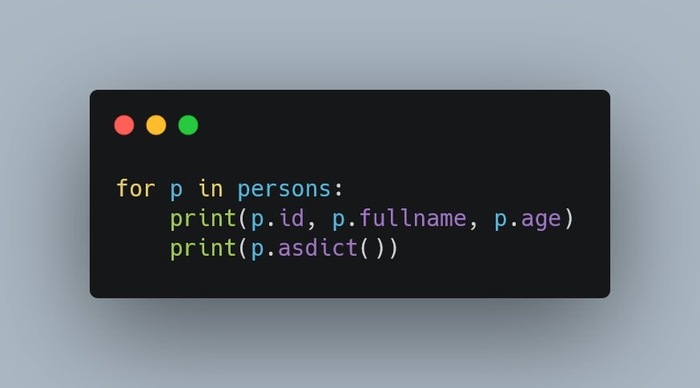
Можно:
- обращаться к атрибутам напрямую
- получить индекс исходной строки (row_index)
- получить словарь через asdict()
Многоуровневые заголовки
Иногда таблицы выглядят так:
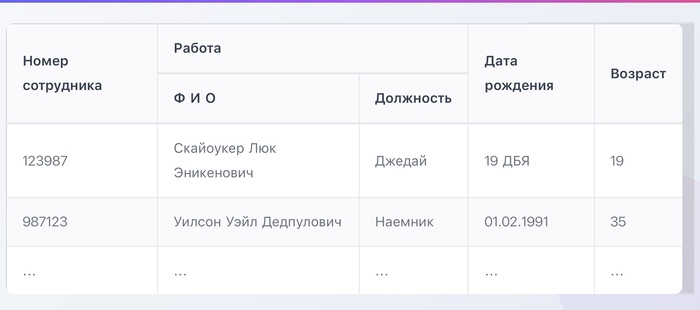
Здесь столбцы объединены в группу «Работа».
Парсится это тоже довольно просто:
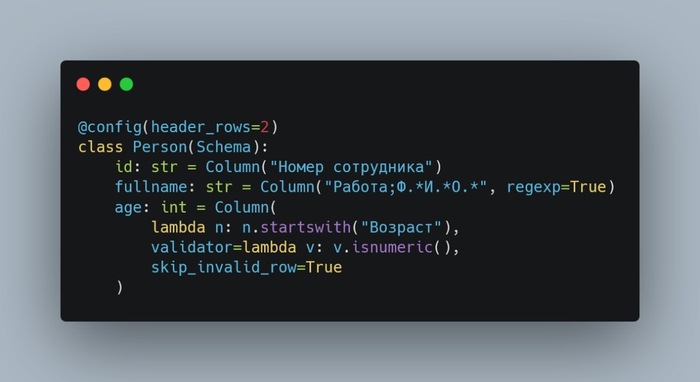
В декораторе config указываем количество строк заголовка,
а уровни заголовков в Column разделяем символом ; (его тоже можно переопределить параметром delimiter в конфиге).
Установка и репозиторий
Установка стандартная:
pip install xleaРепозиторий на GitHub: https://github.com/artanador/xlea
Звезды приветствуются 🌚
А как вы обычно решаете задачу парсинга «кривых» Excel-файлов?
Пишете кастомный код каждый раз или у вас уже есть свои универсальные инструменты?







