Потратить 296 млрд, построить 1142 системы — и не суметь их подружить

Государство построило 1142 информационные системы и потратило на них больше 296 миллиардов рублей. А «подружить» их так и не смогло: данные в них, по заключению Счётной палаты, «обособлены и несопоставимы» — для решений непригодны. Звучит как чья-то халатность, но это не разгильдяйство, а системная проблема — и именно она сегодня глушит любой государственный ИИ. Я Product Engineer, занимаюсь агентными ИИ-системами; разобрался, в чём корень, и вынес решение на форум «Сильные идеи для нового времени». Рассказываю.
Идея.
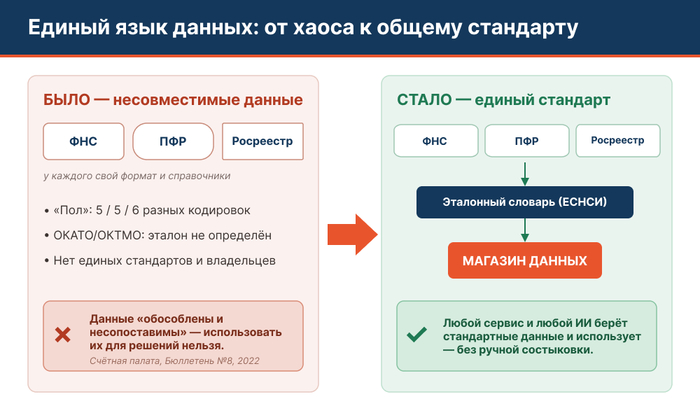
Главное ограничение для ИИ в государстве — не модели, они уже достаточно сильны. Ограничение — данные: они на разных «языках», и любая межведомственная задача упирается в ручное согласование ещё до того, как подключится ИИ. Даже базовые справочники в разных ведомствах не стыкуются.
Мой тезис: первым государственным ИИ должен стать не очередной «помощник для граждан», а агент, который готовит данные для всего остального ИИ. Над каждой системой ставится ИИ-агент-стандартизатор: он приводит данные к единому эталону (государство такой эталон уже вводит и делает обязательным с 2026 года), а человек проверяет и утверждает результат. То, что сегодня делают вручную месяцами, агенты выполняют за дни. Это нулевой шаг, без которого любой государственный ИИ остаётся декларацией.
Я говорю об этом предметно, потому что строю такие системы для себя, например:
— BondsTracker — аналитический сервис по облигациям. Данные больше чем из десятка разнородных источников — Московская биржа (MOEX ISS), Банк России (ключевая ставка, RUONIA, курсы валют, рейтинги), ГИР БО ФНС (финансовая отчётность), рейтинговые агентства (АКРА, Эксперт РА, НКР, НРА), e-disclosure, Dadata, Росстат/ЕМИСС, Yandex Wordstat, Telegram — приводятся к единому стандарту через контролируемые словари и нормализацию, и уже на этом слое работает агентный ИИ-аналитик с проверкой достоверности. Это ровно тот паттерн «разные данные → единый стандарт → ИИ», который я предлагаю перенести на государство.
Суть та же, что нужна государству: научить ИИ надёжно работать на реальных, «грязных» данных.
Моя позиция.
Как директор компании, я не люблю неэффективность: мне физически больно смотреть, как тратятся огромные деньги, а результата нет. Это и подтолкнуло меня оформить идею и вынести её на обсуждение. Одобрят её или нет — для меня не главное. Если просят помощи или мнения — всегда подскажу и помогу. Изменения приходят не от тех, кто заранее уверен, что «ничего не выйдет», а от тех, кто формулирует и выносит на обсуждение то, во что верит. Даже если идею не выберут, её прочитают — и мысль начнёт работать дальше.
И про сам портал идей.
Да, там хватает наивных идей и откровенного пиара — листать приходится много. Но если присмотреться, попадаются и по-настоящему стоящие идеи, ради которых туда и стоит заглядывать. Свою я отношу к тем, что как минимум заслуживают разбора.
Если тема близка: изучите идею и напишите мнение на портале — за или против, — предложите экспертизу или опыт. Прошу об одном: по делу. Нытьё в комментах «всё плохо и никто это не увидит» бесполезно и потратит только ваше время, а предметный разбор и аргументированное мнение — ценность.
Идея на портале:
Ищите по названию
Источники (подтверждение цифр):
— Счётная палата РФ, Бюллетень №8 (2022): 1142 информационные системы, 630 ФГИС, совокупная стоимость владения 296 млрд ₽, данные «обособлены и несопоставимы» и непригодны для управленческих решений:
• d-russia.ru/bolee-60-federalnyh-gosudarstvennyh-informsistem-ne-imejut-takogo-statusa-schjotnaja-palata.html
• telesputnik.ru/materials/gov/news/schetnaya-palata-gis-ne-godyatsya-dlya-prinyatiya-upravlencheskih-resheniy
— РАНХиГС, ЦПТР «Трудности в работе с государственными данными»: несовместимость справочников, пример с «полом» (5–6 кодировок), неопределённость эталона ОКАТО/ОКТМО