Изучаю как и все новые нейронки, вот одну сейчас тестю, и вот что приемлемо: Spottr — нейросеть, которая за секунды прожёвывает любое видео и находит в нём что угодно. Работает на удивление просто: Кидаешь ссылку на видео (хоть многочасовую трансляцию).Пишешь в строку, что ищешь ("красная машина", "человек в чёрной куртке", "момент, где показывают график").Жмёшь Enter и через пару секунд получаешь таймкоды.
Фишки
Ищет что угодно: Не только предметы, но и действия, сцены, тексты. Работает в браузере: Ничего качать не нужно. Ест видео любой длины: От тиктоков до видео лекций, мастер классов в 4 часа. Пока что БЕСПЛАТНО: Успей протестить.
Проверил на своём проекте — интерфейс понятный, заходить можно через аккаунт, есть пробный период. Однозначно палочка-выручалочка. Как у вас получилась, кто то пробовал платный контент, какие преимущества в платном?
Для тестирования использовался именно этот сценарий .
Конфигурация виртуальных машин
ВМ-1
Postgres Pro (enterprise certified) 15.8.1 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 11.4.1 20230605 (Red Soft 11.4.0-1), 64-bit
CPU = 8
RAM = 15
OC = RED 7.3
ВМ-2
Postgres Pro (enterprise certified) 14.11.3 on x86_64-pc-linux-gnu, compiled by gcc (Debian 6.3.0-18+deb9u1) 6.3.0 20170516, 64-bit
CPU = 24
RAM = 189
ОС = Astra Linux (Smolensk) 1.6
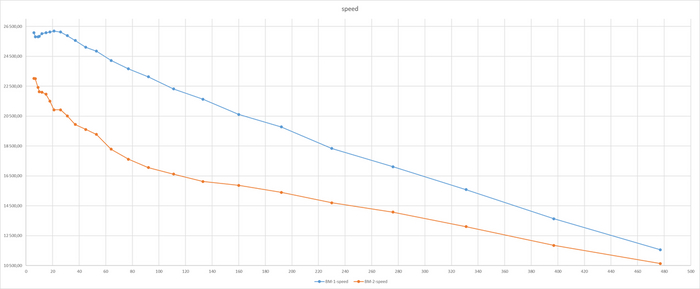
Итоги теста по сценарию TPC-B
Производительность ВМ-1 существенно выше ВМ-2
Т.е. по итогам данного теста получается - СУБД развёрнутая по шаблону ВМ-1 будет существенно производительнее ?
Что будет , если архитектор примет решение о выборе версии СУБД и запланирует ресурсы инфраструктуры на основании только данного теста ?
Решение проблемы
Одного теста для анализа производительности СУБД и ВМ - недостаточно.
Как было указано в документации:
Однако вы можете легко протестировать и другие сценарии, написав собственные скрипты транзакций.
Что и было сделано.
Для продолжения тестов, был подготовлен сценарий требующий серьезных вычислительных ресурсов - SELECT ... JOIN
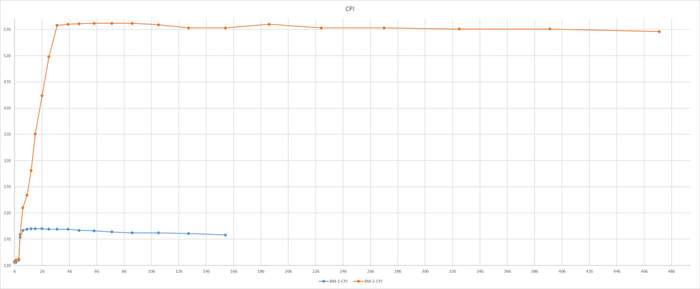
Результат тестирования тяжелого запроса
ВМ-2 СУЩЕСТВЕННО производительнее чем ВМ-1
Все встало на свои места.
ВМ-1 даже не хватило ресурсов при количестве одновременных запросов свыше 160. При этом производительности ВМ-2 существенно выше производительности ВМ-1.
Итог
Нельзя принимать архитектурных решений на основании результатов одного только сценария нагрузочного тестирования
2. Для оценки производительности архитектурного решения по конкретной СУБД необходим комплекс разных сценариев нагрузочного тестирования.
Как минимум:
-Select only: оценка скорости чтения данных из СУБД
-Standard: оценка производительности СУБД в условиях конкуренции за блокировки.
-Heavyweight: оценка производительности СУБД при выполнении тяжелых вычислительных и ресурсоемких операций.
В прошлом посте обмолвился, что собираюсь в своей базе данных завести каждому пользователю по табличке. Ну потому что у меня запросы всегда только для одного пользователя, а значит можно сэкономить ресурсы сервера на индексации, так я думал. Мне накидали полную панамку что так делать нельзя, но почему – никто особо не объяснил. И я решил бахнуть небольшой тест на нескольких БД – проверить что там будет на самом деле.
Для ЛЛ: В большинстве случаев выдавать каждому пользователю по таблице действительно нет смысла. Но для SQLite запросы обрабатываются ощутимо быстрее, если у каждого пользователя своя табличка.
Итак, тестовая задача, более- менее приближенная к моему сценарию:
периодически пользователи закидываеют в БД записи в которой есть ID пользоватея, время записи, текстовая метка (комментарий) и какой-то параметр (число)
после наполнения базы пользователями иногда запрашивается статистика по тому самому числовому параметру за какой-то период времени и с определенным комментарием
SELECT SUM( dat_stat ) FROM mega_table WHERE id=%s AND dt < %s AND dt > %s AND txt = %s
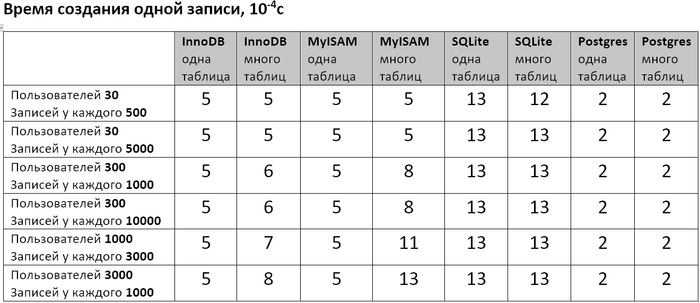
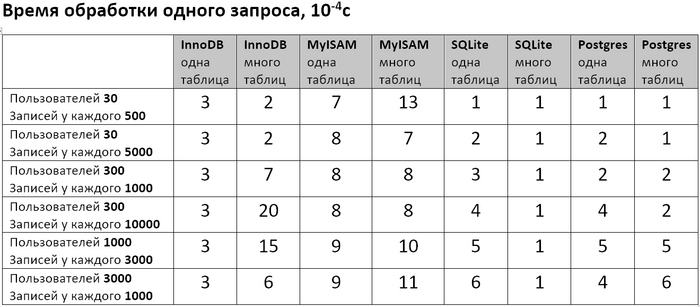
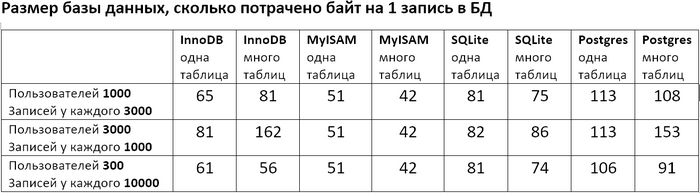
Проверял 3 БД: MySQL сдвижками InnoDB и MyISAM, SQLite и Postgres. Написал скрипт, который эмулирует заполнение БД и запросы к ней, и измеряет сколько времени занимает добавление записи и выполнение запроса. Скачать скриптец можно тут (он сугубо тестовый, т.е. стрёмный и без никакой обработки ошибок, уж сорян). Менял количество пользователей и количество записей у каждого пользователя и смотрел что будет если всё писать в одну таблицу, либо каждому пользователю создавать отдельную. Заодно после выполнения скрипта посмотрел сколько полученные базы данных занимают места на диске. И вот получились такие таблички.
Какие выводы я для себя сделал.
Во первых видно, что если делать по таблице для каждого пользователя, то и добавление записи, и обработка запроса и размер БД получаются вобщем не лучше, чем если завести одну таблицу на всех. Единственное исключение – выполнение запросов в SQLite (и в некоторых случаях для Postgre) может быть в разы быстрее на многих таблицах, чем на одной. Почему так получается? Думаю потому что БД люто заоптимизированы очень крутыми чуваками под определенные сценарии использования. И если ты не столь-же крут (я лично нет), то нужно выбрать наиболее подходящую БД и подгонять свою задачу под типичные сценарии использования этой БД.
Во вторых если мне важнее скорость добавления/чтения (т.е. экономить вычислительные ресурсы) то из протестированных лучше пользовать Postgres, если важнее экономить место на диске – то MySQL с движком MyISAM. MySQL с движком InnoDB где-то посередине.
В третьих SQLite неожиданно всех обошел в скорости выполнения запросов (для моего случая по крайней мере). Прикольно.
Ну и в четвертых, питоновская обёртка для SQL-запросов про которую я писал в прошлом посте таки упростила бы мне написание тестового скрипта, но для чистоты эксперимента пришлось её отложить в сторону.
В любом случае это было интересно сделать, надеюсь кому-то было интересно и почитать.