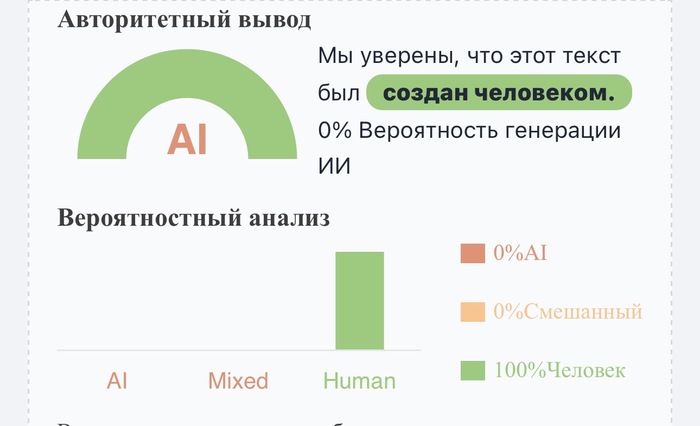
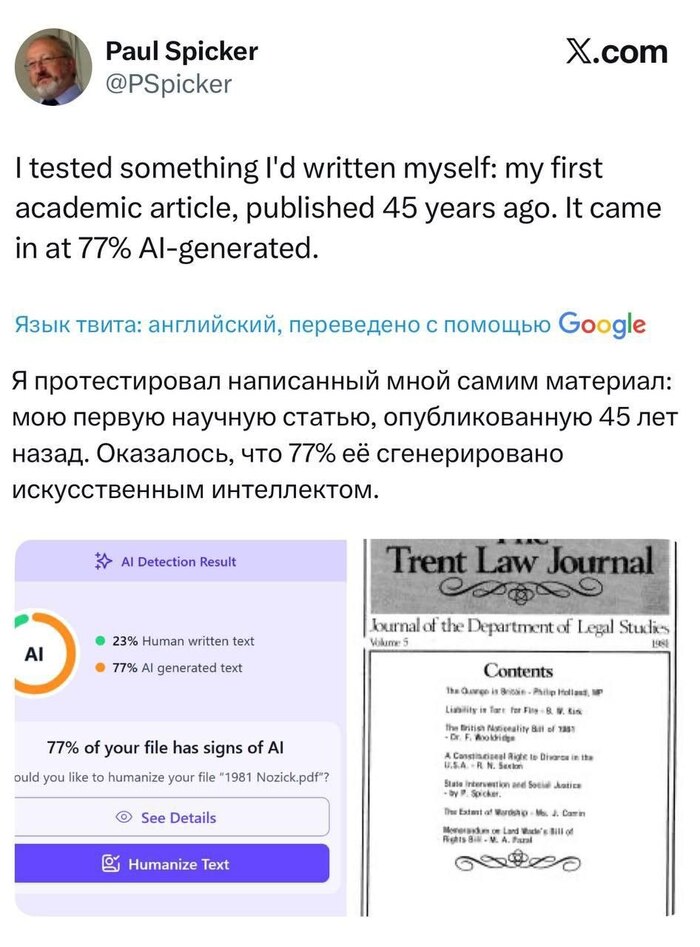
Что неудивительно, тк нейросети обучаются в том числе и на академических текстах.
Коль уж пошел разговор про нейросети, а я как раз ими и занимаюсь, давайте пробежимся по базе.
Как работают ИИ-детекторы, почему их легко обойти и почему они врут?
Так как я уже давно работаю с ИИ, мне приходилось вручную собирать информацию по крупицам, не каждые из которых были доступны даже на Английском. Тем не менее я считаю, что у меня есть достаточно данных, чтобы пояснить что это и с чем это едят.
И так. ИИ-детекторы определяют текст по следующим критериями:
Перплексия (perplexity) — это показатель того, насколько уверенно языковая модель «угадывает» следующий элемент в тексте. Если значение низкое, значит модель хорошо справляется: текст для неё выглядит логичным и предсказуемым. Высокая перплексия, наоборот, говорит о том, что последовательность кажется модели менее очевидной и содержит больше неожиданных сочетаний слов.
Perplexity(W)=exp(−N1i=1∑NlogP(wi∣w1,…,wi−1)
Перплеусия это показатель того, насколько текст «понятен» модели.
Да. Любая модель ИИ если что это просто рандомизатор текста, который пытается угадать как правильно написать ответ.
Взрывчатость (burstiness) измеряет вариативность длины и структуры предложений. Люди склонны писать «взрывами и затишьями», смешивая длинные, сложные предложения с короткими и емкими. Это создает неравномерный, «взрывной» ритм. Модели ИИ, напротив, обычно создают текст с более однородной и регулярной структурой предложений, что приводит к низкой взрывчатости.
Эта однородность является прямым артефактом формульного, пословного процесса генерации.
Формально это можно посчитать через два параметра:
λλ — средний промежуток между появлениями слов,
kk — средний размер таких «кусков».
Тогда показатель взрывчатости считается так:
Вот взрывчатость текста и является как правило фактором определения у всяких ИИ-детекторов. Дело все в том, что академические текста (на которых чаще всего и обучались нейронки), как правило длинные, размеренные, что и приводит детектор в ступор.
Но ещё одним фактором является стилометрия.
Стилометрия — это изучение лингвистического стиля, и она лежит в основе многих функций обнаружения. Детекторы анализируют тексты на предмет закономерностей в стиле, структуре предложений, частоте слов и других параметрах. Ключевые признаки включают:
• Лексическое разнообразие: Текст, сгенерированный ИИ, часто имеет менее разнообразный словарный запас. Детекторы анализируют такие метрики, как количество уникальных слов, соотношение уникальных слов к общему числу слов (коэффициент лексического разнообразия, Type-Token Ratio) и частоту слов, встречающихся только один раз (hapax legomenon rate).
• Синтаксическая структура: Человеческое письмо демонстрирует более экспериментальные и разнообразные структуры предложений. Текст ИИ, особенно от ранних моделей, часто сохраняет «стерильную» и последовательную структуру с плавными, логичными переходами, которые могут ощущаться неестественно. Средняя длина предложения — еще один важный признак.
• Выбор слов и фраз: Модели ИИ часто злоупотребляют определенными переходными фразами («В заключение», «Это означает, что...»), общими или универсальными утверждениями и формальным языком, что может быть обнаружено детекторами.
Все вышеуказанные данные отлично ложиться на любой академический/научный текст и даже на художественные произведения.
Это не весь гайд, лишь кусок из ~70 страниц.
Даже этой незначительной инструкции хватает, чтобы обойти самые последние версии ИИ-детекторов