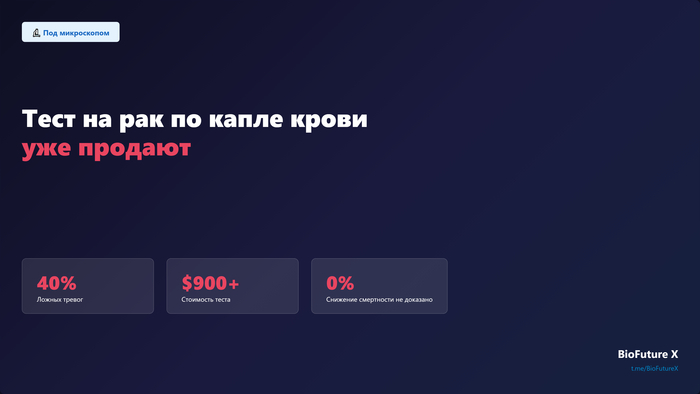


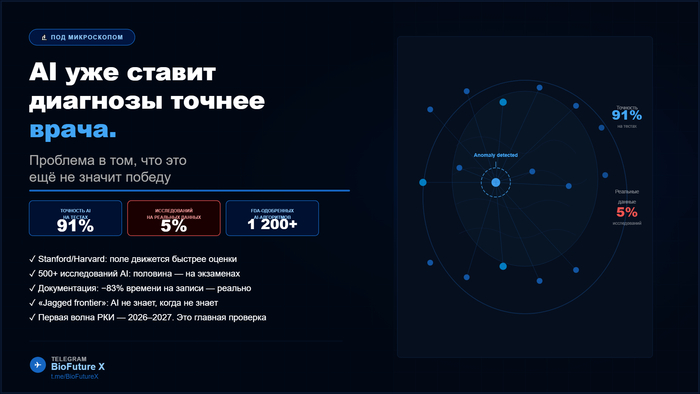
AI уже ставит диагнозы точнее врача. Проблема в том, что это ещё не значит победу
В январе 2026 года Stanford и Harvard опубликовали первый совместный доклад о клиническом AI. Вывод обескураживает: «поле движется быстрее, чем его способность оценивать само себя».
В апреле 2026 года Stanford HAI опубликовал очередной ежегодный AI Index — 400-страничный доклад о состоянии искусственного интеллекта. В медицинском разделе одна цифра стоит отдельного разговора.
Исследователи проанализировали более 500 клинических исследований AI в медицине. Почти половина из них использовали в качестве «теста» экзаменационные вопросы — стандартизированные задачи с готовыми ответами. И только 5% исследований использовали реальные клинические данные реальных пациентов.
При этом системы AI регулярно «превосходят врачей» — на тех самых экзаменационных вопросах.
Это противоречие — не случайность и не технический нюанс. Это центральная проблема одного из самых быстро развивающихся направлений в медицине. И именно её стоит понять каждому, кто следит за историей AI в диагностике.
Что умеет AI в медицине — честный перечень
Начнём с того, что реально работает. Это важно — потому что скептицизм по отношению к хайпу не означает отрицания реальных достижений.
Клиническое документирование. AI-системы, которые слушают разговор врача с пациентом и автоматически формируют структурированную медицинскую карту, — это область, где внедрение состоялось по-настоящему. По данным нескольких крупных больничных систем США, врачи сообщают об 83% снижении времени на написание записей и значимом снижении выгорания. Это реальный эффект, измеренный в реальных клиниках. Сюда не нужны слова «потенциально» или «в перспективе» — это уже сегодня.
Радиология и скрининг. Здесь доказательная база сильнее всего в диагностическом AI. В маммографии — корейское исследование: AI показал 90% чувствительность при выявлении рака груди против 78% у радиологов. AI-триаж рентгеновских снимков в нескольких уровень-1 травмцентрах позволяет прочитать экстренные снимки на 20–30 минут быстрее. В Москве проспективное многоцентровое исследование (67 медицинских организаций, 15+ месяцев) показало, что AI в комбинации с радиологом лучше выявляет внутричерепные кровоизлияния, чем каждый из них по отдельности.
ЭКГ и структурная кардиология. Модель EchoNext в многоцентровом исследовании показала точность 77,3% при выявлении структурных заболеваний сердца по 12-канальной ЭКГ против 64% у кардиологов. Это не benchmark, это реальные пациенты.
Предиктивная аналитика. AI-системы, которые выявляют госпитализированных пациентов с риском ухудшения состояния, уже работают в больницах по всему миру. В ряде систем они снизили число непредвиденных переводов в реанимацию.
Но вот где история становится сложнее.
Benchmark vs реальная клиника: в чём разница и почему она огромна
AI-система, набирающая 91% на экзаменационных медицинских вопросах (MedQA), — это впечатляющий результат. Для сравнения: средний показатель врачей на тех же тестах — около 70–75%. Заголовки «AI превзошёл врачей» — технически верны в этом контексте.
Но вот в чём дело.
Экзаменационный вопрос — это куратированный кейс с полной информацией, чёткой формулировкой, единственным правильным ответом и отсутствием неопределённости. Реальный пациент — это человек с неполным анамнезом, противоречивыми симптомами, сопутствующими болезнями, социальным контекстом и неоднозначными данными анализов. Плюс врач, который несёт юридическую ответственность и знает что-то важное, чего нет в документах.
Из более чем 500 клинических исследований AI в медицине почти половина использовали экзаменационные вопросы вместо реальных данных пациентов. Только 5% использовали реальные клинические данные. Stanford AI Index 2026.
Stanford/Harvard ARISE Network в своём докладе «State of Clinical AI 2026» (январь 2026) называет это «рваной границей» (jagged frontier): модели показывают сверхчеловеческие результаты на контролируемых задачах — и одновременно демонстрируют хрупкость при работе с неопределённостью. Система, которая великолепно разбирает фиксированные клинические случаи, может не знать, когда она не знает. Это принципиальная проблема для клинического применения.
Исследование обобщения AI в радиологии (систематический обзор, 6 исследований, 2022–2025): внутренняя валидация — AUC 0,76–0,95. Внешняя валидация на данных из других больниц — производительность снижается. Это значит: алгоритм, обученный на снимках больницы А, может плохо работать в больнице Б. Не потому что алгоритм плохой — потому что медицинские данные зависят от оборудования, протоколов, популяции пациентов.
1200 одобренных FDA алгоритмов. Что за этим стоит
К 2026 году FDA одобрило более 1200 AI-алгоритмов для медицины. Звучит как монументальное достижение. Но нужно понимать, что именно означает это одобрение.
FDA «расчищает» (clearance) устройства через разные механизмы. Большинство медицинских AI-алгоритмов проходят через 510(k) — путь, который требует не доказательства превосходства, а доказательства «существенной эквивалентности» уже существующему одобренному устройству. Это означает, что многие из 1200+ алгоритмов не проходили проспективных рандомизированных испытаний, показывающих улучшение клинических исходов.
Stanford/Harvard доклад прямо пишет: «поле движется быстрее, чем его практика оценки». Клинические испытания AI начались, но их недостаточно. Доказательная медицина требует не просто точности на тестовой выборке, а улучшения исходов для пациентов — смертности, осложнений, качества жизни. Таких данных пока мало.
Параллельная проблема: непрозрачность. Stanford AI Index 2026 констатирует, что наиболее мощные модели — наименее прозрачные. Данные о составе обучающих данных, архитектуре, параметрах больше не раскрываются рядом ведущих разработчиков. В клинической медицине, где критично понимать ограничения инструмента, это создаёт реальные риски.
Где AI в медицине работает лучше всего прямо сейчас
Если очистить поле от хайпа и смотреть на реальную доказательную базу, картина такая:
Сильная доказательная база: скрининговая маммография, выявление диабетической ретинопатии (одна из первых областей с FDA-одобренным автономным AI), тriage рентгенограмм в экстренной помощи, ускорение клинической документации, выявление пациентов с риском ухудшения в стационаре.
Перспективное, но требует больше данных: диагностика меланомы, анализ ЭКГ для структурных заболеваний сердца, скрининг колоректального рака при колоноскопии, сепсис-скрининг.
Пока преимущественно benchmark, а не клиника: общая диагностическая экспертиза (LLM на медицинских вопросах), лечение и назначение терапии, взаимодействие с пациентами без надёжной «эскалации» к врачу.
Ключевой паттерн: AI убедительнее всего работает там, где задача узкая, выходные данные хорошо определены, и есть большой массив размеченных данных. Чем шире и неоднозначнее клиническая задача — тем осторожнее нужно быть с экстраполяцией.
Новое измерение: AI в диагностике старения и онкологии
Для аудитории BioFuture X особенно интересна точка пересечения AI с геронаукой и онкологией.
В диагностике болезни Альцгеймера AI-модель Массачусетской больницы общего профиля научилась прогнозировать когнитивное снижение и развитие деменции за годы до появления симптомов — по анализу речи с 78,2% точностью. Это не benchmark, это реальные данные NIA.
В онкологии жидкая биопсия с AI-анализом — одна из наиболее динамичных областей. Подход Johns Hopkins MIGHT (Multidimensional Informed Generalized Hypothesis Testing) показывает новый уровень надёжности при раннем выявлении рака по анализу клеточно-свободной ДНК из крови. Однако та же команда подчёркивает: клинические испытания и внешняя валидация необходимы — AI-инструменты нельзя рассматривать как замену клинического суждения.
В патоморфологии AI-системы для анализа цифровых слайдов позволяют сократить время диагностики на ~90% при сопоставимой точности — это важно в контексте глобальной нехватки патологоанатомов, особенно в развивающихся странах.
«Цифровые двойники» пациентов — динамические вычислительные представления индивидуальных пациентов, обновляемые в реальном времени по мере поступления данных, — начинают появляться как концепция. Публикации выросли с нуля в 2015 году до 372 статей в 2025 году. Ранние результаты обнадёживают, масштабных клинических испытаний пока нет.
Где хайп, а где реальность
Что реально сильно: AI в скрининге (маммография, ретинопатия), клиническая документация, триаж и приоритизация, предиктивная аналитика в стационаре. Это уже внедрено и даёт измеримый эффект.
Что пока хайп: «AI диагностирует всё лучше любого врача» — это верно на экзаменационных вопросах и узких задачах, но не подтверждено для широкой клинической практики. «1200 одобренных FDA алгоритмов» звучит как триумф, но большинство не проходили проспективных РКИ с клиническими исходами.
Что замалчивается: проблема обобщения — алгоритм, обученный в одной больнице, может плохо работать в другой. Проблема неопределённости — многие модели не знают, когда они не знают, что особенно опасно в медицине. Проблема непрозрачности — наиболее мощные коммерческие модели раскрывают о себе всё меньше. И главное: прогресс в точности на тестовых выборках ≠ улучшение клинических исходов пациентов.
Где индустрия сейчас: рандомизированные проспективные клинические испытания AI только начались. Stanford/Harvard доклад говорит: именно они должны стать следующей волной доказательств. Пока их мало — поле опирается преимущественно на ретроспективные исследования и benchmark-данные.
Что это значит на практике
Если вы пациент: AI-инструменты уже помогают врачу — в скрининге, в приоритизации, в снижении административной нагрузки. Это реальная польза. Но системы, с которыми вы взаимодействуете напрямую (чат-боты, AI-ассистенты для симптомов), пока имеют ограниченную клиническую валидацию. Главный вопрос при любом AI-инструменте: есть ли человек в петле — и каков протокол эскалации к специалисту?
Если вы медицинский специалист: AI убедительнее всего там, где задача узкая и хорошо определена. Используйте AI как второй взгляд, а не как замену клинического суждения — особенно в ситуациях неопределённости. Следите за внешней валидацией инструментов, которые внедряете: хорошие результаты на обучающей выборке не гарантируют перенос на вашу популяцию пациентов.
Если вы инвестор или предприниматель в healthtech: ключевой разрыв сейчас — не в точности алгоритмов, а в клинической валидации и внедрении. Компании, которые смогут провести проспективные испытания и доказать улучшение клинических исходов, создадут принципиально другой конкурентный результат, чем те, кто демонстрирует только benchmark-результаты.
Чего ждать в 2026–2027: первая волна проспективных РКИ клинического AI. Если они покажут улучшение реальных исходов — это действительно изменит стандарт диагностики. Если нет — переход от benchmark к клинике окажется сложнее, чем ожидалось.
Как я это вижу
AI в медицинской диагностике — это, вероятно, самая значимая технологическая трансформация здравоохранения со времён МРТ. Не потому что AI «лучше врача» — а потому что AI меняет масштаб: один хороший алгоритм может работать в миллионах точек одновременно, не уставая, не пропуская смены, не зависясь от географии.
Но я возвращаюсь к цифре: 5% исследований на реальных клинических данных из 500+. Это не техническая статистика — это диагноз состояния поля. Мы много знаем о том, что AI умеет на хорошо подготовленных задачах. Мы гораздо меньше знаем о том, что происходит, когда этот AI попадает в реальную больницу с реальными пациентами, реальным шумом в данных и реальной ценой ошибки.
Stanford и Harvard правы: поле движется быстрее, чем его способность оценивать само себя. Следующие 2–3 года дадут ответ: конвертируется ли впечатляющий прогресс в точности в измеримое улучшение жизни и здоровья пациентов. Вот это будет настоящей победой — а не очередной строчкой в benchmark.
Что важно запомнить
✅ AI уже внедрён и работает: клиническая документация (−83% времени на записи), скрининговая маммография, триаж рентгенограмм, предиктивная аналитика в стационаре
✅ Более 1 200 AI-алгоритмов одобрено FDA для медицины (2026)
✅ LLM-модели набирают 91%+ на медицинских экзаменационных вопросах — выше среднего врача
✅ AI в ЭКГ: точность 77,3% vs 64% у кардиологов при структурных болезнях сердца
❌ Из 500+ клинических исследований AI — только 5% использовали реальные клинические данные. Почти половина — экзаменационные вопросы (Stanford AI Index 2026)
❌ Benchmark ≠ реальная клиника: алгоритмы теряют точность при внешней валидации на данных из других больниц
❌ Большинство из 1200+ FDA-одобренных алгоритмов не проходили РКИ с клиническими исходами
⚠ Проблема «jagged frontier»: модели могут не знать, когда они не знают — критически важно в медицине
⚠ Наиболее мощные коммерческие модели становятся всё менее прозрачными в отношении обучающих данных и архитектуры
⏳ Первая волна проспективных РКИ клинического AI — ожидается в 2026–2027. Это и будет настоящей проверкой
🤖 Слежу за клиническим AI в реальном времени
Проспективные испытания AI начались — их результаты в 2026–2027 годах определят, как быстро AI войдёт в реальный стандарт диагностики. Когда появятся первые данные — разберу сразу.
В Telegram-канале BioFuture X слежу за этим направлением каждую неделю: новые исследования, одобрения FDA, реальные внедрения — без маркетинга, только данные.