

Вопрос к знатокам
Как написать формулу для условного форматирования в Excel так, чтобы в диапазоне H2:AA2 закрашивались те ячейки, сумма которых превышает значение в ячейке G2. все остальные ячейки не должны закрашиваться.
Как написать формулу для условного форматирования в Excel так, чтобы в диапазоне H2:AA2 закрашивались те ячейки, сумма которых превышает значение в ячейке G2. все остальные ячейки не должны закрашиваться.
Имеется длинный столбец с числами в одной таблице. Второй столбец готовый и пустой.
Имеются два длинных столбца с примерно теми же числами в первом столбце и другими числами - во втором.
Задача: расставить числа из второго столбца второй таблицы во второй столбец первой таблицы так, чтобы они соответствовали своей паре в первой таблице.
Может быть, не очень понятно объяснил... Знающих, кто обладает свободным временем, прошу в телеграм: t.me/hirurgia2. Есть возможность через Anydesk подключиться.
Нет, просто по возрастанию/убыванию столбцы сортировать нельзя. Необходимо сохранить порядок чисел в первой таблице.
Делал по работе таблицу с концентрациями вещества. Мне нужно было получить колонку с пропорциями и использовал в экселе функцию НОД (наименьший общий делитель, если кто не знает).
Столкнулся с вот таким интересным явлением (это уже не мои вычисления а попытка разобраться в ошибке с концентрацией 55%):
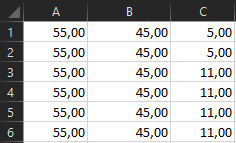
Первых две колонки - это числа (изначально - целые). В правой колонке - их НОД.

То же самое, только с отображением формул.
Чудесно, не правда ли? В какой-то момент эксель перестаёт адекватно воспринимать полученное в вычислении число и возвращает феерический результат.
Мне уже стало совсем интересно и я решил прогнать расчёт от 1 до 100%.
Чтобы не городить сложных формул, я делал промежуточные решения в столбцах. Так легче отследить ошибку.
И вот когда я на это посмотрел... я был удивлён.
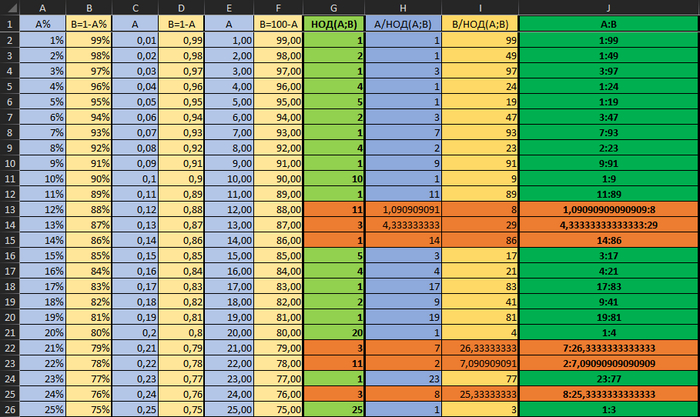
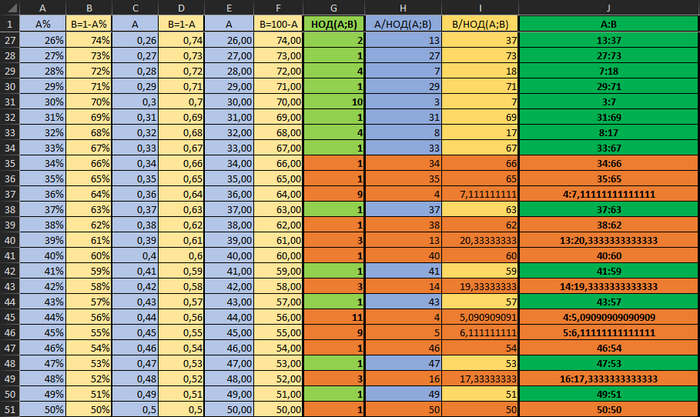
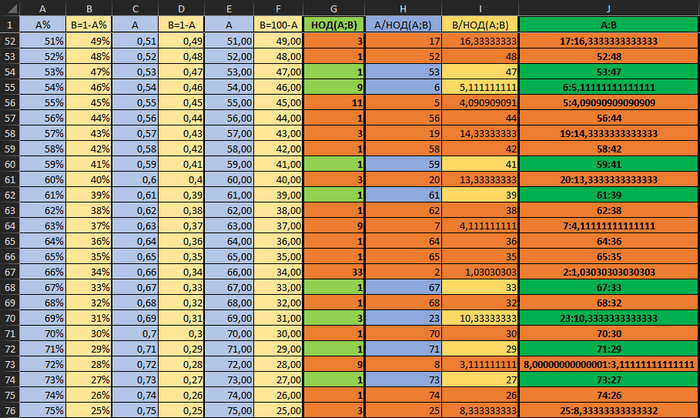
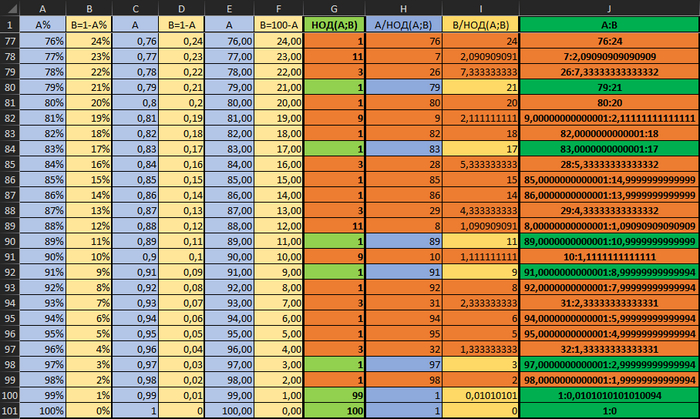
Это значения (с формулами можно ознакомиться в файле по ссылке). Оранжевым я выделил ошибки.
Из всего этого ряда мне изначально нужно было всего 20 значений. Но посчастливилось поймать ошибку и я полез разбираться.
На первый взгляд кажется, что у экселя проблема с простыми числами. Но нет, он даже для чётных чисел после 2-3 вычислений не способен выдать результат. У чётных чисел НОД = 1.

Более того, стало заметно, что точность операций с плавающей запятой - непредсказуема.
Например, НОД (20;80) он считает верно, а НОД (80;20) - уже не может. Хотя результат должен быть одинаковый.
Получается, что алгоритм вычисления НОД очень чувствителен и перед ним надо числа округлять до целых.
Используется Excel 2019. Вот прилагаю файл, если кому интересно:
https://docs.google.com/spreadsheets/d/16RMazU_jAGKAg3UHpIYL...
У кого есть возможность проверить формулы в своём экселе - какой результат покажет вам?
В комментариях указывайте версию своего экселя (или офиса).
Здравствуйте, ребята! Прошу помощи с решением задач, в долгу не останусь)



По этому мне приходиться вручную в калькуляторе вводить:
15 - 2,5% = 14,625
14,625 - 2,5% = 14,259375
14,259375 - 2,5% = 13,9028906
13,9028906 - 2,5% = 13,5553183
13,5553183 - 2,5% = 13,2164353
13,2164353 - 2,5% = 12,8860244 и т.д.
Таким образом по итогу у меня получается значения (15; 14,625; 14,259375; 13,9028906; 13,5553183; 13,2164353; 12,8860244), где каждое последующее число меньше предыдущего на 2,5%.
В связи с этим можете ли вы мне посоветовать програму, онлайн калькулятор или шаблон для Exel. Для упрощения вычислительного процесса. (Ибо вручную в калькуляторе вводить это всё не очень удобно)). Или человечество ещё не придумало как вычислять подобную числовую последовательность?
Привет!
Есть задачка замены текста с пробелом.
Вот так выглядят данные
Основные|Вес|2 кг
Основные|Вес|2.72 кг
Основные|Вес|2.5 кг
....
При попытке замены "2 кг" на "2000 г" меняет все данные.
Разбить данные по столбцам не выход, так как это ЦСВ выгрузка и данные в одной ячейке разбиты еще и переносом строки (альт+энтэр). По этой же причине нельзя использовать замену "ячейка целиком"
Может можно как-то прописать 2(СИМВОЛ(ПРОБЕЛ))кг ?
Помогите решить задачу по управленческому учету, сам уже не первый час бьюсь, не могу найти ошибку. :(
Поставьте плюсик, комментарий для минусов внутри. :)
Для решения нужно использовать Excel и модуль "Поиск решения".
Ссылка на файл Excel: https://drive.google.com/file/d/14V8BbOXhSa9QAm_ctb0-XoQ73pP...
Оранжевым отмечены значения, которые по идее должны быть целыми числами.
А красным отмечено число, которое должно быть положительным, либо равным нулю.
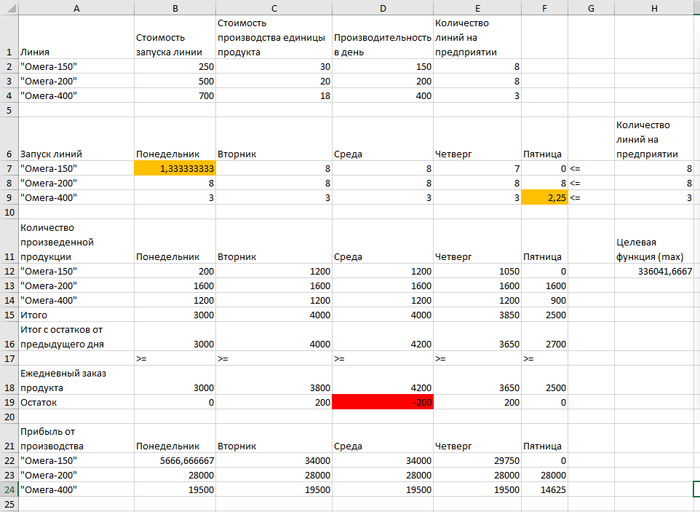
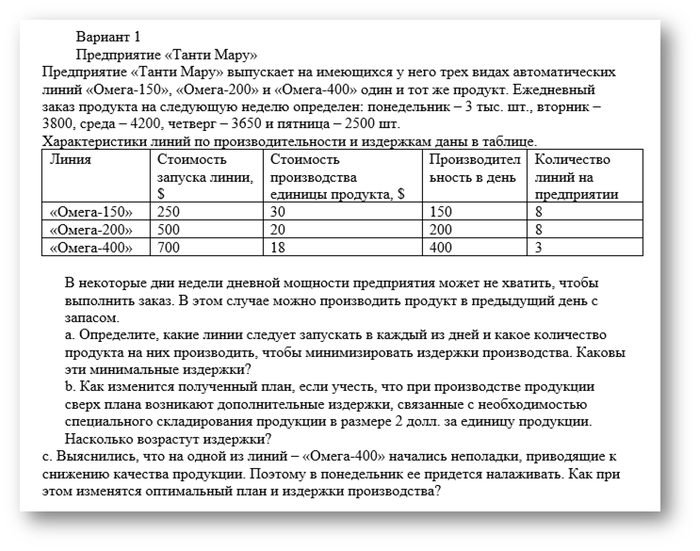
Получил вот такой вопрос:

И хочу предложить один из вариантов решения этой задачи с помощью стандартных инструментов Excel (в следующих постах также рассмотрим решение отдельно с помощью Power Query и отдельно с помощью VBA).
Итак, из постановки задачи получается, что у нас есть столбец с фамилией, именем и отчеством и в соседнем столбце указывается номер паспорта. В этой таблице теперь надо найти те записи, в которых для одного и того же человека указываются разные номера паспортов.
Как я понимаю, речь скорее всего идёт об определенном списке, который со временем пополняется всё новыми записями и нужно найти те записи, в которых были неправильно внесены паспортные номера.
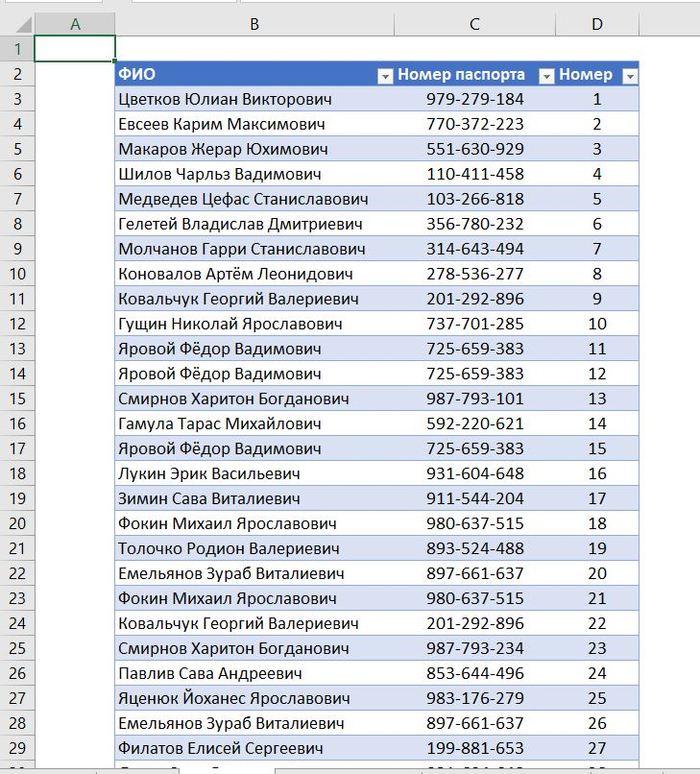
Так что, во-первых, я создал список с тридцатью воображаемыми лицами, каждому из которых присвоен рандомный номер, представим, что это и есть такой номер паспорта. Получается это и будет исходный список уникальных имён с правильными номерами паспортов, по которому мы в итоге и будем проверять правильность нашего решения:

Теперь я создам этот самый упомянутый в постановке задачи лист записи. То есть рандомно заполняю столбец ФИО лицами из нашей исходной таблички (добавляю около трёхсот строк), и в случае пяти строк преднамеренно вношу неправильный номер паспорта, симулируя ошибку.

Если также хочешь потренироваться в решении этой задачи, то вот ссылка на скачивание файла, показанного выше:
https://drive.google.com/file/d/1-y1erQDwHdAMId-juqpJ0KGMtVF...
Итак, теперь собственно процесс поиска внесённых ошибок (естественно, представляем, что не знаем их).
В первую очередь статично пронумеруем все строки, кому-как удобно (формулой и вставкой в виде значений или автозаполнением):
Теперь будем удалять дубликаты по первым двум столбцам. Для этого выбираем одну из ячеек таблицы и идём во вкладку «Данные», где затем щелкаем по «Удалить дубликаты».
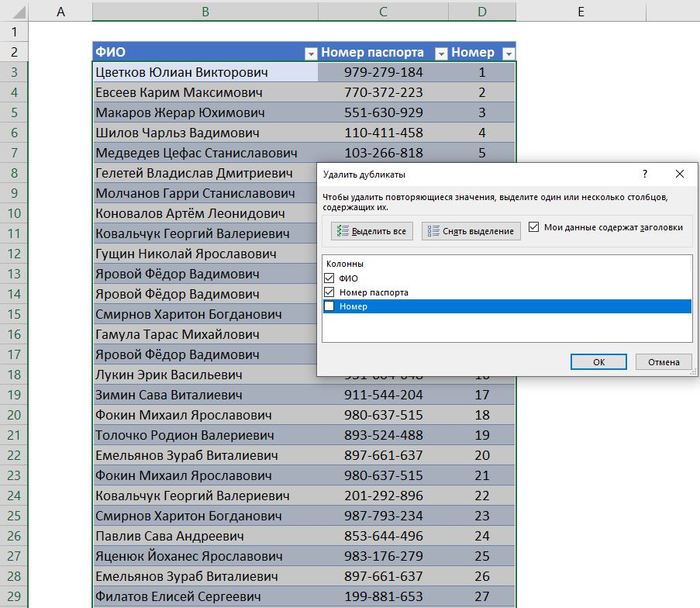
Здесь убираем галочку напротив столбца «Номер», так как он нам иначе помешает удалить правильные дубликаты записей и подтверждаем операцию. Итог будет следующий:

Уже у нас осталось 35 уникальных значений, что на 5 больше, чем в исходной таблице. Поэтому теперь делаем следующее.
Добавляем столбец «Подсчёт», и прописываем в нём функцию СЧЁТЕСЛИ. В первом аргументе указываем столбец со всеми ФИО, а во втором аргументе ссылаемся на ФИО текущей строки таблицы:
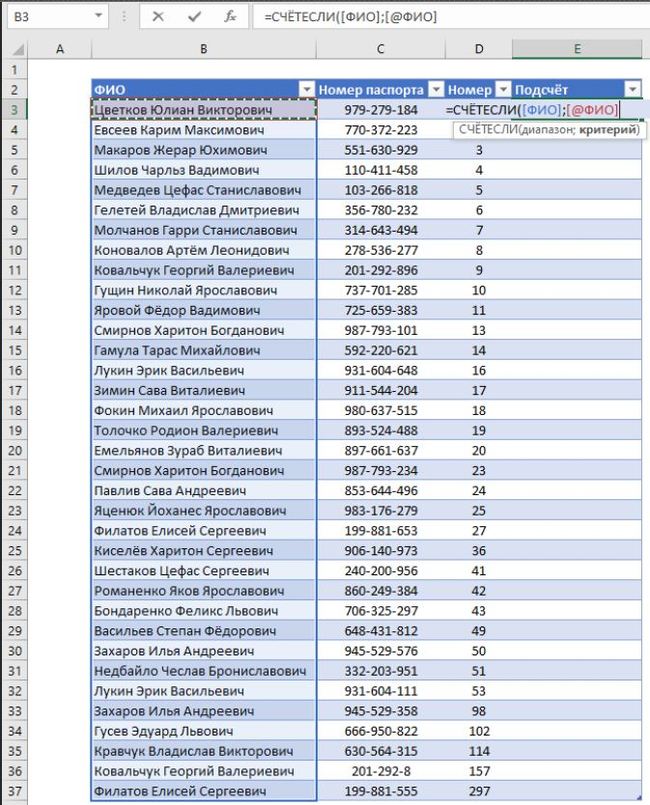
При этом я здесь работаю с умной таблицей, поэтому у меня были вставлены так называемые структурные ссылки ([ФИО], [@ФИО] и т.д.). Если тебе приходится проделывать эту операцию с обычным диапазоном на рабочем листе, то процесс имеет мельчайшее отличие (просто важно не забывать закреплять ссылки).
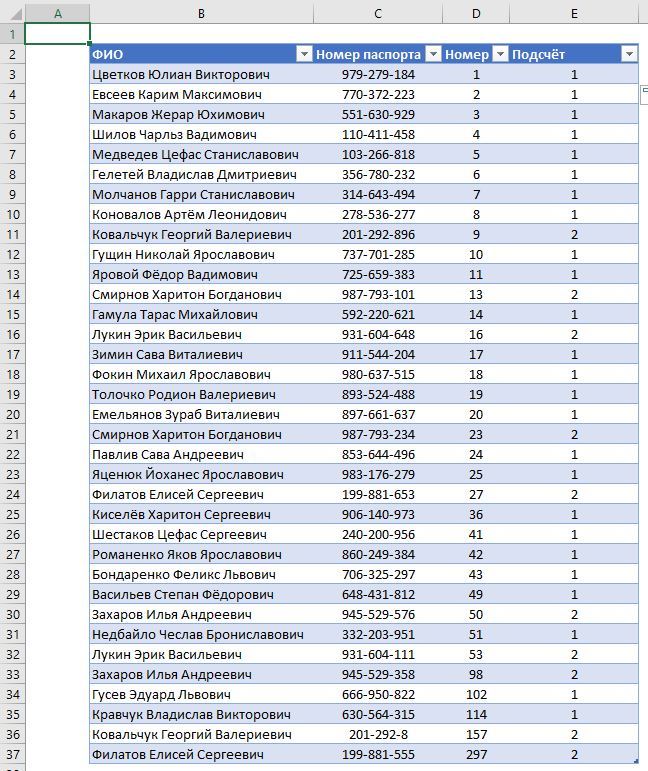
Вот что в итоге выходит в столбце «Подсчёт». Функция СЧЁТЕСЛИ считает, сколько раз встречается имя каждой текущей строки во всей таблице. Если имя встречается всего один раз, то из этого следует, что все записи с этим именем в таблице имели одинаковый номер паспорта. Там же где мы видим любое другое число нам становится понятно, сколько вариантов номера паспорта была внесено для одного и того же человека.
Так что всё что остаётся — это профильтровать значения. Убираю в фильтре столбца «Подсчёт» единицы, и мы получаем следующий результат:
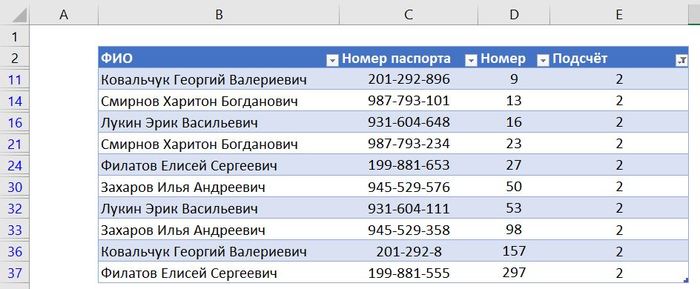
Вот у нас и показаны лишь те записи, в которых для одних и тех же лиц были вписаны разные номера паспортов. По сути дела все, задача выполнена – теперь мы знаем, что в листе записи, нужно проверить строки с выведенными на картинке выше номерами.
Ну и конечно же можно еще сделать итоговый результат попривлекательнее (условное форматирование, сортировка и так далее):
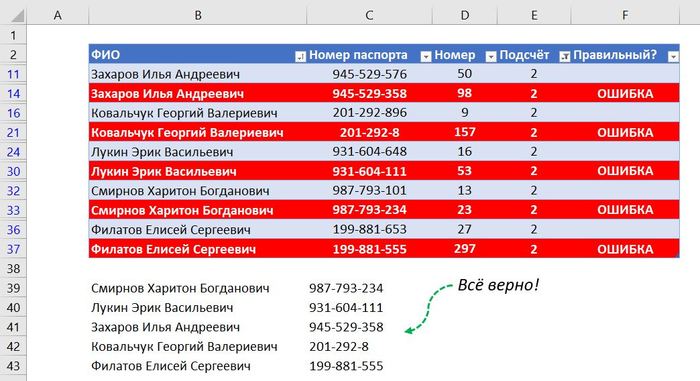
Вот такое решение поставленной задачи с помощью стандартных инструментов Excel. Если хочешь более подробно узнать о всём, что было проделано в этом примере, предлагаю посмотреть следующее видео (в нём, помимо прочего, подробно рассказываю о примененном условном форматировании, о удалении дубликатов нескольких столбцов и т.д.):
Ну а в одном из следующих столбцов мы разберем более интересное и более оптимальное решение этой же задачи – с помощью Power Query!




