Вышла новая модель для 3D-реконструкции LingBot-Map
Раскрыта новая потоковая модель-основа LingBot-Map (https://huggingface.co/robbyant/lingbot-map) для 3D-реконструкции (позы камер и карты глубины) из видеопотока.
Центральный механизм внимания Geometric Context Attention (GCA) сохраняет три типа геометрического контекста. Якорный контекст позволяет первым кадрам фиксировать масштаб и систему координат. Локальное окно опорных поз содержит последние k кадров с полными визуальными признаками для точной локальной геометрии. Память траектории представляет собой сжатые (6 токенов на кадр) признаки всех предыдущих кадров, вытесненных из окна, для подавления дрейфа.
Подобная система обеспечила стабильный вывод (около 20 FPS, разрешение 518×378) на последовательностях длиной более 10 000 кадров с почти постоянным потреблением памяти.
Двухэтапное обучение от базовой офлайн-модели к потоковой с прогрессивным увеличением длины последовательностей использовало параллельную обработку контекста (Ulysses) и относительную функцию потерь.
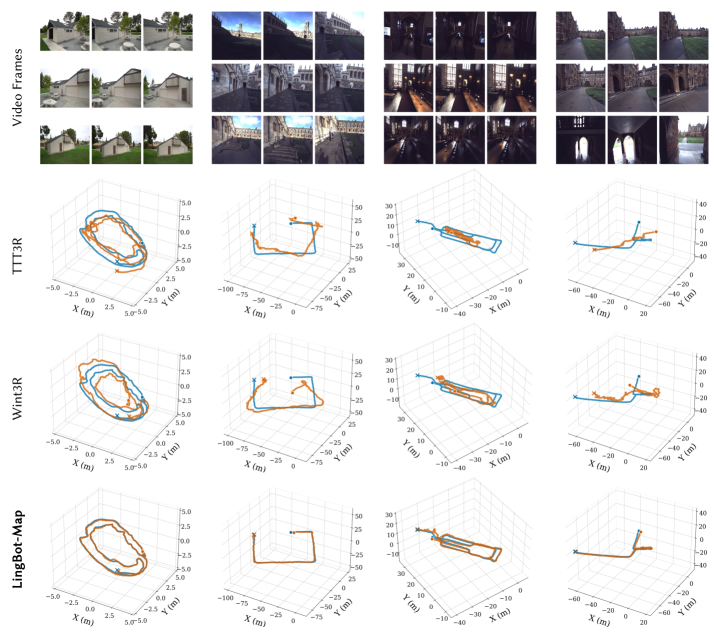
Прямой вывод предоставляет наивысшую точность для материалов до примерно 3000 кадров, тогда как VO-режим с разбиением на перекрывающиеся окна и Sim(3)-совмещением годится для задач со сколь угодно длинными роликами.
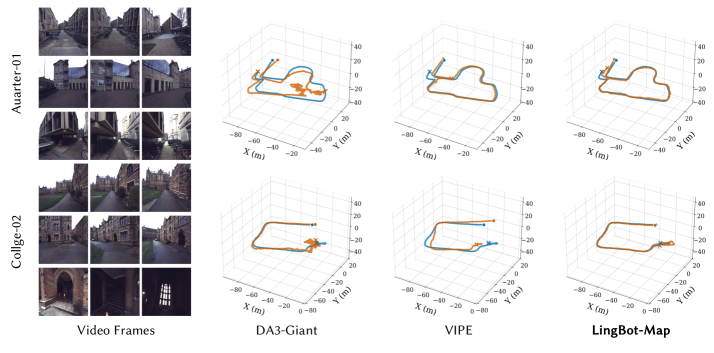
В результате достигнут state-of-the-art среди потоковых методов на Oxford Spires, ETH3D, 7-Scenes и Tanks and Temples, превосходящий офлайн и оптимизационные подходы по точности поз и качеству плотной реконструкции.