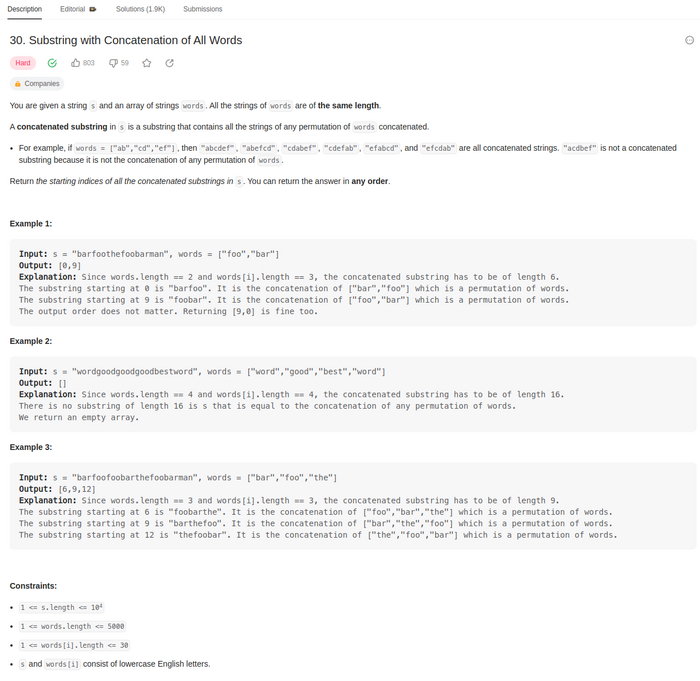
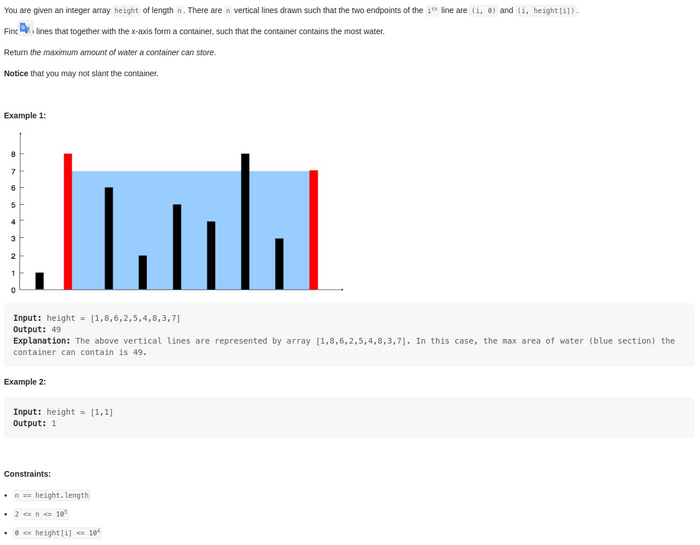
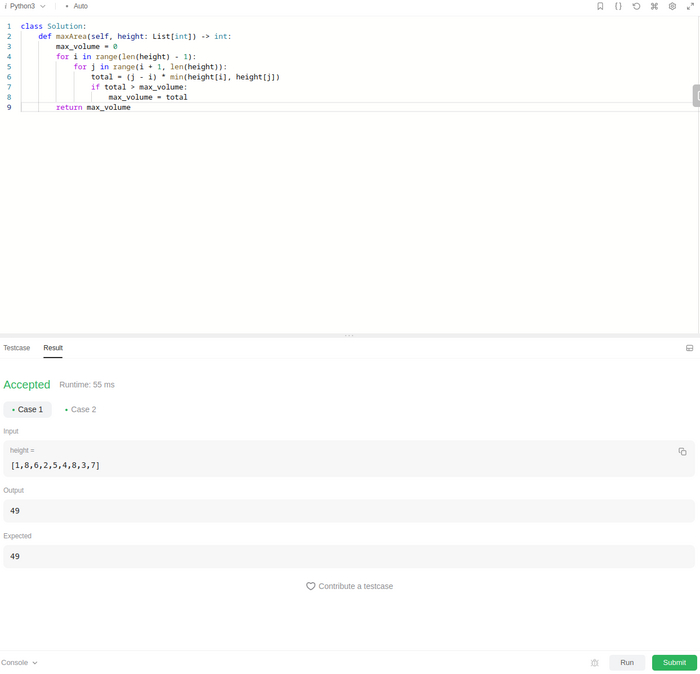
Набравшись смелости и определив изрядно времени на сегодня, я решил взять задачу, помеченную как сложная. А вот собственно и она:
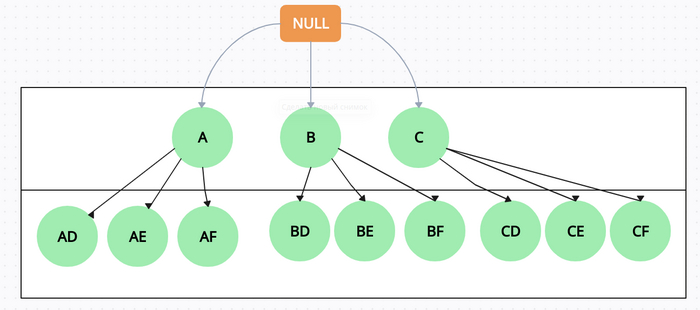
На первый взгляд задачка показалась достаточно простой и смутно знакомой. Есть текст (s) и список из текстовых переменных(words). Сначала из списка текстовых переменных составляем словарь всех возможных значений, а потом пробегаемся по значениям и ищем всех их в тексте, чего же тут hard?
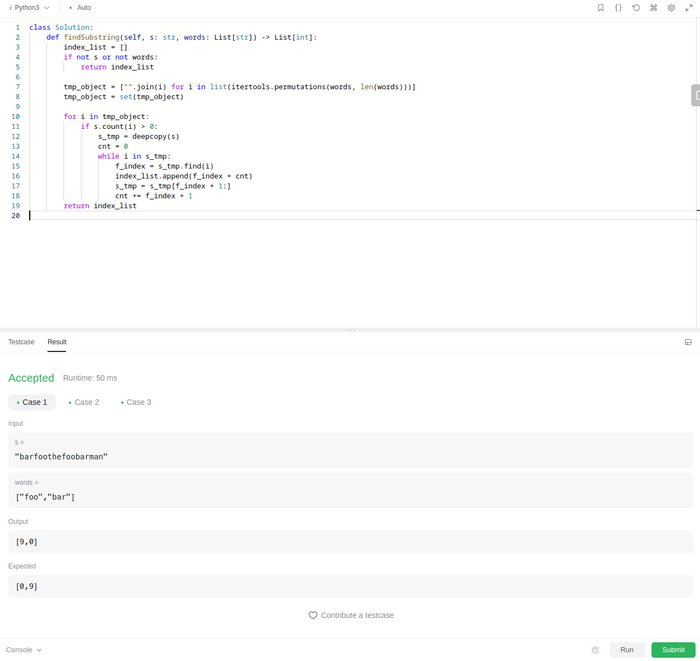
Поминая добрым словом курсы по python, я решил для генерации словаря использовать встроенный модуль itertools, он тут в самый раз. Сказано сделано, сначала составляем словарик, потом по словарику пробегаем и ищем вхождения слов в строку. И на первый взгляд все очень даже не плохо:
Если бы хотя бы примерно представлять размер словарика при имеющихся ограничениях на входные данные:
Как всегда перетащил тесткейс на локальную машину, и приложение сожрав 32 Гб памяти сказало кря, даже не сгенерировав словарь до конца. От словарика отказываемся....
Пару дней назад я делал что-то отдаленно похожее, там тоже надо было искать строку в подстроке, только самую длинную.
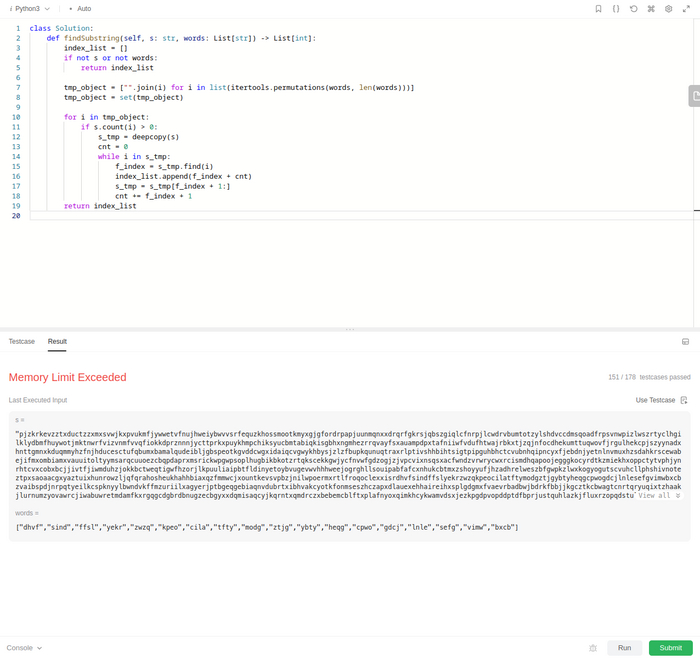
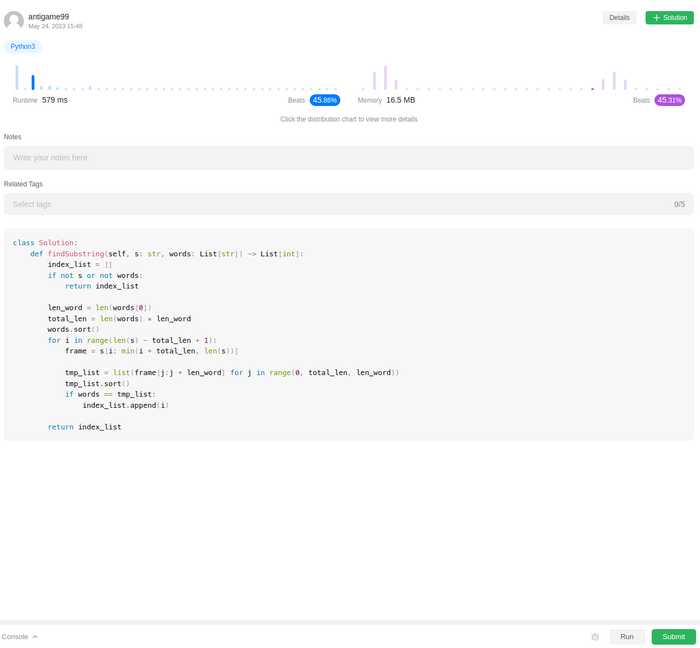
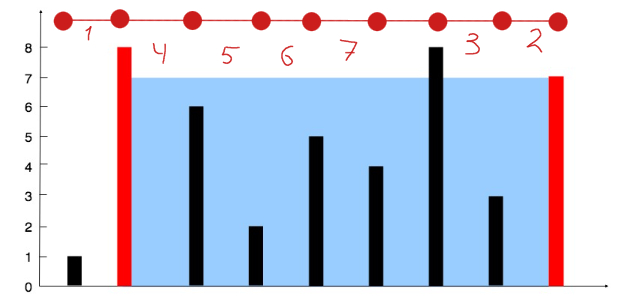
А тут же нам надо просто подсчитать количество подстрок в строке. Длина подстроки известна заранее - это сумма длин всех слов в words, значит ее и возьмем за длину кадра(среза строки). Т.е. задачка опять на скользящий кадр. Значит осталось сравнить кадр с имеющимися словами в words и записать результат для каждого кадра, а затем вернуть общий результат.
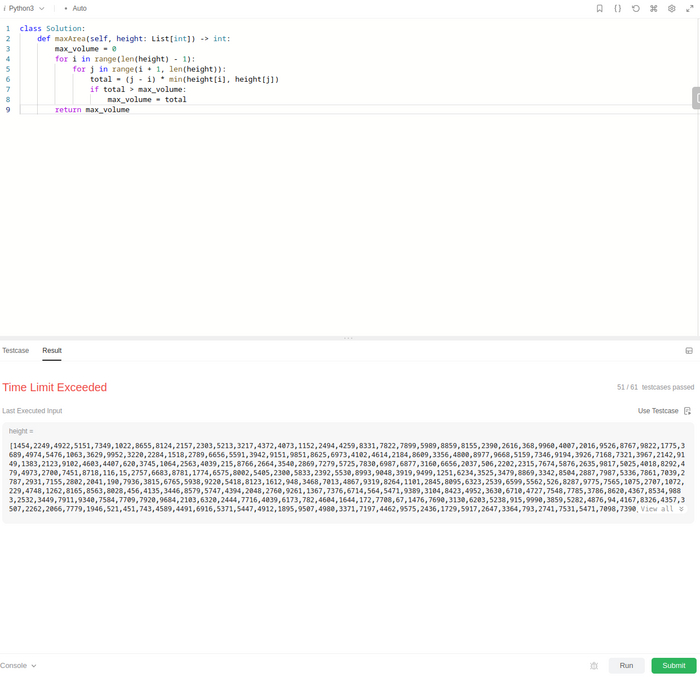
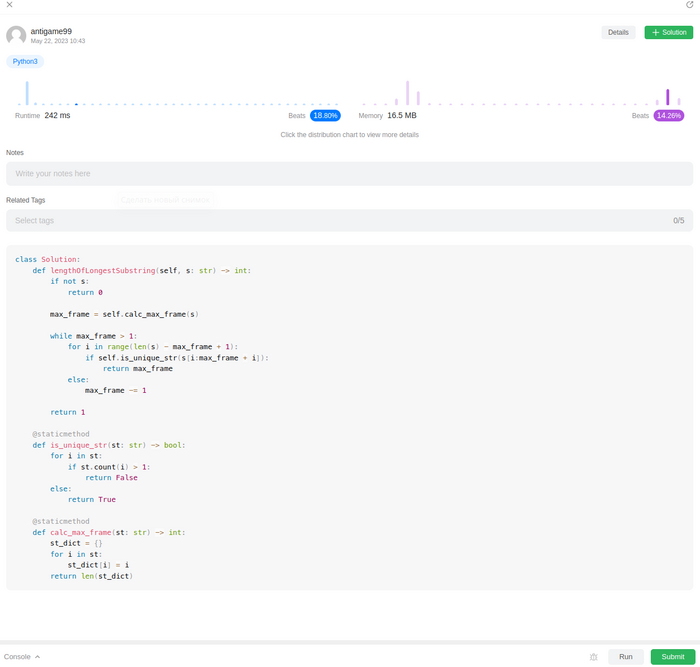
Собственно получилось, но результат проверки меня несколько удивил: все 178 кейсов выполнены успешно, но задача не зачтена, т.к. общее время выполнения вышло за рамки допустимого. Оооокееей, уже ближе, думаем дальше.
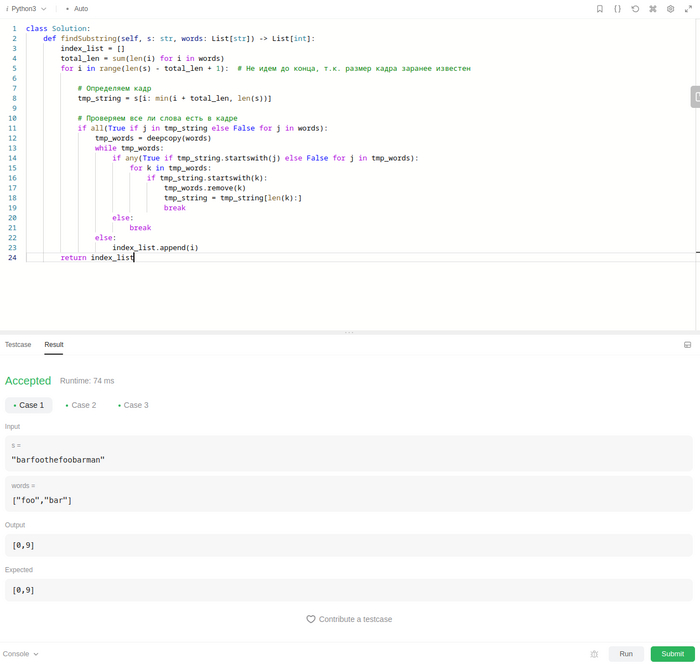
Очевидно, что тройной вложенный цикл, это как раз то, что надо как то оптимизовать, чтобы ускорить обработку. Еще одно съеденное яблочко, дало мне идею: если кадр - соответствует искомому, значит его можно разбить на равные части, количество которых будет равно размерности словаря words. Собственно, если составить список из этих частей кадра, мы и получим список words, только со значениями в произвольном порядке. Значит достаточно сортировать список words и полученный список из частей кадра и сравнить. Если сортированный words и этот сортированный новый список идентичны, значит этот кадр мы и ищем, если нет, значит пропускаем.
Решение вышло уже вполне приемлемым по скорости выполнения. На этом стоп.
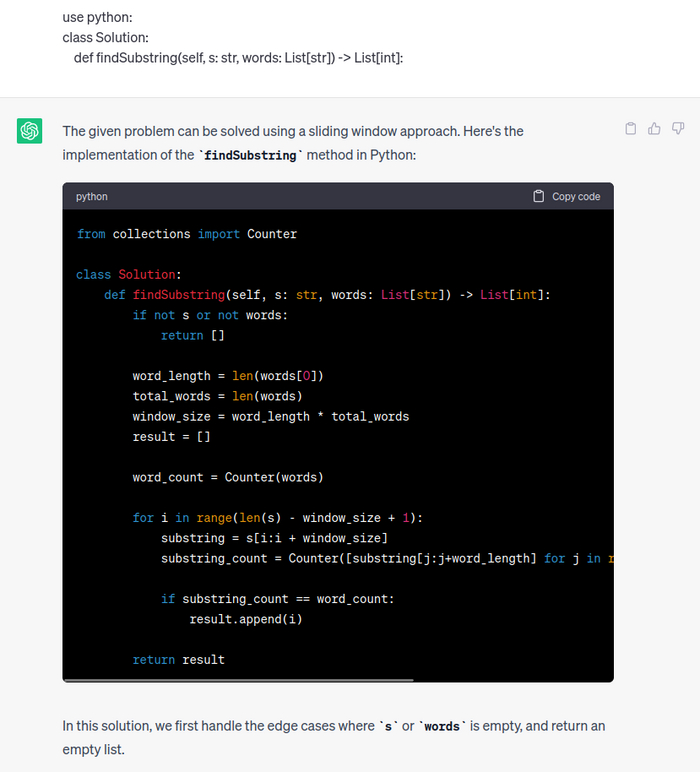
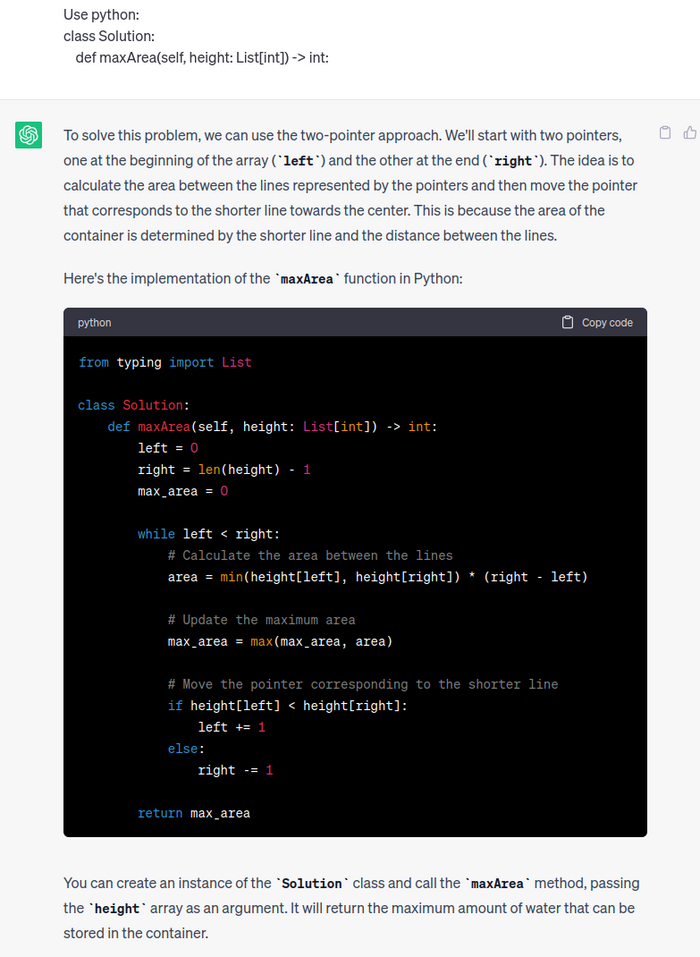
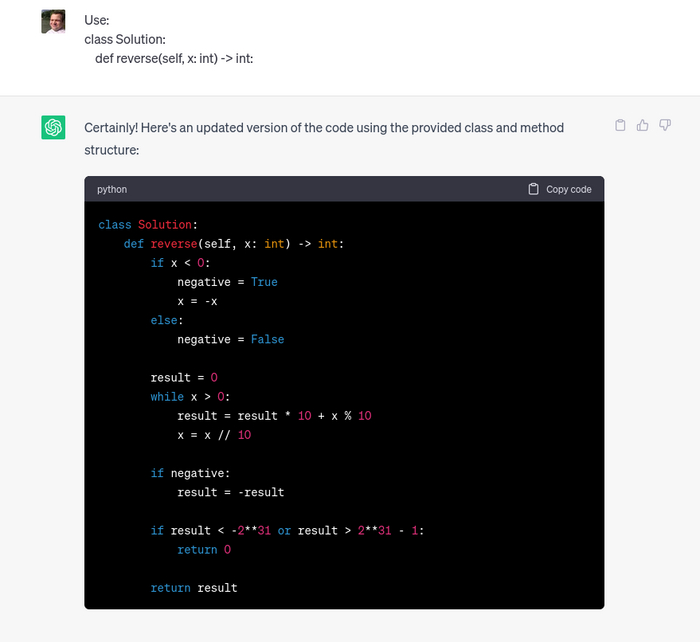
Ну и как всегда я спросил у chatGPT. Бот выдал решение крайне похожее на мое, но он использовал встроенный модуль collections, о котором я знаю мало.
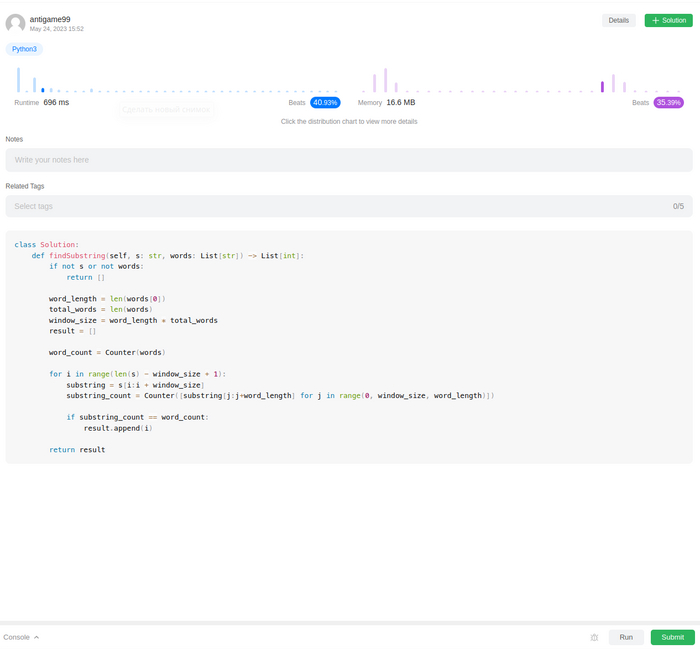
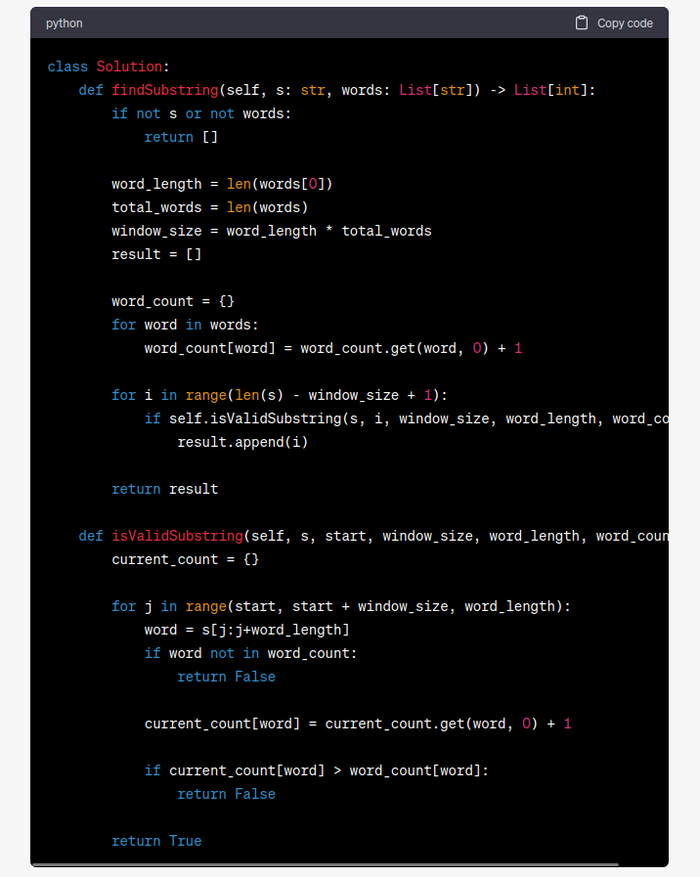
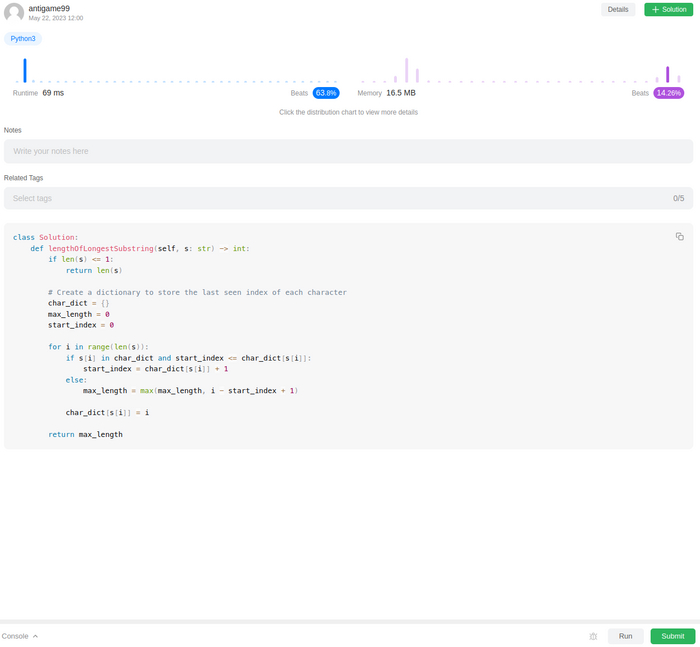
Однако достаточно было указать боту на низко производительный код, он выдал еще одно решение. Существенно быстрее предыдущего, за счет отказа от встроенного модуля collections в пользу встроенных словарей.
В общем было познавательно, на решение мной вбито 2+ часа. На решение ботом + оптимизация 2+ минуты.