

LeetCode
6 постов
6 постов
Прочитал статью в форбс: Минцифры в лице Шадаева анонсировали платный трансграничный трафик, как минимум для мобильных операторов. Анонсирован бесплатный лимит в 15 Гб, остальное платно. Для меня очевидно, что этот порог однажды уронят в 512 Мб и весь трансграничный трафик будет платным. РКН в очередной раз обосрался с техническими ограничениями, потому правительство переходит к экономическим мерам воздействия, конечно же на население.
Теперь давайте считать потери. Наилучший сценарий для пользователя, где у него есть наземный интернет по кабелю до квартиры.Просто запрещаем телефонам обновления через мобильные сети и все манипуляции с тяжелым трафиком делаем дома. Это все еще неприятно, т.к. ютубчик в дороге становится платным, но кажется не смертельно.
Наихудший вариант: вы в деревне, где стационарных сетей нет и у вас мобильная опсос - единственное средство доступа в сеть. Ну или эту фичу с ограничением трансграничного трафика обяжут прикрутить и наземных операторов типа РТК. И вот тут уже становиться очень плохо, потому что мы неожиданно обнаружим следующие платные вещи, которые распространяются бесплатно:
1) Обновление ОС/ПО для Adroid/Windows/iOS/Linux, в том числе и приложения из магазина приложений. На себе могу сказать, что 3Гб+ в неделю для моей Fedora
2) Просмотр легального контента зарубежных сервисов типа Netflix, Apple TV и прочее
3) Пиринговые сети, читай раздача/скачивание торентов будет убито, Xatab не одобрит
4) Элементарно скачать купленную в стиме игру будет очень платно, современные игры 100+ Гб.
5) В принципе сервисы гугл типа почты, гугл-фото станут платными

Плата за вещи распространяемые бесплатно за плату выглядит как налог на воздух.
Бонусом Шадаев попросил операторов цифровых платформ VK, Ozon, «Авито», Wildberries, «Яндекс» - принять меры против использования их клиентами средств обхода блокировок. Т.е. прямо стучать на использование вами ВПН будут эти конторы, ну или ограничивать работу своих сервисов для пользователей, что вряд ли, они же не враги себе.
А ну и вишенка на торте, господин министр предупреждает нас неразумных. Если вдруг мы продолжим пользоваться средствами обхода будут административки. А следом и уголовки, я правильно понимаю?
Источник Forbes, знакомый с ходом обсуждения, добавил, что в ходе совещания Максут Шадаев не исключил также возможность введения административной ответственности за использование средств обхода блокировок, при этом министр выразил надежду, что удастся обойтись без этого.
Ненависти прибавилось существенно, очередная антинародная мера от дорого правительства.
Ссылка на статью для модератора
https://www.forbes.ru/tekhnologii/558273-operatory-vvedut-pl...
В какой-то момент времени мне стало душно от мира, мир тоже ко мне симпатий не испытывал. Я закрылся от людей и в ближний круг никого не впускал, жизнь была поделена как телефон, первый для всех, второй для близких людей числом до десятка. Первый просто выключался после окончания рабочего времени, если было такое настроение, ну или просто переводился в беззвучный режим.
На фоне описанного выше, познакомился с девушкой и по привычке выдал ей рабочий номер, через него с ней и общался. Отношения развивались, но как то закрутилось и личный номер я не выдавал, не то чтобы сознательно, просто не приходилось к случаю. Отношения стремительно развивались и однажды обнаружил, что мы уже на той стадии, где я предлагаю прекратить тупить и перевезти ко мне остатки ее вещей из съемной комнатки, перестать отдавать сумму денег каждый месяц. В общем ситуация с личным номером телефона уже перезрела и я решил вывернуться обратив все в веселую шутку.
Очередным вечером беру её за руку, заглядываю в глаза и говорю очень проникновенно:
- Дорогая, пора мне кажется пока перевести наши отношения на новый уровень!
- Какой еще новый уровень, я уже у тебя живу?
- Пора дать тебе мой личный номер телефона!
- А у меня тогда **** что тогда?
- Рабочий...
В общем шутка удалась на столько, что спустя 10+ лет и двоих детей теперь уже жена периодически мне припоминает, правда она ее такой веселой почему-то не считает. Жена моя, тег моё =)
Привет, котятки.
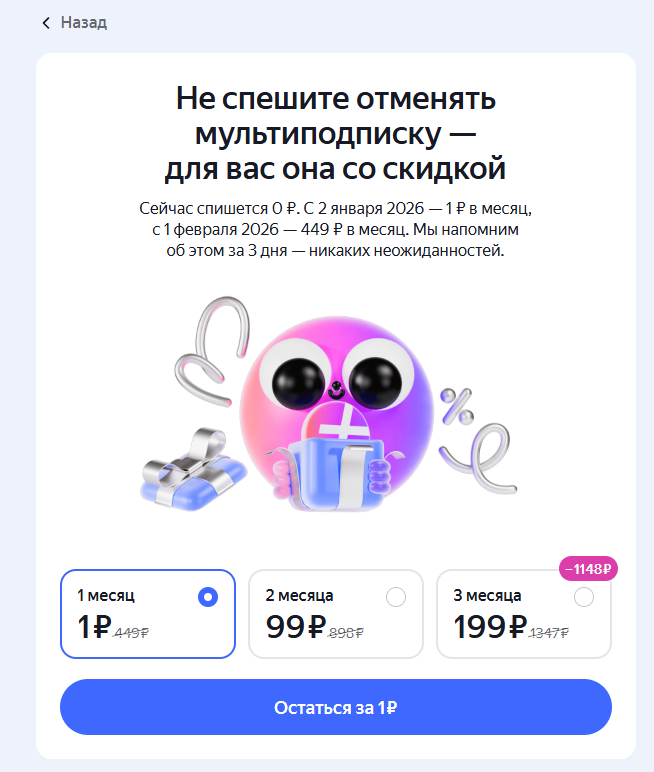
Захотел отменить подписку яндекс плюс, т.к. автопродления с оплатой сразу на год(со скидкой)не существует. Я сндекс, в надежде на мою забывчивость дарит мне месяц за рубль, ну или 3 за 199 рубликов, проверяйте. Механизмы удержания наверняка одни и те же.
Как у родителя, у меня возник вопрос: как объяснить ребенку, что же произошло. С одной стороны можно сказать, что добрые дядьки в РКН борются с террористами, а в твоей игрушке таких оказалось много, и вот пока всех террористов не почистят, роблокс блокирован. С другой поставить ему ПНВ, обучить пользоваться и рассказать, что у власти в стране упопротые наркоманы, видящие терроризм в детской игрушке.
Вопрос важный, ибо с братьями из другого города это у них было место встречи. Поэтому прошу тыкнуть голосовалку и по возможности поднять вверх. Без рейтинга.
Слушай, дядя Костин, ты никогда не видел оправдывающих насилие в стиле "она сама так вырядилась"? "Без лоха и жизнь плоха" стала практически народной. Но даже не это, как по мне, основной источник разрушение понятия законности. А причины в том, что ты уже не отличаешь законное от незаконного.
Вот тебе в одностороннем порядке сотовый оператор подключил услугу знакомств в симку на контроллере ворот на даче - это законно? Вот банк начислил пенни по выплаченному 3 года назад кредиту, нормально? Вот в автосалоне ты можешь купить машину только с комплекте с ковриками по 200к за штуку, это мошенничество? И это то с чем мы сталкиваемся в жизни, а теперь открываем твои истории, какой же пиздец с решениями судов, причем я не про справедливость, а хотя бы про законность, а потом еще больший пиздец с исполнением решений этих судов. И это все на фоне судей без образования, судей имеющих сеть борделей, простых полканов с миллиардами наворованного, битых на камеру заключенных в СИЗО, зеков выпущенных из тюрьмы по непонятным основаниям.
Поэтому у населения в этой мешанине критическое мышление плывет, потому что ориентиров нет, что ты собственно и наблюдаешь у себя в комментах. Бытие определяет сознание однако...
Нам уже начали продавать великую победу, план то ведь наш, значит это мир на наших условиях, значит победили мы. Это основной нарратив, дальше могу сделать ставку, всплывает какой-нибудь мегаэксперт, который нам всем расскажет, что по этому плану все цели СВО, какие бы они не оказались в итого, достигнуты. Вуаля, вы победители в экзистенциальной войне, можно и дальше спокойно продавать газ, нефть, уран.
З.Ы. Принцип сработает и с той стороны. Откажемся от пары пунктов и вуаля, победили мы.
Под "бонапартистом" я разумею вообще всякого, кто смешивает выражение "отечество" с выражением "ваше превосходительство" и даже отдает предпочтение последнему перед первым. Таких людей во всех странах множество, а у нас до того довольно, что хоть лопатами огребай.
М. Е. Салтыков-Щедрин
Котятки, почитайте правила в голосовалке. Всем плевать на ваше очень важное и нужное голосование, оно нужно только для того чтобы сместить акценты с действительно важных проблем типа повышения налогов, снижения уровня жизни и чем-то занять самых беспокойных. Даже если вы натыкайте в Эльбурс больше, кавказский бай сможет провернуть вас на МПХ через совет директоров, а Адамчик получит еще одну медальку.

Ссылка на правила для модератора. https://cbr.ru/cash_circulation/simvoly-dlya-banknot/
З.Ы. Меня вполне устраивает родной Архангельск на 500.





