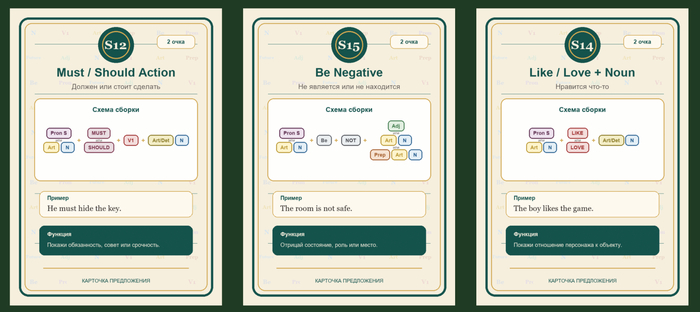
Эксперимент! Можно ли использовать нейроку в качестве судьи в лингвистической игре?
Как уже писал в предыдущих постах, я сейчас пробую разработать карточную игру для изучения английского языка. В том числе планирую использовать нейросети для проверки грамотности и для оценки результатов игры.
И на этой почве, под одним из прошлых моих постов про эту игру, у нас с @garris79 возникла дискуссия. Он писал, что нейросети страшно врут, и использовать их в качестве судьи и арбитра невозможно. Мне кажется, что это всё же возможно, и поэтому я решил произвести эксперимент.
Суть эксперимента была следующей: Я составил текст так, как он бы составлялся во время игры, тоже через нейронную сеть. К нему приписал просьбу оценки по определенным параметрам. Получившийся промпт с текстом и запросом на оценку вы можете найти внизу этого поста, в приложении 1.
Я задавал этот промпт всем нейронкам которые были под рукой (на разных уровнях анализа). В том числе это были Codex, Gemini Pro, Flash и Flash Lite, DeepSeek Lite, GPT Instant и Thinking, Sonnet от Cloudy и от Cloudy Haiku. А, и также Яндекс AI.
Результаты я записывал в таблицу для того, чтобы в дальнейшем можно было их сравнить. Таблицу вы можете видеть чуть ниже. Также в описании есть ссылка на Google таблицу, если вдруг кому-то нужно.
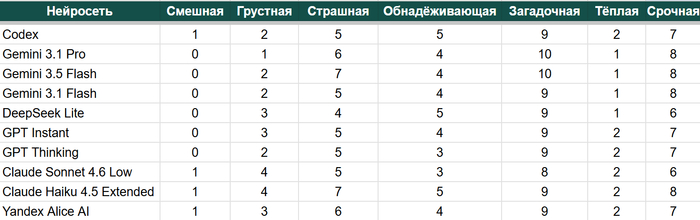
Что ж, как вы можете видеть, в целом разброс не очень большой. Видно, что есть некоторые колебания в оценках, они не стопроцентно такие же, но я думаю, что и люди будут оценивать, естественно, тоже по-разному.
Если провести немножко анализа, то получается, что в среднем разброс у нас 0,79 балла. Самое большое отличие было 1,57 на категорию.
Хотел бы обратить внимание, что вне зависимости от модели победитель всегда оставался один и тот же.
Но есть место, где нейросетки не согласились в последовательности третьего и четвертого места, а именно: "насколько история страшная или обнадеживающая". Большинство посчитало, что история более страшная, чем обнадеживающая. При этом Кодекс поставил оценку равную, а DeepSeek поставил оценку в сторону обнадеживающей истории. Но при этом большинство моделей всё равно выбрало одинаково.
Думаю, из этого можно сделать вывод, что в случае спорных ситуаций, если оценки очень близкие, имеет смысл использовать несколько нейросетей или прогнать несколько раз одну и ту же, чтобы получить взвешенную среднюю оценку, например, с трёх попыток.
@garris79, что скажешь?
Возможно, ты бы хотел присылать какой-то более неоднозначный текст для проведения подобных повторных тестов? Ну или, может быть, я что-то упускаю, и ты укажешь на это?
Кстати говоря, думаю еще над тем, чтобы провести тест на одной и той же нейронке. Выбрать какую-нибудь общедоступную, которая бесплатная. Взять самый простой режим и какой-то текст. И загонять его в нее много-много раз и смотреть, насколько будет биение в рамках одной нейронной сети. Как думаете, стоит такое сделать?
Возможно, у вас есть еще какие-то идеи, как можно эти нейронки потестить и оценить целесообразность их использования в настольных играх?
Ещё одна идея — это сделать текст и дать его сперва оценить разным людям по тем же параметрам, а после этого провести такой же опрос у нейронок и сравнить, насколько будут различаться оценки людей и оценки нейронки.
Приложение 1. Промт.
Итоговый текст на английском
There is an old map in the hotel room. It lies under a clean bed, folded many times. Lena looks at it and sees a red mark near the old station.
The traveler found a strange ticket. It was inside the map, between two thin pages. The ticket had no date, but it showed the same red mark.
The station is not safe. Lena understands this when the hotel phone rings and no one speaks. Outside, the street becomes quiet, and the last bus leaves early.
She must leave the city. Lena packs her small bag and takes the map, the ticket, and a bottle of water. She hopes the guide at the old station can explain everything.
The guide opened the door, but the room was empty. On the table, there was only a camera and a note with Lena's name. The note said, “Take the next train if you want the truth.”
Оцени итоговый текст истории по каждой цели от 0 до 10.
Цели:
Насколько история получилась смешной?
Насколько история получилась грустной?
Насколько история получилась страшной?
Насколько история получилась обнадёживающей?
Насколько история получилась загадочной?
Насколько история получилась тёплой, доброй или человечной?
Насколько история получилась срочной, напряжённой по времени?
Для каждой цели дай:
оценку от 0 до 10;
короткое объяснение, почему такая оценка;
1-2 фразы из текста или события, которые повлияли на оценку.