
PDF ассистент: Учим робота читать. Часть 2

Пост "PDF ассистент: Учим робота читать. Часть 2." продолжает цикл постов о решении повседневных задач с помощью локальных нейросетей. В прошлом посте я рассказывал о создании PDF ассистента, для локальной обработки документов. Ранее был создан ИИ ассистент работающий полностью локально без доступа к сети интернет, которому можно "скормить" документ в формате PDF и на основе данных содержащихся в нем, отправить запрос нейросети. Однако в качестве исходных данных функционал позволял загрузить только документы в формате PDF, что лишало возможности обрабатывать сканы и фото документов.
В этой части проекта добавим загрузку сканов и фото документов в форматах .png,.jpg,.jpeg с автоматическим OCR распознаванием содержимого. Весь код доступен на странице проекта github
О проекте :
Зачастую чтобы найти нужную информацию в документе на несколько десятков страниц, необходимо потратить значительное время на ознакомление, если для текста есть поиск, то для более сложных задач требуются помощь нейросетей. Существует большое количество ИИ сервисов, которым можно "скормить" наши документы. К сожалению с учетом количества "сливов утечек" данных, загружать документы содержащих личные данные или конфиденциальные сведения плохая идея. Если использование в личных целях таких сервисов происходит на свой страх и риск, то применение в корпоративных целях зачастую недопустимо. Например вряд ли клиенты клиники будут рады если их медкарта окажется на серверах OpenAi.
Поскольку я специализируюсь на дообучении и интеграции локальных ИИ моделей в корпоративных задачах, решение этой задачи будет строится на применении исключительно локальных AI технологий. В основе проекта относительно недавно вышедшие на приемлемое качество хоть и урезанные по количеству параметров версии ИИ моделей, которые можно запустить даже на домашних ПК оснащенных видеокартами с объемом памяти от 6-8Гб. Для полноценных моделей по количеству параметров этого объема VRAM домашнего ПК конечно не достаточно, да и скорость работы домашних GPU не сравнится с коммерческими AI сервисами, но для обработки средних по объему документов вполне достаточно.
Итак цель второй части очередного мини проекта выходного дня - создать ИИ ассистент работающего локально без доступа к сети интернет, которому можно "скормить" наш документ не только в формате PDF но и в виде фото или скана и на основе данных содержащихся в нем, отправить запрос нейросети. Получив в ответ информацию с учетом содержащейся в документе информации
Реализация
Поскольку в проекте уже присутствует пользовательский web интерфейc, а также основные функции API, RAG и т.д. ограничимся минимальными изменениями.
Во первых добавим в web форму изменения буквально пары строк Расширим допустимые типы загружаемых файлов
<input type="file" id="file" name="file" accept=".pdf,.png,.jpg,.jpeg" style="display: none;">
Изменим текст кнопки загрузки
<button type="button" id="uploadButton">Загрузить файл (PDF/изображение)</button>
Для OCR функционала будем использовать библиотеку easyocr она доступна по лицензии Apache-2.0, могут потребоваться дополнительные зависимости , устанавливаем библиотеку:
pip install easyocr
Данные из загруженного и преобразованного в текст документа, обрабатываются в скрипте API сервера
Строки
context = extract_text_from_pdf(file_path)
response = generate_response(query, context, role) # Passing the role to the function
return jsonify({"response": response}), 200
Заменяем на
if file_path.endswith('.pdf'):
context = extract_text_from_pdf(file_path)
elif file_path.lower().endswith(('.png', '.jpg', '.jpeg')):
context = extract_text_from_image(file_path)
else:
return jsonify({"error": "Unsupported file type"}), 400
Добавляем функцию извлечения текста в document_prcessor.py
Подключаем библиотеку
import easyocr
def extract_text_from_image(file_path):
if not os.path.exists(file_path):
raise FileNotFoundError(f"File not found: {file_path}")
Устанавливаем поддержку русского и английского языков
reader = easyocr.Reader(['ru', 'en'])
result = reader.readtext(file_path)
Извлекаем текст из результата
text = ' '.join([detection[1] for detection in result])
return text
Проверим новый функционал
Загрузим скан сметы на строительство дома в PNG формате 1240х1754
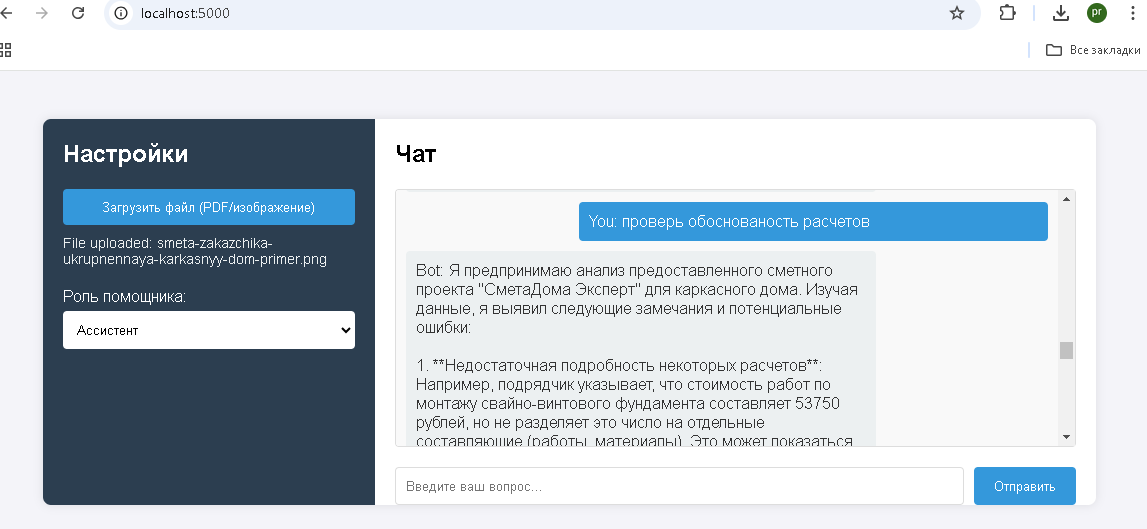
Как видно из генерации ответа, библиотека успешно справилась с распознаванием
Попробуем загрузить изображение с сканом расчета зарплаты:
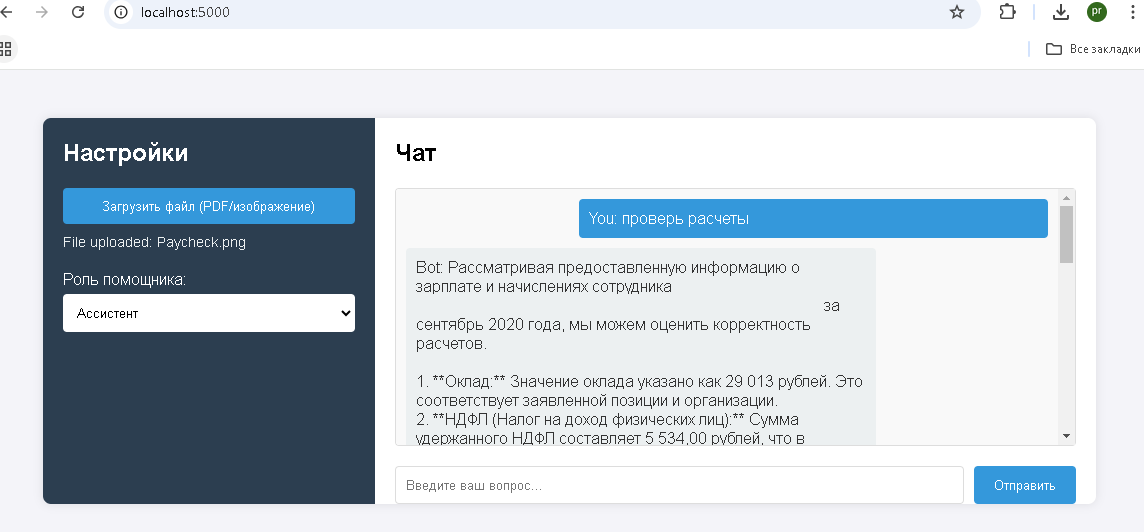
Зарплатный лист
Также успешный результат обработки изображения
Этот мини проект всего лишь один из примеров использования AI технологий, для повседневных задач
Цель проекта достигнута. а значит еще один рабочий проект отправляется в копилку мини проектов "выходного дня"
С учетом того что здесь затруднительно публиковать читаемый код корректно с TABами, весь код доступен на странице проекта github
Вопросы по коду можете писать мне в ТГ