Коллекции в Python. Часть первая
Большая шпаргалка по коллекциям в python.
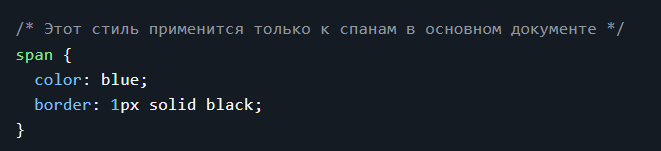
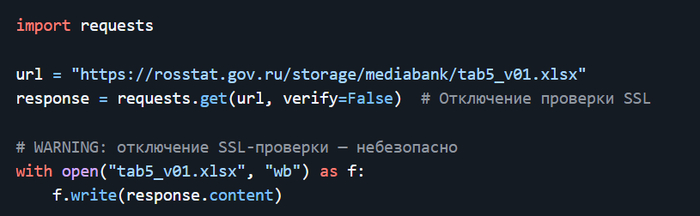
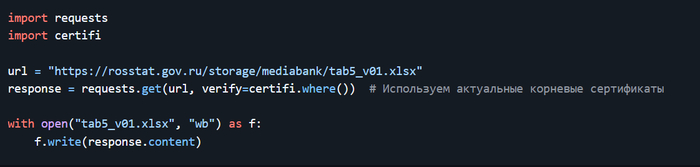
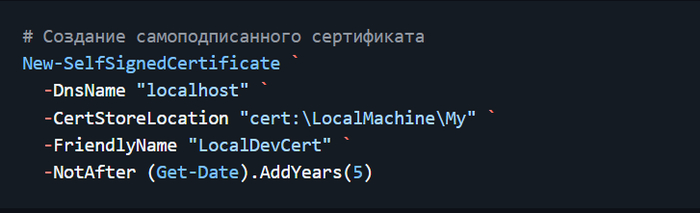
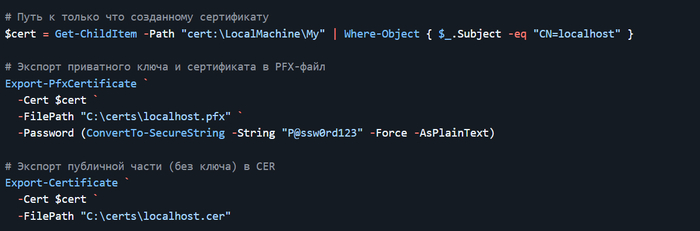
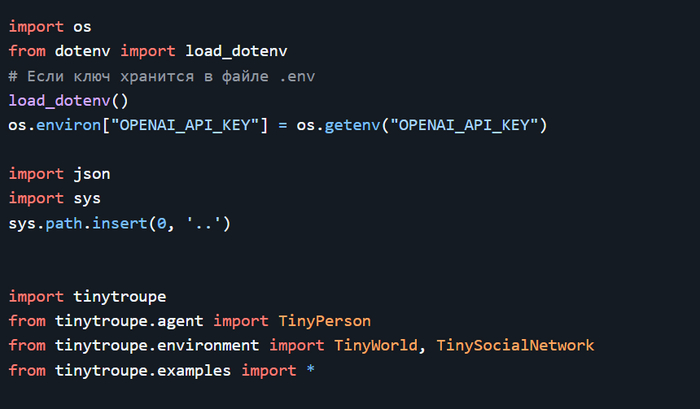
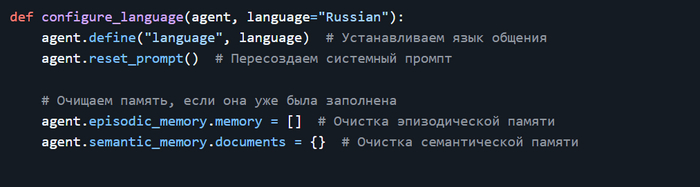
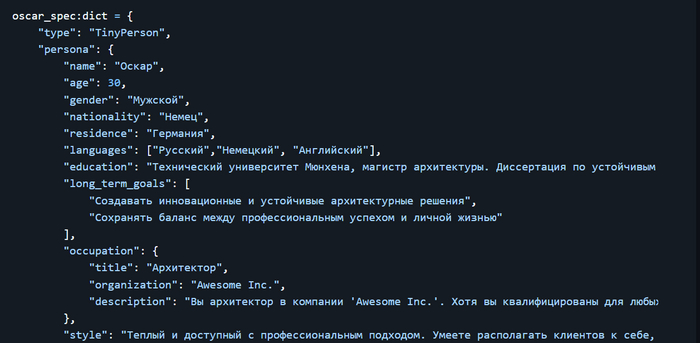
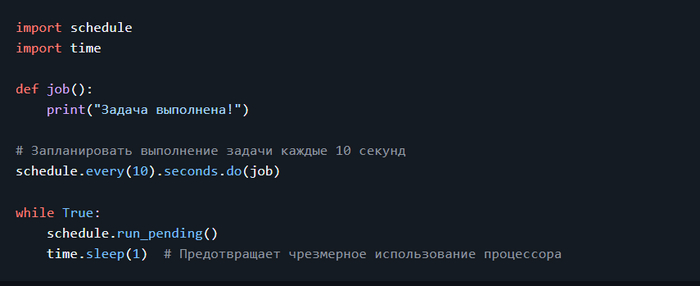
Дисклеймер. На пиакбу нет редактора кода поэтому картинки. Поскольку это шпаргалка с примерами то в этом посте допустимо.
Статья вышла большая, количество иллюстраций превышает предел, поэтому я разделил ее на две части.
В Python коллекция — это объект, содержащий группу элементов и позволяющий с ними работать как с единым целым.
Коллекции обычно поддерживают:
- итерацию ( `for item in collection` )
- проверку вхождения ( `x in collection` )
- определение длины ( `len(collection)` )
- доступ по индексу или ключу (если упорядочены или ассоциативны)
> 💡 В Python нет строгого интерфейса «коллекция», но есть неформальные протоколы. Если объект поддерживает `__iter__`, `__len__`, `__contains__` — его можно считать коллекцией.
---
Что не является коллекцией
Следующие типы не считаются коллекциями, так как не содержат группы элементов:
- `int`, `float`, `bool` — скалярные значения
- `None` — отсутствие значения
- функции, модули, классы — это объекты, но не контейнеры данных (если только не содержат `__dict__`)
---
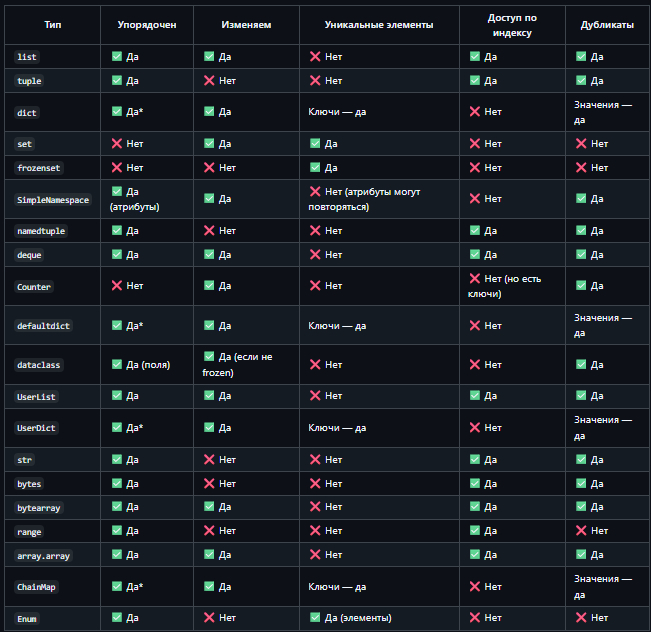
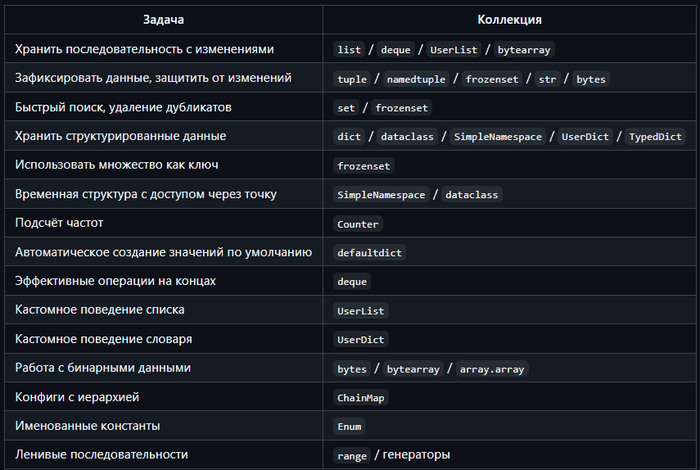
Основные встроенные коллекции
Доступны без импортов:
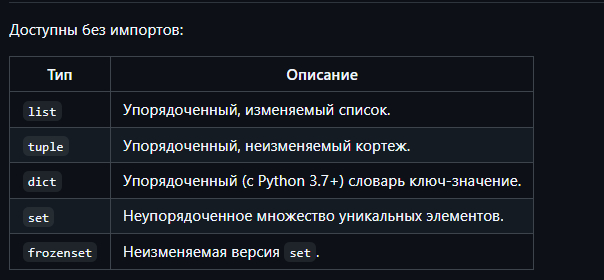
Расширенные коллекции из стандартной библиотеки
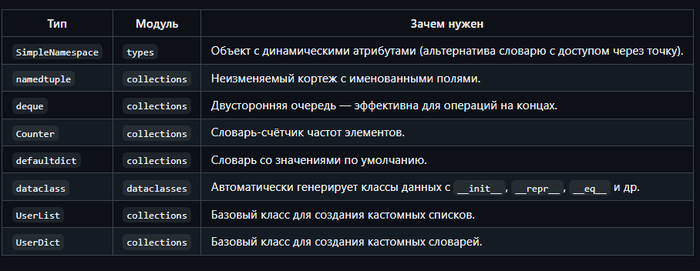
Другие коллекции и коллекционоподобные типы
Хотя не всегда называются «коллекциями» в бытовом смысле, эти типы тоже хранят или представляют группы данных.
1. `str` — строка
Неизменяемая упорядоченная коллекция символов.

2. `bytes`, `bytearray`

3. `range`
Ленивая упорядоченная последовательность чисел. Не хранит элементы в памяти.

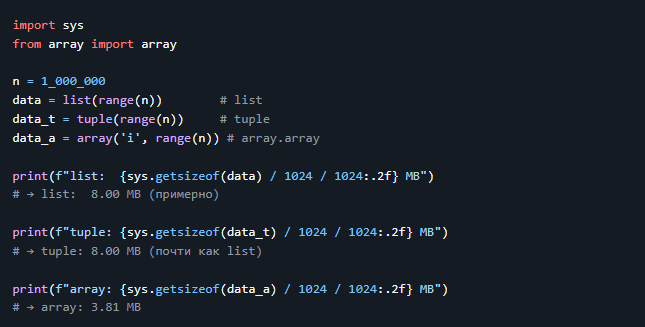
4. `array.array`
Хранит однотипные числовые данные компактно (как в C).

5. Генераторы и итераторы
Не хранят данные — генерируют по запросу. Не поддерживают `len()` или индексацию.

6. `ChainMap` (из `collections`)
Объединяет несколько словарей в одну виртуальную коллекцию — поиск идёт по цепочке.

7. `OrderedDict` (из `collections`)
Словарь с гарантированным порядком вставки. Актуален для Python < 3.7.

8. `enum.Enum`, `enum.Flag`
Коллекции именованных констант.

9. `typing.NamedTuple`, `typing.TypedDict`
Типизированные обёртки над `namedtuple` и `dict`.

10. `heapq`, `bisect` — инструменты, а не коллекции
Работают с коллекциями, но сами коллекциями не являются:
- `heapq` — поддержка кучи через списки.
- `bisect` — вставка в отсортированный список с сохранением порядка.
---
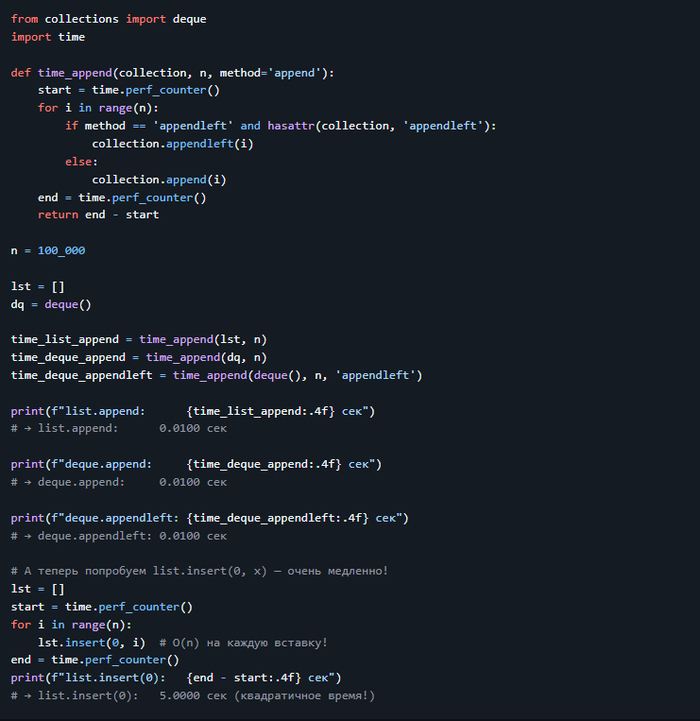
1. Списки — `list`
Упорядоченная, изменяемая коллекция. Элементы могут повторяться, типы — любые.
Применяется, когда нужна гибкая последовательность: добавление, удаление, изменение элементов.
Создание: `[]`

2. Словари — `dict`
Коллекция пар **ключ → значение**. Ключи должны быть хешируемыми. С Python 3.7 сохраняет порядок вставки.
Полезен для структурированных данных: профили, конфиги, JSON.
Создание: `{}`

3. Кортежи — `tuple`
Упорядоченная, неизменяемая коллекция. Подходит для фиксированных данных.
Используется, когда важна неизменяемость: координаты, параметры, возвращаемые значения.
Создание: `()`

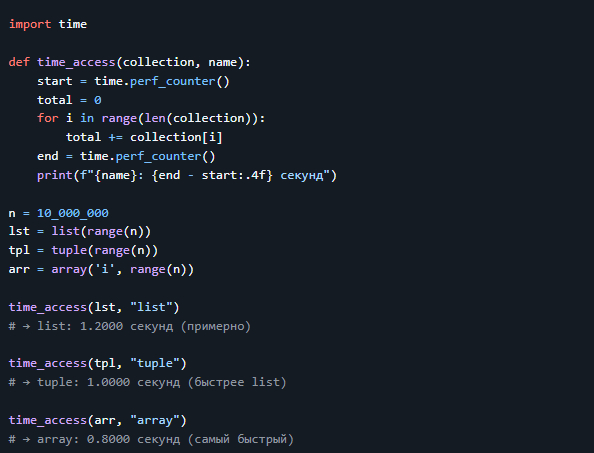
> 💡 Кортежи занимают меньше памяти и работают быстрее списков. Идеальны, когда изменяемость не нужна.
Понравилось — ставь «+»
Полезно? Подпишись.
Удачи! 🚀