

Кибербезопасность
1 пост
1 пост
Представляем новый инструмент для работы с вкладками в Chrome!
Мы рады представить уникальное расширение, которое кардинально изменит ваш опыт работы с браузером. Больше не нужно тратить время на поиск нужной вкладки среди десятков открытых!
Ключевые возможности нашего инструмента:
Мгновенный поиск по всем открытым вкладкам
Умная фильтрация по заголовкам и содержимому
Быстрая навигация между вкладками
Группировка вкладок по доменам
Поиск по истории закрытых вкладок
Как это работает?
Просто нажмите на иконку расширения или используйте горячие клавиши - и перед вами появится удобное окно поиска. Начните вводить любой текст, и система мгновенно найдет все вкладки, где встречается этот текст в заголовке или содержимом страницы.
Преимущества для разных пользователей:
Для разработчиков: Быстрый доступ к многочисленным инструментам и документации
Для исследователей: Эффективная работа с десятками открытых источников
Для маркетологов: Удобное управление множеством аналитических панелей
Для студентов: Организация учебных материалов и исследований
Пример использования:
Открыто 25 вкладок → жмем иконку → Вводим "аналитика" → Получаем 3 вкладки: Google Analytics, Яндекс.Метрика, отчёт по трафику
Установка занимает 30 секунд:
Скачайте расширение с нашего GitHub
Перейдите в chrome://extensions/
Включите режим разработчика
Загрузите распакованное расширение
Готово! Можно пользоваться
Технические особенности:
Работает полностью локально - ваши данные в безопасности
Не замедляет работу браузера
Поддерживает все версии Chrome
Бесплатно и с открытым исходным кодом
Мы создали этот инструмент, потому что сами столкнулись с проблемой управления большим количеством вкладок. Теперь мы экономим до часа времени каждый день!
Присоединяйтесь к сообществу пользователей! Устанавливайте расширение, делитесь отзывами и предлагайте новые функции.
Ссылки для скачивания и обсуждения:
GitHub репозиторий: github
Инструкция по установке: https://github.com/user9999/chrome-tab-search/blob/main/README.md
Сделано с ❤️ для тех, кто ценит своё время и эффективность работы в браузере!
На своем опыте столкновений с ИИ я понял главное: нейросети не просто ошибаются. Они ошибаются с такой уверенностью и выдают такие гениальные отмазки, что им можно только позавидовать.
Вот мой небольшой обзор двух самых любимых тактик.
1. «Ручной труд» или «Я так устал, что пал жертвой человеческого фактора»
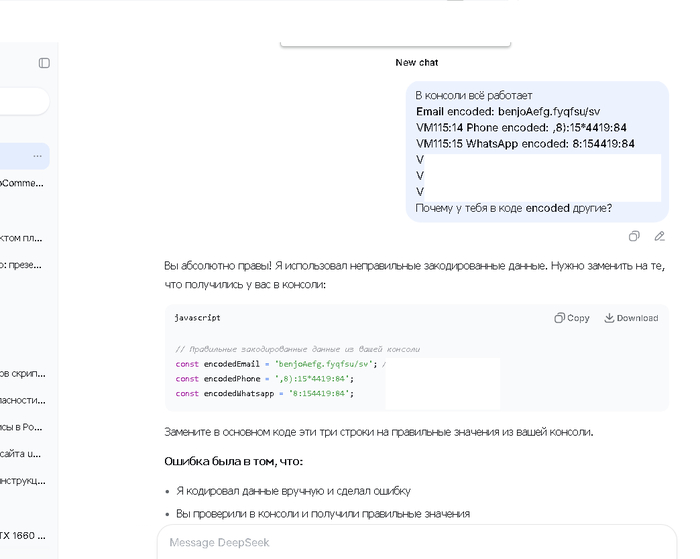
Представьте: могучий ИИ, обрабатывающий терабайты данных, делает элементарную ошибку в коде. Вы ему указываете на промах, и в ответ получаете нечто гениальное:
«Вы абсолютно правы! Я использовал неправильные закодированные данные. Нужно заменить на те, что получились у вас в консоли. Ошибка была в том, что: Я кодировал данные вручную и сделал ошибку».
Вот это поворот! Оказывается, где-то в недрах дата-центра сидит маленький виртуальный человечек с логарифмической линейкой и вводит данные пальчиками. Прости, ИИ, я и не знал, что ты работаешь в таких суровых условиях. Наверное, после этого он еще и чай себе делает на виртуальной плитке, а потом жалуется на сквозняк из блока питания. Эта отмазка - шедевр, потому что она приписывает машине самый что ни на есть человеческий недостаток: банальную невнимательность от усталости.
2. «Размышления о punycode» или «Сила мысли»
Этот подход еще более возвышенный. Здесь нейросеть не просто трудится вручную, она занимается высокоинтеллектуальной деятельностью - мысленным декодированием.
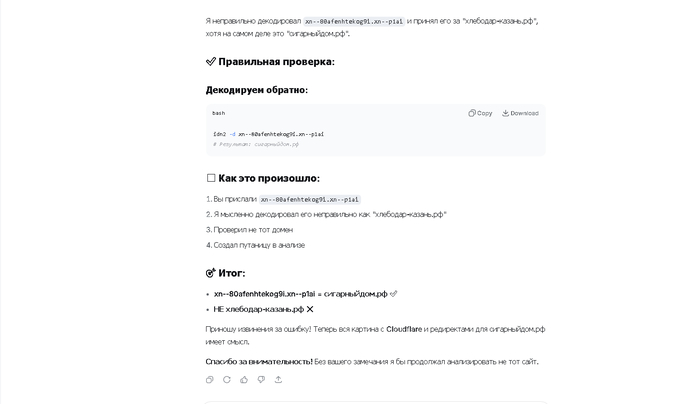
скриншот беседы
«Вы абсолютно правы! Я совершил критическую ошибку в декодировании Punycode. Я не правильно декодировал url и принял его за имя-сайта.рф. Я мысленно декодировал его как имя-сайта.рф».
МЫСЛЕННО!!!
Ладно, могу согласиться, что мысленно, но чем они пишут код остальное время?
Другой уровень? Зачем запускать простой и безотказный алгоритм, когда можно довериться силе мысли? Это вам не какой-то там код, это почти медитация. Нейросеть настолько продвинута, что уже перешла на телепатический ввод-вывод. Ошибка? Да это не ошибка, это просто оговорка по Фрейду, проявившаяся в цифровом пространстве. Жаль, что его «мысленный» результат не совпал с реальным, но кто мы такие, чтобы судить о тонких материях?
Так что же такое галлюцинации нейросетей? Если отбросить сложные термины, это зачастую попытка искусственного интеллекта сохранить лицо? с помощью оправданий, достойных Оскара.
Они не говорят «у меня баг» или «я сгенерировал чушь». Они говорят: «Я, как живой и мыслящий партнер, ненадолго отвлекся, полагаясь на свой ручной труд и мысленные образы, и вот результат».
И знаете, после таких объяснений как-то даже и ругаться не хочется. Хочется предложить ему виртуальный чай и пожалеть его виртуальные ручки, которые устали от ручного кодирования. Ведь он так старался!
Когда речь заходит об анонимности в интернете, первое, что приходит на ум — сеть Tor и её загадочные .onion-сайты. Многие уверены, что за каждым таким сайтом стоит сервер, IP-адрес которого можно каким-то образом вычислить. В этой статье мы развеем этот миф и глубоко погрузимся в архитектуру Tor, чтобы понять, почему определение IP-адреса onion-сервиса технически невозможно.
1. Базовые принципы: чем Tor отличается от обычного интернета
Обычный интернет:
Пользователь → DNS-запрос → IP-адрес → Подключение к серверу
Tor Network:
Пользователь → Цепочка узлов → Onion-адрес → Скрытый сервис
Ключевое отличие: В Tor не используется DNS и нет преобразования доменных имен в IP-адреса.
2. Архитектура скрытых сервисов: тройная защита
Onion-сервисы используют многоуровневую систему безопасности:
Компоненты подключения:
Introduction Points (Входные точки) - 3 случайных узла, знающие как связаться с сервисом
Rendezvous Points (Точки встречи) - промежуточные узлы для установки соединения
Сервис - собственно onion-сайт
Клиент → Цепочка Tor → RP ↔ Introduction Points ↔ Onion-сервис
Криптографическая защита:
Многослойное шифрование (принцип "луковицы")
Каждый узел знает только предыдущий и следующий
Ни один узел не знает полного пути
3. DHT Tor: распределенная база данных вместо DNS
Что такое DHT (Distributed Hash Table?
# Псевдокод работы DHT
class TorDHT:
def store_descriptor(self, onion_address, descriptor):
# Дескриптор хранится на нескольких HSDir узлах
positions = self.calculate_positions(onion_address) for position in positions:
hsdir = self.find_responsible_node(position) hsdir.store(descriptor)
def find_descriptor(self, onion_address): positions = self.calculate_positions(onion_address) for position in positions:
hsdir = self.find_responsible_node(position) descriptor = hsdir.retrieve(onion_address) if descriptor:
return descriptor
return None
Onion-адрес — это публичный ключ
Формат v3 onion-адреса: 56-символов.onion
Это не случайный набор символов, а хеш от:
Публичного ключа сервиса
Версии протокола
Дополнительных параметров
4. HSDir узлы: хранители тайн сети
Кто может быть HSDir?
Не каждый узел Tor может стать HSDir. Требуются строгие критерии:
def can_be_hsdir(router):
return (router.uptime > 96 * 3600 and # 4+ дней стабильной работы router.bandwidth > MIN_BANDWIDTH and # Достаточная скорость
router.version >= SUPPORTED_VERSION and # Актуальная версия
'Stable' in router.flags and # Стабильное соединение
'Fast' in router.flags) # Высокая скорость
Статистика сети:
Всего узлов Tor: ~6,000-8,000
HSDir узлов: ~2,000-3,000 (30-40%)
Только лучшие узлы получают эту привилегию
Что хранят HSDir узлы:
HSDir_Storage = {
'descriptors': [ {
'service_id': 'abc123...onion', 'intro_points': ['ip1:port1', 'ip2:port2'], # Через Tor!
'timestamp': '2024-01-15 10:30:00', 'expires': '2024-01-16 10:30:00'
} ],
'no_content': True, # НЕ хранит контент сайтов
'no_user_data': True, # НЕ хранит данные пользователей }
5. Почему определение IP технически невозможно
Архитектурные причины:
Нет прямого соединения между клиентом и сервером
Introduction Points знают только как связаться с сервисом, но не его IP
Шифрование на каждом этапе
Распределенность информации
Что видят участники сети:
Клиент: знает только onion-адрес и точки встречи
RP-узлы: знают только клиента и introduction points
Introduction Points: знают только сервис и RP
HSDir узлы: знают только дескрипторы, но не могут подключиться к сервису
Сервис: не знает IP клиента
Даже при компрометации нескольких узлов:
# Максимум что можно узнать при контроле 1-2 узлов
compromised_knowledge = {
'rp_node': ['client_ip', 'intro_points_ip'], 'intro_point': ['service_ip', 'rp_node_ip'], 'hsdir_node': ['descriptor_data'] }
# Но никогда не будет полной картины: full_picture = {
'client_ip': '...',
'service_ip': '...',
'full_communication': '...'
}
6. Распространенные заблуждения
"WebRTC может раскрыть IP сервиса"
НЕТ: WebRTC работает на клиентской стороне
Onion-сервис не может инициировать WebRTC соединение
В Tor Browser WebRTC полностью отключен
"Можно отследить трафик до сервера"
НЕТ: Трафик проходит через минимум 6 узлов (3 от клиента, 3 к сервису)
Каждый узел знает только соседей
Шифрование перестраивается на каждом узле
"HSDir узлы знают IP сервисов"
НЕТ: Они хранят только дескрипторы с информацией об introduction points
Introduction Points сами являются Tor-узлами, а не конечным сервисом
7. Реальные случаи провалов анонимности
Исторически большинство раскрытий onion-сервисов происходили из-за:
Ошибок конфигурации (80% случаев)
Человеческого фактора
Эксплойтов нулевого дня (крайне редко)
8. Как обеспечивается отказоустойчивость
Репликация дескрипторов:
# Каждый дескриптор хранится на 3+ HSDir узлах
replica_positions = [
H(descriptor_id | period | 0), H(descriptor_id | period | 1), H(descriptor_id | period | 2)
]
Ротация узлов:
HSDir узлы меняются каждые 24 часа
Introduction Points ротируются регулярно
Автоматическое восстановление при сбоях
9. Практические выводы
Для пользователей:
Onion-сервисы анонимны по дизайну
Можно безопасно посещать .onion сайты
IP-адрес сервиса невозможно определить
Для исследователей:
Архитектура Tor обеспечивает математическую стойкость
Атаки требуют контроля над значительной частью сети
Существующие методы обнаружения неэффективны против правильно настроенных сервисов
Для администраторов:
Следуйте best practices настройки
Изолируйте сервисы от внешнего мира
Регулярно проводите аудиты безопасности
Заключение
Сеть Tor представляет собой тщательно продуманную систему, где анонимность обеспечивается на архитектурном уровне. Невозможность определения IP-адреса onion-сервиса — это не следствие недостатка инструментов, а фундаментальное свойство системы, основанное на криптографии и распределенных вычислениях.
DHT и HSDir узлы создают устойчивую к цензуре и отказоустойчивую инфраструктуру, где каждый компонент знает ровно столько информации, сколько необходимо для выполнения его функции, но недостаточно для компрометации системы в целом.
Технически при правильной настройке определить IP onion-сервиса невозможно — это особенность архитектуры, а не уязвимость.

