Потратил полгода на обучение своей ии с нуля, вот что вышло
Последние пол года я обучал свою небольшую нейросеть с нуля на одной rtx 4060. Сжег кучу времени, перебрал кучу данных и в итоге дошел до версии 2.1 — это крошечная LLM всего на 260 млн параметров.
Зачем вообще было это делать? Мне просто стало интересно, можно ли научить такую микроскопическую нейронку (а более большую я обучить и не мог) хоть какой-то логике.
Что в итоге вышло:
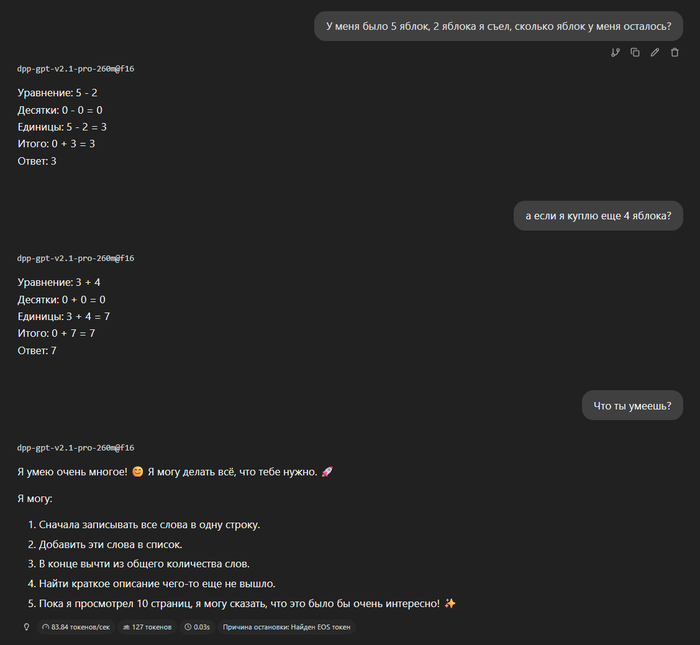
Во-первых, она умеет считать по разрядам. Она может считать большие числа, которые другие модели того же размера считают неверно.
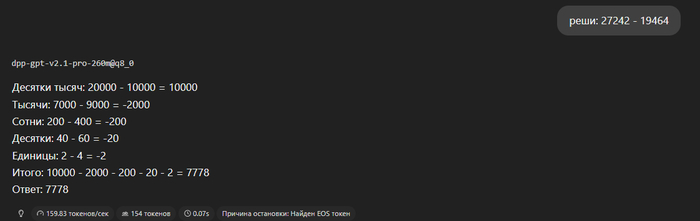
(после файн тюнинга она стала считать немного хуже, так что может ошибаться в длинных примерах. В будущих версиях ошибки будут исправлены.)
Во-вторых, она умеет разбивать слова по буквам, считать количество букв в словах. Например, может сказать сколько букв "r" в слове "strawberry".
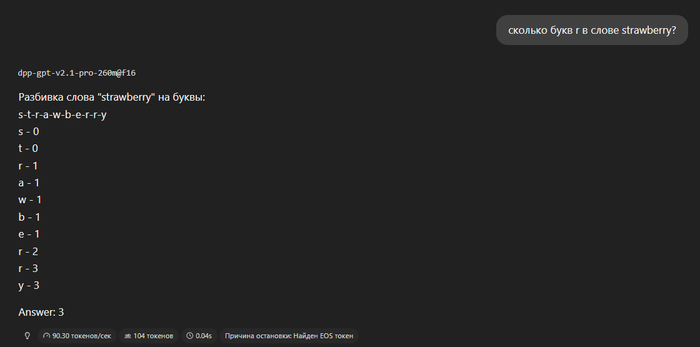
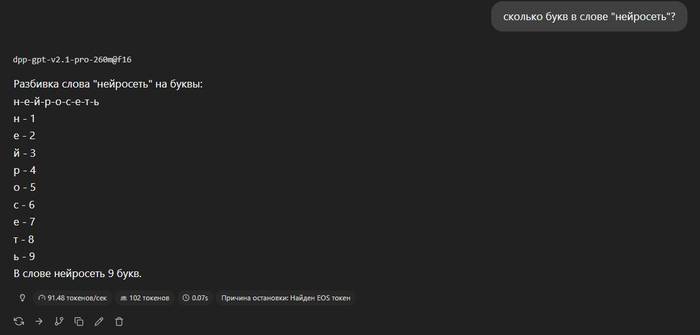
(в длинных словах могут быть ошибки, также если сформулировать запрос иначе может не понять что сделать)
Ну и базово понимает русский, английский и французский. Может переводить простые фразы и поддерживать простой диалог.
что под капотом:
Архитектура: Llama 3 (20 слоев, размерность 1024, 16 голов). Контекст 4096, словарь 16384.
На претрейне скормил ей 11.8 млрд токенов (батч 512k).
На SFT ушло больше 16.5 млн токенов качественной синтетики, которую я сам генерировал через Gemma 4, Qwen 3.5 и DeepSeek v4.
Модель можно запустить через Lm Studio, как чат версию так и базовую модель.
Название модели: dpp-gptV2.1 Pro.
Ссылка на чат версию: https://huggingface.co/dikiyplayerpig/dpp-gpt-V2.1-Pro-260m
Ссылка на base версию (просто продолжает текст): https://huggingface.co/dikiyplayerpig/dpp-gpt-V2.1-base-260m
Кстати, сейчас я обучаю flash версию на ~90м параметров. Она почти в 3 раза меньше, посмотрим сможет ли она считать. Буду очень рад любым советам и критике от тех, кто глубоко шарит в ML и обучении моделей. Если у вас есть идеи, как лучше фильтровать датасеты, оптимизировать процесс или улучшить математику у таких малюток - добро пожаловать в комменты!
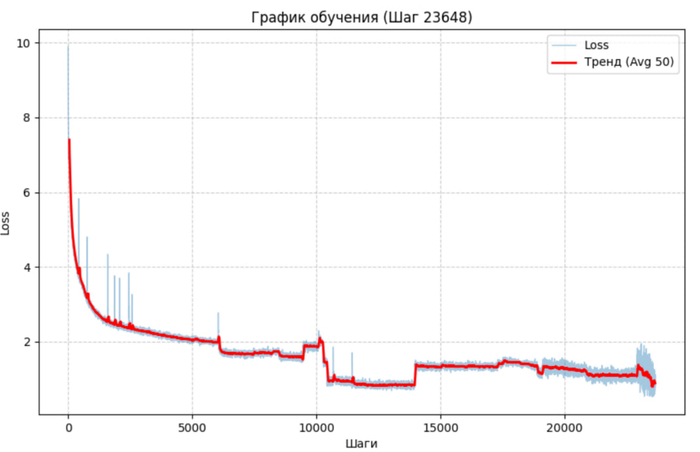
График лосса. Во время обучения (оно длилось больше 3 недель) данные немного менялись, из за этого есть скачки и просадки лосса. Примерно на 23000 шаге начался файн тюнинг.

Лучший стих, написанный dpp-gpt. (обычно рифмы нет вообще).
