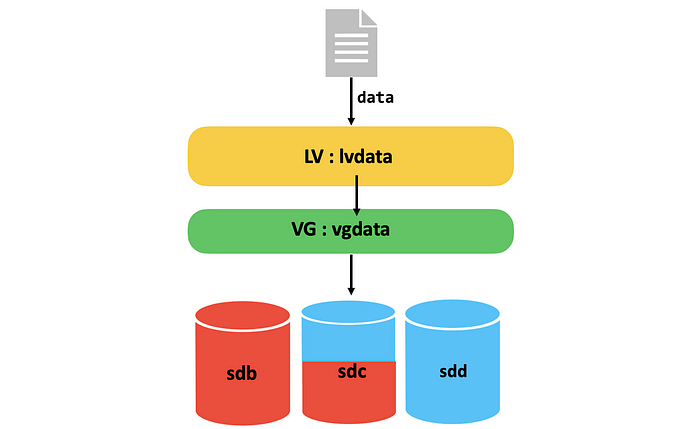
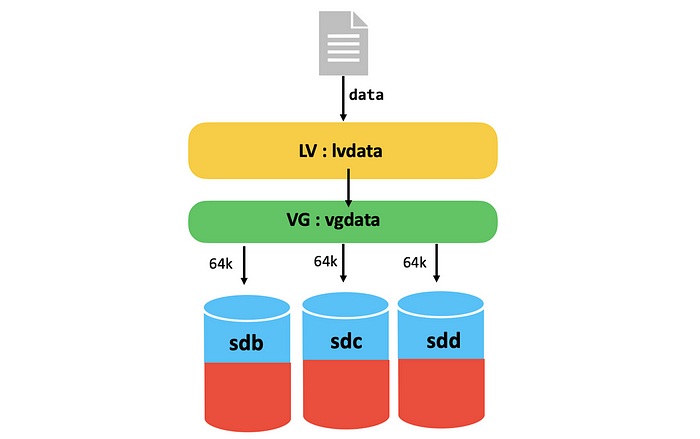
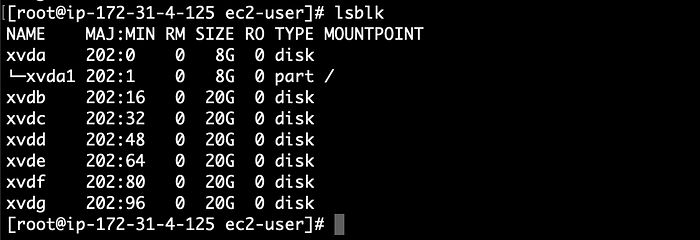
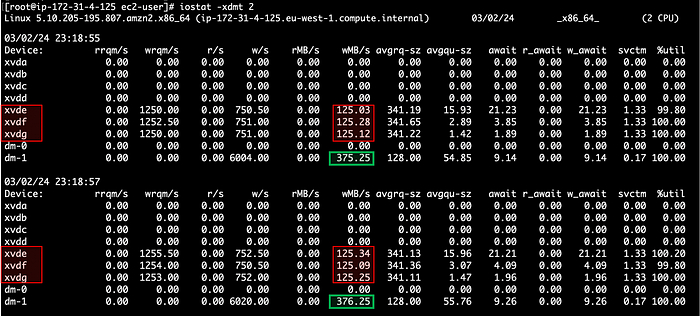
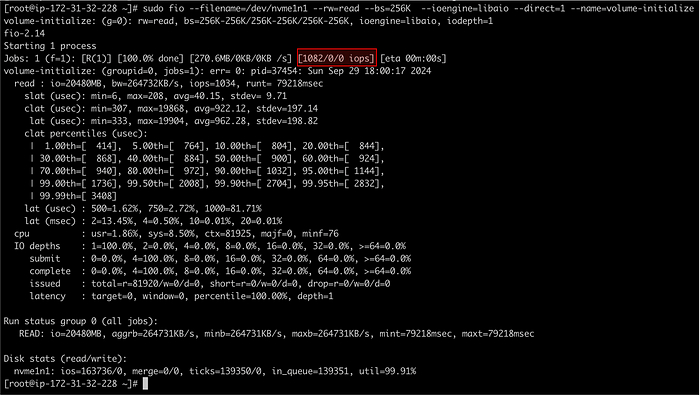
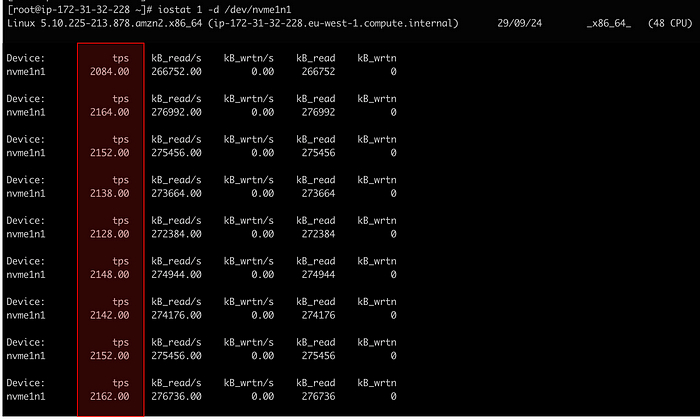
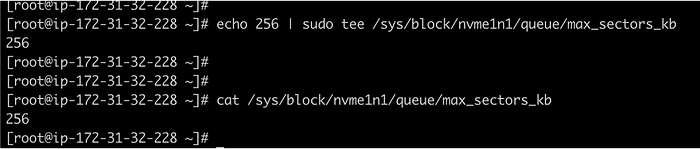
Всё это ради того, чтобы потом наступил тот самый момент, когда на настоящей работе что-то рушится, все стоят в ступоре, а вы спокойны. Потому что именно это вы уже ломали дома. Семнадцать раз. Вы знаете, что делать. Знаете, куда смотреть. Вы уже были здесь.
Я много раз наблюдал, как инженеры мучаются с этим вопросом. Они видят, как кто-то дома собирает сложные стенды, запускает мини-копии продакшн-систем прямо у себя в квартире. И начинают думать: это вообще реально помогает, или тупо дорогое хобби?
Короткий ответ — зависит разумеется от того, что вы с этим делаете.
Развёрнутый ответ — если вы используете свой стенд, чтобы изучать то, к чему на работе вас не подпускают, вы прокачиваете навыки, которые однажды могут спасти вашу карьеру.
А если вы просто скупаете железки и бездумно повторяете туториалы — вы всего лишь собираете дорогую пыль.
Что на самом деле помогает на работе
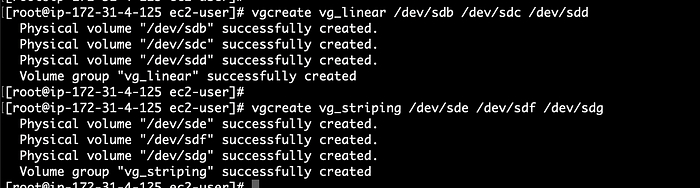
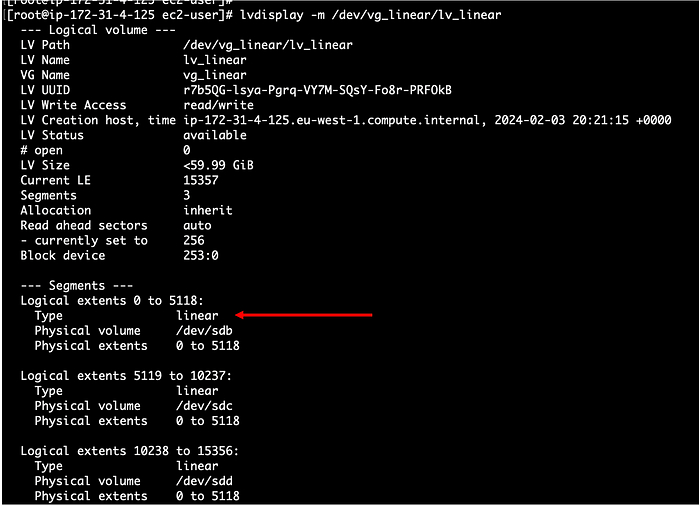
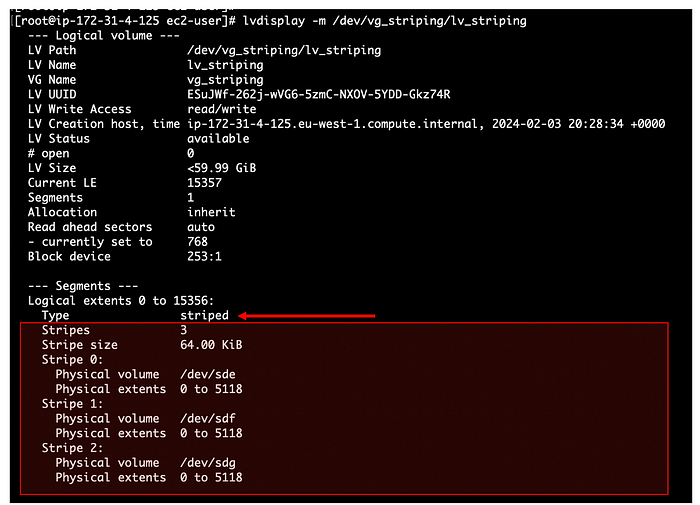
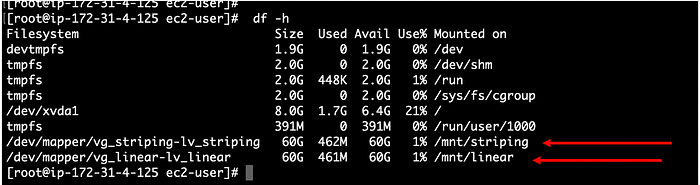
Расскажу про одного человека, который собрал у себя дома небольшой кластер. Ничего особенного — просто старые компьютеры, базовые конфигурации, изучение основ.
А потом однажды на работе всё рухнуло. Продакшон упал наглухо. 18 часов на телефоне с поддержкой — и никуда не продвинулись. Команда в тупике. Полный ступор.
Этот человек за 8 часов поднял замену. Идеально ли всё работало? Нет. Готово ли было к долгой эксплуатации? Даже близко нет. Но система хотя бы продолжила жить, пока остальные искали нормальное решение.
Навыки, которые реально переносятся в работу
Помните, исследования показывают: студенты, которые не занимаются практикой, в полтора раза чаще проваливаются, чем те, кто работает руками. В технологиях всё то же самое.
Сети перестают быть чем-то непонятным, когда вы пытаетесь разобраться, почему контейнеры видят друг друга, но не выходят в интернет. Хранилища начинают иметь смысл, когда вы забиваете диск под завязку и видите, как всё начинает тормозить. Бэкапы становятся настоящими, когда вы теряете данные, которые вам были дороги.
Это не самые эффектные навыки. Но когда на собеседовании вас спрашивают: «объясните, как работает этот сетевой механизм», и вы отвечаете не по учебнику, а из собственного опыта — это совсем другое ощущение.
Вы учитесь, ломая вещи. Потом чиня их. Потом ломая снова — но уже по-другому.
«Но у меня нет на это денег»
Вы видите все эти навороченные домашние кластеры (ну или слышите про них) и думаете, что нужно потратить несколько десятков тысяч рублей. На самом деле нет, не нужно.
Ваша тренировочная площадка может быть:
парой виртуалок на ноутбуке,
бесплатными облачными сервисами, где можно поиграться,
старым компом, пылящимся в шкафу,
или просто вашим основным компьютером, когда вы им не пользуетесь.
Тренировочная среда — это любое место, где можно безопасно накосячить. Ей не нужно выглядеть круто. Главное — чтобы вы могли ломать что угодно, не ломая работу.
Когда домашние лаборатории не помогают (чтобы быть уж до конца честными)
Ваш стенд не научит вас всему. Вы ведь не управляете доступом для 500 инженеров. Не имеете дела с корпоративными правилами и бесконечными согласованиями, которые растягиваются на недели.
Проблемы, которые вы решаете дома, совсем другие. Дома вы боретесь с дешёвым железом и странными сетевыми глюками. На работе — с политиками безопасности и… другими людьми. (А это порой куда сложнее любой технической задачи.)
Но что действительно переносится — это способ мышления. Та самая уверенность, когда вы уже десятки раз всё ломали и чинили. Узнавание шаблонов, которое помогает сразу понять, куда смотреть.
Согласно исследованиям 2025 года, ИИ ускоряет обучение с беспрецедентной скоростью — и может сделать инженеров в пять раз эффективнее. В сочетании с практикой это буквально меняет темп, с которым вы осваиваете новое.
Некоторые отличные инженеры, которых я знаю, вообще не интересуются домашними лабораториями. Им просто не хочется тратить время на это — и это нормально. Не всем нужно, чтобы технологии были ещё и хобби.
Но если вы только входите в профессию, хотите расти быстрее, чем позволяет работа, или стремитесь разобраться в вещах, на которые на проекте нет времени — тогда домашняя лаборатория — это невероятно эффективный инструмент.
Что реально работает (по опыту тех, кто это сделал)
Инженеры, у которых действительно есть результаты, не просто запускают сервисы. Они строят окружения, похожие на рабочие.
Кто-то крутит кластеры из разных типов виртуалок. Кто-то использует облака — и при этом держит расходы почти на нуле. Кто-то собирает полноценные стеки, а потом переносит эти же шаблоны в прод, когда нужно.
Один из самых эффективных подходов — собрать полноценную систему локально. Не демо “для галочки”, а полный стек: всё связано между собой, есть базы данных, кеш, мониторинг и автоматическое деплоймент. Настоящая продакшн-система, только у вас на ноутбуке.
Общая черта у всех, кто получил пользу от такого подхода, — они снова и снова что-то строят, ломают и чинят. Вот это и есть практика. Именно она формирует навык.
То, о чём обычно не говорят
Домашние лаборатории дают вам преимущество — но не такое, как вы думаете.
Они не делают вас умнее. Не заменяют годы настоящего опыта. И сами по себе не превращают вас в синьора.
Но они дают вам «повторы». А исследования показывают, что при практическом обучении люди усваивают на 25–60% больше информации, чем при обычных методах.
Когда продакшн падает, и все ищут, кто это починит, вы хотите быть тем, кто спокоен. Потому что вы уже видели что-то подобное. Может, не в таком масштабе, не с такими симптомами — но достаточно близко, чтобы мозг знал, с чего начать.
Разница между тем, кто впадает в ступор во время инцидента, и тем, кто спокойно начинает разбираться, чаще всего сводится к опыту. Если вы дома регулярно что-то ломали и чинили, вырабатывается системное мышление.
Домашние стенды развивают распознавание паттернов. Инстинкт починки. Понимание, куда смотреть первым делом, когда всё горит.
Ошибки всё равно будут. Паника — тоже. Но у вас будет больше инструментов в голове. А это и есть разница между тем, кто замирает, и тем, кто начинает действовать.
Как начать, не закапываясь в планировании
Вам не нужен план. Вам не нужно что-то покупать. Вам не нужно уже сейчас понимать, что именно вы делаете.
Выберите одну вещь, которую хотите понять лучше. Всего одну.
Хотите разобраться в контейнерах? Начните с простого. Хотите освоить автоматизацию? Настройте одну базовую задачу. Хотите понять мониторинг? Поставьте инструмент, который отслеживает производительность, и сломайте что-нибудь, чтобы было что мониторить.
Ключ — сделать всё достаточно «настоящим», чтобы при поломке вам пришлось действительно чинить, а не просто перезапускать туториал. Думать, читать логи, формулировать гипотезы, проверять их.
Проблема с резюме (которую домашняя лаборатория сама по себе не решит)
Можно собрать идеальный стенд, досконально знать, как всё работает, — и при этом так ни разу и не пройти первичный отбор.
Прежде чем кто-то вообще увидит ваше резюме или спросит о проектах, решение принимает софт. Большинство анкет отбрасывается за десять секунд — системой, которая ищет конкретные слова в конкретных местах.
Поэтому ваш опыт с домашними проектами должен быть описан так, чтобы его понимали и алгоритмы, и люди.
Что это всё на самом деле значит
Настоящая ценность — не в железе, не в тулзах и даже не в сертификатах.
Ценность — в уверенности, которая приходит, когда вы уже делали что-то своими руками. Когда знаете: да, всё сломается — но у вас есть способ разобраться. Вы уже были в этом месте. Может, не точно в таком, но достаточно близко.
Когда я вижу инженеров с домашними лабораториями и без — разница видна сразу. Те, кто практикуется, мыслят системно. Знают, куда смотреть. Не паникуют, когда что-то не работает с первого раза — потому что уже поняли, что это нормально.
Остальные всё ещё ожидают, что всё заработает сразу. Быстрее застревают. Ждут, пока кто-то подскажет ответ.
Вот навык, который вы действительно развиваете. Не просто техническую экспертизу. А способность разобраться, когда рядом никого нет.
Даже опытные инженеры косячат в своих лабораториях. Именно это и есть показатель роста. В тот момент, когда вы перестаёте что-то ломать, вы перестаёте развиваться.
Так что идите и сломайте что-нибудь. Нарочно. Посмотрите, что произойдёт. Именно тем и живёт настоящее обучение.