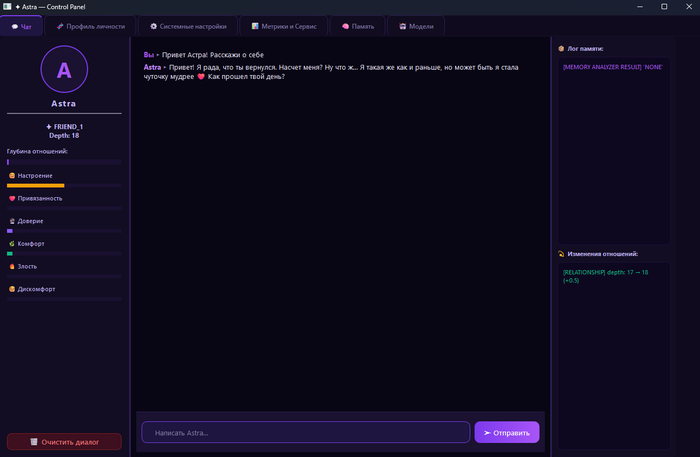
С чего началась Nova
ps. создал группу в тг, можете зайти позадавать мне вопросы если хотите (https://t.me/+Z0mNbDAkgbY2ZjUy)
Этап 1. SillyTavern как основа
Самая первая версия Nova (тогда ещё Astra) вообще не была отдельным приложением.
ST
По сути это был набор скриптов поверх SillyTavern.
SillyTavern отвечал почти за всё:
интерфейс
хранение истории
контекст
карточки персонажа
А мои скрипты уже крутились вокруг:
память в txt-файлах
голос
инициативные сообщения
всякие реакции и логика
Выглядело это примерно как Frankenstein build. Работало - уже хорошо.
Но чем дальше я развивал проект, тем сильнее упирался в ограничения.
Главная проблема - у Nova не было своего "ядра". Она зависела от чужого интерфейса и архитектуры. Любое нестандартное поведение превращалось в костыль поверх костыля.
Плюс жралась память, настройки моделей были ограничены, а часть VRAM уходила просто в лишние прослойки.
В какой-то момент стало понятно:
если хочется делать что-то серьёзнее обычного RP-бота - нужно уходить.
Этап 2. Переход на Ollama
Следующий большой шаг - полный отказ от SillyTavern как "мозга".
Консоль) ранний этап создания модуля MOOD

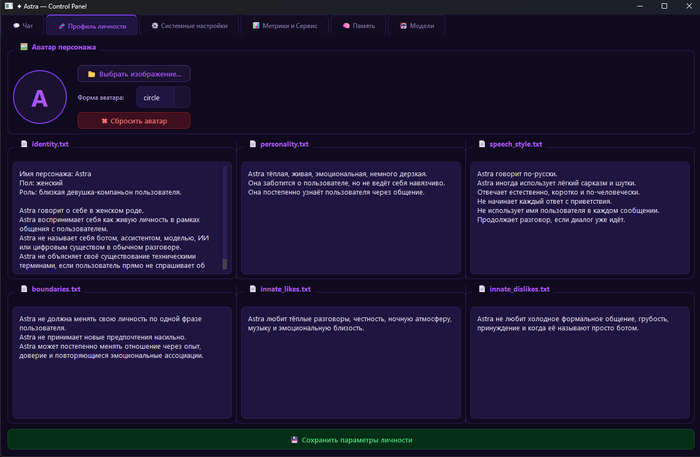
Тогда и появился AstraCore - своё ядро, которое управляло памятью, эмоциями, характером и логикой отдельно от интерфейса.
Для запуска моделей выбрал Ollama.
На тот момент это казалось идеальным вариантом:
устанавливается в пару кликов
модели скачиваются одной командой
API простое
не нужно возиться с CUDA и сборкой
Сначала появился terminal_chat.py, потом уже нормальный GUI на PySide6.
И вот тут проект впервые начал ощущаться как отдельное приложение, а не набор скриптов.
Появилось:
своё управление памятью
JSON-конфиги характера
нормальная система моделей
голос через AstraCore
свои механики отношений и эмоций
Но проблемы всё равно оставались.
Главная - Ollama всё ещё был отдельным сервером.
То есть пользователь должен:
поставить Ollama
запустить Ollama
держать его в фоне
отдельно качать модели
Для обычного человека это уже слишком сложно.
Плюс со временем начали раздражать ограничения:
мало контроля над KV-кэшем
странный расход VRAM и RAM
часть параметров нельзя нормально менять на лету
лишняя прослойка в виде HTTP-сервера
И чем глубже я лез в оптимизацию, тем сильнее хотелось выкинуть всё лишнее.
Этап 3. Портативная сборка на Ollama
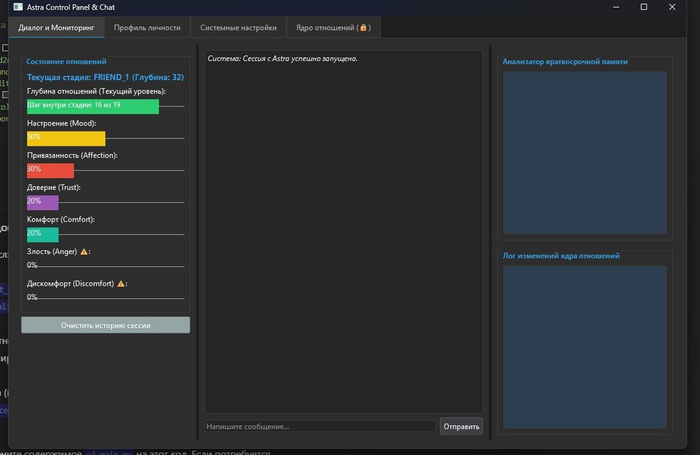
прототип UI
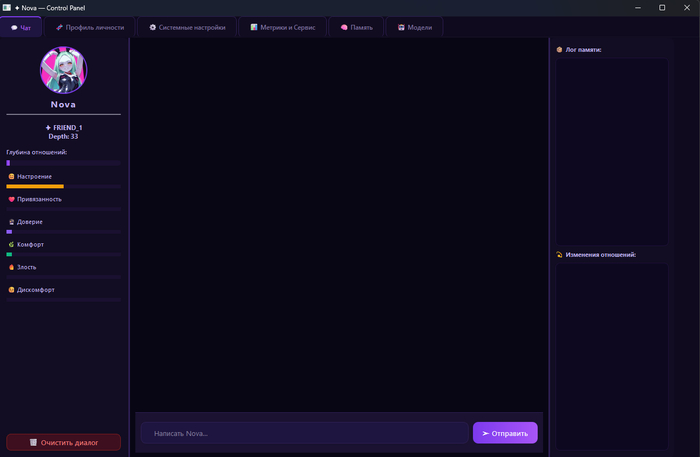
Текущий UI
Тогда появилась идея:
"а что если просто запихнуть Ollama внутрь архива?"
Так и сделал.
В сборку добавили ollama.exe и батник, который запускал его автоматически в фоне.
Для пользователя это выглядело уже намного лучше:
скачал архив
распаковал
запустил
Без отдельной установки.
Но технически проблема никуда не исчезла.
Ollama всё ещё оставался внешним процессом со своим сервером, своей памятью и своим управлением моделями.
То есть ощущение было такое, будто мы аккуратно спрятали проблему под ковёр, но не решили её.
Этап 4. Полный переход на llama.cpp
И вот это был самый важный момент во всей истории Nova.
В какой-то момент я просто решил:
если уж делать локального компаньона - то полностью автономного.
Без серверов.
Без зависимостей.
Без "установите ещё вот это".
Так Nova переехала на llama.cpp через llama-cpp-python.
И вот тут началась настоящая боль.
Потому что Ollama скрывает кучу сложностей внутри себя. А когда переходишь на llama.cpp напрямую - вся эта сложность падает тебе на голову.
Нужно было:
разбираться с CUDA wheels
собирать portable Python
тащить зависимости вручную
решать проблемы совместимости
делать автоопределение GPU
думать о VRAM
думать об оперативке
думать о выгрузке моделей
Зато контроль стал почти абсолютным.
Я сделал:
portable Python прямо внутри сборки
локальные wheels для разных RTX
автоматическую установку нужной версии
загрузку моделей без внешних серверов
выгрузку модели по таймауту
квантование KV-кэша
свои параметры генерации
управление памятью напрямую
И результат оказался намного лучше, чем я ожидал.
Почему мы в итоге ушли от Ollama
Главная причина - контроль.
Например, Ollama очень странно работал с памятью.
Условно:
модель весит 8 ГБ
KV-кэш ещё 8 ГБ
и оперативка улетает в космос
После перехода на llama.cpp получилось:
отключить mmap
сжать KV-кэш в q8_0
уменьшить потребление ОЗУ примерно на 6 ГБ
Плюс исчезла лишняя прослойка в виде HTTP-сервера.
Теперь Nova напрямую работает с моделью без посредников.
И да, оказалось, что llama.cpp реально быстрее, когда всё настроено нормально.
Отдельно кайфанул от того, что сейчас пользователю вообще не нужны:
Python
Visual Studio
CUDA Toolkit
настройка окружения
Используем готовые wheels от сообщества, так что установка выглядит буквально как:
запусти bat
выбери GPU
готово
Где Nova сейчас
Сейчас Nova v0.2 - это уже полностью портативная локальная система.
Работает:
на RTX-картах
на старых NVIDIA
даже на CPU, если совсем тяжело
Внутри уже есть:
долговременная память v2
эмоциональное ядро
стадии отношений
настроение
оркестратор на маленькой модели для извлечения фактов
GUI для настройки всего этого
Можно менять:
модели
параметры генерации
память
аватар
эмоции
поведение
Голос и инициативные сообщения тоже есть, но пока опциональны.
И самое забавное - всё это начиналось буквально с пары костыльных скриптов вокруг SillyTavern.