AI в контент-маркетинге - как не получить одинаковые картинки, как у всех

Представьте сцену. Маркетолог листает Instagram* (или ВК, или просто увидел рекламу) конкурента и внезапно удивляется. Картинки - почти те же. Та же модель с кофе у окна. Тот же мягкий боке. Пастельные тона. Оба использовали AI. Оба были уверены, что делают что-то своё.
Это не единичная история, а то, что происходит прямо сейчас в лентах миллионов пользователей - и большинство маркетологов пока не понимает (или прекрасно понимают, но не хотят с этим что-то делать), почему.
Ежедневно генерируется более 34 миллионов AI-изображений. 62% маркетологов используют генеративный AI для визуала. Маркетинг и реклама занимают больше 36% всего рынка AI-инструментов для изображений. Инструментов много. Людей, которые умеют ими пользоваться так, чтобы не выглядеть как все, мало.
Почему нейросеть рисует для всех одно и то же
Начнем с механики, потому что без неё всё остальное - просто советы в воздух.
Midjourney, GPT Image 2, Nano Banana 2 от Google, Алиса AI от Яндекса, Кандинский от Сбера - каждый из этих инструментов обучен на гигантских массивах изображений из интернета. Midjourney занимает 26,8% мирового рынка, GPT Image 2 (который в апреле 2026 года окончательно заменил DALL-E 3) держит 24,4%. Больше половины всего AI-визуала в мире генерируют две модели, обученные примерно на одних данных.
Когда пишешь "красивая женщина с кофе в уютном кафе", модель выдает статистически наиболее вероятный результат для этого набора слов. Не творческий. Вероятный. То, что встречалось чаще всего в обучающем датасете и получало больше всего положительных оценок при RLHF-дообучении. Именно поэтому у Midjourney есть легко узнаваемая эстетика - гиперреалистичная, с характерным светом и глубиной. Профессионалы опознают её с первого взгляда. И если вы умеете её опознавать - ваша аудитория тоже.
Но это только половина проблемы. Вторая - сами маркетологи. Подборки "топ-100 промтов для маркетинга" расходятся в Telegram-каналах тысячами репостов. Все используют одни стартовые шаблоны. Результат предсказуем. Исследователи уже назвали это AI-гомогенизацией - когда массовое использование одних систем приводит к схождению результатов. Когда миллионы команд обращаются к одним моделям с похожими запросами, они получают одни картинки.

Есть еще один небольшооооой моментик, Meta*, TikTok и Google в обновлениях алгоритмов 2026 года тихо понизили ранжирование очевидного AI-контента в рекламных кабинетах. Не запретили. Именно тихо. Агентства это заметили, данные подтвердили. Пока маркетологи радуются скорости генерации, платформы уже начали штрафовать за отсутствие оригинальности.
Визуальный язык против визуального настроения
Здесь важно разобраться с одной путаницей, которая дорого обходится большинству брендов.
Стиль и визуальный язык - не одно и то же. Стиль - это настроение. "Мы хотим выглядеть тепло и по-домашнему". "Нам нужно что-то минималистичное". Это описание ощущения. Нейросети с ощущениями работают плохо - они не чувствуют, они вычисляют. Визуальный язык - это система. Конкретные параметры, которые отличают ваши изображения от чужих даже без логотипа в углу.
Разница примерно такая же, как между "мне нужен сайт красивый" и техническим заданием на 40 страниц.
Визуальный язык - это несколько слоев одновременно. Цветовая система - не "пастельные тона", а конкретные HEX-коды или хотя бы описание диапазона. Тип композиции - центральная, правило третей, намеренная асимметрия. Характер персонажей - возраст, внешность, эмоциональное состояние, что они делают руками. Угол съёмки. Фактуры. И - это важно - что никогда не появляется в кадре. Последнее большинство брендов вообще не формулирует, хотя именно оно часто и задает характер.
Исследование Ассоциации директоров по маркетингу и red_mad_robot показало: 93% российских компаний уже используют GenAI в работе, но лишь треть делает это системно. Оставшиеся две трети работают примерно так - открыли инструмент, написали промт, получили что-то приемлемое, опубликовали. Без системы, без воспроизводимости. Каждый раз как первый раз.
Нейросеть заполняет пустоту тем, что статистически наиболее вероятно. А наиболее вероятное - это среднее по больнице.
Референсы - это не "сделай похоже"
Когда говорят "используйте референсы", обычно имеют в виду: найдите красивую картинку и попросите AI сделать что-то похожее. Это работает плохо, и вот почему.
Прямое копирование референса - это подражание. Если ваш конкурент нашёл тот же референс на Pinterest (а он скорее всего нашёл, потому что Pinterest у всех один), вы снова в той же точке. К тому же диффузионные модели не "смотрят" на референс как человек - они переводят его описание в вероятностное пространство и генерируют оттуда. Описание - ключевое слово здесь.
Референсы работают иначе. Не как образец для копирования, а как калибровка. Берёте изображения, которые попадают в ваш визуальный язык, и описываете, что именно в них работает. Не "красивый свет" - а "боковое освещение, источник справа, мягкие тени, нет резких бликов". Не "живые персонажи" - а "женщина 28-35 лет, смотрит в кадр без улыбки, взгляд прямой, одежда однотонная, нейтральные цвета". Это уже операциональное описание, с которым модель работает стабильно.
Хороший промт - это техническое задание для системы, которая одновременно работает как кастинг-директор, оператор и осветитель. Чем точнее ТЗ, тем меньше случайности. И тем больше шансов, что следующие двадцать изображений будут выглядеть как часть одной серии, а не случайная подборка из разных фотобанков.

Хранить референсы тоже нужно правильно. Папка с картинками - не система. Система - когда к каждому референсу прикреплено описание: что именно в нём работает, для каких задач подходит, что нужно адаптировать. Без этого через месяц откроешь папку и не вспомнишь, зачем туда положил вот это фото.
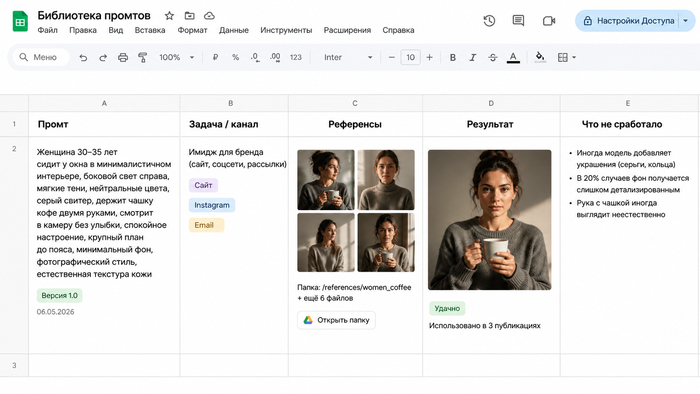
Библиотека промтов - это не таблица с текстами
Вот здесь большинство совершает следующую ошибку. Услышали про библиотеку промтов, создали Google-таблицу, накидали туда "рабочих" промтов из разных источников. Поставили галочку. Считают, что у них теперь система.
Нет.
Промт без контекста - мусор. Через три месяца откроешь этот документ и увидишь строчку "photorealistic woman, soft light, minimal background, 4K" без малейшего понимания: для какой кампании, какой результат получился, что не сработало, с какими референсами это использовалось. Это не библиотека, а свалка какая-то.
Рабочая библиотека устроена иначе. У каждой записи - минимум пять полей: сам промт, задача (для какого формата и канала), референсы, результат (скриншот или ссылка) и - самое важное - что не сработало и как исправили. Именно последнее поле превращает набор текстов в живой документ, который учится вместе с командой.
Отдельно про структуру самого промта. Профессиональный промт для маркетингового визуала состоит из нескольких слоёв: субъект (кто или что в кадре), среда (где, какой фон), свет (источник, характер, направление), стиль (референс на технику или художника), настроение, технические параметры (соотношение сторон, разрешение). Когда эта структура зафиксирована в библиотеке и воспроизводится стабильно - это уже не генерация, это производство.
GPT Image 2 - единственная image-модель OpenAI с мая 2026 года, когда DALL-E 2 и DALL-E 3 официально отключили. Одна из его особенностей - нативный режим рассуждения: модель сначала анализирует структуру будущего изображения, потом рисует. Сложные промты с несколькими ограничениями обрабатываются точнее. Но даже самая умная модель не компенсирует отсутствие структуры на вашей стороне.
Человек на этапе отбора - это не проверка
Вот ловушка, в которую попадают почти все. Команда выстраивает систему: визуальный язык описан, референсы собраны, библиотека заполнена. Генерируют пачку изображений. Потом кто-то быстро просматривает результаты и берёт "нормальные". Этот шаг воспринимается как финальный контроль качества - убрать явный брак, взять то, что "сойдёт".
Это не контроль качества. Это редакционное решение. И разница тут принципиальная.
AI генерирует вероятное. Вероятное - не то же самое, что правильное. Среди двадцати сгенерированных изображений почти всегда есть несколько технически безупречных, которые при этом не работают на бренд. Они красивые. Нейтральные. Ни о чём. Именно такие чаще всего проходят фильтр "сойдёт" - потому что в них нет явного брака, на который можно показать пальцем.
Человек на этапе отбора задаёт другой вопрос. Не "это изображение без ошибок?" - а "это изображение говорит то, что мы хотим сказать, тем голосом, которым мы хотим говорить?". Без этого вопроса библиотека промтов и референсы превращаются в красивую декорацию над той же самой проблемой.
Российские потребители это уже чувствуют, хотя и не формулируют в таких терминах. По данным LAMPA и Rambler&Co, опросивших 127 726 человек, самый частый признак AI-контента, который люди замечают, - слишком "стерильный" или идеальный визуал [9]. Именно стерильный. Не плохой. Просто ни о чём. 53% россиян говорят, что устали от потока такого "нейромусора" [10]. А 56% ухудшают отношение к бренду, если тот использует AI-контент, но не маркирует его.
Это не значит, что нужно прятать AI. Наоборот, нужно делать AI-контент, за который не стыдно.
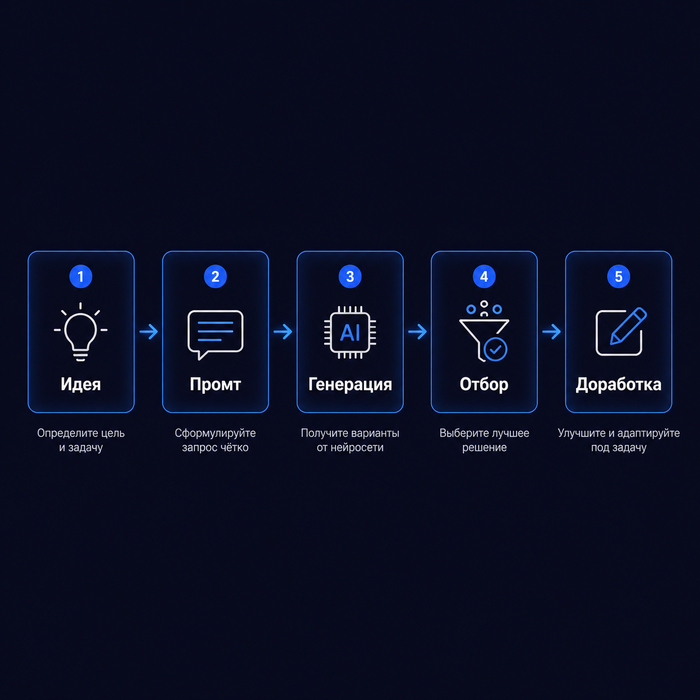
Четыре шага к визуальной системе
Что делать, если хочется выйти из визуальной серости. Без лишних слов.
Первый шаг - описать то, что уже работает. Возьмите двадцать изображений, которые точно работают на ваш бренд. Опишите их по параметрам: свет, композиция, персонажи, цвета, фактуры. Найдите повторяющиеся паттерны. Это черновик вашего визуального языка - не придуманный, а извлечённый из реальной практики. Это быстрее и честнее, чем пытаться описать бренд с чистого листа.
Второй шаг - стоп-лист. Что никогда не должно появляться в вашем визуале. Ограничения дают модели больше точности, чем пожелания. Обычно стоп-лист важнее, чем список того, что должно быть.
Третий шаг - минимальная библиотека из десяти-пятнадцати базовых промтов для типовых задач: пост в Instagram*, баннер, иллюстрация к статье, фоновое изображение. Каждый промт - с референсами и зафиксированным результатом. Не потолок, а фундамент.
Четвёртый шаг - конкретный человек, который принимает редакционные решения при отборе. Не "кто свободен", а тот, у кого есть полномочия сказать "нет, это не наше". Без этого первые три шага теряют смысл - система будет работать вхолостую.
По данным red_mad_robot и CMO Club Russia, ChatGPT и Midjourney - лидеры среди российских маркетологов с удовлетворённостью 88%. Хорошие инструменты. Но удовлетворённость инструментом не равна удовлетворённости результатом.
Те два бренда могли выглядеть по-разному
Возвращаемся к началу. Два бренда, одни инструменты, неразличимые картинки.
У одного из них не было системы. Не было визуального языка, зафиксированного операционально. Не было референсов с описаниями. Не было человека, который задаёт редакционный вопрос, а не просто фильтрует брак. Это единственное отличие - и оно решает всё.
Если бы у одного была эта система, его визуал выглядел бы иначе при тех же инструментах и похожих промтах. Потому что система - это не про то, какой инструмент открыть. Это про то, что вы в него вкладываете и как отбираете результат.
AI для визуала в 2026 году - это уже не преимущество. Это база, которая есть у всех. Преимущество - уметь пользоваться ею так, чтобы ваши картинки были узнаваемо вашими.
Что важно запомнить:
Визуальная гомогенизация - системная проблема, а не вопрос выбора инструмента. Midjourney и GPT Image 2 обучены на одних данных и выдают статистически вероятные результаты на похожие промты по своей сути.
Стиль - это ощущение, с которым AI работает плохо. Визуальный язык - система с конкретными параметрами: цвет, свет, композиция, персонажи, стоп-лист.
Референсы работают не как образец для копирования, а как операциональное описание того, что именно в изображении работает на бренд.
Библиотека промтов без контекста - свалка. Рабочая библиотека фиксирует задачу, референсы, результат и что не сработало.
Человек на этапе отбора принимает редакционное решение. Это творческая работа - и без неё любая система рассыпается.
*Meta, которая владеет Instagram и Facebook, признана в России экстремистской и запрещена.