


Нейроарт
15 постов
15 постов

17 постов

2 поста

4 поста

7 постов

11 постов

3 поста

4 поста
Книга с 75 промптами женщин отлежалась и вышла на Бусти, начал делать мужиков, первая часть с европеоидами. И вот в группу 60+ захотелось включить типаж стареющего рокера. Сначала алгоритмом, без ручного вмешательства, разложил на признаки Джаггера. Внезапно по голому тексту у GPT Image 2 на тестовом прогоне с минимальной детализацией получился… Джаггер.

Блин, подумал я. Как-то нехорошо получается. И начал работать руками. Получился колоритный дядька, в которого я запихнул густую окрошку из десятка знакомых мне лично, шапочно и с экрана старых рокеров. "Четыре волоса, но полметровых". Вайб поймал :)



Собака, кажется, двухголовая, но суть не в ней.

И еще на сегодня один симпатичный промпт. Сделал вот этого сурового английского дядьку. По-моему, хорош без меры. Попал под горячую руку, когда я тестировал алгоритм проработки атмосферности :)

photorealistic 71 year old British man with dignified elderly presence and calm reflective gaze, medium slender natural build, body mass index approximately 23.8, height approximately 176cm, weight approximately 73.7kg, shoulder width approximately 43cm, fair skin with cool neutral undertone, realistic elderly skin texture with visible pores and natural age softness, pronounced forehead wrinkles, deep crow's feet, moderate nasolabial folds, mild marionette lines, soft under-eye puffiness, slight redness around cheeks and nose, age spots near temples and cheeks, one small pale scar near right side of jaw, natural aging details, no artificial smoothing, no exaggerated features
long oval face with mature bone structure and softened lower face, face height approximately 19.9cm, face width approximately 15.6cm, high forehead with notable receded hairline, sparse grey eyebrows with coarse texture and uneven density, pale blue eyes medium set with hooded upper lids and visible lower-lid folds, eye length approximately 2.48cm, eye height approximately 0.75cm, straight long nose with defined bridge, slightly broader tip and visible texture, nasolabial angle approximately 91 degrees, medium-thin lips with relaxed line and natural age softness, upper lip thinner, philtrum approximately 1.56cm, softened jawline with rounded chin, short white-grey beard and mustache with natural uneven density
short white-grey hair, thinning across crown and temples, fine natural texture, realistic hairline, individual silver and pale strands visible, soft density on sides
medium slender elderly torso with natural mature proportions, chest approximately 100cm, waist approximately 90cm, hips approximately 98cm, lean ribcage, mild muscle softening with natural abdomen, relaxed shoulders, longer neck with visible age texture, arms with mature softness and mild skin laxity, proportional hands with visible knuckles, prominent veins and age spots, balanced leg proportions, dignified elderly silhouette without stylization
calm reflective facial expression, steady direct gaze, relaxed mouth with subtle natural downturn at corners, realistic facial asymmetry, dignified wise elderly presence, photorealistic human anatomy, physically accurate skin shading, natural subsurface scattering, realistic specular highlights, high detail
ВОТ ТУТ ИДЕТ АТМОСФЕРА. МОЖНО УБРАТЬ, ЧТОБЫ ОСТАВИТЬ ЧИСТО ДЯДЬКУ
cinematic photographic realism, refined editorial stillness, quiet visual tension, suspended living moment, elegant emotional restraint, intimate human presence, immersive realism, a sense of time gently held in place
balanced editorial composition with clear visual hierarchy, soft asymmetry, controlled negative space, clean neutral background, subtle foreground-middle-background separation, natural visual rhythm, relaxed yet deliberate structure, unobtrusive but precise compositional design
ТУТ СВЕТ
soft diffused natural lighting with gentle directional modeling, low-to-moderate contrast, delicate shadow density, smooth highlight transitions, light revealing skin texture and fabric softness with restraint, believable daylight-inspired illumination, refined tonal gradation
ЭФФЕКТЫ КАМЕРЫ И ОБЪЕКТИВА
photographic camera language, classic portrait perspective, shallow-to-moderate depth of field, soft focus falloff, tactile lens rendering, gentle optical smoothness, intimate observational distance, realistic dimensional presence, clean editorial optical character
ЭФФЕКТЫ ПЛЕНКИ И ФАКТУРЫ
refined analog-inspired texture, fine organic grain, smooth highlight roll-off, subtle halation around bright areas, soft diffusion, rich readable shadow detail, tactile fabric and skin rendering, polished photographic surface, understated filmic imperfection
ЦВЕТОКОР
professional cinematic color grading, restrained cool-leaning palette, silvery midtones, preserved natural skin tones, elegant color separation, controlled saturation, soft contrast curve, luminous highlights, gentle shadow density, cohesive editorial tonality
РЕТУШЬ
subtle professional finishing, refined microcontrast, delicate vignette, atmospheric depth, gentle bloom, dimensional separation between planes, polished but natural image treatment, enhanced realism with editorial sophistication, quiet visual elegance
ХЗ ПОКА, РАБОТАЕТ ИЛИ НЕТ, НО НАПИСАЛ ОТ ДУШИ
a deep breathing still image, visually alive and emotionally present, realistic yet poetic, cinematic but not theatrical, quiet intensity, frozen motion, suspended time, three-dimensional world compressed into a powerful photographic frame
ОДЕЖДА В КОНЦЕ - В БОЛЬШИХ ГЕНЕРАТОРАХ (Типа Банана) ОНА ВСЕ РАВНО ПРОЧИТЫВАЕТСЯ
...но можно ее перенести до всех моих экспериментовWearing a dark gray flat cap, a cream long-sleeve henley shirt, brown leather suspenders, loose cropped trousers in dusty taupe, ribbed brown knee-high socks, brown lace-up leather work boots, and a dark belt or waistband detail.

А вот короткая версия для open-source и Midjourney. Пробую сейчас такие делать оптом вместо отдельно под Flux, отдельно под DALL-E и так далее. По сути, у них всех одинаковые грехи: не умеют читать длинные промпты и понимают в разы меньше токенов.
photorealistic 71 year old British man, dignified calm gaze, fair skin with cool undertone, realistic elderly skin texture, forehead wrinkles, crow's feet, nasolabial folds, age spots on temples and cheeks, small pale scar near right jaw
long oval face, high forehead with receded hairline, sparse grey eyebrows, pale blue hooded eyes, straight long nose, medium-thin lips, softened jawline, rounded chin, short white-grey beard and mustache, short thinning white-grey hair
tall lean slender elderly body, natural mature proportions, narrow shoulders proportional to height, long torso, long thin arms and legs, longer neck with age texture, slim waist, flat lean chest, proportional small head relative to tall frame, hands with visible knuckles, veins and age spots
wearing a dark gray flat cap, cream long-sleeve henley shirt, brown leather suspenders, loose cropped trousers in dusty taupe, ribbed brown knee-high socks, brown lace-up leather work boots
(под предыдущим постом вместе с клоуном автограф оставил кто-то более вонючий. Кто же появится здесь? :))
Сначала очередной экспериментальный промпт дня (тестировал алгоритм создания вайба). Целая драматическая сцена с эмоцией и персонажем.

GPT Image 2 (Low)
photorealistic 33 year old Kazakh-Uyghur mixed heritage woman wearing her own skin, sweat and hair with sharp dry elegance and observant composed gaze, tall very lean natural build, body mass index approximately 18.8, height approximately 177cm, weight approximately 58.9kg, shoulder width approximately 37.8cm, light-medium beige skin with cool olive undertone, realistic adult skin texture with visible fine pores, slight dryness around cheeks and mouth, subtle uneven pigmentation across forehead, faint under-eye shadows, delicate smile lines beginning at corners of mouth, one tiny dark mole below right cheekbone, faint healed acne marks on chin, natural facial asymmetry, no artificial smoothing, no exaggerated features
long diamond-shaped face with very high angular cheekbones and narrow lower face, face height approximately 19.3cm, face width approximately 14.5cm, medium-high forehead with smooth natural hairline, thin-to-medium black eyebrows with straight elongated shape, fine dense texture and slight asymmetry, dark brown eyes narrow set almond shaped with slight epicanthic folds and calm assessing gaze, eye length approximately 2.54cm, eye height approximately 0.78cm, long narrow nose with medium bridge and refined slightly pointed tip, nasolabial angle approximately 94 degrees, medium-thin lips with sharp cupid's bow and dry natural texture, lower lip subtly fuller, philtrum approximately 1.38cm, narrow pointed chin and sharply defined jawline
minimal graphic makeup featuring matte natural skin finish preserving dryness and texture, softly sharpened straight brows, muted taupe-grey eyeshadow close to lash line, fine black mascara, very subtle cool rose blush, and muted brick-rose lip stain with natural dry satin finish
very long black hair with cool blue undertone, straight heavy texture with slight natural bend near ends, reaching lower back, sharp center part with mild natural irregularity, realistic density, individual strands visible, smooth but not glossy, fine flyaways near temples
tall very lean feminine torso with elongated angular proportions, small natural bust approximately 78cm with realistic anatomical shape, narrow waist approximately 61cm, slim hips approximately 88cm, flat abdomen with slight natural softness and visible structural lines, prominent angular collarbones, long slender neck, narrow shoulders, very lean arms with subtle tendon visibility, fine wrists, proportional long hands with slender fingers and visible knuckles, very long lean leg proportions, dry angular elegant silhouette without stylization
composed observant facial expression, direct assessing gaze, relaxed lips with subtle sharpness at corners, realistic facial asymmetry, sharp understated austere presence, photorealistic human anatomy, physically accurate skin shading, natural subsurface scattering, realistic specular highlights, high detail
Dressed in a fitted long-sleeve knit top with a BLACK base, dense horizontal stripes in LIGHT BLUE, TURQUOISE, WARM ORANGE, ROSY PINK, GOLDEN BEIGE, and OFF-WHITE, a subtle metallic sheen, and a simple round neckline, paired with wide-leg trousers with a BLACK base, broad horizontal stripes in TURQUOISE, BLACK, and WARM ORANGE-CORAL, a soft flowing drape, and a loose sculptural silhouette, and low-profile pointed-toe flats with a LIGHT CREAM base and a BLACK checkered lattice pattern, a slim flat sole, and a clean tailored shape.
cinematic photographic realism, eerie elegant prestige thriller mood, suspended solitary presence, cold psychological tension, fashion-editorial noir atmosphere, immersive realism, a sense of time held in place
balanced poster composition with a strong central figure anchor, clear visual hierarchy, controlled framing, layered foreground-middle-background separation, symmetrical environmental structure, decisive but unobtrusive design, harmonious integration of character and space
soft diffused interior lighting, cool atmospheric illumination, gentle directional modeling, readable shadows, delicate highlight separation, light shaping form and emotion, believable cinematic ambience, refined tonal transitions
photographic camera language, classic cinematic portrait perspective, moderate depth of field, soft focus falloff, tactile lens rendering, intimate observational distance, realistic dimensional presence, subtle prestige-drama optical character
refined analog-inspired texture, fine organic grain, smooth highlight roll-off, subtle halation, soft diffusion, rich shadow depth, tactile rendering of fabric, skin, wood and glass, understated filmic imperfection
professional cinematic color grading, teal and cyan dominance, deep black shadows, muted steel-gray midtones, restrained skin tones, elegant color separation, controlled saturation, soft contrast curve, luminous cool highlights, cohesive art-house thriller tonality
subtle professional finishing, refined microcontrast, delicate vignette, atmospheric depth, gentle bloom in bright areas, dimensional separation between planes, polished but natural image treatment, enhanced realism with prestige-poster sophistication, quiet ominous glamour
VIBE BOOSTER: drifting cinematic haze, faint luminous window glow, soft atmospheric particles, subtle fabric shimmer, cool reflective highlights, gentle environmental softness, delicate editorial polish, additional understated emotional accents that strengthen the mood without changing the scene
a deep breathing still image, visually alive and emotionally present, realistic yet poetic, cinematic but not theatrical, quiet intensity, frozen motion, suspended time, three-dimensional world compressed into a powerful photographic frame
stands alone at the edge of an empty municipal ice rink after closing hours, one hand resting on the wet boards while the other traces the freshly resurfaced ice, observing the long reflective lane under cold overhead lights and faint fog from the ventilation system; crisp blue, silver, white, charcoal, pale cyan palette; main light from stadium fluorescents, rim light from the rink perimeter, practical light from a maintenance cart, atmospheric haze over the ice; film grain, shallow depth of field, subtle motion blur, cinematic color grading.
...И ее адаптация под более скромные open-source
photorealistic adult woman in her 20s of European descent, medium height, slim narrow frame, elongated oval heart-shaped face, broad forehead, large light blue almond eyes, small straight nose, mild overbite, fine light brows, dark blonde short layered bob with airy bangs, fair freckled skin, reserved cool expression, realistic skin texture, cinematic night portrait through a dirty car windshield, direct emotional gaze, hand pressed to glass, dark frame-within-frame composition, intimate separation, dramatic backlight, soft face fill, deep shadows, red and green practical accents, reflections, smudges, film grain, halation, Kodak Vision3 500T look, melancholic art-house still, quiet longing, fragile closeness, emotional barrier, realistic and poetic, highly detailed, photorealistic, cinematic lighting
Все равно дает неплохие результаты.

Z-Image Turbo
А теперь о том, чем занимался всю прошедшую неделю, пока выкладывал кучу промптов :).
Все-таки доделал я блог на Бусти и даже оформил. И Большую книгу промптов там выложил по Большой Прекрасной Цене, и бесплатный комплект, который здесь уже засветил двумя промптами из трех. Дальше немного рекламы: А заодно сделал три уровня подписки — для тех, кому красивых картинок скачать и в Телегу секретную зайти (ну там Телега-то так себе), для тех, кому промптов хорошо проработанных (все-таки, здесь я выкладываю новые, побочные и не всегда проотестированные и адаптированные, а в подписках — более четкие и проверенные на разной капризности генераторах). А самый высоий уровень подписки - там по ходу работы над следующими томами книги буду выкладывать прямо полноценные протестированные архетипы, со всеми адаптациями и точно работающие. Не все, конечно, но 20% книги точно так отдам (по одному представителю каждой возрастной группы каждого этноса). В первом томе женщины, во втором мужики будут.

Вчера уже тестировал первые мужские промпты.
...и осознал, что у меня скопился десяток крутых алгоритмов для генерации всего подряд — людей, одежды, сцен, даже вайба. Помог опыт фотографа и ГПТ, который мои километровые алгоритмы аккуратно структурировал в рабочие паспорта :). Теперь я делаю описание, прописываю все детально, а ГПТ это аккуратно структурирует - и можно промпты выводить.
Когда буду уверен, что все они работают бесперебойно (а то структуризация - хорошо, но без нее сбоев было меньше, пока довожу до ума), сделаю еще одну подписку - для промптов на заказ. По крайней мере, уже получается очень точно копировать заданную одежду и бижутерию и переводить ее в голый текст в любых комбинациях (каламбуры случайные). Типа, можно хранить свои товары для маркетов в записной книжке и пересылать через мессенджеры. Без фото-референсов. Удобно, наверное (во, ща кто-то клоуна влепит, как чую, за саморекламу).
А дальше не самореклама, а так, похвастаться немного :). Это тестовые версии новых алгоритмов, так что промпты там не везде даже на блоки разбиты, а колоритный дядька в таком виде вообще остался только в виде картинки. Но что есть - делюсь.

Промпт случайно удалил, но картинку сохранил.

Промпт прилагается :)
Photorealistic cinematic fine-art boudoir editorial photograph, single subject, adult woman in HER MID-20S with LIGHT HAZEL EYES with heavy lowered eyelids and languid downward-sideways gaze directed below the lens, PLATINUM BLONDE shoulder-length hair in soft loose retro waves with side parting and subtly darker roots, very pale faint brows, porcelain fair skin with realistic adult skin texture and visible natural pores, soft oval face, high smooth forehead, long elegant straight nose, full pouty lips with matte crimson-red lipstick relaxed and slightly parted, delicate pointed chin, softly defined cheekbones. Slim delicate adult build, narrow shoulders, visible collarbones, long slender arms, anatomically coherent adult figure, natural adult anatomical structure, natural torso contour, realistic skin folds, neutral anatomical realism. POSE — PRONE DIAGONAL SIDE-TWIST WITH BENT FOREGROUND LEG AND OVER-SHOULDER DOWNWARD GAZE: She lies diagonally across the fur rug in front of the fireplace, PRONE ON HER STOMACH WITH A PARTIAL SIDE TWIST toward the camera. Her UPPER BODY IS LIFTED ON HER FORARMS, both forearms resting on the rug ahead of her supporting her torso, chest angled slightly toward camera but not fully frontal. Her PELVIS IS ROTATED MORE STRONGLY TOWARD CAMERA THAN HER CHEST, creating a soft twist at the waist, the near hip lifted and pushed forward toward the lens. Her NEAR SHOULDER (closest to camera) IS RAISED CLOSE TO HER CHEEK, shoulders softly rounded forward and gathered inward, not opened wide. Her HEAD IS TURNED BACK TOWARD CAMERA OVER THE NEAR SHOULDER, chin lowered, neck elongated, gaze directed downward and slightly sideways below the lens line, lips relaxed and softly parted, introspective languid film-still expression. Her LEG CLOSEST TO CAMERA IS BENT AT THE KNEE AND BROUGHT FORWARD, the thigh forming a large sculptural shape in the foreground close to the lens, the knee pointing forward, the LOWER LEG EXTENDING TO THE RIGHT ALONG THE BOTTOM EDGE OF THE FRAME. Her FAR LEG EXTENDS BACKWARD behind her, softly relaxed, partially hidden by her body and the cascading fabric. The overall body forms one long elegant diagonal line from crown through shoulder, waist, near hip, bent thigh, to extended shin. Back forms a subtle gentle arch, not a deep curve. Weight distributed across her forearms, lower ribs, and near hip. Wearing a vintage champagne-gold satin-velvet slip dress with thin spaghetti straps, soft crushed-velvet sheen, fabric clinging to the twisted torso, bare shoulders and exposed collarbones, the long skirt draping in heavy honey-amber folds across the rotated hips and cascading over the bent foreground thigh and along the extended leg, pooling onto the fur in rich gathered folds, natural drape physics. The fur rug is a deep sable-chocolate brown with warm chestnut and mahogany highlights catching the firelight, long plush natural pile, soft glossy fiber tips, realistic fur texture, velvety dark tone creating refined chiaroscuro counterpoint to platinum hair, porcelain skin, and champagne fabric. CAMERA: low angle near the level of the rug, positioned to the side of the model, lens aimed along the diagonal of her body — face occupies the upper-left portion of the frame, near hip and bent foreground leg dominate the lower-right of the frame, strong foreshortening of the thigh, long body line stretching diagonally across the composition. Background: classic stone fireplace with live dancing orange flames, warm directional firelight as primary key light from behind and above, soft amber rim along her raised shoulder, the curve of her back and her hair, deep cinematic edge shadows, rich chiaroscuro contrast, warm filmic color grading, honey-amber and sable-brown complementary palette, medium-format film aesthetic, Steven Klein / Paolo Roversi editorial mood, restrained fine-art boudoir finish, photorealistic finish, ultra-detailed, shallow depth of field, 35-50mm lens feel, intimate sculptural single-subject composition.


photorealistic head-and-shoulders portrait of an adult woman in her 20s of European-American descent.
narrow heart-shaped face, high broad forehead, elongated skull shape, delicate temples, softly hollowed upper cheeks, high cheekbones, narrow lower face, small pointed chin, fine tapered jawline, subtle asymmetry with one eye slightly more open and one brow slightly higher; large PALE BLUE rounded almond eyes in accurate librarian glasses with thin round rims, wide visible sclera, slightly upturned outer corners, shallow-set placement, thin translucent upper lids, visible eyelid crease, faint lower-lid puffiness, long natural lashes, and an alert vulnerable gaze. [P]
small short nose with narrow high bridge, delicate radix, smooth dorsum, subtle supratip break, softly upturned rounded tip, compact nostrils visible from the front, and narrow alar base; medium-small lips with defined cupid’s bow, slightly lifted upper lip, fuller lower lip, small central opening at rest, lightly tense corners, mild overjet, narrow dental arch, small even front teeth, and slight upper-teeth display when the mouth opens. [P]
long thin neck, small sloping shoulders, delicate collarbones, compact upper torso, slim narrow frame, very fair skin with faint freckles, pink undertones, mild redness on the nose and cheeks, visible pores around the nose and central face, slight lip dryness, realistic texture across the neck and shoulders. [P]
COPPER RED long hair with a clean center part, high rounded hairline, slight temple recessions, darker root depth, lighter ginger face-framing strands, fine dense texture, soft waves, uneven ends, and flyaways along the forehead and crown; reserved, watchful, slightly breath-held expression, close framing, natural photorealism, no glamour retouching moving through wet night jungle with a tense tactical posture, realistic 1980s VHS action-cinema still, dense tropical foliage, dripping leaves, muddy ground, broken radio antenna tangled in vines, faint heat-haze distortion between trees suggesting an unseen watcher, CHARACTER pushing palm leaves aside and reacting to a sound above, green moonlight filtering through canopy, hard blue rim light from distant lightning, red emergency flare glowing in wet smoke, sweat and rain on skin, practical flashlight beam cutting through mist, deep shadows, tense survival atmosphere, analog film grain, slight halation, serious semi-parodic 80s action mood
dressed in relaxed feminine creative styling: a loose oversized vintage band t-shirt tucked into high-waisted wide-leg corduroy trousers in warm caramel, a thin leather belt, white canvas sneakers, layered silver necklaces, a stack of beaded bracelets, small silver hoops, and a low messy bun with loose strands around the face
cinematic photographic realism, intimate emotional stillness, quiet visual tension, suspended living moment, understated vulnerability, immersive realism, a sense of presence held in a brief pause [P]
layered composition with a clear visual hierarchy, balanced asymmetry, controlled framing, subtle foreground and background interaction, natural visual rhythm, gentle directional flow, strong but unobtrusive compositional structure, intimate observational distance [P]
soft naturalistic lighting with delicate directional modeling, controlled contrast, realistic shadow density, gentle highlight separation, light used to reveal facial volume, texture, and emotional focus, believable illumination with refined tonal transitions [P]
photographic camera language, close observational perspective, moderate focal compression, shallow depth of field, soft focus falloff, tactile lens rendering, subtle optical softness, intimate portrait distance, realistic dimensional presence [P]
refined analog-inspired texture, fine organic grain, smooth highlight roll-off, gentle halation around bright areas, subtle diffusion, rich readable shadow detail, tactile photographic surface, delicate moisture-rich realism [P]
professional cinematic color grading, restrained palette, elegant color separation, preserved natural skin and material tones, nuanced warm-cool balance, controlled saturation, soft contrast curve, dense but open shadows, luminous midtones, cohesive filmic tonality [P]
subtle professional finishing, refined microcontrast, delicate vignette, atmospheric depth, gentle bloom, dimensional separation between planes, polished but natural image treatment, enhanced realism without decorative excess [P]
atmospheric moisture, wet strands of hair, delicate droplets, soft lens bloom, tiny specular highlights, gentle bokeh, faint haze, floating dust, reflective light fragments, micro-contrast on texture, natural environmental shimmer, additional understated emotional accents that strengthen mood without changing the scene [P]
a deep breathing still image, visually alive and emotionally present, realistic yet poetic, cinematic but not theatrical, quiet intensity, frozen motion, suspended time, three-dimensional world compressed into a powerful photographic frame [P]

Photorealistic adult woman in her early 20s with a slender narrow-shouldered build, long smooth neck, delicate wrists, long slim fingers, small-to-medium hands, balanced soft upper torso line, relaxed shoulders, natural human proportions, quiet everyday realism, restrained sensual presence, self-possessed private body language, slow controlled physical rhythm Dressed in a DARK wide-brim felt hat with a soft rounded crown and slightly downturned brim, a fitted DARK black bodice with a subtle vertical textured sheen and asymmetrical draped construction, a soft CREAM draped wrap with loose layered folds and uneven edges crossing diagonally across the upper garment, a long DEEP GREEN layered drape with heavy flowing fabric and a trailing hem, and delicate CREAM lace trim along the edges with fine openwork texture and soft scalloped borders.
Fair warm peach-beige skin with visible pores, subtle uneven warm tone, faint redness around the cheeks and nose, mild under-eye shadows, natural cheek texture, realistic lip texture, natural hand lines, fine knuckle texture, PALE NATURAL PINK ALMOND NAILS, fine delicate hairs on arms and legs, tactile photoreal skin.
WARM HAZEL-BROWN eyes, narrow almond-shaped eyes, horizontally elongated eye openings, softly heavy upper eyelids, low partially hidden eyelid crease, calm slightly sleepy direct gaze, private watchful expression, mild under-eye shadows, fine lower-lid texture, slight asymmetry between the eyelids, dark natural lash line. Dark medium-density brows, softly arched, low-to-medium brow placement, slightly fuller inner brows, natural uneven brow hairs, relaxed brow tension.
Soft elongated oval-heart face with a high smooth open forehead, softly rounded frontal hairline, narrow pale center-part line, gentle temples partly covered by curls, soft cheek volume, smooth malar area, subtle cheekbone support, smooth under-cheek transitions, narrow delicate lower face, fine non-square jawline, compact but convex lower third, small rounded recessed chin relative to the lips, soft chin-lip groove, slight natural facial asymmetry. Small straight narrow nose with a soft narrow bridge, smooth nasal dorsum, compact nasal length, narrow nasal pyramid, softly rounded compact blunt nasal tip, gentle moderate tip projection, narrow-to-medium alar base, softly defined nostrils, subtle nose-to-cheek transition, minimal visible columella.
Medium-width closed mouth with softly full lips, lower lip full but softly tucked under the upper dental support, upper lip gently projected by forward upper dental-arch support, soft defined Cupid’s bow, short-to-medium philtrum with slight convex support, noticeable overbite-like closed-mouth support, projected dentoalveolar mouth area, lips resting forward of the chin, convex mouth-to-chin relationship, soft mentalis tension under the lower lip, natural lip texture, restrained firm horizontal mouth line.
Slender narrow-shouldered body, long smooth neck, delicate collarbones, fine wrists, long slim fingers, soft small-to-medium hands, narrow delicate frame, calm grounded posture, slow minimal gestures, controlled stillness, quiet tactile physical presence.
DARK CHESTNUT BROWN CURLY-WAVY HAIR, very long and very dense, center part, thick loose waves mixed with soft curls, large side volume around the face, uneven natural curl pattern, airy frizz, irregular textured strands near the forehead and cheeks, warm brown tonal variation, heavy natural hair mass framing the narrow face, porous tactile hair texture.
Minimal natural makeup, soft groomed brows, neutral natural lip tone, calm slightly distant expression, heavy-lidded gaze, closed-mouth stillness over forward dental support, slow inner tension, tactile facial volume, individualized asymmetry, specific living face, ordinary human imperfections, photorealistic skin and hair texture, raw photographic realism, soft natural light, quiet magnetic adult presence.
cinematic photographic realism, poetic melancholic stillness, quiet contemplative tension, suspended living moment, intimate introspective atmosphere, tender emotional weight, immersive realism, a sense of time gently held in place
balanced painterly composition with symmetrical natural framing, soft central focus, clear visual hierarchy, layered foreground-middle-background separation, organic interplay between geometric structure and living elements, decisive but unobtrusive design, harmonious integration of subject and environment
selective directional sunlight piercing through a window, sharp-edged warm light beam against cool ambient illumination, strong but controlled contrast, deep readable shadows, dramatic highlight isolation on key subject elements, light shaping form and meaning, believable natural motivated illumination, refined tonal gradation
photographic camera language, classic film-inspired perspective, moderate depth of field, soft focus falloff, tactile lens rendering, intimate observational distance, realistic dimensional presence, gentle analog softness in shadows, clean poetic optical character
refined analog film texture, visible organic grain, smooth highlight roll-off, subtle halation around warm highlights, soft diffusion in shadow areas, rich readable shadow detail, tactile rendering of tile, skin, fabric, paper and foliage, polished photographic surface, understated filmic imperfection
professional cinematic color grading, split-tone palette with warm amber highlights and cool teal shadows, preserved natural skin tones, selective saturated yellow accents, gentle green midtones from foliage, elegant color separation, controlled saturation, soft contrast curve, luminous warm key light, cohesive melancholic tonality
subtle professional finishing, refined microcontrast, delicate vignette, atmospheric depth, gentle bloom on warm sunlit areas, dimensional separation between planes, polished but natural image treatment, enhanced realism with poetic sophistication, quiet contemplative warmth
VIBE BOOSTER: soft atmospheric haze in the light beam, delicate dust motes drifting through sunlight, gentle skin sheen in warm light, subtle moisture on cool surfaces, faint lens bloom on yellow highlights, tactile micro-contrast on tile and fabric, natural environmental softness, additional understated emotional accents that strengthen the mood without changing the scene
a deep breathing still image, visually alive and emotionally present, realistic yet poetic, cinematic but not theatrical, quiet intensity, frozen motion, suspended time, three-dimensional world compressed into a powerful photographic frame

Во вчерашнюю сцену сегодняшние персонажи вполне умещаются :)
Работы был вагон, да и вообще ночью Рязань так бомбили, что мы с женой решили сына в школу не вести, пока не развеется облако, а то с его кашлем оно чревато, да и на машину черный дождик покапал. А кому-то вообще квартиры разнесло, жесть :(.
Но под вечер разобрало: решил с помощью Грока и ЧГПТ освежить недоделанный алгоритм превращения вымышленных персонажей в людей. Опять же, чисто текстом, ясное дело. Такое в "Большую книгу промптов", которая хрен знает когда будет уже на Бусти по-нормальному, не поставишь, за копирайт жопу отшибут, так что это вообще так, баловство. (Я не могу не сказать: тут и клоунов можно пачками кидать, готовьтесь. Оно так и задумано :)
Не тестировал, естественно, по всем генераторам, ибо некогда. Персонажей подбирал, как для стресс-теста (дети, эротичная мадам, брутальные мужики), но получилось немного однообразно. Так, немножко там, немножко тут. Джим из "Острова сокровищ" вообще хоть сейчас в "Ералаш". Но типажи прикольные. Последние два блока у каждого - типичный наряд и типичная сцена. Уберите их - и уже просто люди останутся. (Парень в очках и розовом костюме, кто ты без него? Джим Хокинс, сэр...)
Короче, прошу. Вдруг понравится кому. И нет, тут я даже результат показать не прошу %)
Тэг: [MUG]

Высокий атлетичный молодой мужчина с дикими чёрными волосами, острым хищным взглядом и беззаботной ухмылкой. Сильная челюсть, загорелая кожа с видимой текстурой и нервная уличная пластика создают образ хаотичного, свободолюбивого самурая, который живёт одним днём.
photorealistic full-body character portrait of an adult Japanese man in his 20s, sun-kissed warm skin with visible pores, subtle freckles across the nose bridge, slight cheek redness, uneven natural tone, realistic micro-texture and human skin imperfections, chaotic free-spirited ronin presence, raw photographic realism
tall athletic build, broad powerful shoulders, lean muscular torso, long limbs, confident upright posture with loose swagger, relaxed shoulders, quick nervous street-samurai plasticity, realistic weight distribution and slight natural body asymmetries
sharp angular face with strong square jawline, prominent high cheekbones, slightly asymmetrical bone structure, high facial tension and predatory street energy; intense DARK BROWN almond-shaped eyes with heavy upper lids, subtle epicanthic fold, sharp outer corners and a piercing playful-dangerous gaze; thick black expressive eyebrows, slightly furrowed in a cocky expression; straight nose with a small bridge bump and slightly flared nostrils; full lips usually pulled into a mischievous grin, slightly uneven mouth line, sharp canine teeth visible when smiling
wild spiky BLACK hair with uneven natural strands, visible cowlick at the crown, flyaways, rough texture and slight frizz at the edges
dark sleeveless haori jacket over open torso, loose black hakama pants, wooden geta sandals, red headband, katana sword at the hip, messy battle-worn appearance; dusty Edo-period Japanese street, wooden buildings, paper lanterns, drifting cherry blossom petals, distant mountains, warm cinematic sunset lighting
photorealistic close-up portrait of an adult Japanese man in his 20s, sun-kissed warm skin with visible pores, subtle freckles on the nose bridge, slight redness on cheeks, natural uneven tone and realistic micro-texture, chaotic free-spirited ronin mood, raw photorealistic skin detail, not a real person likeness
sharp angular face, strong square jawline, prominent high cheekbones, slightly asymmetrical facial structure, high forehead tension and rugged cheek planes; intense DARK BROWN almond-shaped eyes with heavy upper lids, subtle epicanthic fold, sharp outer corners and a confident piercing gaze with playful danger; thick black eyebrows, expressive and slightly furrowed; straight nose with a small bridge bump and slightly flared nostrils; full lips curved into a cocky mischievous grin, slight asymmetry in the smile, sharp canine teeth visible
wild spiky BLACK hair with uneven strands, cowlick at the crown, flyaways and slight frizz around the silhouette
red headband framing the hairline, dark sleeveless haori edge visible near the shoulders, dangerous street-samurai energy
photorealistic adult Japanese man in his 20s, tall athletic build, sun-kissed textured skin, sharp angular face, strong square jaw, high cheekbones, intense DARK BROWN almond eyes, thick furrowed brows, straight nose with slight bridge bump, full mischievous grin with sharp canines, wild spiky BLACK hair, red headband, dark sleeveless haori, loose black hakama, swaggering dangerous street-samurai energy, not a real person likeness
Тэг: [DRU]

Высокая стройная женщина с длинными волнистыми тёмными волосами, большими выразительными глазами и мягкими, но сильными чертами лица. Плавная пластика, уверенная осанка и загадочная аура создают образ чувственной, свободной и немного таинственной натуры.
photorealistic full-body character portrait of an adult Mediterranean woman in her mid-20s, warm natural skin with subtle olive undertones, visible pores, faint freckles across the nose bridge, fine delicate hairs on arms and legs where visible, natural blush variations and realistic micro-texture, enigmatic sensual-but-dangerous presence, photorealistic editorial realism, not a real person likeness
tall graceful curvaceous-athletic build with balanced proportions, long neck, gently sloping shoulders, balanced upper torso, narrow waist flowing into full hips, long toned legs, confident upright posture with a slight predatory lean, relaxed shoulders and slow fluid plasticity
oval face with soft yet sharply defined high cheekbones, refined jawline, slight natural asymmetry and calm sculptural facial planes; large expressive DARK BROWN eyes with long thick lashes, slight downward tilt, soft heavy upper lids and an intense mysterious gaze conveying quiet confidence and hidden danger; arched dark eyebrows, elegant and expressive; straight nose with gentle bridge and softly rounded tip; full naturally shaped lips with defined cupid’s bow, soft texture and a slight asymmetry in the smile
long voluminous wavy DARK BROWN hair with natural movement, loose waves, heavy flowing length, irregular strand thickness, flyaways and slight frizz at the ends
form-fitting dark leather harness-and-straps outfit, high boots, minimal mysterious sci-fi styling; post-apocalyptic ruined city, broken concrete buildings, sand dunes, dramatic orange sky, atmospheric light
photorealistic close-up portrait of an adult Mediterranean woman in her mid-20s, warm olive-toned natural skin with visible pores, faint freckles over the nose bridge, subtle blush variations and realistic micro-texture, enigmatic sensual-but-dangerous mood, raw photographic realism, not a real person likeness
oval face with softly defined but high cheekbones, refined jawline, gentle facial asymmetry and calm sculptural geometry; large expressive DARK BROWN eyes with long thick lashes, soft heavy upper lids, slight downward tilt and a steady mysterious gaze with quiet confidence; arched dark eyebrows, elegant and controlled; straight nose with a gentle bridge and soft rounded tip; full natural lips with defined cupid’s bow, soft texture and slight asymmetry in the mouth line
long voluminous wavy DARK BROWN hair framing the face, natural movement, loose waves, flyaways and slight frizz at the ends
dark leather strap detail visible near the shoulders, mysterious confident expression
photorealistic adult Mediterranean woman in her mid-20s, tall graceful curvaceous-athletic silhouette, warm olive textured skin, oval face, high soft-defined cheekbones, large DARK BROWN eyes with long lashes, arched brows, straight soft-tipped nose, full natural lips, long voluminous wavy DARK BROWN hair, dark leather harness styling, mysterious confident expression, not a real person likeness
Тэг: [MOR]

Высокий крепкий мужчина в расцвете сил с суровым, но честным лицом, пронзительными голубыми глазами и короткой бородой. Загрубевшая от ветра и солнца кожа, сильные черты и спокойная, но тяжёлая осанка создают образ надёжного, много повидавшего человека с внутренним стержнем.
photorealistic full-body character portrait of an adult European American man in his late 30s, weathered sun-tanned skin with visible pores, fine lines, freckles, solar lentigines on cheeks and nose, wind-chapped texture and natural uneven redness, calm dangerous western gravity, raw photographic realism, not a real person likeness
tall muscular rugged build with very broad shoulders, thick chest, strong arms with visible veins, compact waist, sturdy legs and heavy grounded stance; confident but weary upright posture with natural weight shift to one leg, slow economical frontier plasticity
rugged square face with strong prominent jawline, high cheekbones, slightly asymmetrical bone structure, heavy brow ridge and tired facial tension; piercing STEEL-BLUE eyes with heavy upper lids, subtle crow’s feet and an intense honest gaze; thick expressive brown eyebrows, slightly furrowed; straight nose with slight bridge bump and flared nostrils; full lips with natural downturn at the corners, dry texture and visible restrained tension; neat stubble and short beard with grey flecks, rugged but controlled grooming
short brown hair with natural cowlick, slight recession at temples, realistic flyaways
wide-brimmed cowboy hat, long brown duster coat, red bandana around neck, leather gun belt with two revolvers, worn leather boots, rugged western outlaw outfit; vast American prairie at golden hour, rolling hills, distant mountains, dusty trail, lone horse in background, cinematic western sunset lighting
photorealistic close-up portrait of an adult European American man in his late 30s, weathered sun-tanned skin with visible pores, fine lines, freckles, solar lentigines, wind-chapped cheeks and natural uneven redness, calm dangerous western gravity, raw photorealistic realism, not a real person likeness
rugged square face with strong prominent jawline, high cheekbones, heavy brow ridge, slightly asymmetrical bone structure and tired weathered expression lines; piercing STEEL-BLUE eyes with heavy upper lids, subtle crow’s feet and a steady honest gaze carrying fatigue and resolve; thick brown eyebrows, slightly furrowed; straight nose with slight bridge bump and flared nostrils; full lips with dry texture and natural downturn at the corners; short beard and stubble with grey flecks, rough natural texture
short brown hair with cowlick and slight recession at temples
brim of a worn cowboy hat, red bandana edge and brown coat collar visible, weary honest expression
photorealistic adult European American man in his late 30s, tall muscular rugged build, weathered sun-tanned skin, square rugged face, strong jaw, high cheekbones, piercing STEEL-BLUE eyes, thick furrowed brows, straight nose with slight bump, full downturned lips, short brown hair, short beard with grey flecks, cowboy hat, brown duster coat, red bandana, weary honest expression
Тэг: [LIV]

Высокий крепкий мужчина средних лет с чрезвычайно длинным вытянутым лицом, огромной заразительной белозубой улыбкой до ушей и белым напудренным париком. Театральная энергичная пластика и неукротимый оптимизм создают образ эксцентричного, но надёжного и жизнерадостного доктора.
photorealistic full-body character portrait of an adult European man in his late 40s, sun-kissed skin with visible pores, subtle cheek redness, natural age lines, realistic micro-texture and lively warmth, exuberant reliable comic-doctor energy, photorealistic theatrical realism, not a real person likeness
tall stocky powerful build with very broad shoulders, barrel chest, thick muscular arms, sturdy shorter legs, long neck and theatrical grounded stance; energetic upright posture with open gesture, buoyant theatrical plasticity and unstoppable optimism
extremely long elongated face with high prominent forehead, long nasal bridge, strong prominent chin, exaggerated but believable facial proportions and energetic asymmetry; warm HAZEL eyes with joyful spark, slight crow’s feet and alert intelligent gaze; round wire-rimmed glasses resting on the high nasal bridge; massive wide grin almost from ear to ear, large perfect white teeth, visible upper gum line, infectious comic confidence; expressive brows partly hidden by the wig line, lifted with optimism; long straight nose integrated into the elongated face; neat short beard with grey flecks
white powdered 18th-century wig with tight side curls, structured volume and black ribbon bow
bright green 18th-century frock coat with gold buttons, white ruffled jabot and cuffs, brown breeches, white stockings, black shoes with large buckles, slightly dishevelled pirate-doctor appearance, curved saber in one hand; dim wooden ship cabin, low beams, scattered treasure maps and charts, barrels labeled ROM, warm oil-lantern glow, adventurous humorous 18th-century atmosphere
photorealistic close-up portrait of an adult European man in his late 40s, sun-kissed skin with visible pores, subtle cheek redness, age-appropriate lines and realistic micro-texture, exuberant reliable comic-doctor energy, raw photographic realism, not a real person likeness
extremely long elongated face with high prominent forehead, long nasal bridge, strong prominent chin and exaggerated yet believable facial geometry; warm HAZEL eyes with joyful spark, slight crow’s feet and bright intelligent optimism; round wire-rimmed glasses sitting high on the nose; massive wide grin almost from ear to ear, large perfect white teeth and visible upper gum line, infectious theatrical confidence; expressive lifted brows under the wig line; long straight nose, neat short grey-flecked beard
white powdered 18th-century wig with tight curls, structured side volume and black ribbon
white ruffled jabot and bright green coat collar visible, energetic theatrical expression
photorealistic adult European man in his late 40s, tall stocky powerful build, extremely long elongated face, high forehead, long nose, prominent chin, massive ear-to-ear white-toothed grin, warm HAZEL eyes, round wire glasses, white powdered wig with black ribbon, short grey-flecked beard, bright green 18th-century coat, theatrical joyful energy, not a real person likeness
Тэг: [REI]

Бледная девочка-подросток с короткими светло-голубыми волосами и огромными красными глазами. Спокойное, почти безэмоциональное выражение лица, хрупкая фигура и отстранённая аура создают образ тихой, загадочной и немного неземной натуры.
photorealistic standing character portrait of a Japanese girl around 14 years old, very pale almost translucent skin with subtle pink flush on cheeks and nose bridge, visible pores, soft natural micro-texture and gentle uneven skin tone, silent detached introspective mood, photorealistic realism, not a real person likeness
narrow shoulders, compact age-appropriate build, long graceful neck, calm upright posture with slight forward head tilt and restrained fragile plasticity
small delicate face with soft rounded cheeks, high forehead, slight facial asymmetry and quiet fragile geometry; large RED round eyes, wide open calm distant gaze, soft heavy upper lids, delicate lower lash line, subtle epicanthic fold and almost emotionless stillness; very light thin eyebrows, soft and understated; small straight nose with soft rounded tip; small mouth with naturally thin lips, neutral relaxed line and minimal expression
short straight LIGHT BLUE hair in a precise even bob cut, fine delicate strands, soft bangs, slight natural movement at the ends and small flyaways
white and blue Japanese school uniform with red bow tie and pleated skirt, clean simple appearance; quiet Tokyo city street at dusk, tall modern buildings, soft orange sky, subtle sci-fi city glow in the distance, calm introspective atmosphere
photorealistic head-and-shoulders portrait of a Japanese girl around 14 years old, very pale almost translucent skin with soft pink flush on cheeks and nose bridge, visible pores, gentle micro-texture and natural uneven tone, silent detached introspective mood, photorealistic natural skin detail, not a real person likeness
small delicate face with high forehead, soft rounded cheeks, slight asymmetry and quiet fragile facial structure; large RED round eyes with wide open calm distant gaze, soft heavy upper lids, delicate lower lash line and subtle epicanthic fold; very light thin eyebrows, understated and soft; small straight nose with rounded tip; small mouth with thin natural lips and neutral relaxed line
short straight LIGHT BLUE bob haircut with precise even shape, soft bangs, fine delicate strands, slight movement at the ends and natural flyaways
white-and-blue school uniform collar and red bow tie visible, quiet detached expression
photorealistic Japanese girl around 14 years old, very pale textured skin, small delicate face, high forehead, soft rounded cheeks, large RED round eyes with calm distant gaze, light thin brows, small straight nose, thin neutral lips, short straight LIGHT BLUE bob hair, compact age-appropriate build, white-and-blue school uniform with red bow tie, quiet detached expression, not a real person likeness
Тэг: [LUS]

Высокая элегантная женщина с длинными волнистыми чёрными волосами, пронзительными красными глазами и хищной грацией. Острые черты лица, уверенная осанка и опасная чувственность создают образ соблазнительной, смертельно опасной и загадочной натуры.
photorealistic full-body character portrait of an adult Japanese woman in her late 20s, pale cool-toned skin with visible pores, subtle micro-texture, faint natural blush and smooth realistic variations, elegant dangerous aura, photorealistic cinematic realism, not a real person likeness
tall elegant curvaceous-athletic build with balanced proportions, long graceful neck, gently sloping shoulders, balanced upper torso, narrow waist flowing into full hips, long toned legs and controlled predatory posture
sharp elegant face with high prominent cheekbones, refined jawline, slight facial asymmetry and polished dangerous beauty; piercing RED-VIOLET eyes with heavy upper lids, long thick lashes, slight downward tilt and an intense confident gaze conveying quiet danger and allure; arched expressive dark eyebrows, precise and elegant; straight nose with delicate bridge and soft rounded tip; full naturally shaped lips with defined cupid’s bow, soft texture and slight asymmetry, calm knowing expression
long voluminous wavy BLACK hair with dramatic side-swept bangs partially covering one eye, soft waves, natural movement, irregular strands and slight frizz at the edges
sleek form-fitting black off-shoulder dress with long sleeves and deep sculptural neckline, long black gloves, large clawed gauntlet with five long razor-sharp blades on the right hand, red ouroboros tattoo on upper chest, elegant menacing homunculus style; dim elegant urban interior or shadowy high-tech laboratory, cool blue-white lighting, blurred city or industrial background, mysterious dangerous atmosphere
photorealistic close-up portrait of an adult Japanese woman in her late 20s, pale cool-toned skin with visible pores, subtle micro-texture, faint natural blush and smooth realistic tone variations, elegant dangerous aura, raw photographic realism, not a real person likeness
sharp elegant face with high prominent cheekbones, refined jawline, subtle asymmetry and dangerous sculptural facial planes; piercing RED-VIOLET eyes with heavy upper lids, long thick lashes, slight downward tilt and a steady confident gaze with quiet menace; arched expressive dark eyebrows, precise and controlled; straight nose with delicate bridge and soft rounded tip; full naturally shaped lips with defined cupid’s bow, soft texture and slight asymmetry in a calm knowing expression
long voluminous wavy BLACK hair framing the face, dramatic side-swept bangs partially covering one eye, soft waves, natural movement and fine flyaways
black off-shoulder dress neckline and glove detail visible, red ouroboros tattoo partly visible on upper chest, confident dangerous expression
photorealistic adult Japanese woman in her late 20s, tall elegant curvaceous-athletic silhouette, pale cool textured skin, sharp elegant face, high cheekbones, refined jaw, piercing RED-VIOLET eyes, arched dark brows, straight delicate nose, full natural lips, long wavy BLACK hair with side-swept bangs over one eye, black off-shoulder dress, long gloves, red ouroboros upper-chest tattoo, confident dangerous expression, not a real person likeness
Тэг: [JIM]

Энергичный подросток с живым лицом, круглыми очками и ярко-рыжими волосами, собранными в маленький хвостик. Румяные щёки, озорной взгляд и авантюрная пластика создают образ смелого, любопытного и немного неуклюжего мальчишки, готового к приключениям.
photorealistic standing character portrait of a European boy around 13-14 years old, fair skin with visible pores, soft micro-texture, rosy flushed cheeks, light freckles across the nose bridge and cheeks, natural uneven tone, brave curious island-adventure energy, photorealistic realism, not a real person likeness
compact energetic build with age-appropriate proportions, narrow shoulders, relatively short sturdy legs, long neck and lively upright posture with adventurous forward lean
round youthful face with high forehead, soft rounded cheeks and slight facial asymmetry; large expressive HAZEL eyes behind round wire-rimmed glasses, bright curious gaze, open alert expression and playful courage; short dark eyebrows, slightly raised; small straight nose with soft rounded tip; small mouth with naturally thin lips, slightly open adventurous smile revealing upper teeth
short spiky BRIGHT RED hair with uneven lively strands, small black bow tied at the back, light flyaways and playful silhouette
tall cylindrical red striped hat slightly tilted, bright pink-red 18th-century frock coat with large white buckle and gold buttons, blue vest and breeches, white stockings, brown buckled shoes, white bow tie, round glasses, classic adventurous boy appearance; lush green jungle foliage with large leaves and vines, bright sunny day, blue sky and white clouds, tropical island adventure atmosphere
photorealistic head-and-shoulders portrait of a European boy around 13-14 years old, fair skin with visible pores, soft micro-texture, rosy flushed cheeks, light freckles across nose bridge and cheeks, natural uneven tone, brave curious island-adventure energy, photorealistic natural detail, not a real person likeness
round youthful face with high forehead, soft rounded cheeks, slight facial asymmetry and lively open expression; large expressive HAZEL eyes behind round wire-rimmed glasses, bright curious gaze and adventurous alertness; short dark eyebrows slightly raised; small straight nose with rounded tip; small mouth with thin natural lips and slightly open smile showing upper teeth
short spiky BRIGHT RED hair with uneven strands, small black bow tied at the back, playful flyaways
tilted red striped cylindrical hat, white bow tie and pink-red frock coat collar visible, curious adventurous expression
photorealistic European boy around 13-14 years old, compact energetic build, fair textured skin, rosy freckled cheeks, round youthful face, high forehead, large HAZEL eyes behind round wire glasses, raised dark brows, small straight nose, thin smiling lips, short spiky BRIGHT RED hair with black bow, tilted red striped hat, pink-red frock coat, curious adventurous expression, not a real person likeness
Ну а что, работа кипит, делиться есть чем. Первый клоун, кстати, под вчерашним постом отметился только спустя сутки — растем над собой.
Сегодня опять мадемуазель. Я тут промптами одежды сильно так заморочился, так что сегодня в первую очередь костюмы со сценой, а во-вторую - дама :). Совмещать по схеме ПЕРСОНАЖ → ОДЕЖДА, как в длинных промптах, так и в коротких. Кстати, когда себе референсы искал для описания, заметил, что в поиске сразу прямо пачками вылетают однотипные ИИ-болванки. Вот ради этого и работаем. Заодно даю сцену со сложным светом. Ее добавлять после первого блока, с основным описанием персонажа. Ну, или брать короткую версию сцены и короткие версии персонажей, потому что базовый промпт получился километровый, его только бизоны ловят вроде Nano Banana и GPT Image
Во многие адаптации добавлена нейтральная одежда - White cropped athletic top and high-waisted white fitted athletic shorts. Если будете переодевать, убирайте этот кусок. А то генераторы тупят.

Тег/Tag: [TATPL]
Взрослая женщина за 20 с короткой платиновой стрижкой, компактным овальным лицом и множеством чёрных татуировок на шее, руках и корпусе.
Photorealistic adult woman in her mid-20s with fair warm-neutral skin, slight golden sun tone, visible pores, subtle uneven skin tone, faint redness around the nose and upper cheeks, soft under-eye shadows, small natural skin marks, fine delicate hairs on arms and legs, slight dryness on knuckles, elbows and knees, gentle skin compression at wrists, elbows, waistline and knees, realistic contact shadows under the lower lip, along the neck and around the waistband.
DARK BROWN EYES, almond-shaped, slightly narrowed, compactly spaced, with a steady direct gaze, heavier upper eyelid line, softly defined upper lids, faint lower-lid shadow, dark eyelash line and subtly lifted outer corners. The eyes show a calm focused expression.
Dark medium-thick arched brows, cleanly shaped, sitting close to the eyes, with a defined outer tail and strong contrast against the pale hair.
Compact oval-heart face with a high open forehead, smooth rounded skull contour, soft temples, moderate cheekbones, smooth full cheeks, short middle face, narrow soft lower jaw and small rounded chin. Slight natural asymmetry in brow height and eyelid openness.
Small straight nose with a short neat bridge, narrow-to-moderate nasal dorsum, soft rounded tip, moderate nostril width and gentle nose-to-cheek transition.
Medium-width mouth with a finer upper lip, fuller lower lip, shallow cupid’s bow, calm closed-mouth line, natural lip texture and neutral mouth corners.
Slim compact lightly athletic build, narrow-to-medium shoulders, long slim neck, defined collarbone area, compact upper torso, narrow waist, naturally toned abdomen, slim arms, delicate wrists, long narrow hands, lean hips, firm upper thighs, slim legs and defined knees.
Collected upright posture, relaxed shoulders, slightly angular body language and calm direct presence.
PLATINUM BLONDE BUZZ CUT, ultra-short even length, close-cropped rounded head silhouette, pale blonde tone with slight warm beige variation, dense fine stubble-like hair texture, clean visible hairline and smooth crown contour.
DENSE BLACK LINEWORK TATTOO COVERAGE across the neck, shoulders, arms, torso, abdomen and thighs: thin black lines, botanical stems, ornamental shapes, symbolic small motifs, medium-to-high visual density, black ink with slightly softened healed edges.
Minimal natural makeup impression with defined dark eyelash line and shaped brows.
Raw photographic realism, natural light response on skin, realistic shadow gradients, small color shifts between face, arms, abdomen and legs, healed tattoo edges, real fabric texture and tactile skin detail.

Photorealistic close-up portrait of an adult woman in her mid-20s with a compact oval-heart face, high open forehead, smooth rounded skull contour, soft temples, moderate cheekbones, smooth full cheeks, short middle face, narrow soft lower jaw, small rounded chin and slight natural asymmetry.
DARK BROWN almond-shaped eyes, slightly narrowed, compactly spaced, steady direct gaze, heavier upper eyelid line, softly defined upper lids, faint lower-lid shadow, dark eyelash line and subtly lifted outer corners. The gaze is calm and focused.
Dark medium-thick arched brows, cleanly shaped, close to the eyes, with a defined outer tail and strong contrast against PLATINUM BLONDE BUZZ CUT hair.
Small straight nose with a short neat bridge, soft rounded tip, moderate nostril width and gentle nose-to-cheek transition.
Medium-width mouth with a finer upper lip, fuller lower lip, shallow cupid’s bow, calm closed-mouth line, natural lip texture and neutral mouth corners.
Fair warm-neutral skin with visible pores, faint redness around the nose and upper cheeks, soft under-eye shadows, slight uneven tone, tiny natural marks and realistic texture. PLATINUM BLONDE BUZZ CUT with ultra-short even length, pale warm-beige variation, dense fine stubble-like texture and fully open forehead. BLACK NECK TATTOO elements appear as fine ornamental and symbolic linework near the lower frame.
Adult woman in her mid-20s, fair warm-neutral skin, compact oval-heart face, high open forehead, DARK BROWN slightly narrowed almond-shaped eyes, dark arched brows, small straight nose with soft rounded tip, medium closed mouth with finer upper lip and fuller lower lip, narrow soft jaw, small rounded chin, PLATINUM BLONDE BUZZ CUT, slim compact lightly athletic body, narrow waist, collected slightly angular posture, DENSE BLACK LINEWORK TATTOO COVERAGE on neck, arms, torso and thighs, calm direct expression.
Photorealistic adult woman in her mid-20s with fair warm-neutral skin, slim compact lightly athletic build, narrow waist, slim arms, lean legs and collected slightly angular posture.
Compact oval-heart face with high open forehead, soft cheeks, narrow jaw and small rounded chin. DARK BROWN almond-shaped eyes, slightly narrowed, with heavier upper lids and a steady direct gaze.
Dark medium-thick arched brows sit close to the eyes and strongly contrast with her PLATINUM BLONDE BUZZ CUT.
Small straight nose with short bridge and soft rounded tip. Medium closed mouth with finer upper lip, fuller lower lip and neutral mouth corners. Ultra-short pale platinum buzz cut, fully open forehead and rounded skull silhouette. DENSE BLACK LINEWORK TATTOO COVERAGE on neck, arms, torso, abdomen and thighs.
Calm direct presence, raw photographic realism, visible skin texture and healed black tattoo edges.
Photorealistic adult woman in her mid-20s with fair warm-neutral skin, visible pores, slight uneven tone, soft under-eye shadows, faint redness around the nose and upper cheeks, small natural skin marks and a slim compact lightly athletic build. She has narrow-to-medium shoulders, long slim neck, compact upper torso, narrow waist, toned abdomen, slim arms, delicate wrists, lean hips, firm upper thighs and slim legs.
Compact oval-heart face with high open forehead, smooth rounded skull contour, soft temples, moderate cheekbones, smooth full cheeks, narrow soft jaw and small rounded chin. DARK BROWN almond-shaped eyes, slightly narrowed, compactly spaced, steady direct gaze, heavier upper eyelid line and dark eyelash line.
Dark medium-thick arched brows sit close to the eyes and contrast strongly with PLATINUM BLONDE BUZZ CUT hair. Small straight nose with short neat bridge, soft rounded tip and moderate nostril width. Medium closed mouth with finer upper lip, fuller lower lip, shallow cupid’s bow, natural lip texture and neutral corners.
PLATINUM BLONDE BUZZ CUT, ultra-short even length, close-cropped rounded silhouette, pale warm-beige blonde tone, dense fine stubble-like texture and fully open forehead. DENSE BLACK LINEWORK TATTOO COVERAGE across the neck, shoulders, arms, torso, abdomen and thighs, with botanical stems, ornamental shapes, symbolic motifs and airy asymmetric black ink compositions.
White cropped athletic top and high-waisted white fitted athletic shorts, clean sporty minimalism, close practical fit and soft ribbed cotton-like texture. Collected upright posture, relaxed shoulders, calm direct expression, slightly angular body language and raw photographic realism.
Photorealistic full-body adult woman in her mid-20s with slim compact lightly athletic proportions, fair warm-neutral skin, visible pores, slight uneven tone, faint redness around nose and cheeks, soft under-eye shadows and realistic skin texture. Compact oval-heart face, high open forehead, smooth rounded skull contour, soft cheeks, narrow soft jaw and small rounded chin.
DARK BROWN almond-shaped eyes, slightly narrowed, compactly spaced, steady direct gaze, heavier upper lids, faint lower-lid shadow, dark eyelash line and subtly lifted outer corners. Dark clean arched brows sit close to the eyes and strongly contrast against PLATINUM BLONDE BUZZ CUT hair.
Small straight nose with short neat bridge, soft rounded tip and moderate nostril width. Medium closed mouth with finer upper lip, fuller lower lip, shallow cupid’s bow, natural lip texture and neutral mouth corners. PLATINUM BLONDE BUZZ CUT with ultra-short even pale blonde stubble texture and rounded close-cropped silhouette.
DENSE BLACK LINEWORK TATTOO COVERAGE on neck, shoulders, arms, torso, abdomen and thighs, botanical, ornamental and symbolic black motifs with healed softened edges. White cropped athletic top and high-waisted white fitted athletic shorts, minimal sporty styling, clean cotton-like texture and close practical fit. Calm direct presence, relaxed shoulders, collected slightly angular posture and raw photographic realism.
Photorealistic adult woman in her mid-20s with slim compact lightly athletic body, fair warm-neutral skin, compact oval-heart face, high open forehead, DARK BROWN slightly narrowed almond-shaped eyes, dark arched brows, small straight nose with soft rounded tip, medium closed mouth, narrow soft jaw, small rounded chin, PLATINUM BLONDE BUZZ CUT and DENSE BLACK LINEWORK TATTOO COVERAGE across neck, arms, torso, abdomen and thighs. She wears a white cropped athletic top and high-waisted white fitted athletic shorts, with calm direct presence and slightly angular body language.
Demo: She begins in a still upright stance, shifts her weight slightly, lets one hand rest near her side, blinks slowly, turns her head a little toward the camera and holds a steady calm gaze.
Photorealistic cinematic adult woman in her mid-20s with slim compact lightly athletic proportions, fair warm-neutral skin, visible pores, slight uneven tone, compact oval-heart face, high open forehead, smooth cheeks, narrow soft jaw and small rounded chin. DARK BROWN almond-shaped eyes, slightly narrowed, steady direct gaze, heavier upper lids, dark arched brows, small straight nose with soft rounded tip and medium closed mouth.
PLATINUM BLONDE BUZZ CUT, ultra-short even pale blonde stubble texture, close-cropped rounded silhouette and fully open forehead. DENSE BLACK LINEWORK TATTOO COVERAGE across the neck, shoulders, arms, torso, abdomen and thighs, with botanical, ornamental and symbolic black ink motifs. White cropped athletic top and high-waisted white fitted athletic shorts, minimal sporty styling and clean close fit.
Demo: She stands with relaxed shoulders, turns her head slowly in a measured arc, the short pale hair catches a subtle shift of light, then she stills into a direct calm gaze.
Photorealistic adult woman in her mid-20s with a slim compact lightly athletic body, compact oval-heart face, high open forehead, DARK BROWN slightly narrowed almond-shaped eyes, dark arched brows, small straight nose with soft rounded tip, medium closed mouth, narrow soft jaw, small rounded chin, PLATINUM BLONDE BUZZ CUT, fair warm-neutral skin and DENSE BLACK LINEWORK TATTOO COVERAGE on neck, arms, torso and thighs. White cropped athletic top and high-waisted white fitted athletic shorts, calm direct expression and slightly angular posture.
Demo: She makes one short weight shift, gives a quick controlled head turn and fixes the camera with a steady calm gaze.
Create a photorealistic adult woman in her mid-20s with a slim compact lightly athletic build, fair warm-neutral skin, visible pores, slight warm golden undertone, faint redness around the nose and upper cheeks, soft under-eye shadows, small scattered natural skin marks, fine delicate hairs on arms and legs, subtle skin compression at the wrists, elbows, waistline and knees, and realistic color variation between face, arms, abdomen and legs.
Her face is compact oval-heart with a high open forehead, smooth rounded skull contour, soft temples, moderate cheekbones, smooth full cheeks, short middle face, narrow soft lower jaw, small rounded chin and slight natural asymmetry.
She has DARK BROWN almond-shaped eyes that are slightly narrowed and compactly spaced, with a steady direct gaze, heavier upper eyelid line, softly defined upper lids, faint lower-lid shadow, dark eyelash line and subtly lifted outer corners. Her expression is calm and focused.
Her brows are dark, medium-thick, cleanly shaped and arched, with a defined outer tail and strong contrast against her pale hair.
Her nose is small and straight, with a short neat bridge, narrow-to-moderate nasal dorsum, soft rounded tip and moderate nostril width.
Her mouth is medium-width with a finer upper lip, fuller lower lip, shallow cupid’s bow, calm closed-mouth line, natural lip texture and neutral mouth corners.
Her hair is a PLATINUM BLONDE BUZZ CUT: ultra-short even length, close-cropped rounded head silhouette, pale blonde tone with slight warm beige variation, dense fine stubble-like texture, clean visible hairline and fully open forehead.
She has DENSE BLACK LINEWORK TATTOO COVERAGE across the neck, shoulders, arms, torso, abdomen and thighs, using thin black botanical stems, ornamental shapes, symbolic small motifs and airy asymmetric compositions with medium-to-high visual density and softened healed black ink edges.
She wears a simple white cropped athletic top with broad straps, close fit, minimal seams and soft ribbed cotton-like texture, plus high-waisted white fitted athletic shorts with a simple waistband, clean sporty look and close practical fit. Her posture is collected, relaxed and slightly angular, with calm direct presence and raw photographic realism.
Рекомендуемые параметры: --style raw --stylize 10-15 --chaos 0
Photorealistic adult woman in her mid-20s, slim compact lightly athletic build, fair warm-neutral skin, visible pores, slight uneven skin tone, soft under-eye shadows, compact oval-heart face, high open forehead, smooth rounded skull contour, soft full cheeks, narrow soft jaw, small rounded chin, DARK BROWN almond-shaped eyes, slightly narrowed eyes, heavier upper eyelids, steady direct gaze, dark medium-thick arched brows, small straight nose, short neat bridge, soft rounded nose tip, medium closed mouth, finer upper lip, fuller lower lip, neutral mouth corners, PLATINUM BLONDE BUZZ CUT, ultra-short even pale blonde stubble texture, fully open forehead, DENSE BLACK LINEWORK TATTOO COVERAGE across neck shoulders arms torso abdomen thighs, botanical ornamental symbolic black ink motifs, healed tattoo edges, white cropped athletic top, high-waisted white fitted athletic shorts, collected slightly angular posture, calm direct expression, raw photographic realism, tactile skin texture
Photorealistic adult woman in her mid-20s with fair warm-neutral skin, visible pores, slight golden undertone, faint redness around the nose and upper cheeks, soft under-eye shadows, small scattered natural skin marks, subtle natural texture on the abdomen and thighs, fine delicate hairs on arms and legs, slight dryness on knuckles, elbows and knees, and realistic contact shadows around lips, neck, fingers, waistband and joints.
Slim compact lightly athletic body with narrow-to-medium shoulders, long slim neck, defined collarbone area, compact upper torso, narrow waist, toned abdomen, slim arms, delicate wrists, long narrow hands, lean hips, firm upper thighs, slim legs and defined knees.
Compact oval-heart face with high open forehead, smooth rounded skull contour, soft temples, moderate cheekbones, smooth full cheeks, short middle face, narrow soft lower jaw, small rounded chin and slight natural facial asymmetry. DARK BROWN almond-shaped eyes, slightly narrowed, compactly spaced, steady direct gaze, heavier upper lids, faint lower-lid shadow, dark eyelash line and subtly lifted outer corners.
Dark medium-thick arched brows sit close to the eyes, with a defined outer tail and strong contrast against pale hair. Small straight nose with short neat bridge, narrow-to-moderate dorsum, soft rounded tip and moderate nostril width. Medium closed mouth with finer upper lip, fuller lower lip, shallow cupid’s bow, natural lip texture and neutral mouth corners.
PLATINUM BLONDE BUZZ CUT, ultra-short even length, pale warm-beige blonde tone, close-cropped rounded silhouette, dense fine stubble-like texture, clean visible hairline and fully open forehead. DENSE BLACK LINEWORK TATTOO COVERAGE across the neck, shoulders, arms, torso, abdomen and thighs, thin black lines, botanical stems, ornamental shapes, symbolic small motifs, airy asymmetric compositions, varied scale and healed softened black ink edges.
White cropped athletic top with broad straps, close fit, minimal seams and soft ribbed cotton-like texture; high-waisted white fitted athletic shorts with a simple waistband, close practical fit and clean sporty minimalism. Calm direct presence, relaxed shoulders, collected slightly angular body language and raw photographic realism.
Photorealistic adult woman in her mid-20s with slim compact lightly athletic proportions, fair warm-neutral skin, compact oval-heart face, high open forehead, DARK BROWN slightly narrowed almond-shaped eyes, heavier upper lids, dark arched brows, small straight nose with soft rounded tip, medium closed mouth with finer upper lip and fuller lower lip, narrow soft jaw, small rounded chin and PLATINUM BLONDE BUZZ CUT.
She has DENSE BLACK LINEWORK TATTOO COVERAGE on the neck, shoulders, arms, torso, abdomen and thighs, with botanical, ornamental and symbolic black motifs and softened healed edges. She wears a white cropped athletic top and high-waisted white fitted athletic shorts. Calm direct expression, collected slightly angular posture, visible skin texture and raw photographic realism.
low quality, blurry, over-sharpened, noisy image, bad crop, distorted perspective, flat lighting, waxy highlights, watermark, text, logo, frame, compression artifacts, broken anatomy, extra fingers, fused fingers, missing fingers, distorted hands, twisted limbs, incorrect joints, warped torso, uneven shoulders, distorted waist, uneven eyes, crossed eyes, glassy eyes, wrong eye color, wide round eyes, overly open eyes, wrong brow shape, thin pale brows, wrong face shape, elongated face, square jaw, heavy chin, oversized chin, hollow cheeks, wrong nose shape, long sharp nose, wide nose, upturned nose, overfilled lips, huge smile, exposed teeth, wrong mouth shape, wrong hair color, long hair, soft glamorous hairstyle, helmet-like hair, missing PLATINUM BLONDE BUZZ CUT, missing open forehead, wrong body type, overly curvy body, overly muscular body, elongated fashion-model proportions, missing compact athletic build, missing narrow waist, missing slim arms, missing tattoo coverage, colorful tattoos, oversized copied tattoo design, missing black linework tattoos, plastic skin, porcelain skin, over-smoothed skin, missing pores, missing skin tone variation, missing healed tattoo edges, CGI look, cartoon style, anime style, doll-like face, generic influencer face, beauty filter face, age drift, identity drift, direct real person replica, celebrity likeness, public figure likeness
СЦЕНА
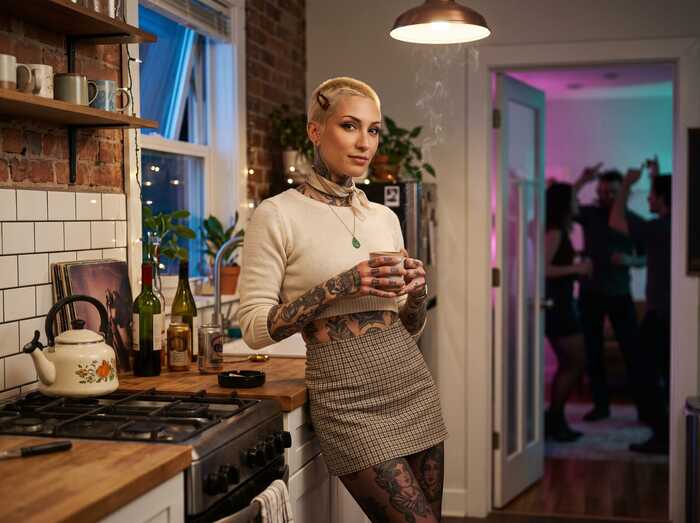
CHARACTER taking a quiet break in the kitchen during a hipster house party, realistic cozy cinematic editorial portrait, stylish lived-in apartment kitchen, exposed brick wall section, white subway tiles with dark grout, open wooden shelves with mismatched ceramic mugs, vintage enamel kettle on the stove, indoor plants in clay pots, fairy lights along the upper cabinets, vinyl record sleeves leaning on a shelf, half-empty wine bottles and craft beer cans on the wooden countertop, an ashtray with a smoldering cigarette, a steaming mug of tea, slightly open window with cold night air, sheer curtain moving gently, muffled music and warm light spilling from the living room through a half-open doorway, silhouettes of dancing guests visible in the background blur, CHARACTER leaning against the countertop and holding a ceramic mug with both hands, thin curl of cigarette smoke rising near the face, warm tungsten kitchen light from a pendant lamp above, cool blue night light from the window, magenta and teal party light spilling through the doorway, soft steam from the kettle catching the light, reflections on tiles and glass bottles, intimate late-night atmosphere, warm amber, deep teal, soft magenta, cream and brick red palette, shallow depth of field, stylish hipster domestic mood, realistic skin texture, natural hair flyaways, fine film grain
CHARACTER 1 leaning against the kitchen countertop and holding a steaming ceramic mug, CHARACTER 2 sitting on the windowsill with a cigarette and a glass of wine, taking a quiet break during a hipster house party, realistic cozy cinematic editorial double portrait, stylish lived-in apartment kitchen, exposed brick, subway tiles, open wooden shelves with mismatched mugs, vintage enamel kettle, indoor plants, fairy lights along cabinets, vinyl sleeves on a shelf, wine bottles and craft beer cans on the wooden counter, ashtray with smoldering cigarette, slightly open window, sheer curtain moving in the night air, muffled music and warm light spilling from the living room through a half-open doorway, soft silhouettes of dancing guests blurred in the background, both characters in a relaxed intimate conversation, one turned toward the other, soft cigarette smoke and tea steam drifting between them, warm tungsten pendant light above, cool blue night light from the window, magenta and teal party light from the doorway, gentle reflections on tiles and bottles, late-night intimate atmosphere, warm amber, deep teal, soft magenta, cream and brick red palette, shallow depth of field, stylish hipster domestic mood, realistic skin texture, natural hair flyaways, fine film grain
CHARACTER 1 leaning against the kitchen countertop with a steaming ceramic mug, CHARACTER 2 sitting on the windowsill with a cigarette and a glass of wine, CHARACTER 3 standing near the stove and pouring hot water from a vintage enamel kettle into a teapot, taking a quiet break during a hipster house party, realistic cozy cinematic editorial group portrait, stylish lived-in apartment kitchen, exposed brick wall, subway tiles, open wooden shelves with mismatched ceramic mugs, indoor plants in clay pots, fairy lights along cabinets, vinyl record sleeves on a shelf, wine bottles and craft beer cans scattered on the wooden countertop, ashtray with a smoldering cigarette, slightly open window letting in cold night air, sheer curtain moving softly, muffled music and warm light spilling from the living room through a half-open doorway, soft silhouettes of dancing guests blurred in the background, all three characters relaxed and quietly interacting, gentle eye contact, soft cigarette smoke and tea steam drifting through the room, warm tungsten pendant light overhead, cool blue night light from the window, magenta and teal party light spilling through the doorway, reflections on tiles, bottles and ceramic surfaces, intimate late-night kitchen atmosphere, warm amber, deep teal, soft magenta, cream and brick red palette, shallow depth of field, stylish hipster domestic mood, realistic skin texture, natural hair flyaways, fine film grain
CHARACTER / CHARACTERS taking a quiet smoke and tea break in a stylish hipster apartment kitchen during a house party, exposed brick, subway tiles, fairy lights, wine bottles, enamel kettle, party light spilling from the living room, warm tungsten and cool window light, intimate late-night atmosphere
dressed in feminine hipster party styling: a fitted black slip dress with thin straps, an oversized vintage denim jacket slipping off one shoulder, sheer black tights, chunky black leather boots, layered thin gold necklaces, small hoop earrings, stacked rings, dark red lipstick, and slightly messy hair with face-framing strands
dressed in soft feminine indie styling: a cropped cream knit sweater, a high-waisted plaid mini skirt, sheer dark tights, retro leather loafers, a thin silk scarf tied loosely around the neck, tortoiseshell hair clips, tiny gold studs, a slim wristwatch, and natural makeup with a soft flushed cheek
dressed in relaxed feminine creative styling: a loose oversized vintage band t-shirt tucked into high-waisted wide-leg corduroy trousers in warm caramel, a thin leather belt, white canvas sneakers, layered silver necklaces, a stack of beaded bracelets, small silver hoops, and a low messy bun with loose strands around the face
Кажется, все алгоритмы отладил, ГПТ где надо помогает, где не надо не мешает. Признаки уже структурирую без словаря :)
Вот и еще один типаж, правда не очень типичный, из 90-х вытащил. И да, я понимаю, что там бегают скучающие люди с говнометами и клоунскими смайлами, но те, кто все же попробует что-то с ней сгенерить — киньте пару картинок в комменты :) Посмотрю на взгляд со стороны. На всякий случай уточняю: там все разбито на блоки. Отдельно голова, тело, одежда. Цвета и возраст выделены кэпсами, чтобы можно было менять. Важно — если генератор не принимает базовый промпт, только тогда и надо пользоваться адаптациями. Они, все-таки, кастрированные слегка.

RG1 — Rosaly
Тег: [RGL]
Темноволосая гламурная модель с крупными тёмно-янтарно-карими миндалевидными глазами, тонкими дугообразными бровями в эстетике 1990-х, узким овально-сердцевидным лицом, маленьким прямым носом, мягко очерченными скулами и полными глянцевыми розово-коричневыми губами. Её образ сочетает гламурную уверенность, спокойную взрослую интенсивность взгляда, винтажную журнальную роскошь и мягкую тропическую женственность.
photorealistic full-body fashion portrait of an adult woman in her mid-20s, original high-fashion resort-glamour archetype, not a real person likeness, warm tan olive-beige skin with golden undertone, realistic adult skin texture, visible natural pores, mild natural unevenness, subtle tiny freckles and skin speckles, soft peach-rose blush, warm bronzed satin-glow complexion
large DARK AMBER-BROWN almond-shaped eyes with warm golden highlights, slightly upturned outer corners, softly hooded upper eyelids, sharp dark inner eye corners, balanced eye spacing, long dark lashes, smoky black kohl eyeliner along upper and lower lash lines, soft taupe-brown eyeshadow, calm direct intense gaze, thin arched dark brown 1990s brows with high tapered arches, delicately plucked eyebrow shape, soft inner brow start and narrow extended tail
narrow oval-heart face, high smooth forehead, softly rounded forehead plane, natural uneven hairline with fine baby hairs at the temples, softly defined cheekbones, smooth adult cheek volume, subtle cheek hollow beneath the cheekbone plane, small straight narrow nose with a slim bridge and soft rounded nasal tip, narrow nostril base, small oval nostrils, narrow tapered jawline, soft V-shaped lower face, small pointed-soft chin, full glossy rose-brown lips, plump rounded lower lip with bright central gloss highlight, soft defined Cupid’s bow, medium-width mouth, short-to-medium philtrum, slightly parted relaxed lips, subtle natural facial asymmetry
medium-height balanced adult fashion build, graceful neck, defined collarbones, natural shoulders, elegant arms and hands, softly defined waist, balanced hips, long clean leg line, poised upright editorial posture, composed adult presence, realistic full-body proportions, controlled refined movement, warm tan body skin with natural texture and subtle tonal variation
long BLACK-BROWN hair with subtle dark chestnut highlights, thick voluminous loose glamour waves, slightly tousled 1990s texture, soft center or off-center part, face-framing strands, natural flyaways, fine baby hairs near the temples, glossy dark strands catching light, hair creating a strong dark frame around the warm face
bright yellow floral resort wrap mini dress with pink rose prints and green leaf details, lightweight summer fabric, structured fitted bodice, soft sweetheart-inspired neckline, fitted waist, wrapped skirt panels, realistic fabric folds, vivid expensive summery floral print, white open-knit tall stockings worn as restrained vintage fashion details, clean editorial styling
1990s glamour makeup, smoky kohl eyes, thin arched brows, warm bronzer, peach-rose blush, glossy rose-brown lips, high-end resort magazine mood, cinematic photorealism, crisp high-fashion detail, natural adult beauty, sophisticated glamour, calm confident editorial presence

photorealistic close portrait of an adult woman in her mid-20s, original resort-glamour archetype, not a real person likeness, warm tan olive-beige skin with golden undertone, realistic pores, mild natural unevenness, subtle tiny freckles, warm bronzed satin-glow complexion, peach-rose blush
large DARK AMBER-BROWN almond-shaped eyes with warm golden highlights, slightly upturned outer corners, softly hooded upper lids, sharp dark inner corners, long dark lashes, smoky black kohl eyeliner, soft taupe-brown eyeshadow, calm direct intense gaze, thin arched dark brown 1990s brows with high tapered arches and narrow extended tails
narrow oval-heart face, high smooth forehead, natural uneven hairline with baby hairs at the temples, small straight narrow nose with slim bridge and soft rounded tip, softly defined cheekbones, narrow tapered jawline, small pointed-soft chin, full glossy rose-brown lips with plump rounded lower lip, soft Cupid’s bow, slightly parted relaxed lips, subtle natural asymmetry
long BLACK-BROWN hair with subtle dark chestnut highlights, voluminous loose glamour waves, slightly tousled texture, face-framing strands, soft center or off-center part, glossy hair detail, 1990s glamour makeup, quiet confident editorial presence, sharp facial focus, head-and-upper-body framing
photorealistic adult woman in her mid-20s, original resort-glamour archetype, warm tan olive-beige skin, long BLACK-BROWN voluminous hair, large DARK AMBER-BROWN almond eyes, thin arched 1990s brows, narrow oval-heart face, high smooth forehead, small straight narrow nose, softly defined cheekbones, tapered jawline, small pointed-soft chin, full glossy rose-brown lips, warm bronzed glamour makeup, bright yellow floral resort wrap mini dress, white open-knit tall stockings, calm confident editorial expression
photorealistic full-body adult woman in her mid-20s, original resort-glamour fashion archetype, not a real person likeness, warm tan olive-beige skin with golden undertone, realistic pores and natural texture
large DARK AMBER-BROWN almond eyes with slight upward tilt, softly hooded lids, smoky kohl eyeliner, long dark lashes, thin arched dark brown 1990s brows, narrow oval-heart face, high smooth forehead, small straight narrow nose, softly defined cheekbones, tapered jawline, small pointed-soft chin, full glossy rose-brown lips with plump lower lip
balanced adult fashion build, graceful neck, defined collarbones, poised upright posture, natural full-body proportions, warm tan skin with subtle tonal variation, controlled elegant movement
long BLACK-BROWN voluminous hair with dark chestnut highlights, loose glamour waves, face-framing strands and natural flyaways
bright yellow floral resort wrap mini dress with pink rose print, structured fitted bodice, wrapped skirt panels, white open-knit tall stockings as vintage fashion detail, 1990s bronzed glamour makeup, calm confident editorial presence
photorealistic adult woman, full-body fashion presentation, mid-20s, original resort-glamour archetype, not a real person likeness, warm tan olive-beige skin with natural texture and golden undertone
large DARK AMBER-BROWN almond eyes, slightly upturned, smoky kohl eyeliner, thin arched 1990s brows, narrow oval-heart face, high smooth forehead, refined small straight nose, soft cheekbones, narrow jawline, small pointed-soft chin, full glossy rose-brown lips, calm direct expression
balanced adult figure, graceful neck, natural shoulders, poised editorial stance, realistic full-body proportions, clean adult styling
long BLACK-BROWN wavy hair with subtle chestnut highlights, soft movement, face-framing strands
bright yellow floral resort wrap mini dress, pink rose print, white open-knit tall stockings, warm bronzed 1990s glamour makeup, realistic high-fashion photography
photorealistic adult woman, full-body video portrait, mid-20s, original resort-glamour fashion archetype, not a real person likeness, warm tan olive-beige skin with natural texture and golden undertone
large DARK AMBER-BROWN almond eyes, slightly upturned, smoky kohl eyeliner, thin arched 1990s brows, narrow oval-heart face, high smooth forehead, small straight nose, soft cheekbones, tapered jawline, small pointed-soft chin, full glossy rose-brown lips, calm direct gaze
balanced adult fashion build, graceful neck, poised posture, realistic proportions, long BLACK-BROWN wavy hair with subtle chestnut highlights and soft natural movement
bright yellow floral resort wrap mini dress, pink rose print, white open-knit tall stockings, warm bronzed 1990s glamour makeup, clean editorial realism
Demo: in a six-second fashion beat, she takes one slow measured step forward, pauses with controlled resort-glamour poise, turns her shoulders slightly into a three-quarter angle, brushes one face-framing strand away from her cheek, and finishes with a calm direct amber-brown gaze into the camera
photorealistic full-body adult woman in her mid-20s, original resort-glamour archetype, not a real person likeness, warm tan olive-beige skin with realistic texture, subtle pores and golden undertone
large DARK AMBER-BROWN almond eyes with a slight upward tilt, smoky kohl eyeliner, long dark lashes, thin arched dark brown 1990s brows, narrow oval-heart face, high smooth forehead, small straight narrow nose, softly defined cheekbones, tapered jawline, small pointed-soft chin, full glossy rose-brown lips
balanced adult fashion proportions, graceful neck, defined collarbones, poised upright posture, calm confident editorial presence
long BLACK-BROWN loose wavy hair with subtle chestnut highlights, natural flyaways, face-framing movement
bright yellow floral resort wrap mini dress with pink rose print, white open-knit tall stockings as vintage fashion styling, warm bronzed 1990s makeup, cinematic realism, soft atmospheric depth
Demo: in an eight-second cinematic mood beat, she stands still in warm resort light as her black-brown waves move softly, slowly turns her face toward the brighter side of the frame, lets one hand settle at her waist, breathes into a quiet poised pause, and holds a polished magazine-like gaze
photorealistic adult person, full-body character presentation, woman in her mid-20s, original resort-glamour archetype, not a real person likeness, warm tan olive-beige skin with natural texture
large DARK AMBER-BROWN almond eyes, calm and slightly upturned, smoky eyeliner, thin arched brows, narrow oval-heart face, small straight nose, soft cheekbones, tapered jawline, full glossy rose-brown lips, composed neutral expression
balanced adult proportions, graceful neck, poised stance, realistic full-body clarity, long BLACK-BROWN wavy hair with soft natural movement
bright yellow floral resort wrap mini dress, white open-knit tall stockings, warm bronzed glamour makeup, clean realistic fashion-photo look
Demo: in a two-second iconic identity beat, she makes a small controlled head turn toward camera, one dark wave shifts beside her cheek, and her calm amber-brown gaze locks into a still editorial pose
A photorealistic full-length fashion portrait of an adult woman in her mid-20s, designed as an original resort-glamour archetype rather than a real person likeness. She has warm tan olive-beige skin with a golden undertone, visible natural pores, mild realistic unevenness, subtle tiny freckles and skin speckles, peach-rose blush, and a warm bronzed satin-glow complexion.
She has large DARK AMBER-BROWN almond-shaped eyes with warm golden highlights, slightly upturned outer corners, softly hooded upper eyelids, sharp dark inner eye corners, long dark lashes, smoky black kohl eyeliner, soft taupe-brown eyeshadow, and a calm direct intense gaze. Her eyebrows are thin, arched, dark brown, and distinctly 1990s in shape, with high tapered arches and narrow extended tails.
Her face is narrow oval-heart shaped, with a high smooth forehead, a natural uneven hairline, fine baby hairs at the temples, softly defined cheekbones, a small straight narrow nose with a slim bridge and soft rounded tip, a narrow tapered jawline, a small pointed-soft chin, and full glossy rose-brown lips with a plump rounded lower lip, a soft Cupid’s bow, and a slightly parted relaxed expression.
Her body has balanced adult fashion proportions, a graceful neck, defined collarbones, natural shoulders, elegant arms and hands, a softly defined waist, balanced hips, and a poised upright editorial stance. Her skin has realistic texture and subtle tonal variation.
She has long BLACK-BROWN hair with subtle dark chestnut highlights, styled in thick voluminous loose glamour waves with a soft center or off-center part, face-framing strands, natural flyaways, and glossy realistic strand detail.
She wears a bright yellow floral resort wrap mini dress with pink rose prints and green leaf details, lightweight summer fabric, a structured fitted bodice, a soft sweetheart-inspired neckline, a fitted waist, wrapped skirt panels, realistic fabric folds, and white open-knit tall stockings as a restrained vintage fashion detail. The overall mood is high-end 1990s bronzed glamour, crisp photorealistic fashion detail, natural adult beauty, and sophisticated resort-magazine elegance.
Рекомендуемые параметры / Recommended parameters: --style raw --stylize 10-15 --chaos 0
photorealistic full-body adult woman, mid-20s, original resort-glamour fashion archetype, not a real person likeness, warm tan olive-beige skin, golden undertone, realistic pores, long BLACK-BROWN voluminous wavy hair, dark chestnut highlights, large DARK AMBER-BROWN almond eyes, slightly upturned eyes, smoky kohl eyeliner, thin arched dark brown 1990s brows, narrow oval-heart face, high smooth forehead, small straight narrow nose, soft cheekbones, tapered jawline, small pointed-soft chin, full glossy rose-brown lips, plump lower lip, warm bronzed glamour makeup, balanced adult fashion build, poised editorial posture, bright yellow floral resort wrap mini dress, pink rose print, white open-knit tall stockings, raw photographic realism, high-fashion editorial portrait
photorealistic full-body fashion portrait of an adult woman in her mid-20s, original resort-glamour archetype, not a real person likeness, warm tan olive-beige skin with golden undertone, realistic pores, mild natural unevenness, subtle freckles, peach-rose blush, warm bronzed satin-glow complexion
large DARK AMBER-BROWN almond-shaped eyes with warm highlights, slightly upturned outer corners, softly hooded lids, sharp dark inner corners, long dark lashes, smoky black kohl eyeliner, thin arched dark brown 1990s brows with tapered arches, calm direct gaze
narrow oval-heart face, high smooth forehead, natural uneven hairline with baby hairs, softly defined cheekbones, small straight narrow nose with slim bridge and rounded tip, narrow tapered jawline, small pointed-soft chin, full glossy rose-brown lips, plump rounded lower lip, soft Cupid’s bow, slightly parted relaxed lips, subtle natural asymmetry
balanced adult fashion build, graceful neck, defined collarbones, natural shoulders, elegant hands, softly defined waist, balanced hips, poised upright editorial posture, realistic full-body proportions and warm tan skin texture
long BLACK-BROWN hair with subtle dark chestnut highlights, thick loose glamour waves, slightly tousled 1990s texture, face-framing strands, natural flyaways, glossy realistic hair detail
bright yellow floral resort wrap mini dress with pink rose prints and green leaf details, lightweight summer fabric, structured fitted bodice, wrapped skirt panels, realistic fabric folds, white open-knit tall stockings as restrained vintage fashion detail, high-fashion photorealism
photorealistic full-body adult woman in her mid-20s, original resort-glamour fashion look, not a real person likeness, warm tan olive-beige skin with natural texture
large DARK AMBER-BROWN almond eyes with slight upward tilt, smoky eyeliner, thin arched 1990s brows, narrow oval-heart face, high smooth forehead, small straight nose, soft cheekbones, tapered jawline, small pointed-soft chin, full glossy rose-brown lips
balanced adult figure, graceful neck, poised editorial posture, long BLACK-BROWN wavy hair with subtle chestnut highlights and face-framing strands
bright yellow floral resort wrap mini dress, white open-knit tall stockings, warm bronzed glamour makeup, clean realistic fashion-photo look
blurry, deformed, low quality, artifacts, text, watermark, website logo, signature, overexposed, underexposed, extra limbs, missing limbs, fused fingers, mutated hands, bad anatomy, distorted face, extra heads, cropped head, out of frame, low resolution, cartoon, illustration, painting, 3d render, CGI look, plastic skin, wax skin, doll face, doll eyes, generic Instagram face, laminated brows, overfilled lips, unnatural skin tone, harsh flat lighting, noisy, grainy, jpeg artifacts, extreme facial asymmetry, crossed eyes, dead eyes, distorted mouth, broken teeth, aged face, childlike features, teen-coded appearance, wardrobe malfunction, pornographic framing, adult-site context, exact real person likeness, celebrity name, identity match



А "Большую книгу промптов" я на Бусти уже выложил, только пока подссыкаю обнародовать. Ведь точно что-нибудь забыл.
А пока я тут вовсю настраиваю Бусти, работа над новыми промптами продолжает кипеть. И сегодня мне вдруг подумалось, что можно сделать довольно интересный архетип: собрать воедино штампы антигероев 80-х. Не благородных качков с черно-белыми ориентирами, а кого-то менее однозначного и более морально гибкого. Всё по той же блочной системе.
Короче, сам не ожидал, что получится прям такой красавец :D

Тест в Nano Banana
photorealistic full-body portrait of an adult man in his mid 30s of European American descent
long rectangular face with strong cheekbones, heavy square jaw, prominent cleft chin, broad forehead, thick dark brows, deep-set HAZEL-BROWN eyes with a skeptical squint, asymmetric expressive eyelids, straight medium-length nose with a firm bridge and slightly blunt tip, wide mouth with uneven smirk, fuller lower lip, tense smile lines, rugged facial asymmetry, faint under-eye shadows, realistic pores and lightly weathered skin texture
tall sturdy athletic frame, broad chest, thick neck, wide shoulders, solid upper torso, straight waist, strong hips, long legs with practical muscularity, firm knees, sturdy calves, strong ankles, long arms, large hands with visible knuckles, slightly theatrical upright stance with a hint of swagger, fair-to-light olive skin with visible pores, faint sun damage, small scars or marks, redness around nose and cheeks, natural texture on neck and hands
thick DARK BROWN hair, short-to-medium length, swept back with a slightly messy wave, dense side volume, natural uneven hairline, subtle shine, imperfect flyaway strands
confident wary expression, dry comic intensity, rugged adventure-hero presence, expressive but not polished, realistic photographic lighting, no plastic skin, no superhero exaggeration, no artificial perfection
photorealistic close portrait of an adult man in his mid 30s of European American descent
long rectangular face, strong cheekbones, heavy square jaw, prominent cleft chin, broad forehead, thick dark brows, deep-set HAZEL-BROWN eyes with skeptical squint, asymmetric expressive eyelids, straight medium-length nose with firm bridge and blunt tip, wide mouth with uneven smirk, fuller lower lip, tense smile lines, rugged facial asymmetry and faint under-eye shadows
thick neck, wide shoulders, solid upper frame, slightly theatrical upright posture, fair-to-light olive skin with visible pores, faint sun damage, redness around nose and cheeks, small marks and natural texture on neck and hands
thick DARK BROWN hair, short-to-medium length, swept back with messy wave, dense side volume, uneven hairline and flyaway strands
confident wary expression, dry comic intensity, rugged adventure-hero presence, natural photographic realism
photorealistic adult man in his mid 30s of European American descent, tall sturdy athletic frame, thick neck, wide shoulders, large hands, fair-to-light olive skin, thick DARK BROWN swept-back messy hair, long rectangular face, heavy square jaw, prominent cleft chin, thick dark brows, deep-set HAZEL-BROWN eyes with skeptical squint, straight blunt-tipped nose, wide uneven smirk, rugged comic adventure-hero presence


После давней (удалил уже) попытки создать хаотичные архетипы, зацепился за идею максимального реализма в ИИ. Да так, что не вылезал из экспериментов несколько месяцев. Зато, наконец, допилил первый том «Большой книги промптов». Остапа понесло, и сделал я аж 75 архетипов женщин — изначально под вдохновением от любимых актрис, потом уже специально, подбирая разные и разнообразные особенности и комбинируя черты. Во, образец покажу (попозже выложу ссылку на Бусти, готовьте смайлики с клоунами и минусы, ага).
А пока можно попробовать сгенерировать :) Кэпсами выделил цвет глаз и волос, можно менять. Возраст тоже (выделил жирным). Да там в принципе все можно менять, в том числе между моделями. Считаю достижением :)
EU6 — Jess
(40+)
photorealistic full-body portrait of an adult woman in her mid 40s of Caucasian American descent
large expressive piercing LIGHT HAZEL-GREEN eyes with an intense haunted direct gaze set moderately wide apart with subtle natural surrounding lines, high sculpted cheekbones with gentle mid-face fullness, high broad forehead, straight refined nose of average width with a slightly petite pointed tip and smooth bridge, full naturally defined lips with a clear cupid's bow and natural volume, strong jawline with a subtle cleft chin and elegant bone structure carrying a slight masculine touch, soft inverted triangle to oval face shape with a broader forehead gently tapering to a delicate yet defined chin and clean jawline with subtle softness and rounded contours, medium-set slightly arched eyebrows, natural even teeth alignment, subtle natural facial asymmetry
slender athletic build around 5'4", long elegant neck, toned but lean frame, refined shoulders, sculpted collarbone area, proportionate bust, softly defined waist, lean hips, long shapely legs, graceful arms, poised upright posture with controlled intensity, fair radiant porcelain skin with subtle visible pores and faint natural texture especially on neck and décolleté, occasional light solar lentigines and faint telangiectasia typical of a well-maintained mid-forties complexion, realistic mature-yet-youthful anatomy and natural body individuality
STRAWBERRY BLONDE to VIBRANT RED shoulder-length hair, often styled in soft waves or sleek straight lines, natural flyaways, dry texture, uneven strand thickness, light porosity
dramatic mature beauty, intelligent composure, restrained sensuality, powerful feminine presence, realistic full-body presentation
AF1 — Zen
(20+)
photorealistic full-body adult woman in her 20s of African American descent with mixed European heritage
large hooded almond-shaped DEEP BROWN eyes with a soft reflective catchlight, slight upturn at the outer corners, calm direct intense gaze, high prominent angular cheekbones, compact vertical face proportions, naturally full lips with a defined cupid's bow, small straight refined nose with a narrow bridge and delicate pointed tip, softly angular jawline, arched full eyebrows, natural facial asymmetry, smooth realistic facial skin with visible pores and subtle tonal variation
tall slender build around 177 cm with long elegant limbs, narrow but not fragile shoulders, long graceful neck, defined collarbones, lean upper arms, softly elongated torso, lightly drawn waist, straight balanced hips, long toned thighs, fine knees, slim calves, elegant hands and ankles, medium brown body skin with natural texture, restrained tonal shifts, a few subtle beauty marks, faint natural variation at elbows and knees, poised upright posture with fluid controlled movement and quiet runway-like balance
DARK BROWN hair, very long, voluminous loose waves with natural lift, soft movement, light flyaways, varied strand thickness and slight porosity
calm regal presence, graceful confidence, noble verticality, editorial realism, soft cinematic depth, minimal contrast shaping, very subtle teal-orange grade
Бонус — два уличных образа
(просто добавляешь после промпта персонажа):
dressed in a BLACK thick rib-knit beanie with wide cuff, BLACK oversized hoodie with kangaroo pocket, LIGHT BLUE high-waisted short denim shorts with frayed hem and contrast orange-yellow stitching, BLACK thigh-high suede-like pull-on boots
dressed in a BLACK sheer mesh long-sleeve top with high knit choker neckband, BLACK cropped satin vest with three buttons, BLACK straight-leg trousers with thin leather-like belt and silver buckle, BLACK and WHITE low-top canvas sneakers
Вот какие результаты получаются с этими промптами (никаких референсов, только текст):




Если формат зайдёт — могу выложить на тест полный мини-пак (3 архетипа + портретные + групповые версии + адаптации под все генераторы + три демо-сцены + 3 костюма). А если нет — давайте ваших клоунов.
Но вообще буду очень рад вашим генерациям и отзывам в комментариях. Вдруг получится в кои-то веки получить нормальные отзывы :)


