

Двадцать, тридцать, девятьсот
Продолжаю отвечать на вопрос @RainbowDysch о числительных (см. первую часть). Сегодня мы поговорим о русских названиях десятков и сотен.

Для начала нужно сказать, что числительные первого десятка в праиндоевропейском языке вели себя по-разному. Самые древние, 1–4, как прилагательные, они согласовывались с существительным по числу и роду (в современном русском разные формы родов есть только у 1 и 2, но раньше были также у 3 и 4). Более новые, 5–10, по происхождению сами были существительными и после них зависимое слово ставилось в родительный падеж множественного числа (это называется управление). Эта же схема сохранилась в праславянском и старославянском языках (напоминаю, что это не одно и то же).
Если учесть, что в праславянском языке было три числа, мы получаем четыре возможных способа сочетания числительного с существительным:
1 + именительный падеж единственного числа;
2 + именительный падеж двойственного числа;
3-4 + именительный падеж множественного числа;
5-10 + родительный падеж множественного числа.
Продемонстрирую это в таблице (для простоты берём только неодушевлённое существительное мужского рода):
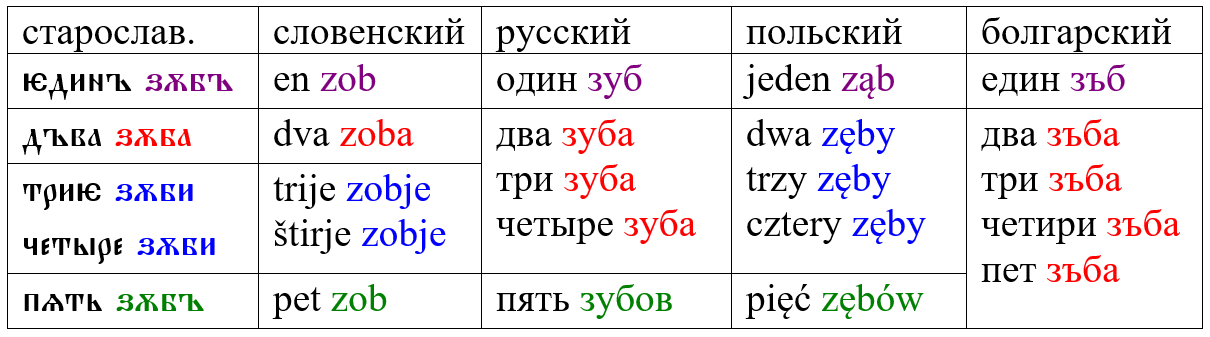
Современные славянские языки пошли несколькими путями:
1) полностью сохранить старую систему смогли только те языки, где есть двойственное число – словенский и лужицкие;
2) в русском и сербохорватском 2-4 сочетаются со старой формой именительного падежа двойственного числа;
3) в польском, чешском и словацком с 2-4 используется именительный падеж множественного числа;
4) у болгар и македонцев с 2-5 сочетается так называемая счётная форма, которая восходит к всё тому же именительному падежу двойственного числа.
Перейдём к наименованиям десятков. Нужно сразу сказать, что уже в праиндоевропейском языке было слово *ḱm̥tom /кьмтом/ «сто», прямым потомком которого наше сто и является. Соответственно, существовали и названия десятков, которые хорошо сохранились в санскрите, греческом, латыни и ряде других ветвей индоевропейских языков, но праславянский заменил их на новые, более прозрачные, обозначения. Скажем, 20 для праиндоевропейского реконструируется как *ṷih₁ḱm̥tih₁ /ўихкьмтих/ (сложение *dṷoh₁ «два» и *deḱm̥t «десять»), и эта форма отразилась в латыни как viginti /ўигинти/, в древнегреческом как εἴκοσι /экоси/, а в санскрите как viṁśatí /винщати/. Если бы это слово сохранилось в современном русском, оно бы звучало как *висяти. Однако праславянский ввёл вместо него *dъva desęti, то есть «два десятка».
Все названия десятков в праславянском и древнерусском вели себя как сочетания единиц и числительного десять, полностью подчиняющиеся вышеописанной схеме.

Поначалу это были именно словосочетания, то есть, между их компонентами могли вставляться другие слова, кроме того, при склонении названий десятков в древнерусском изменялись обе части:

Это хорошо видно в берестяной грамоте №293:
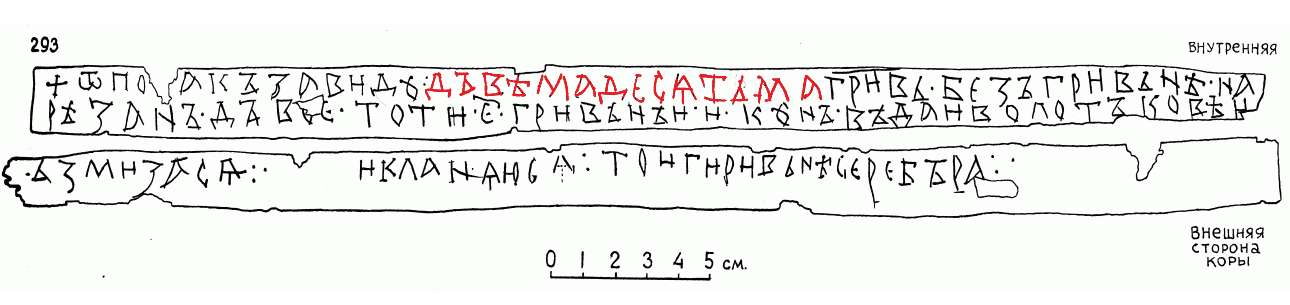
Довольно рано словосочетания срастаются в одно слово, и первый компонент слов 20 и 30 перестаёт склоняться. Кроме того, произошло фонетически незакономерное упрощение слов 20 и 30. Так, из древнерусского дъва десяти в современном русском должно было получиться двадесяти. Однако для числительных довольно характерны нестандартные укорачивания. Скажем, на месте литературного тысяча в разговорном русском появилась форма тыща, хотя у нас сейчас не действует фонетического закона, по которому заударные гласные бы просто так исчезали. Аналогичным образом в двадесяти отвалились -е- и -и. При этом произношение типа двадсять было невозможно, поскольку в русском не могут друг за другом следовать звонкая и глухая согласные. Вследствие этого на месте -дс- получаем -тс-, а -тс- уже в свою очередь сливаются в -ц- (аффриката ц по сути и состоит из т и с). Похожие процессы имеем в случаях браться – /брацца/ или /браца/, детский – /децкий/.
Форма трицать засвидетельствована уже в новгородской берестяной грамоте №1 (1380‒1400 гг.):

Современная запись вида двадцать и тридцать наполовину фонетична, наполовину этимологична, она объединяет -ц-, возникшее в результате описанных выше процессов, и -д-, которое там уже давно не произносится.
Довольно похожие процессы проходили, например, в чешском языке:
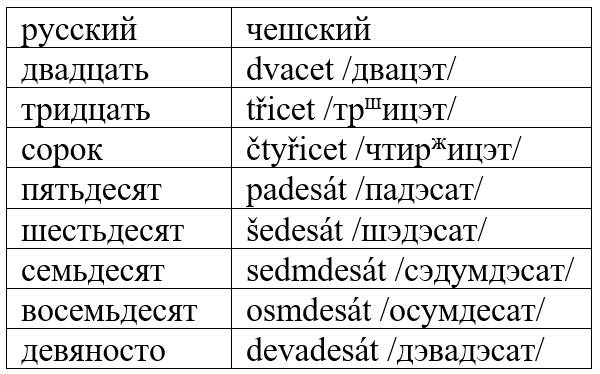
Несложно заметить, что русский ввёл новые названия для 40 и 90. О первом я уже как-то писал, о втором надеюсь сделать отдельный пост в дальнейшем.
Перейдём к сотням. Их обозначения выстроены по тем же принципам, что и названия десятков:

В отличие от названий десятков, в современном литературном русском эти обозначения сохранились почти в неизменном виде. Вполне закономерно пали «редуцированные» (ъ и ь – особые гласные). Кроме того в форме двѣстѣ произошла диссимиляция, то есть расподобление ѣ…ѣ > ѣ...и. Аналогичный пример: сѣдѣти > сидеть.
Отдельно следует оговорить вопрос склонения названий десятков и сотен. Как я уже написал выше, первые части 20 и 30 перестали склоняться рано. Что касается 50-90, со временем вместо форм типа пятьюдесятью начинают появляться пятидесятью, шестидесятью и так далее:
Наконец подпоручик Толстовалов с пятидесятью охотниками сделал вылазку, очистил ров и прогнал бунтовщиков, убив до четырехсот человек и потеряв не более пятнадцати. [А. С. Пушкин. История Пугачева (1833)]
В сию минуту Салманов передался, и Бошняк остался с шестидесятью человеками офицеров и солдат. [А. С. Пушкин. История Пугачева (1833)]Однако литературная норма по-прежнему требует, чтобы в таких числительных склонялись обе части, даже несмотря на то, что пишутся они слитно:

В разговорном языке существует тенденция к полной утрате склоняемости первой части, которая является частью того же процесса, который упростил склонение 20 и 30:
Если вес уссурийского тигра достигает трехсот килограмм, а бенгальского ― двухсот пятидесяти, то «туранец» весил не больше пятьдесяти-шестьдесяти килограмм. [Александр Яблоков. Точка возврата позади // «Знание - сила», 2006]
Литературная норма также велит, чтобы в названиях сотен склонялись обе части:

Однако в разговорной речи эта система уже в значительной степени разрушена, и есть сильная тенденция ориентироваться на склонение числительного сто. Отсюда формы типа пятиста:
― 8-я английская армия в 4.30 утра 6 апреля внезапно штурмовала позиции Роммеля, открыв огонь из пятиста орудий. [В. В. Вишневский. Дневники военных лет (1943-1945)]
Кроме того, зачастую не склоняют первые компоненты составных числительных, то есть состоящих из названий нескольких разрядов. Для многих носителей современного русского будет достаточно проблематично просклонять числительное в следующем примере в соответствии с нормой:
Написав по этой азбуке цифрами слова L'empereur Napoleon, выходит, что сумма этих чисел равна 666-ти и что поэтому Наполеон есть тот зверь, о котором предсказано в Апокалипсисе. [Л. Н. Толстой. Война и мир. Том третий (1867-1869)]
Надеюсь, этот пост помог вам лучше понять, как устроены русские числительные 20-900 в исторической перспективе. За более подробной информацией отсылаю к книге О.Ф. Жолобова Историческая грамматика древнерусского языка IV. Числительные. Больше о том, как русские числительные утрачивают склонение можно прочитать в статье М.Я. Гловинской Изменения в склонении числительных в русском языке на рубеже ХХ—XXI веков // Язык в движении: К 70-летию Л.П. Крысина. М., 2007.





Наука | Научпоп
9.4K постов82.8K подписчика
Правила сообщества
Основные условия публикации
- Посты должны иметь отношение к науке, актуальным открытиям или жизни научного сообщества и содержать ссылки на авторитетный источник.
- Посты должны по возможности избегать кликбейта и броских фраз, вводящих в заблуждение.
- Научные статьи должны сопровождаться описанием исследования, доступным на популярном уровне. Слишком профессиональный материал может быть отклонён.
- Видеоматериалы должны иметь описание.
- Названия должны отражать суть исследования.
- Если пост содержит материал, оригинал которого написан или снят на иностранном языке, русская версия должна содержать все основные положения.
- Посты-ответы также должны самостоятельно (без привязки к оригинальному посту) удовлетворять всем вышеперечисленным условиям.
Не принимаются к публикации
- Точные или урезанные копии журнальных и газетных статей. Посты о последних достижениях науки должны содержать ваш разъясняющий комментарий или представлять обзоры нескольких статей.
- Юмористические посты, представляющие также точные и урезанные копии из популярных источников, цитаты сборников. Научный юмор приветствуется, но должен публиковаться большими порциями, а не набивать рейтинг единичными цитатами огромного сборника.
- Посты с вопросами околонаучного, но базового уровня, просьбы о помощи в решении задач и проведении исследований отправляются в общую ленту. По возможности модерация сообщества даст свой ответ.
Наказывается баном
- Оскорбления, выраженные лично пользователю или категории пользователей.
- Попытки использовать сообщество для рекламы.
- Фальсификация фактов.
- Многократные попытки публикации материалов, не удовлетворяющих правилам.
- Троллинг, флейм.
- Нарушение правил сайта в целом.
Окончательное решение по соответствию поста или комментария правилам принимается модерацией сообщества. Просьбы о разбане и жалобы на модерацию принимает администратор сообщества. Жалобы на администратора принимает и общество Пикабу.