

Нейросеть рисует и пишет
19 постов
19 постов

16 постов

110 постов

40 постов
109 постов

114 постов

20 постов

Слон может немного отдохнуть в тени орешника.
📅 Дата публикации: 15 сентября 2025 года
📍 Место: Россия
Комплекс PG_HAZEL представляет собой инновационное решение для глубокого анализа производительности СУБД PostgreSQL. Этот инструмент сочетает в себе методы статистического анализа, мониторинга в реальном времени и причинно-следственного моделирования, что позволяет точно определять корневые причины инцидентов производительности и прогнозировать потенциальные сбои.
PG_HAZEL использует методы корреляционного анализа для установления взаимосвязей между:
Метриками ОС (iostat, vmstat, использование CPU, памяти, дискового I/O).
Ожиданиями СУБД PostgreSQL (типы ожиданий IO, IPC, LWLock, и др.).
Показателями производительности СУБД (операционная скорость, ожидания СУБД, индикатор деградации производительности СУБД).
Тактический и оперативный анализ
PG_HAZEL работает на тактическом уровне, анализируя влияние отдельных SQL-запросов на производительность СУБД. Он идентифицирует запросы, которые оказывают наибольшее негативное воздействие, и связывает их с конкретными типами ожиданий (IO, IPC, LWLOCK).
Многомерный анализ производительности
PG_HAZEL интегрирует данные из различных источников, включая метрики ОС (iostat, vmstat), события ожидания PostgreSQL и статистику выполнения SQL-запросов. Это позволяет построить единую модель производительности и количественно оценить вклад каждого фактора в общую производительность СУБД.
Планируемое направление развития : причинно-следственный анализ и прогнозное моделирование, визуализация и интерактивные дашборды
Используя методы причинности по Грэнджеру и байесовские сети, комплекс поможет выявляет не просто корреляции, а реальные причинно-следственные связи между метриками. Например, он может определить, что рост времени отклика диска (await) вызывает увеличение времени ожидания ввода-вывода в PostgreSQL, что приводит к деградации производительности. Используя методы ARIMA и машинного обучения возможно будет прогнозировать инциденты производительности СУБД PostgreSQL , таких как исчерпание дискового пространства или достижение критической нагрузки на CPU. Это позволит администраторам СУБД заранее принимать превентивные меры.
Тепловые карты(heatmaps) корреляций и дашборды, позволят быстро выявлять аномалии и анализировать их в контексте всех метрик.
PG_HAZEL уже успешно применяется для анализа инцидентов производительности в реальных условиях.
Кроме того, комплекс используется для нагрузочного тестирования, помогая определить предельные значения нагрузки, которые СУБД может выдержать без деградации производительности.
📈 Преимущества подхода
Раннее обнаружение проблем
Анализ метрик ОС позволяет выявлять потенциальные проблемы до их воздействия на производительность СУБД:
Прогнозирование исчерпания дискового пространства
Выявление растущей нагрузки на CPU и память
Обнаружение деградации производительности дисковых подсистем
Точное определение корневой причины инцидентов значительно сокращает время восстановления:
Четкое разграничение проблем ОС и проблем СУБД
Возможность фокусирования на реальной причине, а не симптомах
1.Рост ожиданий типа IO в PostgreSQL:
В ходе анализа инцидента производительности PG_HAZEL выявил, что наибольшая корреляция наблюдается между ожиданиями типа IPC и снижением операционной скорости СУБД. Это указало на проблему взаимодействия между процессами, что позволило администраторам быстро устранить причину.
2.Рост времени отклика дисков в iostat:
Начало инцидента: Рост утилизации CPU и значений iowait в метриках ОС
Корреляционный анализ: Выявление высокой корреляции между:
- Ростом времени ожидания записи для устройств хранения (/data и /wal)
- Снижением производительности СУБД
- Ростом ожиданий типа IO в PostgreSQL
Заключение: Первичной причиной являлись проблемы на уровне дисковых подсистем
«PG_HAZEL — это не просто инструмент мониторинга, а экспертная система, которая превращает разрозненные метрики в понятные и осуществимые предложения. Наша цель — сделать диагностику производительности PostgreSQL максимально автоматизированной и точной».
В ближайших планах развития PG_HAZEL — разработка и внедрение методов причинно-следственного анализа и прогнозного моделирования.
Разработчик PG_HAZEL специализируется на создании решений для мониторинга и анализа производительности СУБД PostgreSQL.
Наша миссия — помогать компаниям поддерживать высокую производительность и надежность их баз данных.
Для получения дополнительной информации обращайтесь:
Имя: Сунгатуллин Ринат Раисович
Телефон: +7 927 245 80 49
Email: kznalp@yandex.ru
Веб-сайт: https://dzen.ru/kznalp
PG_HAZEL устанавливает новый стандарт в мониторинге и диагностике производительности PostgreSQL. Его способность объединять данные из различных источников, выявлять корневые причины проблем и прогнозировать инциденты делает его незаменимым инструментом для администраторов баз данных и IT-специалистов.
Для получения более подробной информации посетите https://dzen.ru/kznalp.
Еще совсем недавно мы жили при реальных настоящих минусаторах, которые за нас решали - что можно смотреть/читать/слушать согражданам а , что нет .

Это вот они решили , что Bonny -M может выступать в СССР , а Pink Floyd - нет.
Это они решали, что под какую музыку можно танцевать школьникам на дискотеках, а под какую нет . Это они решали , что можно печатать в Тезнике-молодежи , а что нет. Это они составляли списки разрешённых и запрещённых музыкантов и писателей.
Это они вместо меня решали , что мне хорошо, а что нет . Рыцари свежего , блин.
Казалось бы , после известных событий - свобода и эти личности никогда не вернуться . Но, парадокс - кто-то сам хочет , чтобы за него решали , что хорошо, что плохо ? Или скорее , кто то надеется , что он окажется в круге тех кто решает ? "Мы здесь власть" ... Это было совсем недавно , те кто не помнит худ.советы эти события то должны помнить ? Не наигрались ?
Во, что превращается ресурс , если дать ощущение власти толпе можно сейчас в живую увидеть на примере Хабра с его кармой . Когда просто за комментарий не в потоке толпы можно легко лишиться права голоса .
Вопрос минусаторам - вы этого хотите ? По совку соскучились ?
Предложение Пикабу - ни в коем случае нет давайте даже ощущения власти толпе. Кому не нравится - есть альтернативные ресурсы. Правило очень простое - всё, что не противоречит закону и правилам площадки - не должно быть ограничено для просмотра.
Итог - Свобода слова важнейшее достижение цивилизации . Никто кроме меня не может решать, что мне хорошо , что плохо. Тем более когда так развиты средства самостоятельной фильтрации контента .
Взято из комментария:
Заминусованный контент улетал в бан и не светился в горячем.
Вопросы:
1) А на каком основании, те кто ставит минусы лучше меня знают - что мне интересно будет смотреть, а что нет? Почему я должен искать , что-то только потому, что кому то это не понравилось ?
2) Если контент не нарушает правил площадки почему кто-то может решать, что можно , а что нельзя смотреть другим ?
Мы, ну я так точно, так уже жили. Худсоветы, Редколлегии, кураторы от райкома, комсомольский патруль. Соскучились ? Обратно в совок захотелось ?
IMHO - предложение администрации : не надо включать влияние минусов на видимость постов. Кому хочется цензуры толпы - есть альтернативные ресурсы.
Оригинал статьи: Дзен канал Postgres DBA
Необходимое предисловие
Статья создана в далеком 2019 году. Это была моя первая статья на Хабре.
Теперь в качестве первой статьи в сообществе Пикабу.
Как известно, существует всего два метода для решения задач:
Метод анализа или метод дедукции, или от общего к частному.
Метод синтеза или метод индукции, или от частного к общему.
Для решения проблемы “улучшить производительность базы данных” это может выглядеть следующим образом.
Анализ — разбираем проблему на отдельные части и решая их пытаемся в результате улучшить производительности базы данных в целом.
На практике анализ выглядит примерно так:
Возникает проблема (инцидент производительности)
Собираем статистическую информацию о состоянии базы данных
Ищем узкие места(bottlenecks)
Решаем проблемы с узких мест
Узкие места базы данных — инфраструктура (CPU, Memory, Disks, Network, OS), настройки(postgresql.conf), запросы:
Инфраструктура: возможности влияния и изменения для инженера — почти нулевые.
Настройки базы данных: возможности для изменений чуть больше чем в предыдущем случае, но как правило все -таки довольно затруднительны, особенно в облаках.
Запросы к базе данных: единственная область для маневров.
Синтез — улучшаем производительность отдельных частей, ожидая, что в результате производительность базы данных улучшится.
Как происходит процесс решения инцидентов производительности, если производительность базы данных не мониторится:
Заказчик -”у нас все плохо, долго, сделайте нам хорошо”
Инженер-” плохо это как?”
Заказчик –”вот как сейчас(час назад, вчера, на прошлой деле было), медленно”
Инженер – “а когда было хорошо?”
Заказчик – “неделю (две недели) назад было неплохо. “(Это повезло)
Заказчик – “а я не помню, когда было хорошо, но сейчас плохо “(Обычный ответ)
В результате получается классическая картина:

На первую часть вопроса ответить легче всего — виноват всегда инженер DBA.
На вторую часть ответить тоже не слишком сложно — нужно внедрять систему мониторинга производительности базы данных.
Возникает первый вопрос — что мониторить?
Путь 1. Будем мониторить ВСЁ

Загрузку CPU, количество операций дискового чтения/записи, размер выделенной памяти, и еще мегатонна разных счетчиков, которые любая более-менее рабочая система мониторинга может предоставить.
В результате получается куча графиков, сводных таблиц, и непрерывные оповещения на почту и 100% занятость инженера решением кучи одинаковых тикетов, впрочем, как правило со стандартной формулировкой — “Temporary issue. No action need”. Зато, все заняты, и всегда есть, что показать заказчику — работа кипит.
Можно мониторить, чуть по-другому- только сущности и события:
На которые инженер DBA может влиять
Для которых существует алгоритм действий при возникновении события или изменения сущности.
Исходя из этого предположения и вспоминая «Философское вступление» с целью избежать регулярного повторения «Лирическое вступление или зачем все это надо» целесообразно будет мониторить производительность отдельных запросов, для оптимизации и анализа, что в конечном итоге должно привести к улучшению быстродействия всей базы данных.
Но для того, чтобы улучшить тяжелый запрос, влияющий на общую производительность базы данных, нужно сначала его найти.
Итак, возникает два взаимосвязанных вопроса:
какой запрос считается тяжелым
как искать тяжелые запросы.
Очевидно, тяжелый запрос это запрос который использует много ресурсов ОС для получения результата.
Переходим ко второму вопросу — как искать и затем мониторить тяжелые запросы ?
По сравнению с Oracle, возможностей немного, но все-таки кое-что сделать можно.

Для поиска и мониторинга тяжелых запросов в PostgreSQL предназначено стандартное расширение pg_stat_statements.
После установки расширения в целевой базе данных появляется одноименное представление, которое и нужно использовать для целей мониторинга.
Целевые столбцы pg_stat_statements для построения системы мониторинга:
queryid Внутренний хеш-код, вычисленный по дереву разбора оператора
max_time Максимальное время, потраченное на оператор, в миллисекундах
Накопив и используя статистику по этим двум столбцам, можно построить мониторинговую систему.
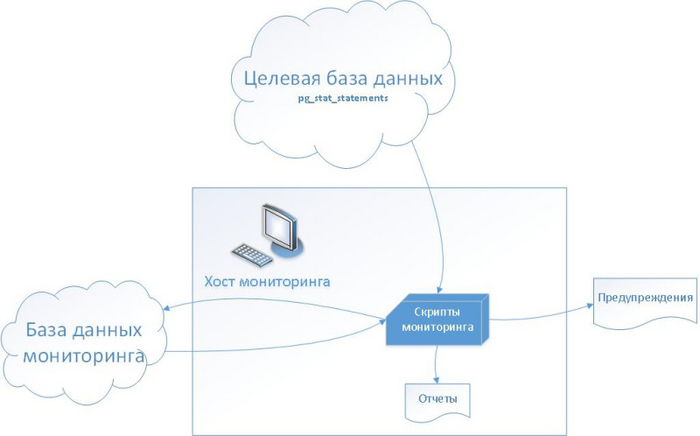
Для мониторинга производительности запросов используется:
На стороне целевой базы данных — представление pg_stat_statements
Со стороны сервера и базы данных мониторинга — набор bash-скриптов и сервисных таблиц.
На хосте мониторинга по крону регулярно запускается скрипт который копирует содержание представления pg_stat_statements с целевой базы данных в таблицу pg_stat_history в базе данных мониторинга.
Таким образом, формируется история выполнения отдельных запросов, которую можно использовать для формирования отчетов производительности и настройки метрик.
Основываясь на собранных данных, выбираем запросы, выполнение которых наиболее критично/важно для клиента(приложения). По согласованию с заказчиком, устанавливаем значения метрик производительности используя поля queryid и max_time.
Мониторинговый скрипт при запуске проверяет сконфигурированные метрики производительности, сравнивая значение max_time метрики со значением из представления pg_stat_statements в целевой базе данных.
Если значение в целевой базе данных превышает значение метрики – формируется предупреждение (инцидент в тикетной системе).
История планов выполнения запросов
Для последующего решения инцидентов производительности очень хорошо иметь историю изменения планов выполнения запросов.
Для хранения истории используется сервисная таблица log_query. Таблица заполняется при анализе загруженного лог-файла PostgreSQL. Поскольку в лог-файл в отличии от представления pg_stat_statements попадает полный текст с значениями параметров выполнения, а не нормализованный текст, имеется возможность вести лог не только времени и длительности запросов, но и хранить планы выполнения на текущий момент времени.
Continuous performance improvement process
Мониторинг отдельных запросов в общем случае не предназначен для решения задачи непрерывного улучшения производительности базы данных в целом поскольку контролирует и решает задачи производительности только для отдельных запросов. Однако можно расширить метод и настроить мониторинг запросы для всех базы данных.
Для этого нужно ввести дополнительные метрики производительности:
За последние дни
За базовый период
Скрипт выбирает запросы из представления pg_stat_statements в целевой базе данных и сравнивает значение max_time со средним значением max_time, в первом случае за последние дни или за выбранный период времени(baseline), во-втором случае.
аким образом в случае деградации производительности для любого запроса, предупреждение будет сформировано автоматически, без ручного анализа отчетов.
В описанной подходе, как и предполагает метод синтеза — улучшением отдельных частей системы, улучшаем систему в целом.
Запрос выполняемый базой данных – тезис
Измененный запрос – антитезис
Изменение состояние системы — синтез

Расширения собираемой статистики добавлением истории для системного представления pg_stat_activity
Расширение собираемой статистики добавлением истории для статистики отдельных таблиц участвующих в запросах
Интеграция с системой мониторинга в облаке AWS
И еще, что-нибудь можно придумать…

Взято из архива основного технического канала Postgres DBA
Предисловие
В ходе работ по подготовке эпюры производительности СУБД в очередной раз была получена иллюстрация проблем использования среднего арифметического при расчете производительности СУБД .
Последовательный рост нагрузки на СУБД
По X - номер итерации. По Y - количество сессий pgbench
Первые же результаты , показали несогласованность pgbench - TPS - с реальными показателями производительности СУБД
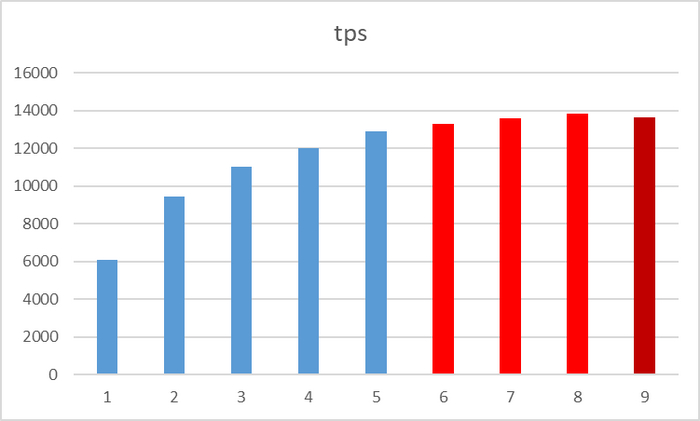
По оси X - номер итерации. По оси Y - TPS. TPS по результатам pgbench - растет.
Значение tps получено тривиально, из результата теста :
лог | grep tps
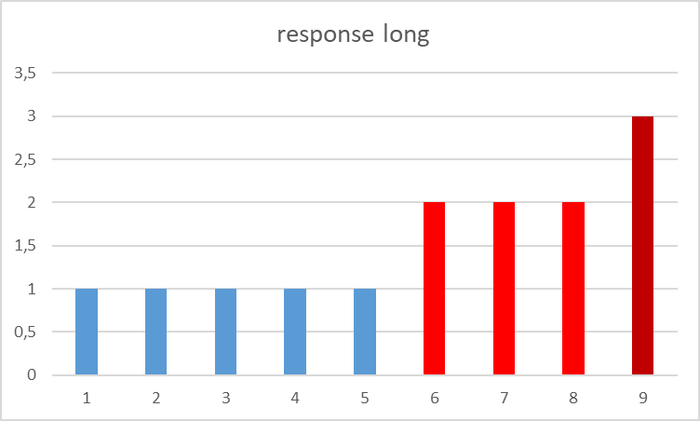
По оси X - номер итерации. По оси Y - среднее время отклика СУБД.
Время отклика вычисляется , также, стандартно:
SUM(total_exec_time) / SUM(calls)
За период из представления pg_stat_statements.
1) Если ориентироваться на результаты pgbench, то , при росте количества подключений c 60 до 70 - tps вырос с 12870,870996 до 13294,489494 (+3%)
2) Если ориентироваться на среднее время отклика СУБД , то, при аналогичном росте количества подключений c 60 до 70 - среднее время отклика увеличилось на 100%
Производительность СУБД растет с ростом нагрузки или нет ?
Очередная иллюстрация на тему - ни TPS , ни время отклика - по отдельности не являются метриками производительности СУБД, потому, что не позволяют предсказать и описать реальную картину и получить объективные данные о реальной производительности СУБД .
P.P.S. Также нужно отметить, что история и анализ данных tps из лога pgbench с помощью grep - не самая удобная процедура . Особенно если не одна итерация, а несколько десятков.
Так, что - как средство создания нагрузки pgbench вполне рабочий и удобный инструмент. Как средство анализа результатов - нет.
Послесловие
Материал носит ознакомительный, справочный характер. Используемая методика расчета среднего времени отклика СУБД в настоящее время не используется. Вообще , среднее арифметическое в расчетах не используется. Да и методика расчета производительности СУБД сильно изменена , в настоящее время идут тесты и анализ результатов. Статьи будут чуть позже.
В связи с проблемами более подробно разобранными в статье О проблеме использования mean_exec_time при анализе производительности PostgreSQL
Меня многие коллеги спрашивают - а зачем , ты на Пикабу размещаешь технические статьи ? Это же развлекательный сайт , там шутки мемы приколы , несерьёзно.
Ну во-первых и это главное - тут не только мемы и приколы , есть и интересные материалы .
Во-вторых , оказалось , что цифры просмотров таки учитываются поисковиками
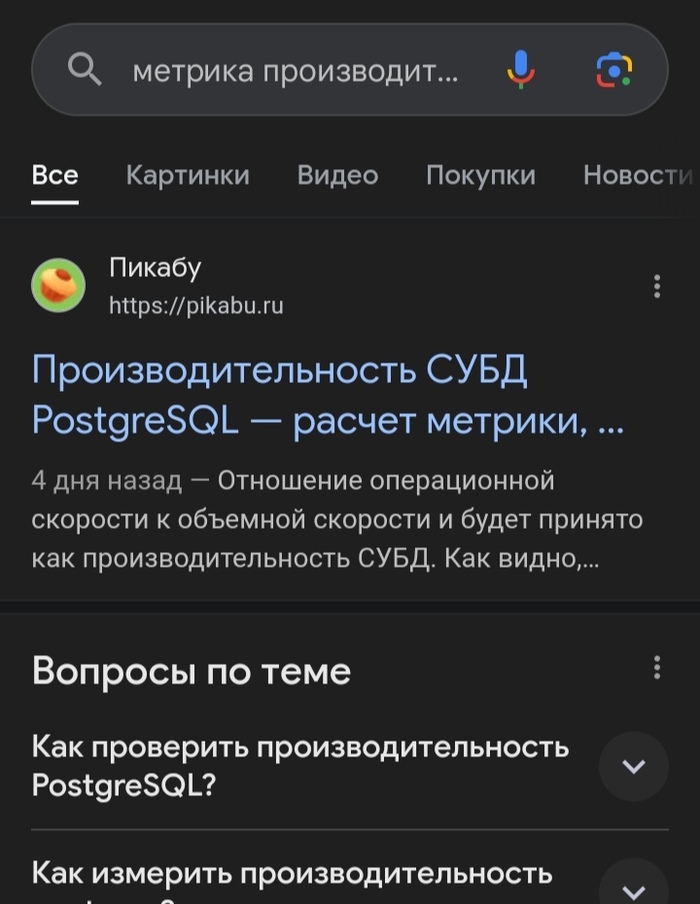
Вот например , если спросить в поисковике "Метрика производительности СУБД PostgreSQL" - выйдет ссылка на Пикабу , а не на Хабр. Я в своё время практически безуспешно искал материалы по теме расчёта производительности СУБД и использованию мат.статистики для анализа проблем производительности. Так, что , кто будет интересоваться темой - найдёт в поисковиках ссылки на Пикабу.
Получается для популяризации интересных идей - размещение статей на развлекательном ресурсе это хорошо, правильно и эффективно.
И будет продолжено.
Update.
Всем спасибо за комментарий и реакцию. Врать не буду - спасибо и был очень удивлен. Да, технические посты будут продолжены . Просто может , не так часто . Архивы уже опубликованы , но тесты и исследования идут. Так , что контент будет.
Еще раз , всем спасибо за обратную связь.
Время идет и можно добавить еще пару копеек в картотеку различий между разными интернет ресурсами.
Важное , принципиальное , стратегическое , краеугольное отличие Пикабу и Хабра - политика моделирования в случае публикации спорного материала .
- Пикабу : удаление спорного поста , без штрафных санкций .
- Хабр : перевод материала в черновик , полный бан аккаунта .
Проверено лично .
P.S. О "минусах" и "цензуре толпы", сказано уже достаточно , добавить в общем то нечего.

Дальнейшая и продуктивная работа только подтвердила правильность принятого решения - столько разных интересных и полезных задумок и штук сделано - и это хорошо! Простейший индикатор - количество публикаций, когда был на Хабре. Как перешёл в тимлиды - тишина . Как вернулся в инженеры - опять материал пошел.
Плюс - надоело доказывать и объяснять вышестоящим начальникам, что ITIL придумали , в общем то не дураки и попытки менять ,ничего не меняя, ни к чему не ведут.
Менеджерство это не моё
-Так и не удалось объяснить и доказать , что DBA не является координатором в случае аварии виртуальной машины - для этого есть отдельная группа виртуализации , они зарплату получают за то чтобы облако работало.
-Так и не удалось объяснить и доказать , что DBA не должен контролировать ошибки резервного копирования - для этого есть группа резервного копирования и это их задача - следить за отчетами РК.
-Так и не удалось объяснить и доказать , что задача "ой у нас стало медленно работать" это не задача обеспечения операционной доступности СУБД и в принципе отдельная услуга - "performance tuning". Ну нет серебряной пули в виде магической комбинации параметров СУБД чтобы кривое приложение и кривая инфраструктура вдруг залетали. Проблему надо решать комплексно и начинать с анализа логики и архитектуры приложения и производительности инфраструктуры.
P.S. Очень важное дополнение - став тимлидом я узнал и почувствовал - что такое "профессиональное выгорание" .
В общем то именно выгорание было основной причиной возвращения в инженеры. Сто тысяч раз сказал себе - "спасибо , молодец не запустил ситуацию до необратимых проблем со здоровьем. Всё правильно сделал!".
Квантовая физика - она везде .
Любое наблюдение за производительностью СУБД - влияет на производительность СУБД.
Вывод:
Невозможно точно определить степень влияния сбора метрик производительности на производительность СУБД.
А метрики производительности снижают производительность СУБД ?
Конечно.
А давайте их отключим?
Создайте изменение и всё сделаем. Только больше не обращайтесь - "Ой у нас почему то все стало медленно".






