Документы Word по-прежнему глубоко встроены в бизнес-процессы. Будь то генерация контрактов, извлечение данных из отчётов, конвертация файлов или объединение нескольких документов — многие из этих задач до сих пор выполняются вручную. Это не только отнимает время, но и чревато ошибками.
Python предлагает богатую экосистему библиотек, которые могут автоматизировать практически все аспекты обработки документов Word. В этой статье мы рассмотрим пять практических задач, которые должен уметь автоматизировать каждый Python-разработчик. Мы сосредоточимся на инструментах с открытым исходным кодом, где это возможно, а для сложного случая конвертации в PDF предложим как бесплатное решение с высоким качеством, так и его коммерческую альтернативу.
Задача 1: Генерация документов Word из шаблонов
Задача 2: Извлечение структурированных данных из файлов Word
Задача 3: Сравнение двух документов Word на предмет изменений
Задача 4: Конвертация документов Word в PDF
Задача 5: Объединение нескольких документов Word в один
Заключение
Задача 1: Генерация документов Word из шаблонов
Зачем это автоматизировать?
Многие приложения нуждаются в создании динамических документов, таких как:
Ручное редактирование каждого экземпляра — повторяющаяся и медленная задача. Используя шаблон и подставляя данные, вы можете сгенерировать сотни документов за секунды.
Рекомендуемый инструмент: python-docx-template
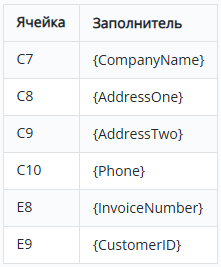
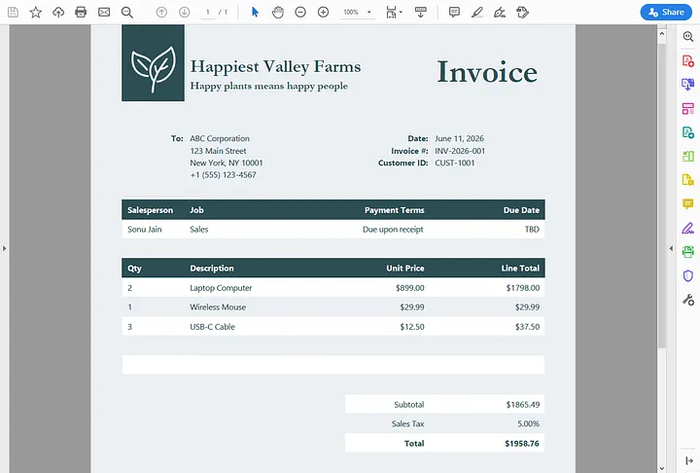
Эта библиотека построена на основе python-docx и интегрирует шаблонизатор Jinja2. Вы просто размещаете заполнители вида {{ customer_name }} внутри шаблона .docx, а затем визуализируете его с вашими данными.
Открытый исходный код (лицензия MIT)
Сохраняет всё форматирование шаблона
Поддерживает циклы и условия (используя синтаксис Jinja2)
Ограничение: Очень сложная логика или вложенные таблицы могут потребовать дополнительной осторожности, но для 95% случаев использования библиотека работает безупречно.
Пример кода
Сначала установите библиотеку:
pip install python-docx-template
Создайте файл шаблона invoice_template.docx с заполнителями:
Счёт для {{ customer_name }}
Дата: {{ date }}
Итоговая сумма: ${{ total }}
Затем сгенерируйте итоговый документ:
from docxtpl import DocxTemplate
doc = DocxTemplate("invoice_template.docx")
context = {
"customer_name": "Алиса Джонсон",
"date": "2026-06-03",
"total": "1299.99"
}
doc.render(context)
doc.save("invoice_alice.docx")
Лучшие сценарии использования
Автоматизированные системы выставления счетов
Генерация кадровых документов
Создание сертификатов для онлайн-курсов
Задача 2: Извлечение структурированных данных из файлов Word
Зачем это автоматизировать?
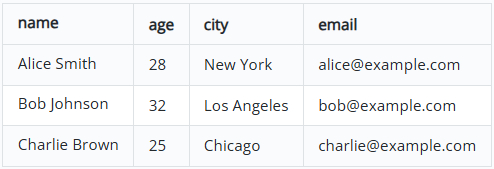
Вы часто получаете документы Word, содержащие ценные данные в таблицах, формах или результатах опросов. Копирование и вставка этих данных в базу данных или CSV-файл — утомительное занятие, чреватое ошибками. Автоматизация извлечения позволяет передавать данные напрямую в ваш конвейер обработки.
Рекомендуемый инструмент: python-docx
python-docx — это фактический стандарт для чтения и записи файлов .docx. Он предоставляет доступ к абзацам, таблицам, элементам форматирования (runs) и стилям. Хотя он не поддерживает файлы .doc (старый двоичный формат), они становятся всё более редкими.
Ограничения, о которых следует знать:
Библиотека сначала читает все абзацы, затем все таблицы — вы не можете легко восстановить смешанный макет (текст → таблица → текст).
Для сложных манипуляций со стилями часто приходится работать на уровне XML.
Пример кода
from docx import Document
doc = Document("survey_results.docx")
# Извлечение всех данных из таблиц
for idx, table in enumerate(doc.tables):
print(f"--- Таблица {idx+1} ---")
for row in table.rows:
row_data = [cell.text.strip() for cell in row.cells]
print(", ".join(row_data))
Если вам нужно экспортировать данные в CSV-файл:
import csv
with open("extracted_data.csv", "w", newline="", encoding="utf-8") as f:
writer = csv.writer(f)
for table in doc.tables:
for row in table.rows:
writer.writerow([cell.text.strip() for cell in row.cells])
Лучшие сценарии использования
Перенос устаревших данных из форм Word в базу данных
Агрегация финансовых данных из нескольких ежемесячных отчётов
Анализ содержимого больших коллекций документов
Задача 3: Сравнение двух документов Word на предмет изменений
Зачем это автоматизировать?
Когда контракт, политика или спецификация пересматриваются, вам нужен быстрый способ увидеть, что изменилось. Ручное сравнение «бок о бок» ненадёжно, особенно для длинных документов. Автоматизированное сравнение может мгновенно выделить добавления, удаления и изменения.
Рекомендуемый инструмент: difflib + python-docx
Поскольку создать чистое open-source решение для получения вывода Word с отслеживанием изменений очень сложно, мы будем использовать встроенный в Python модуль difflib для сравнения необработанного текста двух документов. Это даёт вам быстрый, поддающийся скриптованию способ обнаружения различий.
Он не создаёт документ Word с отметками о правках (красной строкой).
Он сравнивает абзацы, а не символы (но вы можете его адаптировать).
Старые файлы .doc не поддерживаются.
Для юридически значимого сравнения (отслеживание изменений внутри файла Word) вам понадобится коммерческая библиотека, такая как Aspose.Words. Однако для большинства внутренних проверок и обнаружения изменений подхода на основе текста вполне достаточно.
Пример кода
from docx import Document
import difflib
def get_paragraph_texts(docx_path):
doc = Document(docx_path)
return [p.text for p in doc.paragraphs if p.text.strip()]
original = get_paragraph_texts("contract_v1.docx")
revised = get_paragraph_texts("contract_v2.docx")
diff = difflib.unified_diff(
original, revised,
fromfile="Оригинал",
tofile="Изменённый",
lineterm=""
)
for line in diff:
print(line)
Чтобы сделать вывод более читаемым, вы можете записать его в HTML-отчёт:
html_diff = difflib.HtmlDiff()
with open("diff_report.html", "w") as f:
f.write(html_diff.make_file(original, revised, "Оригинал", "Изменённый"))
Лучшие сценарии использования
Аудит изменений в юридических контрактах
Отслеживание обновлений в нормативных документах
Сравнение студенческих работ с эталонным документом
Задача 4: Конвертация документов Word в PDF
Зачем это автоматизировать?
PDF — это универсальный формат для распространения, печати и архивирования. Ручная конвертация (открыть Word → Сохранить как PDF) становится узким местом, когда вам нужно ежедневно конвертировать десятки или сотни файлов. Автоматизация устраняет этот шаг и встраивает конвертацию в ваш конвейер обработки.
Основная рекомендация: docx2pdf (бесплатное, наивысшее качество)
docx2pdf — это не парсер, а тонкая обёртка, которая использует сам Microsoft Word для выполнения конвертации — точно так же, как операция «Сохранить как PDF», которую вы делаете вручную. Поэтому макет, шрифты, таблицы, колонтитулы воспроизводятся идеально.
Microsoft Word должен быть установлен на компьютере (Windows или macOS).
Скрипт запускается в той же операционной системе, где доступен Word.
Не работает на Linux-серверах (нет Word).
Головные серверные среды (например, Docker без графического интерфейса) не могут надёжно запускать эту библиотеку.
Если вы соответствуете требованиям, это лучшее бесплатное решение из доступных.
Пример кода
from docx2pdf import convert
# Конвертация одного файла
convert("report.docx", "report.pdf")
# Конвертация всех .docx файлов в папке
convert("input_folder/", "output_folder/")
Запасное решение: Spire.Doc для Python (когда Word недоступен)
Если вы работаете на Linux-сервере или в среде, где Microsoft Office не может быть установлен, вы можете использовать коммерческую библиотеку, такую как Spire.Doc. Она не зависит от Word и работает полностью автономно.
Примечание: Бесплатная версия имеет ограничения — она обрабатывает только первые 500 абзацев и 25 таблиц, а сконвертированные PDF могут содержать водяной знак. Для промышленного использования требуется лицензия.
from spire.doc import Document, FileFormat
doc = Document()
doc.LoadFromFile("report.docx")
doc.SaveToFile("report.pdf", FileFormat.PDF)
doc.Close()
Альтернатива (полностью открытый исходный код, кросс-платформенная): Вы можете вызвать LibreOffice из командной строки, используя subprocess:
import subprocess
subprocess.run(["libreoffice", "--headless", "--convert-to", "pdf", "report.docx"])
Это работает на Linux, Windows и macOS, но требует отдельной установки LibreOffice.
Итоги по задаче 4
Задача 5: Объединение нескольких документов Word в один
Зачем это автоматизировать?
Типичные сценарии включают:
Объединение ежемесячных финансовых отчётов в квартальную сводку
Слияние отдельных разделов контракта в основной договор
Сборка пакета документации из нескольких глав
Выполнение этого вручную (копирование-вставка) часто разрушает форматирование и крайне медленно для большого количества файлов.
Рекомендуемый инструмент: docxcompose
docxcompose принимает один документ в качестве «основного» и добавляет к нему другие, сохраняя базовое форматирование. Библиотека легковесна и проста в использовании.
Верхние и нижние колонтитулы, а также разрывы разделов часто теряются , потому что библиотека выполняет слияние, добавляя страницы в тот же раздел.
Текстовые поля, сложные вложенные таблицы и некоторые пользовательские стили могут не сохраниться при слиянии.
Проект не поддерживался активно с 2018 года.
Для простых документов (обычный текст, простые таблицы, немного стилей) библиотека работает удивительно хорошо. Для сложных отчётов с разными колонтитулами для каждой главы потребуется более надёжное (скорее всего, коммерческое) решение, или вы можете вручную копировать элементы с помощью python-docx — это больше работы, но полностью контролируемо.
Пример кода
from docxcompose.composer import Composer
from docx import Document
master = Document("chapter1.docx")
composer = Composer(master)
composer.append(Document("chapter2.docx"))
composer.append(Document("chapter3.docx"))
composer.save("full_report.docx")
Если docxcompose не работает с вашими документами, вот более надёжный (но более длинный) подход: перебрать все элементы каждого документа и добавить их в новый основной документ, используя чистый python-docx. Упрощённый фрагмент:
from docx import Document
master = Document()
for file in ["part1.docx", "part2.docx"]:
doc = Document(file)
for element in doc.element.body:
master.element.body.append(element)
master.save("merged.docx")
Имейте в виду, что эта низкоуровневая манипуляция XML может нарушить стили, если выполнять её неаккуратно.
Лучшие сценарии использования
Объединение простых отчётов с большим объёмом текста
Добавление приложений к основному документу
Сборка наборов документации из Markdown, сконвертированных в Word
Заключение
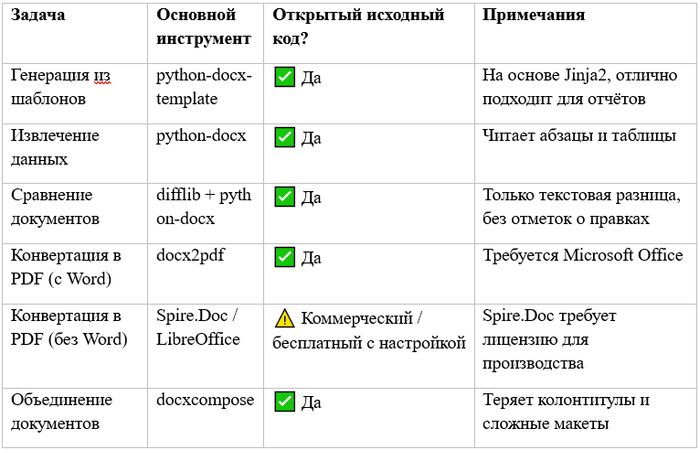
В таблице ниже обобщены рекомендуемые инструменты и их компромиссы.
Автоматизируя эти пять задач, вы можете сэкономить часы повторяющейся ручной работы. Начните с решений с открытым исходным кодом — они покроют большинство повседневных потребностей. Для критически важного форматирования корпоративного уровня (юридически значимое сравнение, идеальная конвертация в PDF на Linux, безупречное слияние) рассмотрите коммерческие библиотеки, такие как Aspose.Words. Но для большинства Python-разработчиков код, показанный выше, уже преобразит то, как вы работаете с документами Word.
Так что вперёд, автоматизируйте генерацию счетов, извлечение данных или конвертацию отчётов — ваш будущее «я» скажет вам спасибо.