

Немножко о нейронных сетях 4
Обучение перцептрона
После того, как мы разработали способ по простому расчету выходных значений, следующим естественным шагом будет пропустить через нейросеть обучающий образ (который мы хотим в нее записать), рассчитать выходное значение, а потом вычислить ошибку, т.е. отличие выхода от входа (мы же хотим, чтобы нейросеть не изменяла эталонный образ).
Задаем матрицу входных значений. Для первой картинки это будет
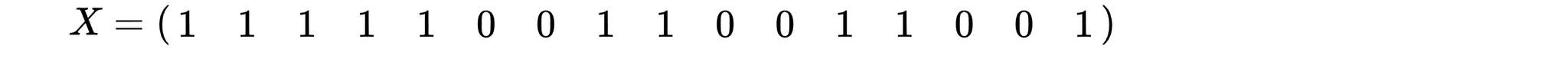

Начальные веса синапсов зададим произвольным образом. Вообще говоря, доказано, что "схождение" перцептрона, т.е. стабилизация весов синапсов не зависит от изначального выбора этих весов.
Выполняем расчет (обучение занимает несколько тысяч итераций, поэтому я, конечно, не буду их тут приводить) и получаем некую матрицу выходных значений M. Для расчета ошибки воспользуемся определением разности матриц, которое сводится к тому, что из каждого элемента первой матрицы нужно вычесть соответствующий элемент второй матрицы.
Тогда получим, что ошибка

Каждый элемент матрицы ошибки соответствует "строке" в нейронной сети, т.е. нейрону, расположенному на входе и нейрону с таким же номером, расположенному на выходе.
Теперь напомню формулу коррекции веса одного синапса:

Следующим большим делом для нас будет вычисление коэффициента g. Если помните, то он описывает влияние изменения веса синапса на выходное значение нейрона, с которым соединен этот синапс. Говоря прямо, это частная производная выходного значения нейрона по весу этого синапса. Поскольку нейроны у нас выполняют элементарную функцию сложения (пока про округление забудем), а синапс выполняет также очень простую функцию умножения двух чисел (веса и значения нейрона предыдущего слоя), то производная эта равна самому значению нейрона предыдущего слоя:

Напомню, что m - значение на выходе нейронов 3-го слоя, а s - на выходе 2-го слоя.
Ну и для совсем полного ощущения простоты задачи помним, что все x, s, m - равны либо 0, либо 1. Поэтому коэффициент g равен либо 1, если на входе синапса 1, либо 0, если на входе синапса 0.
Теперь наверное самый сложный шаг во всей задаче. Нам нужно получить матрицу корректировок для весов. Запишем несколько корректировок в виде уравнений, чтобы увидеть закономерность (и для простоты предположим, что у нас всего три нейрона, а не 16):
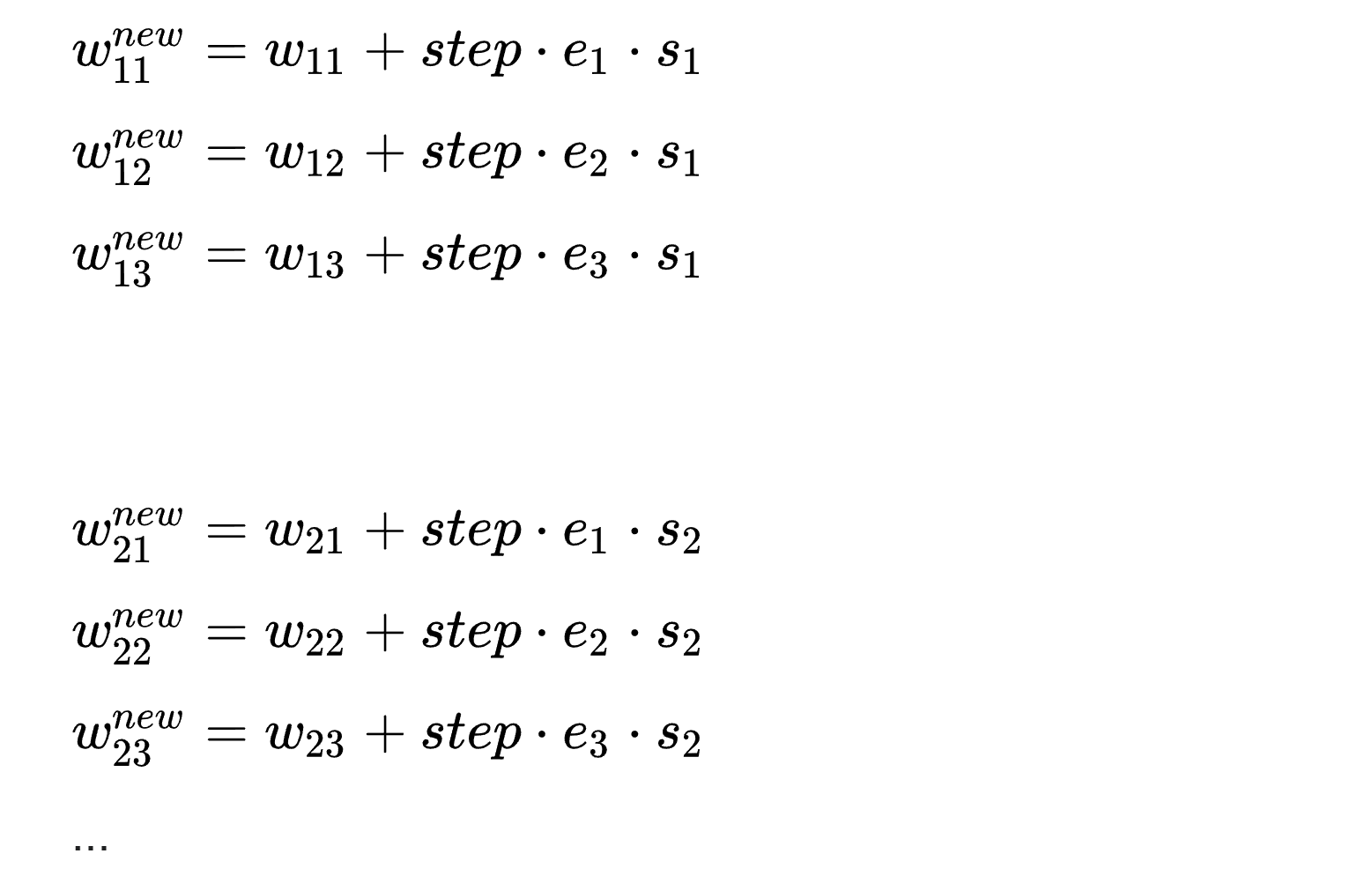
Теперь нужно понять, как будут выглядеть матрица корректировок и ее составляющие, чтобы мы могли привести эти уравнения к матричному виду и получить следующее:

В первую очередь заметим, что все коэффициенты корректировок умножаются на одно и то же число - шаг обучения step. Его можно вынести за матрицу (т.к. процедура умножения матрицы на число подразумевает умножение на это число каждого элемента матрицы). В остальном для получения матрицы коррекций можно использовать произведение следующих простых матриц, которые легко формируются программно:

или сокращенно:
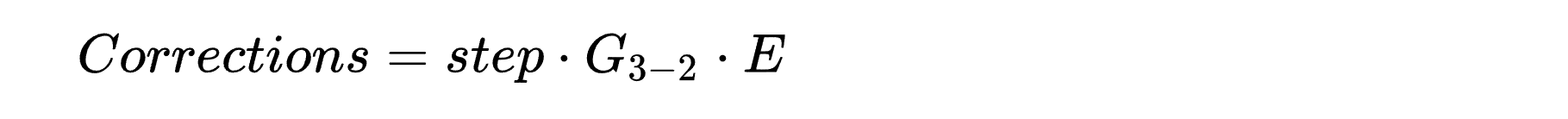
Таким образом выполняются корректировки синапсов, связывающих второй и третий слои. Аналогичным образом можно рассчитать матрицу G_2-1, получаемую при корректировке синапсов первого слоя, но вот значений ошибок на выходе второго слоя у нас нет. Поэтому нам нужно получить матрицу G_3-1 для корректировок синапсов первого слоя на основании ошибок E. Не вдаваясь в математические изыскания, просто укажем, что такую матрицу можно получить, если перемножить матрицы, речь о которых шла выше:
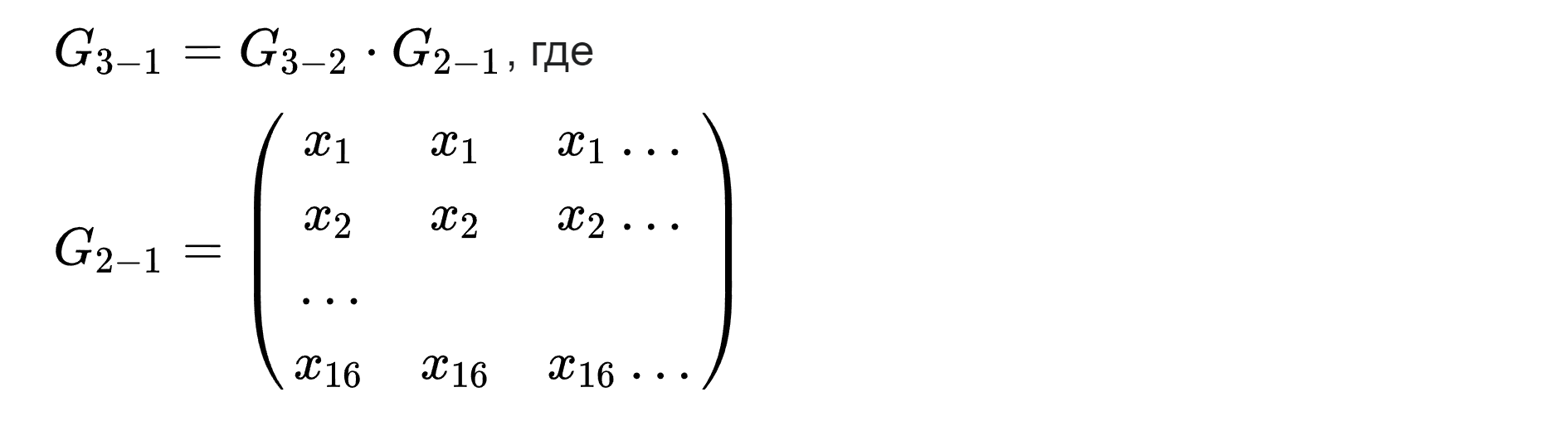
Как можно заметить, на основании ошибки, возникающей на выходе перцептрона, мы сначала корректируем синапсы второго слоя, а затем "распространяем" ошибку еще глубже (умножаем уже на две матрицы G) и корректируем синапсы первого слоя. Такой подход и определяет само наименование метода обучения - метод обратного распространения ошибки.
Что ж, пожалуй, я рассказал все, что хотел по этой теме) Надеюсь, было интересно и помогло приоткрыть завесу тайны, как это работает внутри. Если кого-то заинтересует, могу в комментариях дать ссылку на код на питоне для нейросети из статьи (ранее в посте №2 давал).
Наука | Научпоп
9.7K постов83.1K подписчиков
Правила сообщества
Основные условия публикации
- Посты должны иметь отношение к науке, актуальным открытиям или жизни научного сообщества и содержать ссылки на авторитетный источник.
- Посты должны по возможности избегать кликбейта и броских фраз, вводящих в заблуждение.
- Научные статьи должны сопровождаться описанием исследования, доступным на популярном уровне. Слишком профессиональный материал может быть отклонён.
- Видеоматериалы должны иметь описание.
- Названия должны отражать суть исследования.
- Если пост содержит материал, оригинал которого написан или снят на иностранном языке, русская версия должна содержать все основные положения.
- Посты-ответы также должны самостоятельно (без привязки к оригинальному посту) удовлетворять всем вышеперечисленным условиям.
Не принимаются к публикации
- Точные или урезанные копии журнальных и газетных статей. Посты о последних достижениях науки должны содержать ваш разъясняющий комментарий или представлять обзоры нескольких статей.
- Юмористические посты, представляющие также точные и урезанные копии из популярных источников, цитаты сборников. Научный юмор приветствуется, но должен публиковаться большими порциями, а не набивать рейтинг единичными цитатами огромного сборника.
- Посты с вопросами околонаучного, но базового уровня, просьбы о помощи в решении задач и проведении исследований отправляются в общую ленту. По возможности модерация сообщества даст свой ответ.
Наказывается баном
- Оскорбления, выраженные лично пользователю или категории пользователей.
- Попытки использовать сообщество для рекламы.
- Фальсификация фактов.
- Многократные попытки публикации материалов, не удовлетворяющих правилам.
- Троллинг, флейм.
- Нарушение правил сайта в целом.
Окончательное решение по соответствию поста или комментария правилам принимается модерацией сообщества. Просьбы о разбане и жалобы на модерацию принимает администратор сообщества. Жалобы на администратора принимает и общество Пикабу.