

Знакомство с искусственным интеллектом
4 поста
После того, как мы разработали способ по простому расчету выходных значений, следующим естественным шагом будет пропустить через нейросеть обучающий образ (который мы хотим в нее записать), рассчитать выходное значение, а потом вычислить ошибку, т.е. отличие выхода от входа (мы же хотим, чтобы нейросеть не изменяла эталонный образ).
Задаем матрицу входных значений. Для первой картинки это будет
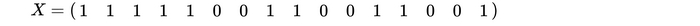

Начальные веса синапсов зададим произвольным образом. Вообще говоря, доказано, что "схождение" перцептрона, т.е. стабилизация весов синапсов не зависит от изначального выбора этих весов.
Выполняем расчет (обучение занимает несколько тысяч итераций, поэтому я, конечно, не буду их тут приводить) и получаем некую матрицу выходных значений M. Для расчета ошибки воспользуемся определением разности матриц, которое сводится к тому, что из каждого элемента первой матрицы нужно вычесть соответствующий элемент второй матрицы.
Тогда получим, что ошибка

Каждый элемент матрицы ошибки соответствует "строке" в нейронной сети, т.е. нейрону, расположенному на входе и нейрону с таким же номером, расположенному на выходе.
Теперь напомню формулу коррекции веса одного синапса:

Следующим большим делом для нас будет вычисление коэффициента g. Если помните, то он описывает влияние изменения веса синапса на выходное значение нейрона, с которым соединен этот синапс. Говоря прямо, это частная производная выходного значения нейрона по весу этого синапса. Поскольку нейроны у нас выполняют элементарную функцию сложения (пока про округление забудем), а синапс выполняет также очень простую функцию умножения двух чисел (веса и значения нейрона предыдущего слоя), то производная эта равна самому значению нейрона предыдущего слоя:

Напомню, что m - значение на выходе нейронов 3-го слоя, а s - на выходе 2-го слоя.
Ну и для совсем полного ощущения простоты задачи помним, что все x, s, m - равны либо 0, либо 1. Поэтому коэффициент g равен либо 1, если на входе синапса 1, либо 0, если на входе синапса 0.
Теперь наверное самый сложный шаг во всей задаче. Нам нужно получить матрицу корректировок для весов. Запишем несколько корректировок в виде уравнений, чтобы увидеть закономерность (и для простоты предположим, что у нас всего три нейрона, а не 16):

Теперь нужно понять, как будут выглядеть матрица корректировок и ее составляющие, чтобы мы могли привести эти уравнения к матричному виду и получить следующее:

В первую очередь заметим, что все коэффициенты корректировок умножаются на одно и то же число - шаг обучения step. Его можно вынести за матрицу (т.к. процедура умножения матрицы на число подразумевает умножение на это число каждого элемента матрицы). В остальном для получения матрицы коррекций можно использовать произведение следующих простых матриц, которые легко формируются программно:

или сокращенно:

Таким образом выполняются корректировки синапсов, связывающих второй и третий слои. Аналогичным образом можно рассчитать матрицу G_2-1, получаемую при корректировке синапсов первого слоя, но вот значений ошибок на выходе второго слоя у нас нет. Поэтому нам нужно получить матрицу G_3-1 для корректировок синапсов первого слоя на основании ошибок E. Не вдаваясь в математические изыскания, просто укажем, что такую матрицу можно получить, если перемножить матрицы, речь о которых шла выше:

Как можно заметить, на основании ошибки, возникающей на выходе перцептрона, мы сначала корректируем синапсы второго слоя, а затем "распространяем" ошибку еще глубже (умножаем уже на две матрицы G) и корректируем синапсы первого слоя. Такой подход и определяет само наименование метода обучения - метод обратного распространения ошибки.
Что ж, пожалуй, я рассказал все, что хотел по этой теме) Надеюсь, было интересно и помогло приоткрыть завесу тайны, как это работает внутри. Если кого-то заинтересует, могу в комментариях дать ссылку на код на питоне для нейросети из статьи (ранее в посте №2 давал).
Напоминаю, что мы рассматриваем сеть для распознавания простых картинок:
Несмотря на то, что каждый нейрон выполняет элементарные арифметические функции, из-за их количества работать напрямую с уравнениями довольно-таки неудобно. Поэтому мы применим своего рода лайфак. Для начала запишем, как будет складываться значение на выходе первых нейронов второго слоя (без учета округления):

Где s_j - выходное значение j-го нейрона, w_ij - вес синапса, выходящего из нейрона i и заходящего в нейрон j, а x_i - входное значение на i-м нейроне.
Смотрится страшно?) Но, как можно заметить, уравнения прямо-таки одинаковые, меняются только индексы. Поэтому математики придумали, как бы записать это попроще, а именно:

где каждый элемент - это матрицы:

Процедура умножения матрицы на матрицу определена таким образом, что результат - тоже матрица, причем каждый элемент вычисляется как раз соответственно уравнениям выше.
Если задать в программе процедуры умножения, сложения матриц и умножения матрицы на число универсально для любого размера этих матриц, то непосредственно работа с ними сводится к анализу таких простых формул. Кстати, мы же рассмотрели только переход одного слоя нейронов ко второму, а у нас есть еще третий. Но как можно видеть, второй переход очень похож на первый: там те же 16 входов, 16х16 синапсов и 16 выходов. Поэтому переход от второго слоя к третьему (опять же, опустим операцию округления) будет выглядеть как:

Сама операция округления может быть произведена отдельно для S перед вычислением М, а затем для M перед выдачей результата.
Работа сети (распознавание картинки) происходит итеративно, т.е. после первой обработки искаженной картинки сетью, результат может не быть достигнут. В этом случае необходимо взять полученный результат и снова прогнать его через сеть, и так (возможно) несколько раз. Строго говоря, после выполнения ряда итераций результат может быть следующим:
На выходе сети получится один из исходных образов. На следующих итерациях он уже не будет меняться, т.к. сеть изначально обучена с тем критерием, что при обработке обучающего образа он не изменяется.
На выходе сети получится стабильный (не меняющийся при последующих итерациях) образ, не совпадающий, однако, ни с одним из эталонных. Такой образ называется химерой.
На выходе сети не получается стабильного результат, но происходит зацикливание: картинка 1 - картинка 2 -... - картинка 1 - ... . Честно говоря, не знаю, характерна ли такая проблема для перцептрона, но она характерна для другого типа сетей - сети Хопфилда. Сеть Хопфилда может попасть в состояние, называемое динамическим аттрактором, заключающееся в том, что она бесконечно переключается между двумя картинками, не совпадающими ни с одним из эталонных образов.
Поэтому сеть нужно остановить в некоторый момент. Причем, как видно, неправильно будет устанавливать критерием остановки работы сети совпадение результата с одним из эталонных образов. Как правило, имеет смысл установить критерием стабилизацию результата вместе с максимальным числом циклов. Например, критерий может звучать так: "Остановить работу сети в случае, если очередное полученное изображение не отличается от поданного на вход, либо после 100 итераций, если изображение не стабилизировалось".
Простой пример рабочей сети.
Рассмотрим пример сети, которая будет заниматься распознаванием примитивных картинок. В процессе обучения мы "запишем" в сеть несколько образов. Затем, в процессе использования, мы будем подавать на вход искаженные образы, а сеть должна будет определить, какой же образ имелся в виду.
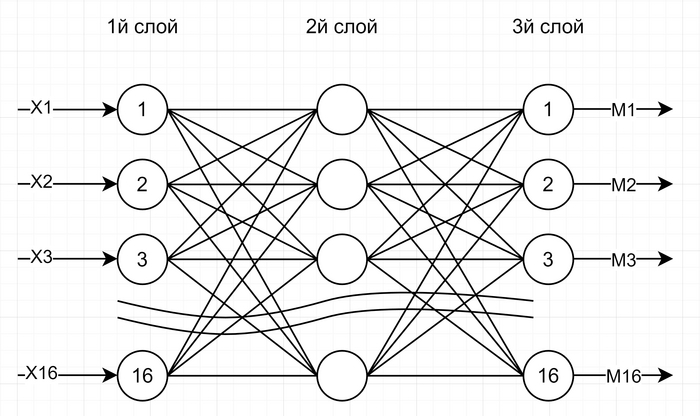
В качестве "картинок" мы будем использовать поле 4х4 пикселя, причем каждый пиксель может быть либо закрашен (тогда на вход подается 1), либо не закрашен (тогда на вход подается 0). Количество входов, соответственно, равно 16, т.е. по одному входу на каждый пиксель. Пример картинки:

Выходов у нас тоже будет 16, т.е. на каждый пиксель. Номера входов и выходов будут соответствовать порядковому номеру пикселя: с 1го по 4 - верхняя строка, с 5 по 8 - вторая строка и так далее. Нейронная сеть в общем будет выглядеть следующим образом:
Напомню функции составных частей сети:
Каждый нейрон вычисляет сумму всех приходящих на него значений, а затем округляет полученное число: если оно больше 0, то на выходе устанавливает значение 1, иначе - 0.
Каждая связь (синапс) имеет свой коэффициент (множитель). Значение, установленное на выходе нейрона, передается на каждый нейрон следующего слоя с умножением на вес соответствующего синапса.
Процесс обучения выглядит следующим образом:
Подаем на вход один из оригинальных образов;
Смотрим, что получается на выходе;
Вычисляем ошибку на каждом выходе;
Корректируем веса синапсов;
Повторяем операцию с другими образами до тех пор, пока ошибка не исчезнет.
Поясню третий пункт: так как на вход мы подали оригинальный образ, то ясно, что после "распознавания" нейронной сетью, он не должен поменяться. Поэтому ошибку, например, на 1-м выходе, можно вычислить как:

С учетом того, что на входах и выходах у нас всегда либо 0, либо 1, то ошибки могут принимать значения: 0, 1, -1.
Четвертый пункт достоин отдельного поста, так как в нем заложена вся суть метода обратного распространения ошибки. Но пока что нам нужно понять в целом, как работает обучение, поэтому на пальцах скажем следующее:
Если ошибка на выходе какого-то нейрона равна 0, то все веса на входных связях правильные, их не корректируем.
Если ошибка на выходе равна 1, т.е. вход больше, чем выход, значит, сигнал слишком ослабляется. Увеличим веса на небольшое значение, называемое шагом обучения. Порядок шага обучения для нашего примера - 0,01.
Если ошибка на выходе равна -1, значит, веса нужно, наоборот, уменьшить.
С учетом этих соображений, для синапса, проходящего от нейрона номер i к нейрону с номером j, вес после корректировки можно определить следующим образом:

Где step - шаг обучения, e_j - ошибка на выходе j-го нейрона, а g_ij - коэффициент, учитывающий влияние изменения веса синапса на выходное значение при текущих значениях входа. Рассмотрим, например, нейрон №1 третьего слоя: он связан со всеми нейронами второго слоя. Если на выходе какого-то из нейронов второго слоя установилось значение 0, то, как ни меняй вес синапса, соединяющего этот нейрон с нашим, значение на нашем нейроне не изменится, ведь вес будет умножаться на 0. Поэтому производить корректировку этого синапса на основании данных текущего примера бессмысленно. А вот если на выходе нейрона второго слоя установилась 1, то при изменении веса синапса, соединяющего его с нашим нейроном №1, выходное значение нашего нейрона может измениться, т.е. можно исправить ошибку за счет корректировки веса.
На самом-то деле у коэффициента g куда более интересный математический смысл, но об этом - в отдельном посте.
Что ж, здесь мы вплотную подошли к этапу, где нам потребуется немножко математики. Прежде чем приступить к ней, посмотрим, как работает наша сеть после обучения.
Подадим на вход искаженные образы, и посмотрим, как распознает их система:
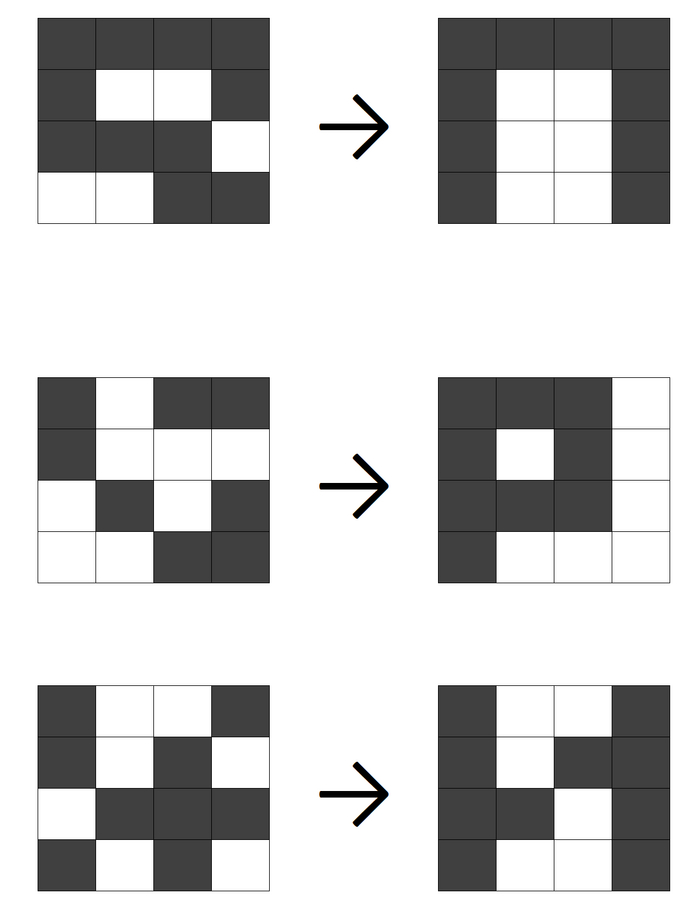
На волне постов о картинках в нейросетях, мне вспомнилось, что у нас в универе был обзорный курс, что-то типа "Методы искусственного интеллекта". Захотелось освежить в памяти, ну и решил поделиться тем, что удалось вспомнить, может, кому-то будет интересно)
Итак, сама концепция нейронной сети основана на реальной биологической структуре мозга. В мозгу есть специальные нервные клетки, собственно - нейроны. Они занимаются обработкой электрических сигналов, получаемых от органов чувств при их раздражении. Например, до наших ушей дошел звук, нервные окончания в ушах начали генерировать электрические импульсы, которые уходят в мозг, а вот уже мозг интерпретирует эти импульсы как, например, музкальное произведение.
Вернемся к нейронам. Каждая отдельная клетка имеет тело и отростки (дендриты и аксон), которыми она может соединяться с другими такими клетками, образуя синапсы (сами соединения). Схематично нейрон выглядит так:

Когда электрические (или химические) сигналы проходят через связи между клетками, они могут модифицироваться, скажем, ослабляться или усиливаться. Все пришедшие в тело клетки сигналы агрегируются, а результат выдается на все выходные отростки для передачи соседним клеткам. В итоге, учитывая огромное количество нейронов в нашем мозге, получаются сложные преобразования, которые выливаются в наши мысли, идеи и решения.
Именно этот принцип положен в основу искусственных нейронных сетей: каждый нейрон связан с несколькими соседними нейронами, от которых он получает информацию, агрегирует ее, и выдает нескольким соседним нейронам дальше. Причем, когда информация проходит по синапсу, соединяющему два нейрона, она может модифицироваться.
Рассмотрим нейронную сеть, называемую перцептроном:
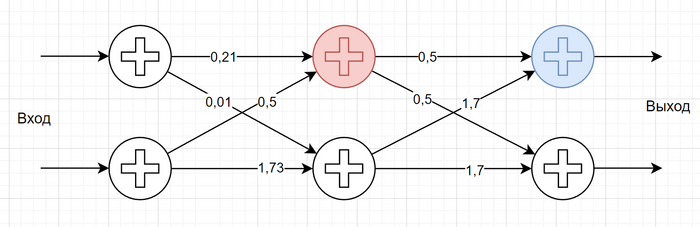
Она состоит из трех слоев, причем каждый нейрон связан со всеми нейронами следующего слоя и только с ними. Каждый нейрон суммирует все сигналы на входе, и, если результат больше 0 - выдает 1, а если нет - то 0.
Можно заметить, что на каждом синапсе-стрелочке написано число - это множитель, на который умножается значение при переходе по этой стрелочке. Например, если красный нейрон в результате суммирования и округления входов получил 1, то при передаче этой единицы синему нейрону она будет умножена на 0,5, и на вход этому нейрону придет значение 0,5. Данные коэффициенты называются весами синапсов.
Частный случай значения веса синапса - 0. Это будет означать, что сигнал по этому синапсу не передается, он разорван.
Сеть на картинке выглядит не очень-то полезной: ведь на вход мы можем подать всего два значения (и на выходе получаем только два). Но если увеличить количество строк, то значений можно подать очень много. Например, для обработки картинки такой сетью, на вход мы можем подать по три значения для каждого пикселя картинки, определяющие цвет этого пикселя: насыщенность красного, зеленого и синего цветов.
Понятно, что связей тогда будет огромное множество. На выходе после преобразования мы получим столько же пикселей, т.е. картинку такого же размера, но закрашенную совершенно непредсказуемыми цветами.
Нам же нужно получить результат, обладающей некоторой полезностью. Поэтому существует процесс обучения нейронной сети, который заключается в корректировке весов синапсов при оценке результата работы сети. Для выполнения этой процедуры существуют различные методы, один из которых - метод обратного распространения ошибки, ради которого и затевается эта серия постов)
