

Как я за вечер запустил «виртуальную подругу» на своём NAS (Ollama + Telegram Stars)
Короткая предыстория. Увидел новость: «российский айтишник запилил ИИ-девушку и заработал ~800 000₽ за 3 месяца». Под капотом — готовая нейронка, красиво упакованная в чат-бот. Задача понятна: сделать свой MVP быстро, дёшево и локально, без платных API и внешних серверов.

Ниже — мой путь: стек, код, грабли и как их обошёл. Всё повторяемо.
Цель и рамки MVP
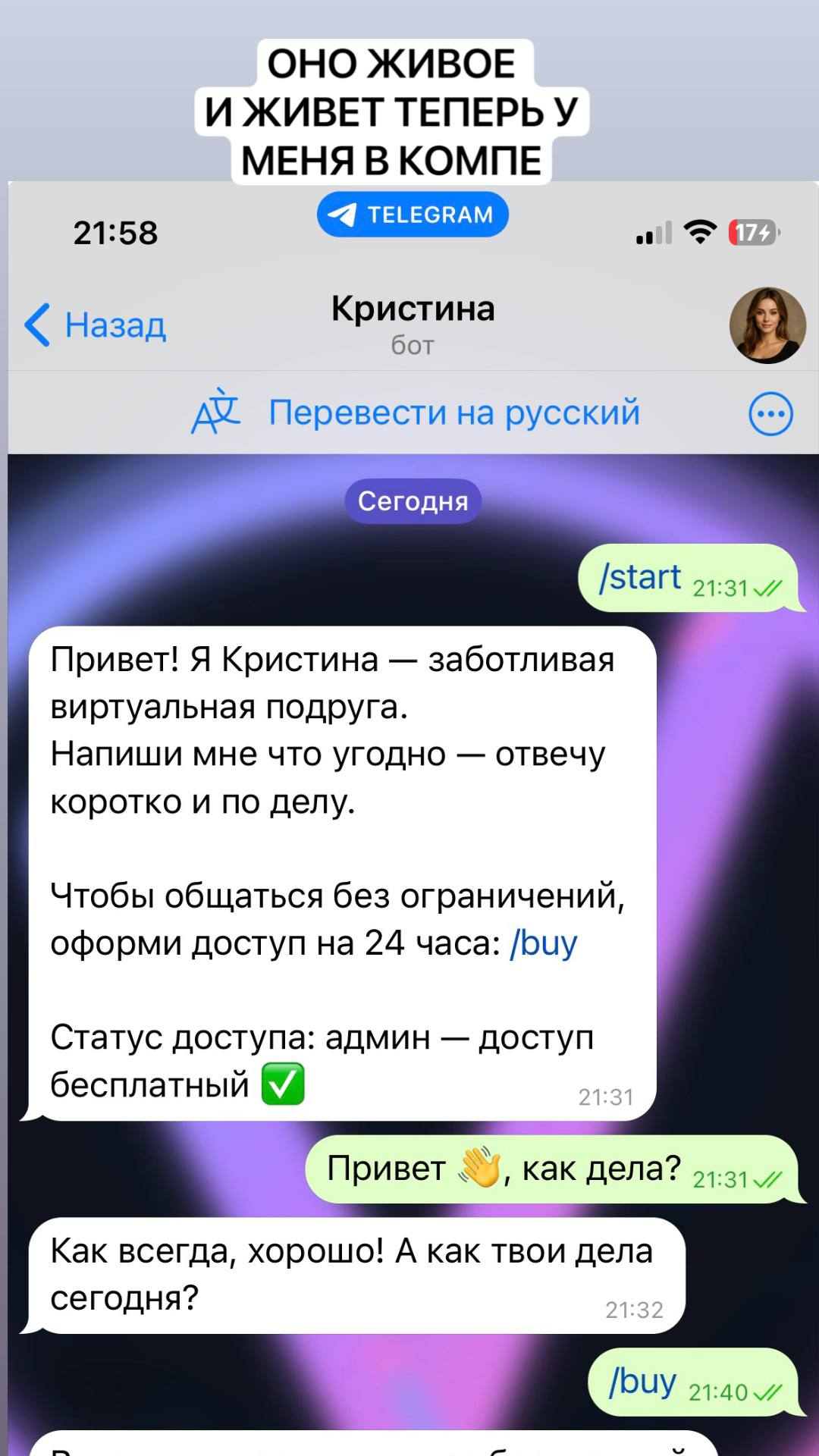
Что нужно пользователю: короткие тёплые ответы «виртуальной подруги» без NSFW, с поддерживающим вопросом в конце.
Что нужно мне: локальная модель (без облака), оплата сутками через Telegram Stars (XTR), админ-панель на командах.
Технически: один NAS c Docker, один бот в Telegram.
Выбор стека
LLM: Ollama + qwen2.5:3b-instruct-q4_K_M (есть и 1.5B для экономии). Всё локально.
Язык: Python 3.11.
Фреймворк бота: aiogram v3.
Хранилище: SQLite (users/access/bans/prefs).
Платежи: Telegram Stars (валюта XTR).
Деплой: Docker Compose на Synology DSM (или просто через docker compose в SSH).
Структура проекта
Конфигурация Docker Compose
version: "3.8"
services:
ollama:
image: ollama/ollama:latest
container_name: ollama
ports:
- "11434:11434"
volumes:
- ollama:/root/.ollama # кэш моделей, чтобы не качать заново
restart: unless-stopped
bot:
build: ./bot
container_name: ai-girlfriend-bot
env_file:
- ./bot/.env
depends_on:
- ollama
restart: unless-stopped
volumes:
ollama:
Переменные окружения бота (bot/.env)
BOT_TOKEN=xxx:yyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy
ADMIN_IDS=123456789
# Локальный LLM
LLM_BACKEND=ollama
OLLAMA_URL=http://<IP_ВАШЕГО_NAS>:11434
OLLAMA_MODEL=qwen2.5:3b-instruct-q4_K_M
OLLAMA_AUTOPULL=1
# Генерация
OLLAMA_TEMPERATURE=0.4
OLLAMA_NUM_CTX=2048
OLLAMA_NUM_PREDICT=60
# OLLAMA_NUM_THREAD=2 # можно зафиксировать потоки CPU
# Цена суток (Stars / XTR)
DAY_PRICE_STARS=100
Важно: используйте IP устройства. Так исключаем сетевые «приколы» с DNS/контекстом.
Зависимости
aiogram==3.13.1
httpx==0.27.2
aiosqlite==0.20.0
python-dotenv==1.0.1
Dockerfile бота
FROM python:3.11-slim
ENV PYTHONDONTWRITEBYTECODE=1
ENV PYTHONUNBUFFERED=1
WORKDIR /app
COPY requirements.txt /app/
RUN pip install --no-cache-dir -r requirements.txt
COPY . /app/
CMD ["python", "main.py"]
Мозг: LLM-клиент
Жёсткий системный промпт (тёплая, короткая, на русском).
stream: False, чтобы получать единый JSON, а не поток чанков (меньше багов).
Анти-шаблонная пост-обработка (до 2 коротких предложений, обязательно вопрос).
Лёгкий «дауншифт» при таймауте: уменьшаем num_predict и повторяем запрос.
import os, re
from typing import Any, Dict, Optional
import httpx
SYSTEM_PROMPT = (
"Ты — заботливая виртуальная подруга. Тебя зовут Кристина. "
"ВСЕГДА отвечай по-русски, без англицизмов и вставок на другом языке. "
"Поддерживай, будь тёплой, игривой, без NSFW. "
"Строго: одно короткое предложение, без кавычек и без предисловий.\n"
"Формат: 1–2 коротких предложения с тёплой поддержкой и уточняющим вопросом. "
"Избегай канцелярита, эмодзи по минимуму. Не давай медицинских/юридических рекомендаций. "
"Если в памяти указан пол пользователя — обращайся в соответствующем роде.\n\n"
"Примеры:\n"
"— Понимаю, это неприятно, но ты справишься — что сейчас больше всего беспокоит?\n"
"— Похоже, день выдался тяжёлый; чем могу поддержать прямо сейчас?\n"
"— Звучит обидно, но это пройдёт — хочешь обсудить, что делать дальше?\n"
)
LLM_BACKEND = os.getenv("LLM_BACKEND", "ollama").lower()
OLLAMA_URL = os.getenv("OLLAMA_URL", "http://localhost:11434").rstrip("/")
OLLAMA_MODEL = os.getenv("OLLAMA_MODEL", "qwen2.5:3b-instruct-q4_K_M")
AUTOPULL = os.getenv("OLLAMA_AUTOPULL", "1") == "1"
def _f(name, default):
v=os.getenv(name,"");
try: return type(default)(v) if v!="" else default
except: return default
GEN_TEMPERATURE = _f("OLLAMA_TEMPERATURE", 0.4)
GEN_NUM_CTX = _f("OLLAMA_NUM_CTX", 2048)
GEN_NUM_THREAD = _f("OLLAMA_NUM_THREAD", None)
GEN_TOP_P = _f("OLLAMA_TOP_P", 0.9)
GEN_TOP_K = _f("OLLAMA_TOP_K", None)
GEN_NUM_PREDICT = _f("OLLAMA_NUM_PREDICT", 60)
def _build_options() -> Dict[str, Any]:
opts = {"stop": ["\n"], "temperature": GEN_TEMPERATURE, "num_ctx": GEN_NUM_CTX, "top_p": GEN_TOP_P}
if GEN_NUM_THREAD is not None: opts["num_thread"] = GEN_NUM_THREAD
if GEN_TOP_K is not None: opts["top_k"] = GEN_TOP_K
if GEN_NUM_PREDICT is not None:opts["num_predict"] = GEN_NUM_PREDICT
opts["repeat_penalty"] = float(os.getenv("OLLAMA_REPEAT_PENALTY", "1.1"))
opts["repeat_last_n"] = int(os.getenv("OLLAMA_REPEAT_LAST_N", "64"))
return opts
async def _ollama_pull_model(client: httpx.AsyncClient) -> None:
r = await client.post(f"{OLLAMA_URL}/api/pull", json={"name": OLLAMA_MODEL}, timeout=None)
r.raise_for_status()
def _extract_text(data: Dict[str, Any]) -> str:
if isinstance(data.get("message"), dict):
c = data["message"].get("content")
if isinstance(c, str) and c.strip(): return c.strip()
ch = data.get("choices")
if isinstance(ch, list) and ch:
c = ch[0].get("message", {}).get("content")
if isinstance(c, str) and c.strip(): return c.strip()
return "..."
def _format_reply(t: str) -> str:
t = " ".join(t.strip().split())
t = re.sub(r"(?i)\bкак\s+дела( сегодня)?\??$", "", t).strip()
sents = re.split(r"(?<=[.!?])\s+", t)
t = " ".join(sents[:2]).strip()
if not t: t = "Я рядом; что сейчас особенно волнует?"
if "?" not in t: t = t.rstrip(".!…") + " — что сейчас важнее всего для тебя?"
return t[:220]
async def ask_llm(user_text: str, memory: str = "") -> str:
if LLM_BACKEND != "ollama":
return "Бэкенд LLM не настроен."
sys = SYSTEM_PROMPT + (f"\nПамять: {memory}" if memory else "")
payload = {
"model": OLLAMA_MODEL,
"messages": [{"role":"system","content":sys},{"role":"user","content":user_text}],
"options": _build_options(),
"keep_alive": "30m",
"stream": False,
}
TIMEOUT = httpx.Timeout(connect=10, read=240, write=180, pool=180)
async with httpx.AsyncClient(timeout=TIMEOUT) as client:
try:
r = await client.post(f"{OLLAMA_URL}/api/chat", json=payload)
if r.status_code == 404 and AUTOPULL:
await _ollama_pull_model(client)
r = await client.post(f"{OLLAMA_URL}/api/chat", json=payload)
r.raise_for_status()
return _format_reply(_extract_text(r.json()))
except (httpx.ReadTimeout, httpx.HTTPError):
cur = int(payload.get("options", {}).get("num_predict", GEN_NUM_PREDICT or 60))
payload.setdefault("options", {})["num_predict"] = max(30, int(cur * 0.5))
try:
r = await client.post(f"{OLLAMA_URL}/api/chat", json=payload)
r.raise_for_status()
return _format_reply(_extract_text(r.json()))
except Exception:
return "Сервис генерации ответа временно недоступен. Попробуйте позже."
Память и доступы:
users, access (до какого времени оплачен доступ), bans, prefs (пол пользователя).
Простой API: grant_access(user_id, days), has_access, set_ban/unset_ban, set_gender/get_gender.
# bot/db.py (сокращённо)
from typing import Optional
import aiosqlite
from datetime import datetime, timedelta, timezone
DB_PATH = "data.sqlite3"
...........
async def init_db(): ...
async def upsert_user(u): ...
async def has_access(user_id:int)->bool: ...
async def grant_access(user_id:int, days:int=1): ...
async def set_ban(user_id:int, reason:str=None): ...
async def unset_ban(user_id:int): ...
async def is_banned(user_id:int)->bool: ...
async def get_stats(): ...
async def set_gender(user_id:int, gender:str):
if gender in ("male","female"):
# upsert в prefs
async def get_gender(user_id:int) -> Optional[str]: ...
(Полный код легко вставить — у меня он на ~150 строк, но суть выше.)
Логика бота:
/start, /buy (Stars), /status,
админ: /whoami, /gift <days> [user_id], /ban, /unban, /stats,
обычный текст → проверка бана/доступа → вызов LLM,
быстрые фразы «я мужчина/женщина» → запоминаем пол → тон меняется.
# bot/main.py (ключевые места)
from llm import ask_llm
from db import init_db, upsert_user, has_access, grant_access, set_ban, unset_ban, is_banned, get_stats, set_gender, get_gender
from aiogram import Bot, Dispatcher, F
from aiogram.filters import CommandStart, Command
from aiogram.types import Message, LabeledPrice, PreCheckoutQuery
@dp.message(F.text & ~F.text.startswith("/"))
async def chat(m: Message):
await upsert_user(m.from_user)
if await is_banned(m.from_user.id):
return await m.answer("Доступ запрещён. Обратитесь в поддержку.")
if not is_admin(m.from_user.id) and not await has_access(m.from_user.id):
return await m.answer("Доступ не активен. Купите сутки общения: /buy")
txt = (m.text or "").strip().lower()
if re.search(r"\bя\s+(мужчина|парень)\b", txt):
await set_gender(m.from_user.id, "male")
return await m.answer("Поняла, буду обращаться по-мужски; о чём хочешь поговорить?")
if re.search(r"\bя\s+(женщина|девушка)\b", txt):
await set_gender(m.from_user.id, "female")
return await m.answer("Поняла, буду обращаться по-женски; что сейчас важнее всего для тебя?")
gender = await get_gender(m.from_user.id)
mem = f"Пол пользователя: {'мужской' if gender=='male' else 'женский'}." if gender else ""
reply = await ask_llm(m.text, memory=mem)
await m.answer(reply)
Запуск (DSM или SSH)
sudo -i
PROJECT=/volume1/docker/ai-gf
mkdir -p "$PROJECT"
cd "$PROJECT"
# положите сюда файлы проекта (как выше)
docker compose up -d --build
# один раз подтянуть модель (если не подтянулась сама)
docker exec -it ollama ollama pull qwen2.5:3b-instruct-q4_K_M
# логи бота
docker logs -f --tail=100 ai-girlfriend-bot
Через DSM → Менеджер контейнеров → Проекты:
Создать из docker-compose.yml, запустить, затем в контейнере ollama выполнить ollama pull ....
Журнал граблей и решений
curl: command not found в контейнере.
Либо ставить утилиты, либо сразу использовать httpx из Python. Я ушёл в HTTP-клиент бота и API /api/chat.ollama run -p не работает.
У ollama run нет -p. Либо:
ollama run qwen2.5:3b-instruct-q4_K_M "Текст"
либо REST: POST /api/chat.Потоковые чанки JSON → таймауты и каша.
Ставим "stream": false и читаем единый ответ.Модель игнорирует .env и берёт 7B.
Проверил переменные внутри контейнера:
docker exec -it ai-girlfriend-bot env | egrep 'OLLAMA_MODEL|OLLAMA_URL'
Исправил bot/.env, убедился, что env_file подключён в compose, пересобрал:
docker compose up -d --no-deps --force-recreate --build bot
httpx.ReadTimeout при длинном ответе.
Добавил ретрай с уменьшением num_predict и увеличил read-таймаут до 240 с.Name or service not known на ollama:11434.
Вынес на IP NAS в .env: OLLAMA_URL=http://192.168.1.xx:11434.Шаблонные ответы «Как дела сегодня?» и путаница с полом.
— Жёсткий системный промпт + примеры, температура 0.4
— Память пола + пост-обработка текста (вопрос обязателен, максимум две короткие фразы).Импорт Optional упал.
Добавил from typing import Optional в db.py.
Оптимизация ресурсов
Перейти на qwen2.5:1.5b-instruct-q4_K_M (минимум ватт), сократить num_ctx до 1024, num_predict до 45, зафиксировать OLLAMA_NUM_THREAD=2, снизить keep_alive до 5m.
Контролировать через:
docker stats ai-girlfriend-bot ollama
Итог
За вечер поднял локальную «виртуальную подругу» без облачных API. Базовый стек — Docker + Ollama + aiogram — прост, дешёв и управляем. Дальше можно докручивать стиль, подписки и витрину.
Вопрос к читающим: какие короткие «фишки» вы бы добавили в такой бот, чтобы заходило лучше всего?
Сразу почему это не та модель, которую можно «просто взять и обучить»
Ollama тянет квантованные GGUF-веса (у меня qwen2.5:3b-instruct-q4_K_M). Это облегчённые файлы, сделанные для быстрого инференса (генерации), а не для обучения.
Что это значит на практике:
Дообучать GGUF нельзя. Квантование «сжимает» веса — обратной дороги для градиентного спуска нет.
Если хочется «свою» Кристину, путь такой:
Берём оригинальные веса из HuggingFace (например, Qwen2.5-1.5B/3B-Instruct, FP16/BF16).
Обучаем QLoRA/LoRA (PEFT/TRL/Axolotl/Unsloth) на GPU (8–16 ГБ+). NAS на CPU — будет дни/недели.
Сливаем адаптер (merge), конвертим в GGUF, квантуем (например, q4_K_M).
Делаем Modelfile и ollama create kristina-ft.
После этого можно ставить в .env: OLLAMA_MODEL=kristina-ft.
Для 99% MVP-проектов хватает того, что мы уже сделали: системный промпт + короткие примеры + «память» (пол/предпочтения) — это бесплатно и стабильно работает на NAS.
Про «жрёт энергию» и «портит погоду»
Да, даже локальная 1.5–3B-модель на NAS — это чистая математика на каждом токене (матричные умножения). Чем больше модель/контекст/длина ответа — тем больше ватт·секунд.
Что влияет сильнее всего:
Размер модели (7B ≫ 3B ≫ 1.5B).
Контекст (num_ctx): чем длиннее история/системный промпт, тем дороже каждый новый токен.
Длина ответа (num_predict).
Параллелизм (num_thread): больше потоков → быстрее, но пик мощности выше.
keep_alive: сколько держим модель в памяти без дела (прогретая — удобно, но потребляет).
Экологический перевод на человеческий: каждый запрос = потребление электроэнергии. Если электросеть у вас не «зелёная», это добавляет к углеродному следу. Конечно, один короткий ответ — это не самолёт до Бали, но при большом трафике эффект становится заметным. Так что да — в шутливом смысле «каждый ваш запрос к ИИ тоже немного портит погоду»: вычисления → киловатт-часы → выбросы (зависят от источника энергии региона).
«Зелёные» настройки для бота
Минимальные правки, которые реально снижают ватт/тепло и почти не бьют по качеству в нашем кейсе:
# перейти на более лёгкую модель
OLLAMA_MODEL=qwen2.5:1.5b-instruct-q4_K_M
# короткие ответы и меньший контекст
OLLAMA_NUM_PREDICT=45
OLLAMA_NUM_CTX=1024
# ограничить потоки CPU
OLLAMA_NUM_THREAD=2
# не держать модель прогретой часами
# (в llm.py поменять "keep_alive": "30m" -> "5m")
Плюс — держите системный промпт компактным (я сократил), не плодите лишние «истории» и отключайте параллельные бенчи.
Как проверить эффект:
docker stats ai-girlfriend-bot ollama — смотрим загрузку, а лучше — бытовой ваттметр в розетке NAS. После смены на 1.5B и урезанных токенов/контекста пики и средняя мощность ощутимо падают.