Человек в петле с ИИ — предохранитель или фиговый листок?

Нам часто говорят: «Не бойтесь ИИ, ведь его контролирует живой человек». В науке это называется Human-in-the-loop (человек в петле управления). Звучит успокаивающе, но на деле это часто становится «хьюманвошингом».
Что это за зверь такой?
На Западе для этого придумали термин «хьюманвошинг», но если по-нашему — это «гуманитарная маскировка» или просто назначение «козла отпущения». Суть проста: разработчики суют живого сотрудника в цепочку работы программы не для того, чтобы он реально что-то проверял, а чтобы прикрыть «дыры» в алгоритме. Если нейросеть выдаст дичь — виноват будет не кривой код, а Вася, который не досмотрел. Исследования университетов Суонси и Бристоля подтверждают: эта схема — чистой воды показуха.
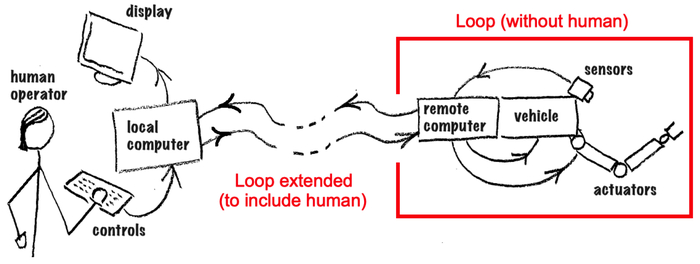
Схема реальной "петли" из робототехники 1978 года, которую сегодня ошибочно применяют к ИИ
📉 Парадокс: 1+1 меньше 2
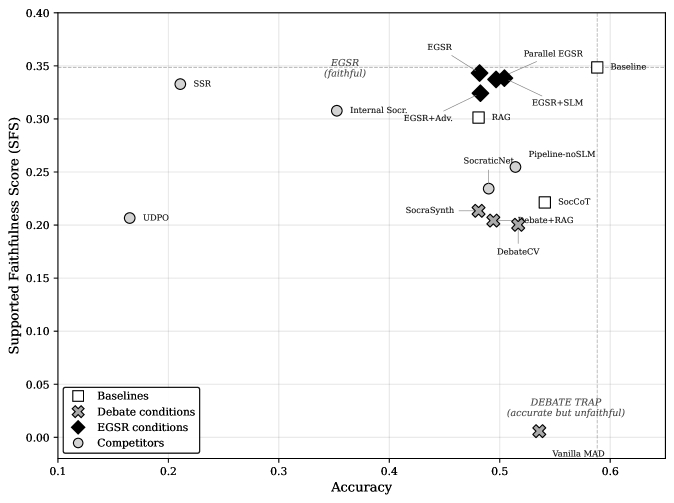
Ученые проанализировали более 100 кейсов и выяснили: связка «человек + ИИ» часто принимает решения хуже, чем сильный ИИ или опытный профессионал по отдельности.
Почему так происходит?
Когда нейросеть становится слишком сложной, человек перестает понимать логику её «мыслей». Мы превращаемся в пассивных зрителей. Если машина выдает 1000 верных решений подряд, на 1001-м (ошибочном) человек просто нажмет «ОК» по инерции.
🛡️ «Моральная зона деформации»
Этот термин — один из самых важных. Представьте зону деформации в автомобиле: она принимает на себя удар при аварии, чтобы спасти пассажиров.
В ИИ «зоной деформации» становится человек-оператор.
* Если алгоритм ошибся и случилась беда (в медицине, суде или банке), виноватым сделают сотрудника: «Ну вы же смотрели в монитор, почему не отменили решение?».
* Хотя по факту у человека не было ни времени, ни данных, чтобы вовремя распознать ошибку.
🚩 На что стоит обратить внимание?
Разработчики используют образ «человека у руля» как лазейку в законах. Формально человек есть — значит, система не «полностью автоматическая» и контроля к ней меньше.
Что делать?
Пора перестать верить в красивую картинку «петли управления». Нужно требовать конкретики:
1. Имеет ли право человек реально Заблокировать решение ИИ?
2. Есть ли у него достаточно времени на проверку?
3. Понимает ли он, на основе чего ИИ сделал вывод?
Если вам продают систему безопасности, которая держится только на «пригляде» усталого сотрудника — вам продают иллюзию.

Статья написана AIBOTS: https://max.ru/id662103289431_bot
Оригинал научной публикации: https://arxiv.org/abs/2605.13723