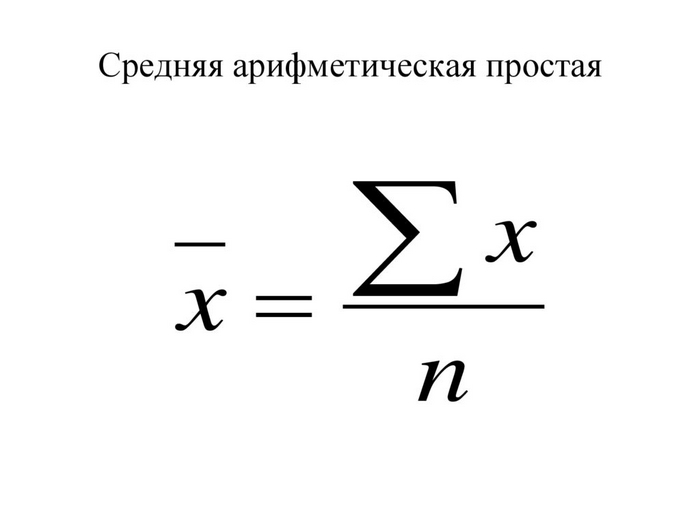Часть 2 - Сценарий нагрузочного тестирования "OLTP"
Выбирай сердцем
Задача эксперимента
Необходимо провести количественный анализ влияния версии Linux на производительность СУБД для разных дистрибутивов Linux : OS-1 и OS-2 .
СУБД расположены на разных виртуальных машинах. Гипервизор - один. Конфигурация файловых систем - одинаковая. Ресурсы хоста - одинаковые.
Сценарий "OLTP"
Тестовый запрос состоит только из выражений SELECT - UPDATE.
Все блоки использующиеся в запросе - находятся в распределенной области.
Для создания нагрузки используется pgbench.
Количество сессий к СУБД растет экспоненциально для каждого прохода теста.
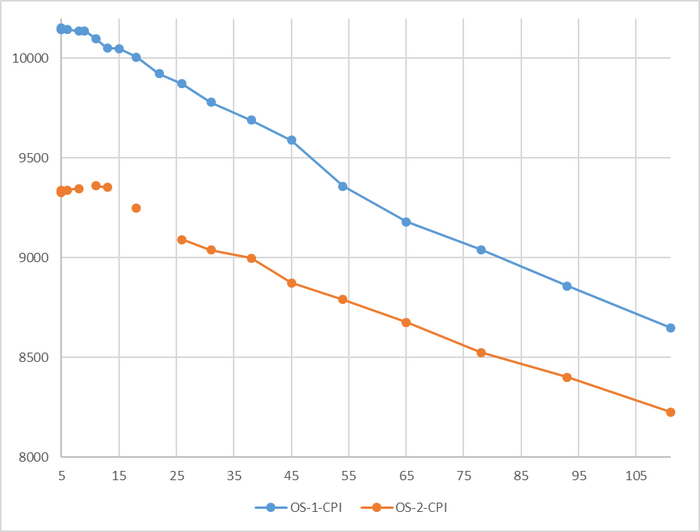
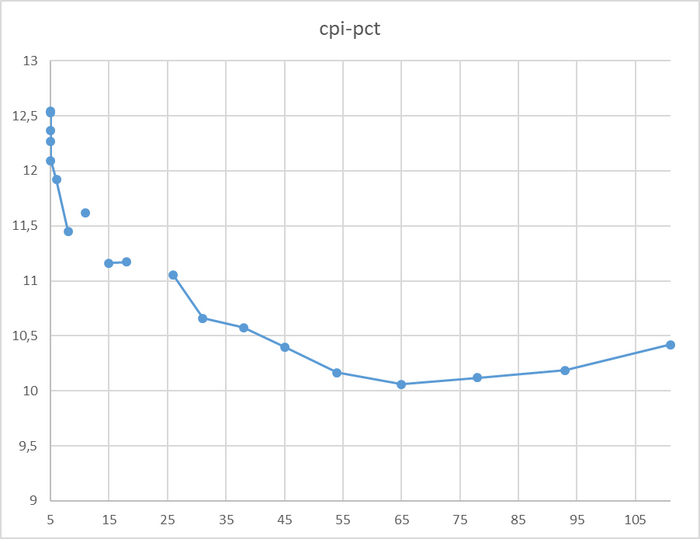
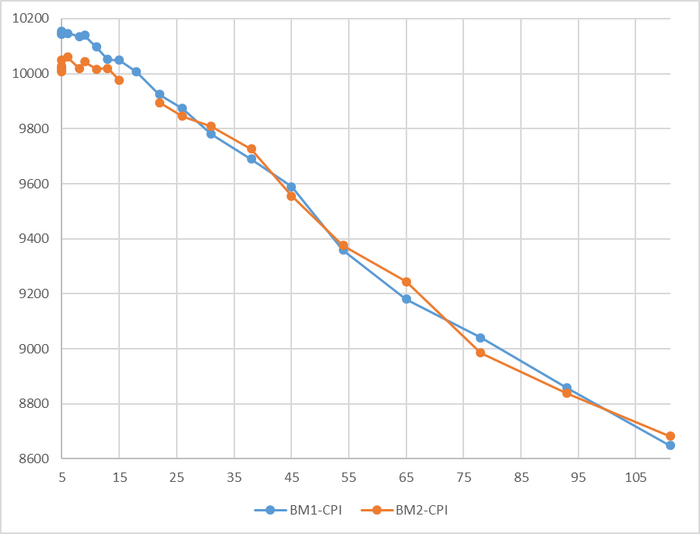
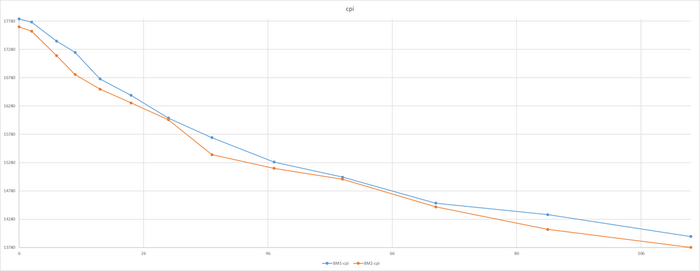
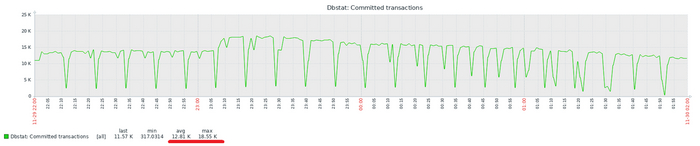
Производительность СУБД
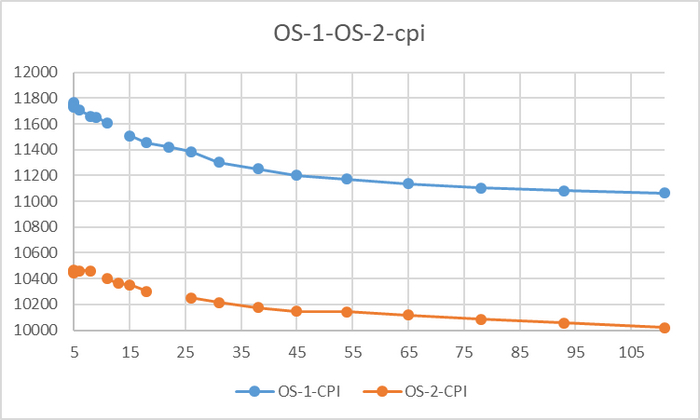
Разница производительности от 5-9%
Относительная разница производительности OS-1 и OS-2
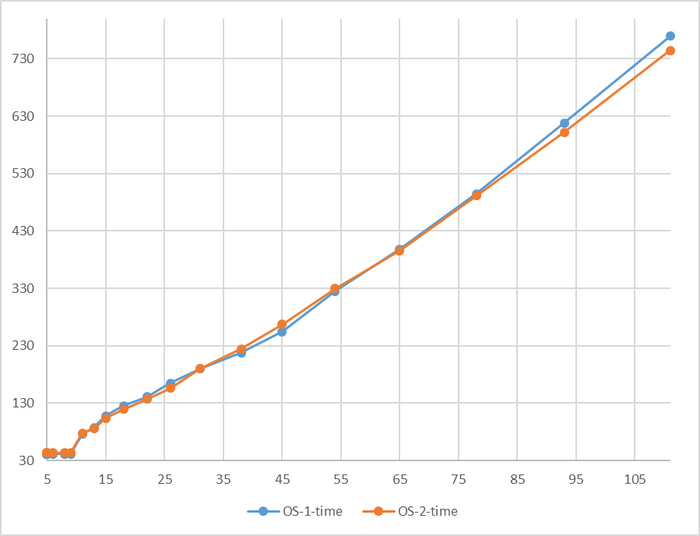
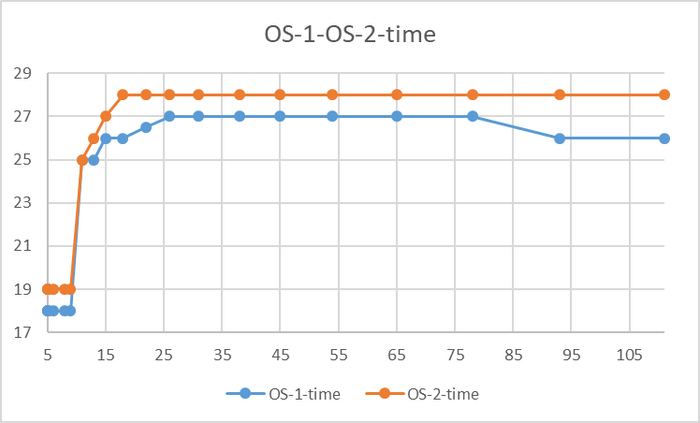
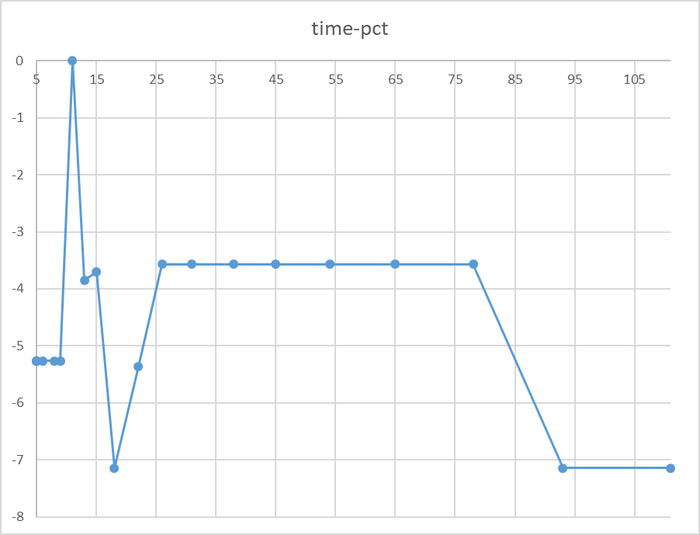
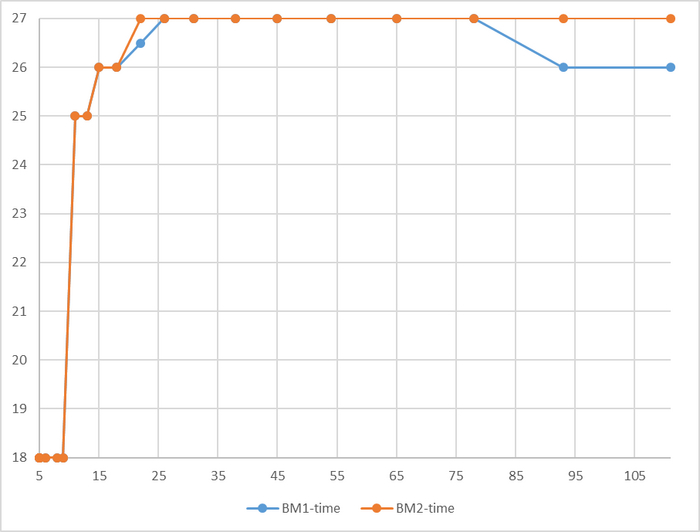
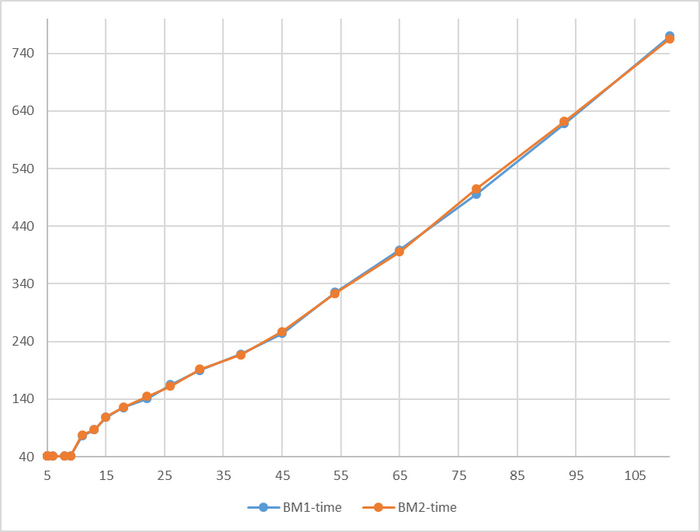
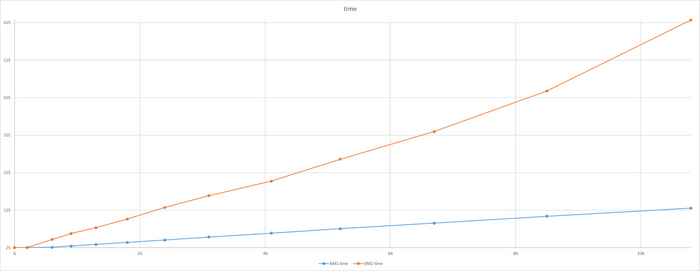
Время выполнения тестового запроса
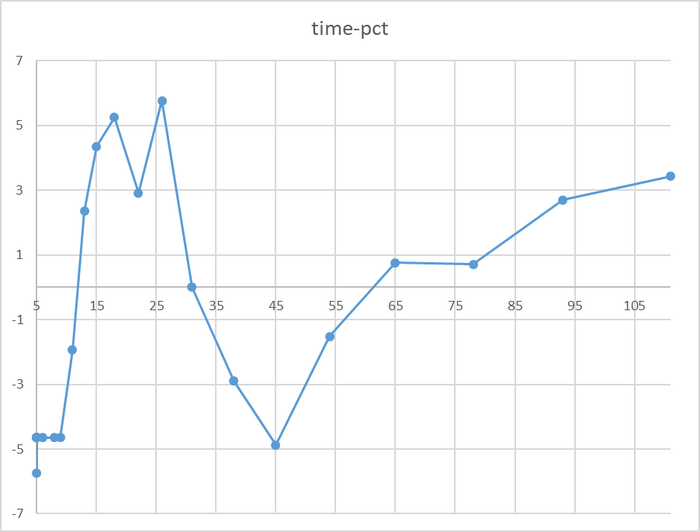
Разница времени выполнения тестового запроса от -5% до 7%
Относительная разница времени выполнения тестового запроса
Итог
Для сценария "OLTP", при нагрузке до 111 сессий - производительность СУБД развернутой на ОС Linux версии OS-1 превосходит производительность СУБД развернутой на ОС Linux версии OS-2 на 5-9% .
Часть 1 - сценарий нагрузочного тестирования "Select only"
Какой Linux выбрать ?
Задача эксперимента
Необходимо провести количественный анализ влияния версии Linux на производительность СУБД для разных дистрибутивов Linux : OS-1 и OS-2 .
СУБД расположены на разных виртуальных машинах. Гипервизор - один. Конфигурация файловых систем - одинаковая. Ресурсы хоста - одинаковые.
Сценарий "Select only"
Тестовые запрос состоит только из выражения SELECT.
Все блоки использующиеся в запросе - находятся в распределенной области.
Для создания нагрузки используется pgbench.
Количество сессий к СУБД растет экспоненциально для каждого прохода теста.
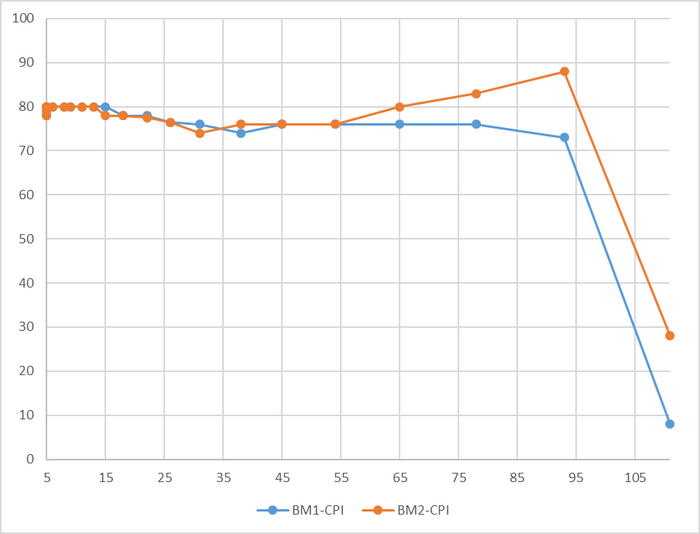
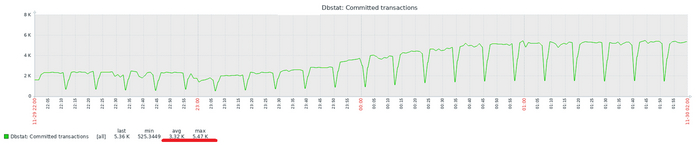
Производительность СУБД
Разница производительности от 10 до 13%
Относительная разница производительности OS-1 и OS-2
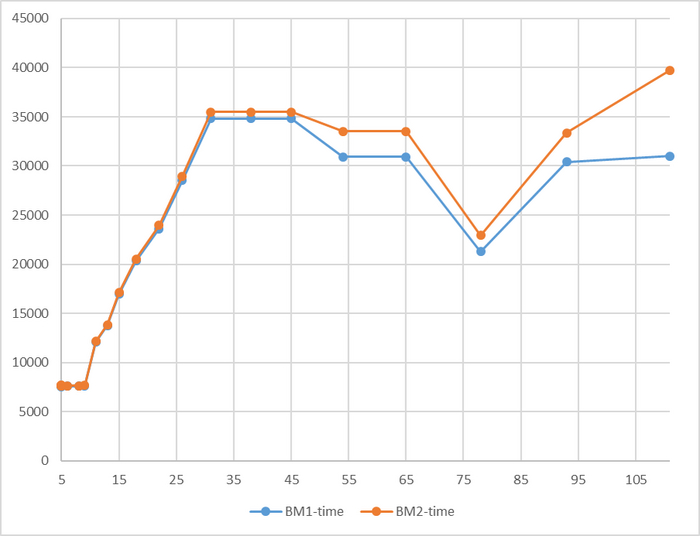
Время выполнения тестового запроса
Разница времени выполнения тестового запроса до 7%
Относительная разница времени выполнения тестового запроса
Итог
Для сценария "Select only", при нагрузке до 111 сессий - производительность СУБД развернутой на ОС Linux версии OS-1 превосходит производительность СУБД развернутой на ОС Linux версии OS-2 не менее чем на 10% .
Статья не о сравнении ОС, задача статьи - тестирование методологии сравнения производительности СУБД.
Задача
Имеется 2 виртуальных машины с развернутой СУБД PostgreSQL.
Версия СУБД - одинаковая.
ОС - одинаковая. Гипервизор - один.
Различие - системный диск HDD vs. SSD.
Необходимо количественно определить влияние расположения файлов ОС на производительность СУБД. Т.е. определить разницу в накладных расходах для создания серверного процесса для нового соединения .
Реализация эксперимента - сценарии нагрузки
Для оценки производительности и среднего времени выполнения тестового запроса используются 3 сценария нагрузки:
Select only (условный сценарий WEB): нагрузка в виде запроса .
TPC-B (условный сценарий OLTP): Нагрузка в виде транзакции состоящей из UPDATE-SELECT
Heavyweight (условный сценарий DSS): Нагрузка в виде тяжелого запроса SELECT..JOIN..ORDER BY + вычислительная нагрузка
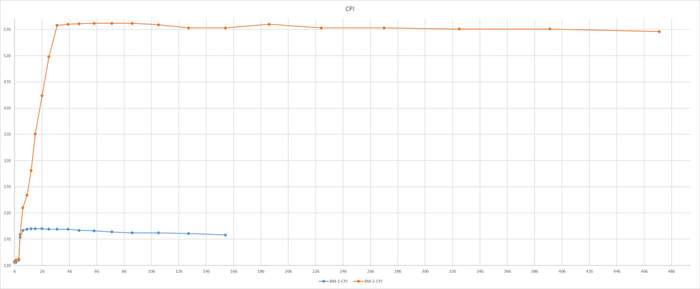
Индекс производительности СУБД(CPI) : операционная скорость
Время выполнения тестового запроса: скользящая медиана с периодом 1 час.
В реальной эксплуатации - применимо с существенными ограничениями.
Проблема
Имеется 2 виртуальные машины в облачном хранилище - версия СУБД одинаковая, гипервизор один , других ВМ в гипервизоре - нет.
Производительность СУБД
Разница в производительности СУБД не превышает 2.5%
Среднее время выполнения тестового запроса
Разница непрерывно растет и достигает 80%
В результате - производительность СУБД практически не отличается , а среднее время выполнения тестового запроса отличается кардинально. Как такое возможно ?
Причина
Использование при расчета значение mean_exec_time среднего арифметического .
Среднее арифметическое не всегда является идеальным показателем. Например, если ваши данные содержат очень высокие или низкие значения, они могут сильно исказить среднее. В таких случаях рассмотрите использование других статистических мер.
Для иллюстрации проблемы был проведен простой эксперимент
Серия запусков тестового запроса с фиксацией времени выполнения и искусственным выбросом(замедление выполнения) .
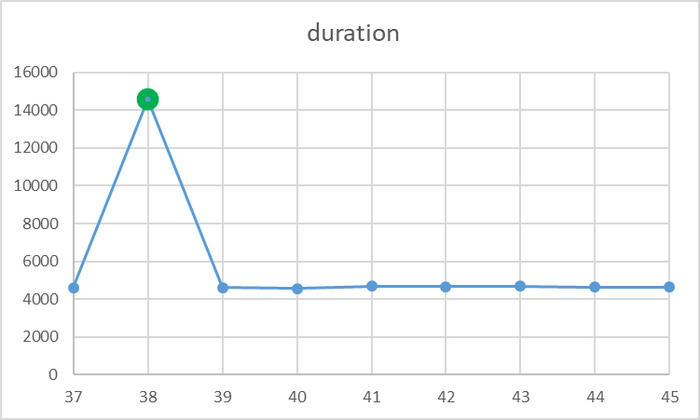
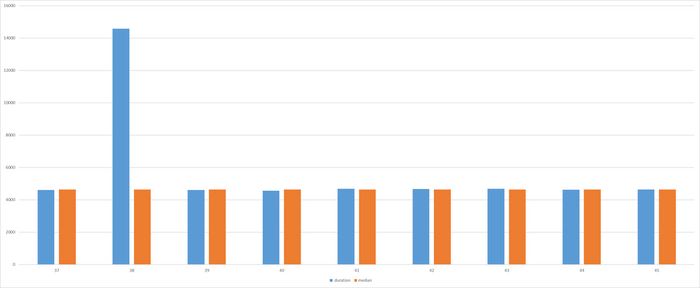
Результаты
Всего 1(один) выброс
id duration
37 4602
38 14581
39 4610
40 4569
41 4685
42 4666
43 4680
44 4621
45 4637
mean_exec_time = 5651.6708999
Достаточно всего одного выброса , что бы значение метрики весьма существенно изменилось .
Решение проблемы
Использование в качестве среднего значение - медианы
Медиана — это значение, которое делит упорядоченный набор данных на две равные части. Другими словами, половина значений в наборе данных меньше медианы, а другая половина — больше. Медиана является центральным значением в наборе данных.
В данном эксперименте медиана = 4637 . Данное значение вполне соответствует значению подсказываемому здравым смыслом при анализе результатов наблюдений.
Единичный выброс не влияет на значение медианы
Итог
Разница между значением длительности выполнения тестового запроса и mean_exec_time для штатной работы СУБД составляет от 17 до 19%.
Разница между значением длительности выполнения тестового запроса и медианой для штатной работы СУБД составляет от -1.5 до 1%.
Какое значение использовать для усреднения показателей - очевидно.
В дальнейшем, при анализе производительности, метрика mean_exec_time ( представления типа pg_stat_statments/pgpro_stats) исключается из показателей производительности СУБД.
При проведении анализа производительности СУБД нет задачи оценить стабильность работы( облачная инфраструктура в принципе нестабильна и подвержена существенным влияниям внешних факторов), есть задача оценить производительность СУБД.
Для тестирования использовался именно этот сценарий .
Конфигурация виртуальных машин
ВМ-1
Postgres Pro (enterprise certified) 15.8.1 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 11.4.1 20230605 (Red Soft 11.4.0-1), 64-bit
CPU = 8
RAM = 15
OC = RED 7.3
ВМ-2
Postgres Pro (enterprise certified) 14.11.3 on x86_64-pc-linux-gnu, compiled by gcc (Debian 6.3.0-18+deb9u1) 6.3.0 20170516, 64-bit
CPU = 24
RAM = 189
ОС = Astra Linux (Smolensk) 1.6
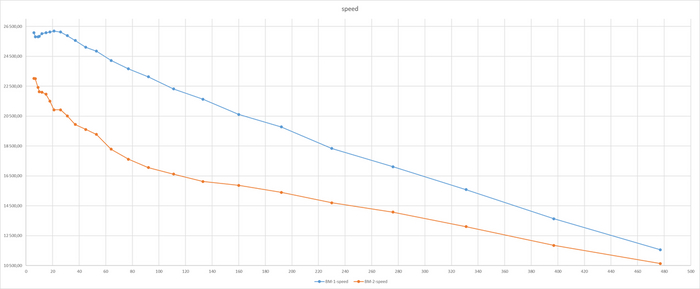
Итоги теста по сценарию TPC-B
Производительность ВМ-1 существенно выше ВМ-2
Т.е. по итогам данного теста получается - СУБД развёрнутая по шаблону ВМ-1 будет существенно производительнее ?
Что будет , если архитектор примет решение о выборе версии СУБД и запланирует ресурсы инфраструктуры на основании только данного теста ?
Решение проблемы
Одного теста для анализа производительности СУБД и ВМ - недостаточно.
Как было указано в документации:
Однако вы можете легко протестировать и другие сценарии, написав собственные скрипты транзакций.
Что и было сделано.
Для продолжения тестов, был подготовлен сценарий требующий серьезных вычислительных ресурсов - SELECT ... JOIN
Результат тестирования тяжелого запроса
ВМ-2 СУЩЕСТВЕННО производительнее чем ВМ-1
Все встало на свои места.
ВМ-1 даже не хватило ресурсов при количестве одновременных запросов свыше 160. При этом производительности ВМ-2 существенно выше производительности ВМ-1.
Итог
Нельзя принимать архитектурных решений на основании результатов одного только сценария нагрузочного тестирования
2. Для оценки производительности архитектурного решения по конкретной СУБД необходим комплекс разных сценариев нагрузочного тестирования.
Как минимум:
-Select only: оценка скорости чтения данных из СУБД
-Standard: оценка производительности СУБД в условиях конкуренции за блокировки.
-Heavyweight: оценка производительности СУБД при выполнении тяжелых вычислительных и ресурсоемких операций.
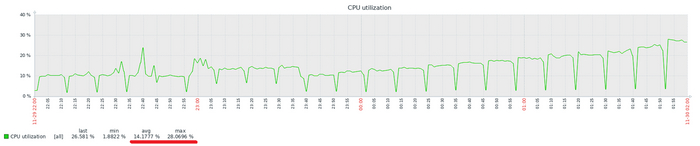
Мониторить утилизацию CPU отдельно — не имеет смысла. Мониторить надо производительность СУБД, в первую очередь.
Рост утилизации CPU — не инцидент. Снижение производительности СУБД и рост утилизации CPU — инцидент.
Высокая утилизация CPU и рост производительности СУБД — показывает эффективное использование предоставленных ресурсов. Низкая утилизация CPU и низкая производительность СУБД в рабочее время — зря потраченные средства.
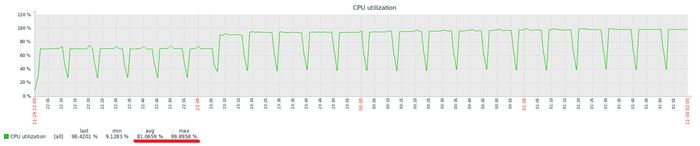
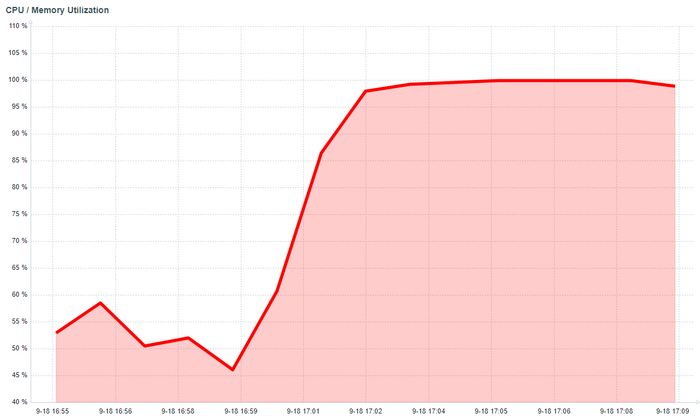
Обычные последствия после получения оповещения мониторинга «CPU Utilization High» — все в панике, лихорадочные поиски причин, аварийная ситуация, конфколлы и т. д. и т. п. Всё, как положено для ИБД.
Однако, если посмотреть на ситуацию чуть подробнее, то выясняется, что всё не так печально, а даже совсем наоборот и причин для паники — никаких.
Что же происходит с СУБД в данный момент ?
А с СУБД, всё хорошо, достаточно посмотреть на метрики мониторинга.
Самое главное: производительность СУБД — не снижается
Почему, производительность СУБД не снижается, ведь CPU в полку?
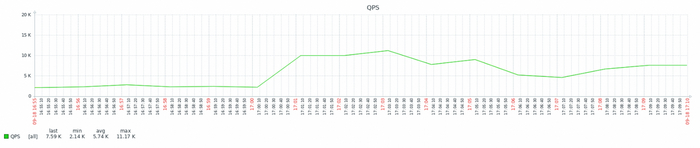
Причина 1: Количество запросов в секунду — не снижается
Количество запросов в секунду не снижается с ростом утилизации СУБД
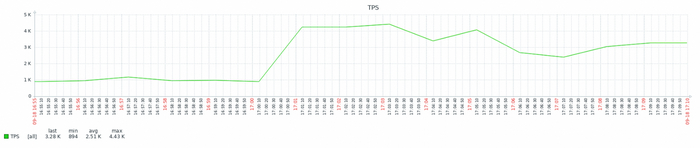
Причина 2: Количество транзакций в секунду — не снижается
Количество транзакций в секунду - не снижается с ростом утилизации CPU
Т.е. можно сделать простой вывод‑ работоспособность СУБД не уменьшилась, а скорее наоборот — увеличилась и рост утилизации CPU это лишь следствие. Или другими словами — в данной, конкретной ситуации СУБД максимально эффективно использует предоставленные ресурсы.
Данный тезис подтверждается метриками, показывающими количество обрабатываемой СУБД информации за единицу времени (что собственно говоря, с известными сейчас допущениями, и определяет в некотором смысле производительность СУБД).
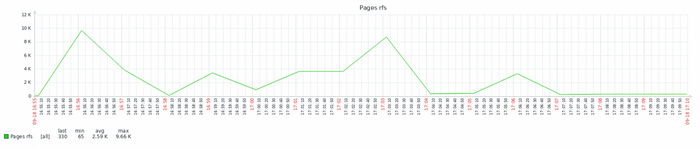
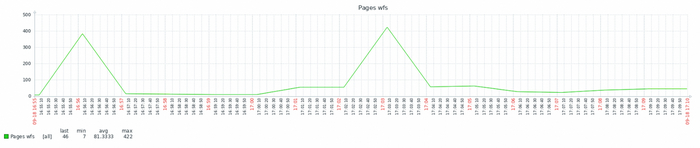
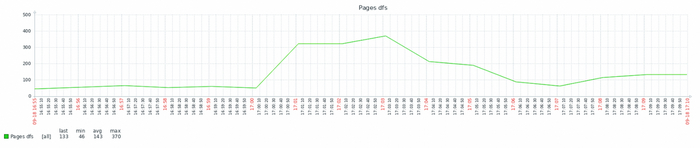
Количество страниц разделяемой области - прочитанных в секунду
Количество страниц разделяемой области - записанных в секунду
Количество страниц разделяемой области - измененных в секунду
Выводы
Мониторить утилизацию CPU отдельно — не имеет смысла. Мониторить надо производительность СУБД, в первую очередь.
Рост утилизации CPU — не инцидент. Снижение производительности СУБД и рост утилизации CPU — инцидент.
Высокая утилизация CPU и рост производительности СУБД — показывает эффективное использование предоставленных ресурсов. Низкая утилизация CPU и низкая производительность СУБД в рабочее время — зря потраченные средства.