

PG_EXPECTO как инструмент валидации гипотез по производительности СУБД
Взято с основного технического канала Postgres DBA (возможны правки в исходной статье).
Настоящее исследование осуществлено с применением инструментария pg_expecto, обеспечивающего строгую методологию репрезентативного нагрузочного тестирования. Данный инструмент позволил провести сравнительный анализ двух дискретных конфигураций СУБД PostgreSQL в контролируемых и идентичных условиях, моделирующих устойчивую OLAP-нагрузку. Ниже представлено краткое изложение методологии эксперимента, включая описание стенда, генерации нагрузочного паттерна и ключевых варьируемых параметров, что обеспечивает полную воспроизводимость и верифицируемость полученных результатов. Основной целью являлась эмпирическая проверка гипотезы о влиянии реконфигурации областей памяти (shared_buffers и work_mem) на комплексные показатели производительности системы.

pg_expecto: где гипотезы встречаются с метриками.
Теоретическая часть и рекомендация нейросети
📉 Гипотеза по уменьшению shared_buffers
Для данной OLAP-нагрузки и текущей конфигурации сервера снижение размера shared_buffers с 4 ГБ до 1-2 ГБ, с одновременным увеличением work_mem, приведет к росту общей производительности системы. Основная цель — не просто уменьшить кэш БД, а перенаправить высвободившуюся оперативную память на выполнение операций в памяти и ослабить нагрузку на подсистему ввода-вывода.
Параметры операционной системы
vm.dirty_expire_centisecs = 3000
vm.dirty_ratio = 30
vm.dirty_background_ratio = 10
vm.vfs_cache_pressure = 100
vm.swappiness = 10
read_ahead_kb = 4096
Нагрузка на СУБД в ходе экспериментов
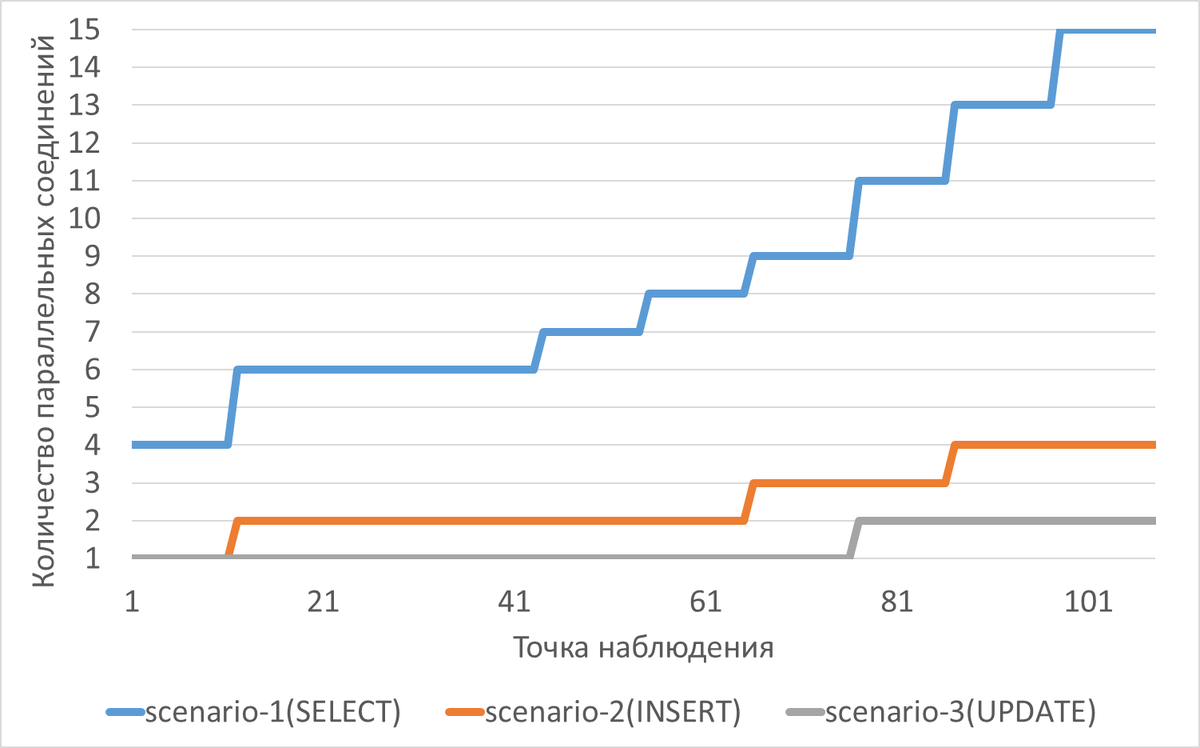
Эксперимент-1: shared_buffers = 4GB + work_mem=32MB
work_mem
----------
32MB
shared_buffers
----------------
4GB
Эксперимент-2: shared_buffers = 2GB + work_mem=256MB
work_mem
----------
256MB
shared_buffers
----------------
2GB
Корреляционный анализ ожиданий
Операционная скорость
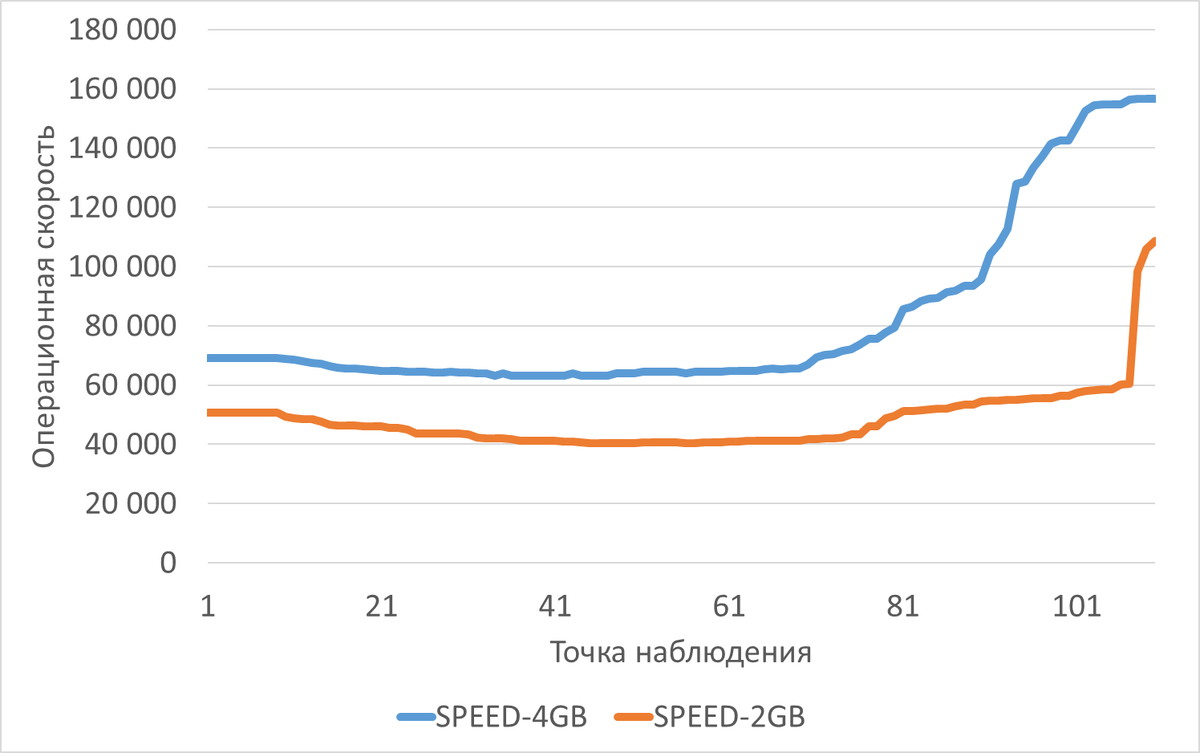
Среднее снижение операционной скорости при shared_buffers=2GB(work_mem=256MB) составило 38.38%.
Ожидания типа IO
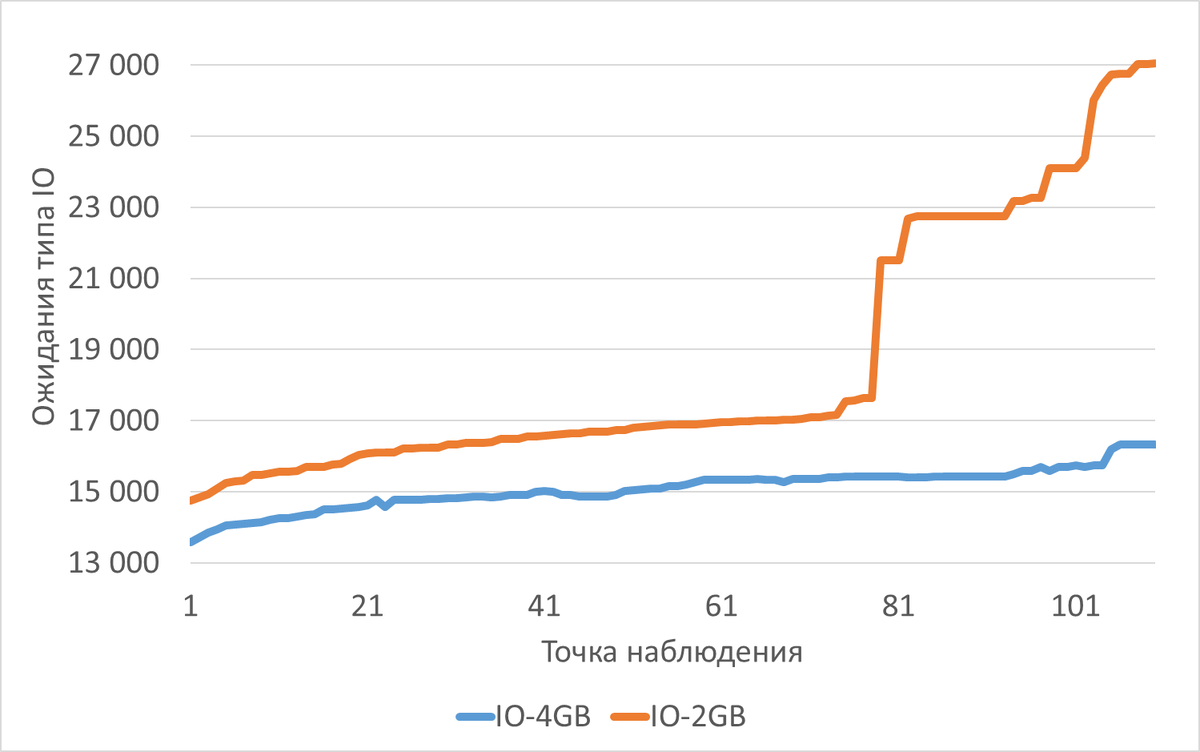
Среднее увеличение ожиданий типа IO при shared_buffers=2GB(work_mem=256MB) составило 22.70%.
Ожидания типа IPC
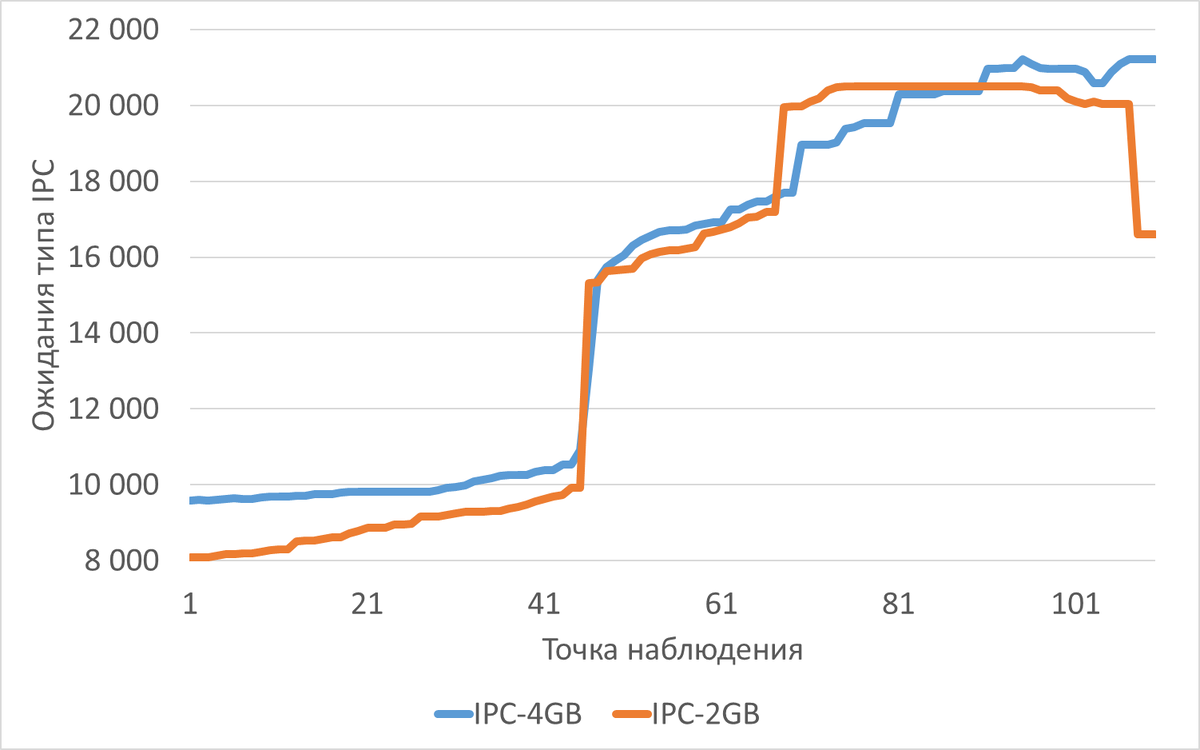
Среднее снижение ожиданий типа IPC при shared_buffers=2GB(work_mem=256MB) составило 4.78%.
Производительность подсистемы IO(IOPS) для файловой системы /data
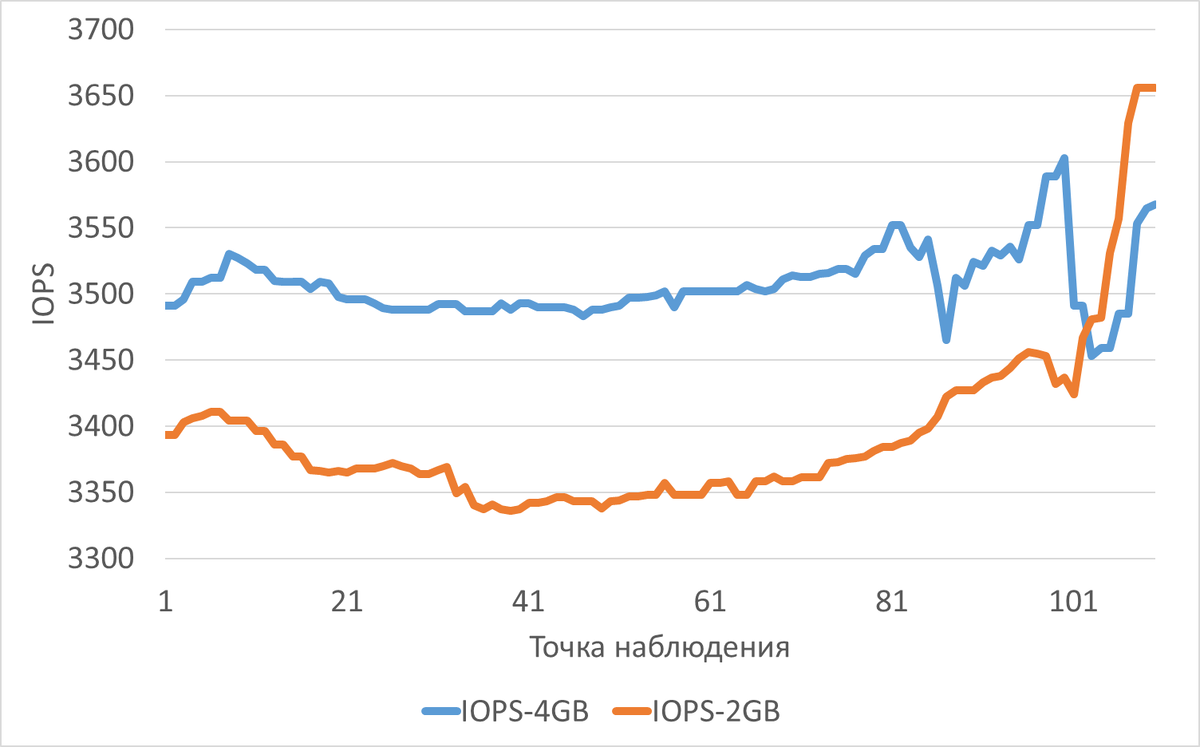
Среднее снижение IOPS при shared_buffers=2GB(work_mem=256MB) составило 3.29%.
Пропускная способность подсистемы IO(MB/s) для файловой системы /data
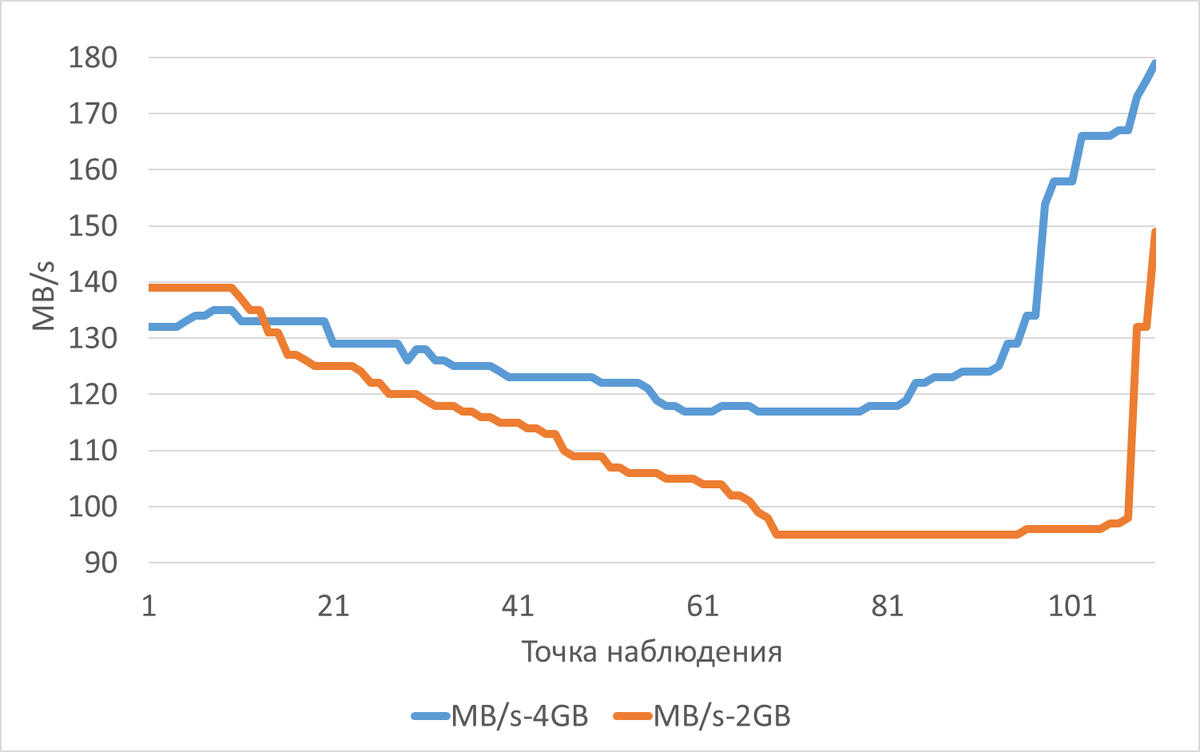
Среднее снижение пропускной способности(MB/s) при shared_buffers=2GB(work_mem=256MB) составило 313.74%.
Сводный отчет по влиянию параметров shared_buffers и work_mem на производительность инфраструктуры при OLAP-нагрузке
1. Общие характеристики нагрузки
Нагрузка соответствует OLAP-сценарию (аналитические запросы, большие объёмы данных).
В обоих экспериментах наблюдался рост нагрузки (Load average увеличился с 5 до 22).
Параметры экспериментов:
Эксперимент-1: shared_buffers = 4GB, work_mem = 32MB
Эксперимент-2: shared_buffers = 2GB, work_mem = 256MB
2. Влияние на производительность ввода-вывода (I/O)
Эксперимент-1 (4GB / 32MB)
Высокий I/O wait (wa): 100% наблюдений с wa > 10%.
Корреляция ожиданий IO и записи (bo): высокая (0.6533), система ограничена производительностью записи на диск.
Состояние процессов (b): слабая корреляция с ожиданиями IO (0.2611), количество процессов в состоянии непрерываемого сна не возрастает значительно.
Отношение прочитанных блоков к изменённым: 177.98, подтверждение OLAP-нагрузки.
Эксперимент-2 (2GB / 256MB)
Высокий I/O wait (wa): 97.27% наблюдений с wa > 10%.
Корреляция ожиданий IO и записи (bo): высокая (0.6719), система также ограничена записью.
Состояние процессов (b): очень высокая корреляция с ожиданиями IO (0.8774), процессы всё чаще переходят в состояние непрерываемого сна (ожидание диска).
Отношение прочитанных блоков к изменённым: 268.01, нагрузка ещё более ориентирована на чтение.
Сравнение
Уменьшение shared_buffers с 4GB до 2GB привело к усилению корреляции между ожиданием IO и блокированными процессами.
В обоих случаях система ограничена производительностью записи, но во втором эксперименте дисковые ожидания сильнее влияют на состояние процессов.
3. Влияние на использование оперативной памяти (RAM)
Эксперимент-1 (4GB / 32MB)
Свободная RAM: менее 5% в 100% наблюдений.
Свопинг (swap in/out): используется незначительно (в 9.01% и 1.8% наблюдений соответственно).
Эксперимент-2 (2GB / 256MB)
Свободная RAM: менее 5% в 100% наблюдений.
Свопинг: не используется (0% наблюдений).
Сравнение
Оба эксперимента показывают критически низкое количество свободной RAM.
Свопинг практически отсутствует, что может указывать на эффективное использование файлового кэша ОС.
4. Влияние на эффективность кэширования (Shared buffers)
Эксперимент-1 (4GB / 32MB)
Hit Ratio: 55.36% (критически низкий).
Корреляция hit/read: очень высокая (0.9725), кэширование связано с большим чтением с диска.
Эксперимент-2 (2GB / 256MB)
Hit Ratio: 38.58% (ещё ниже, критически низкий).
Корреляция hit/read: очень высокая (0.8698), аналогичная картина.
Сравнение
Уменьшение shared_buffers с 4GB до 2GB привело к снижению Hit Ratio на ~16.78%.
В обоих случаях кэширование недостаточно эффективно для данной нагрузки.
5. Влияние на загрузку центрального процессора (CPU)
Эксперимент-1 (4GB / 32MB)
Корреляция LWLock и user time: очень высокая (0.9775).
Корреляция LWLock и system time: очень высокая (0.9092).
Очередь процессов (r): превышение числа ядер CPU в 16.22% наблюдений.
System time (sy): не превышает 30% (все наблюдения).
Эксперимент-2 (2GB / 256MB)
Корреляция LWLock и user time: очень высокая (0.8574).
Корреляция LWLock и system time: высокая (0.6629).
Очередь процессов (r): превышение числа ядер CPU в 3.64% наблюдений.
System time (sy): не превышает 30% (все наблюдения).
Сравнение
В Эксперименте-1 выше корреляция LWLock с системным временем, что может указывать на большее количество системных вызовов и переключений контекста.
Очередь процессов (r) чаще превышает число ядер CPU в Эксперименте-1, но в обоих случаях это не является критичным.
6. Выводы по влиянию параметров
Уменьшение shared_buffers с 4GB до 2GB:
Привело к снижению Hit Ratio (с 55.36% до 38.58%).
Усилило корреляцию между ожиданием IO и блокированными процессами.
Не вызвало существенных изменений в использовании свопинга и свободной RAM.Увеличение work_mem с 32MB до 256MB:
Не компенсировало снижение эффективности кэширования при уменьшении shared_buffers.
Не привело к значительным изменениям в поведении CPU и очереди процессов.Общий характер нагрузки (OLAP) подтверждается высоким отношением чтения к записи и сильной зависимостью производительности от операций ввода-вывода.
Сводный отчет по влиянию параметров shared_buffers и work_mem на производительность подсистемы IO диска vdd для OLAP-нагрузки
1. Общая характеристика инфраструктуры и экспериментов
Диск данных: vdd (100 ГБ, LVM-том 99 ГБ, точка монтирования /data)
Конфигурация сервера:
8 CPU ядер
8 ГБ RAM
Отдельные диски для WAL (/wal) и логов (/log)Параметры сравнения:
Эксперимент 1: shared_buffers = 4 ГБ, work_mem = 32 МБ
Эксперимент 2: shared_buffers = 2 ГБ, work_mem = 256 МБПродолжительность тестов: ≈110 минут каждый
2. Количественные показатели производительности подсистемы IO
2.1. Средние значения по экспериментам
Эксперимент 1 (shared_buffers=4GB, work_mem=32MB):
Средняя утилизация диска: 90-94% → 80% (снижение к концу теста)
Средний IOPS: ≈3500 операций/сек
Средняя пропускная способность: ≈130 МБ/с → 180 МБ/с (рост к концу)
Среднее время ожидания чтения: 9-14 мс
Среднее время ожидания записи: 6-7 мс
Средняя длина очереди: ≈43
Средняя загрузка CPU на IO: ≈24%
Эксперимент 2 (shared_buffers=2GB, work_mem=256MB):
Средняя утилизация диска: 93-97% (стабильно высокая)
Средний IOPS: ≈3400 операций/сек
Средняя пропускная способность: ≈139 МБ/с → 95-149 МБ/с (колебания)
Среднее время ожидания чтения: 10-19 мс
Среднее время ожидания записи: 7-10 мс
Средняя длина очереди: ≈33 → 61 (рост)
Средняя загрузка CPU на IO: ≈28% → 9% (снижение)
3. Качественные характеристики нагрузки
3.1. Характер ограничения производительности
Эксперимент 1:
Тип ограничения: Пропускная способность диска
Корреляция скорость-MB/s: Очень высокая (0.8191)
Корреляция скорость-IOPS: Слабая (0.4128)
Вывод: Производительность определяется объемом передаваемых данных
Эксперимент 2:
Тип ограничения: Количество операций ввода-вывода
Корреляция скорость-IOPS: Очень высокая (0.9256)
Корреляция скорость-MB/s: Слабая (0.1674)
Вывод: Нагрузка чувствительна к количеству IO операций
4. Влияние изменения параметров на поведение системы
4.1. Динамика изменения показателей во времени
Эксперимент 1 (shared_buffers=4GB):
Утилизация диска снижается с 94% до 80% к концу теста
Пропускная способность растет с 132 МБ/с до 180 МБ/с
Загрузка CPU на IO снижается с 28% до 18%
Стабильные показатели IOPS и времени отклика
Эксперимент 2 (shared_buffers=2GB):
Высокая и стабильная утилизация диска (93-97%)
Колебания пропускной способности (139 → 95 → 149 МБ/с)
Значительный рост длины очереди (33 → 61)
Увеличение времени ожидания чтения (10 → 19 мс)
Снижение загрузки CPU на IO (28% → 9%)
4.2. Сравнительные изменения при уменьшении shared_buffers и увеличении work_mem
Утилизация диска: Повысилась и стабилизировалась на высоком уровне
Время отклика: Увеличилось время ожидания операций чтения
Длина очереди: Выросла в 1.8 раза к концу теста
Загрузка CPU на IO: Снизилась в 3 раза
Характер нагрузки: Сместился с пропускной способности на IOPS-ограниченный режим
Стабильность пропускной способности: Ухудшилась, появились значительные колебания
5. Выводы о влиянии конфигурации на OLAP-нагрузку
5.1. Конфигурация shared_buffers=4GB, work_mem=32MB:
Обеспечивает более предсказуемую пропускную способность
Демонстрирует улучшение производительности в ходе теста
Оптимальна для операций, требующих последовательного чтения больших объемов данных
Меньшая длина очереди и время отклика
5.2. Конфигурация shared_buffers=2GB, work_mem=256MB:
Создает более высокую и стабильную нагрузку на диск
Приводит к увеличению времени отклика операций
Смещает характер нагрузки в сторону большего количества мелких операций
Снижает нагрузку на CPU для операций ввода-вывода
Увеличивает глубину очереди запросов к диску
Postgres DBA
203 поста27 подписчиков
Правила сообщества
Пока действуют стандартные правила Пикабу.