

И снова про алгоритмы и структуры данных...
Когда много занимаешься музыкой и продвигаешь свой проект в интернете, сталкиваешься с огромным количеством откровенно бесящих программиста вещей.

На работе, за компом
У меня основная профессия - айтишник, пишу код на Java и других языках, поэтому хорошо понимаю, что происходит в тех или иных сервисах, когда они тормозят, лагают, выдают «неожидаемое» поведение.
Особенно выделяются конечно же понты, приукрашивания, кликбэйт и подобные вещи, которые обильно поджариваются характерным, для русского сознания, флёром.
Спойлер: будет много тавтологии и повторяющихся слов, простите, такая тема материала))
Немного истории...
В нулевые годы студенту, который хочет стать программистом, преподаватели и старшие коллеги как правило снисходительно советовали "выучить алгоритмы".
И сразу же на повестке появлялись две книги "Классические алгоритмы программирования" и "Алгоритмы и структуры данных".
Буквально с этого момента, на пустом месте, появляется ярко выраженная для российского обывателя особенность - выпендреж и "припонтовывание" всего и вся.
А именно - само слово АЛГОРИТМЫ в названиях книг, в статьях и других текстах.
Русский язык так устроен, что абсолютно всё, что можно написать или произнести - нужно сразу же приукрасить.
Поэтому названия книг "Классические алгоритмы программирования" и "Алгоритмы и структуры данных" так классно, лаконично и солидно выглядят.
А далее происходит следующее: в мозг читателя или собеседника «вбивается» слово Алгоритмы, как самое важное, а всё остальное - те же структуры данных уходят как бы на второй план.

И в этом, наверное, САМАЯ главная ошибка современного IT. Алгоритмы сами по себе бессмысленны, если нет структур, к которым они применяются.

Известная книга
Однако, запомнилось-то красивое, понтовое. Благозвучное слово или словосочетание.
А теперь, когда мир IT развивается бешенными темпами, эта классическая "установка" приводит
к огромному количеству багов
к некорректной и нестабильной работе
к жору ресурсов
и к иным проблемам
Кстати, я наверное загнул именно с русским сообществом, в принципе и англоязычное такое же, ведь там по аналогичным правилам существует и алфавит, и календарь и прочие общечеловеческие изобретения.
Просто в России понты "бустятся" кратно. И в быту, и в технологиях.
Пример - произношения слов.
Я специально написал "в нулевые годы", а не цифрами или синонимично.
Никто не говорит "в нолевые" годы - звучит коряво.
Но ноль, нуль и null - вполне.
Или ударения в физических "Бином Ньютона" и "кольца Ньютона" - каждый раз меняется для благозвучности. Здесь характерное для русского произношения правило - как лучше звучит, так и круче!

Кольца Ньютона. Наблюдаются в микроскопе - берешь глаз и смотришь!
Вернемся к алгоритмам - слово потрясающее, начинается на А, содержит в себе столько "неопределенности".
Действительно, alghoritms - это целая отрасль науки или даже общая область в других областях: алгоритмы оптимизации, нейро-сетевые алгоритмы и другие. Этого полно.
Но забывается одна важнейшая деталь.
Еще раз: алгоритм сам по себе - БЕСПОЛЕЗЕН. В особенности без задачи и без сущностей, к которым он прилагается.
Еще пример
Простая функция f(x)=4 из школы. Да хоть ты тресни к ней применять градиентный спуск или метод Ньютона для поиска минимума. Дураку понятно, что при любых значениях x достигается и минимум, и максимум y=4.
Нам не нужны сложные алгоритмы оптимизации, чтобы найти экстремум. Здесь достаточно метода "пристального взора". А еще лучше сформулировать так: Соберите требования и изучите постановку.
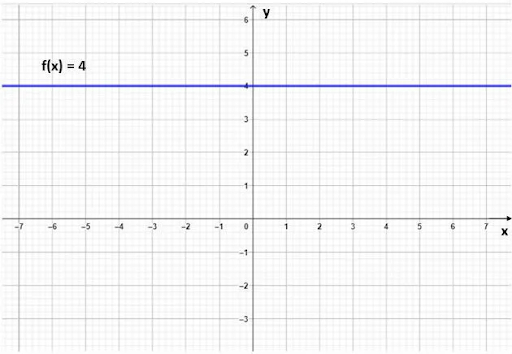
Константная функция
Но наше человеческое сознание устроено так - не знаешь деталей (это ж надо напрягаться, разбираться) - не лезь!
Всегда проще сказать - сложно, трудно, магия ... и не делать. Особенно это ярко проявляется, когда замудрёное слово или термин, сокращение - вводят в состояние неопределенности слушателя или читателя.
Открываешь книгу по квантовой механике: "Ууу, нифига себе формулы, текст с непонятными словами, ну нафиг, это не для меня, пусть ботаны учат".
Особенно пользуются популярностью у людей "НА ОКОЛО" - журналистов, блогеров, популяризаторов науки, болтунов.
Умеющие красиво говорить и преподносить информацию о той или иной сложности "Алгоритмов", преуспели здесь в разы.

Модный программист
Пример
Простые фразы в описаниях работы с синглами и альбомами у дистрибьютера в FAQ: время публикации релиза "зависит" от количества ваших загруженных треков и треков других пользователей платформы.
А что имеем: кривой алгоритм валидации данных.
Например, неудачно проверяются:
Ошибки заполнения полей (текстовые опечатки, неочевидные даты)
Формат изображения обложки в пикселях неочевиден, либо расшифровка содержит неточности
Отсутствие лишнего рекламного текста в картинке
Пост-фактум: на последнем этапе, юзер ждет, нервничает, пишет в поддержку, а простого логирующего сообщения в кабинете нет месяцами.
Но зато "алгоритмы" проверяют содержимое треков, текст, картинку и прочее.
Вернемся к основной теме поста
Алгоритмы - это вещь сугубо прикладная к структурам данных, которые возникают при сборе требований и при постановке задачи.
Мы неоднократно наблюдали, что тот или иной подход надо применять с умом, зная особенности ситуации, внешних и внутренних обстоятельств, нефункциональных требований.
Бывают случаи, когда казалось бы крутой алгоритм просто нифига не работает. А бывает, что идеально подходит к структуре.
Простой жизненный пример, показывающий, как нужно применять тот или иной сценарий в быту. Потом это поможет нам при программировании.
Семечки. Я люблю «точить» семки за компом, смотря видосики с ютуба.
Позитивный сценарий таков - насыпать себе горсть семечек в емкость, взять дополнительную тару для мусора и грызть по одной.
Полезный для понимания, но хреновый в реализации алгоритм - оставить пачку семечек на кухне.
После "слузгивания" одной семечки вставать из-за компа, идти на кухню, брать одну семку из пачки, нести её в комнату за комп, грызть. Потом снова вставать, относить мусор на кухню и брать новую семечку. Далее работа в таком цикле.
Ни видос нормально не получится посмотреть, ни погрызть нормально.
Здесь суть в структуре данных - "близкая тарелка с горстью семок", против "пакет на кухне". Вроде бы почти одно и тоже, да и в деталях похоже, сам алгоритм одинаковый, взять семку, положить в рот, сгрызть и выкинуть мусор.
А какая разница в "производительности"!
Что толку, что я знаю второй маргинальный алгоритм "с кухней", он же тупой, тяжелый, бесит. А вот и нет.
Второй алгоритм тоже полезен, просто для другой "структуры данных".
Однажды много лет меня пригласили на дачу на шашлыки. Всё как обычно.
В воскресенье к вечеру начали собираться уезжать. Хозяин дачи, мой друг попросил меня помочь помыть посуду за 3 дня веселья.
Входные данные:
- Гора тарелок в раковине на даче возле крана со шлангом
- Ледяная вода
- Помытую посуду надо относить в дом и ставить в шкаф
- Похолодало, погода не очень, дождь, ветер.
Когда я начал мыть посуду, я понял, что у меня мерзнут руки. Алгоритм помыть всё, вытереть всё и отнести всё порциями по N тарелок не работал.
Чтобы не замерзнуть в край и не заболеть я стал мыть тарелки по одной, по одной же относить в дом и ставить на полку, за это время у меня согревались руки и я их мог вытереть.
Неоптимальный алгоритм здесь прекрасно сработал - посуда вымыта, не заболел.
Мораль сей басни такова - просто вызубрить алгоритмы, и, уж тем более, бравировать их наличием, но без понимания задачи - та еще ерунда.
Возвращаясь к реалиям. Рекомендательные алгоритмы.
У начинающих с нуля блогеров всегда есть соблазн узнать, почему их посты/видео/reels"не заходят".
Да все просто - нейро-сетевые алгоритмы рекомендаций вообще ни при чем, важна структура данных и сами данные, которые им копятся.
Конкретный программист типа "солдат" чаще всего работает по принципу "мне сказали, я сделал". И хардкодно делает, например, выборку из условной базы данных постов к рекомендациям.
Если там стоит жесткое условие - крутить посты только "из этого списка авторов", или "от 1000 лайков", или "нужное подставить", то ваш нулевой канал/аккаунт не попадает в структуру данных (список идентификаторов например) для рекомендаций.
Характерный пример - на YouTube при загрузке своих видео на канал нужно заполнять форму с самим файлом, заголовком, описанием и другими полями.
Присмотримся к двум важнейшим для публикации и ротации input'ам:
Да это видео для детей
Нет это видео не для детей
Связанный со вторым:
Это видео подходит для пользователей менее 18 лет
Нет, это видео не подходит для пользователей менее 18 лет
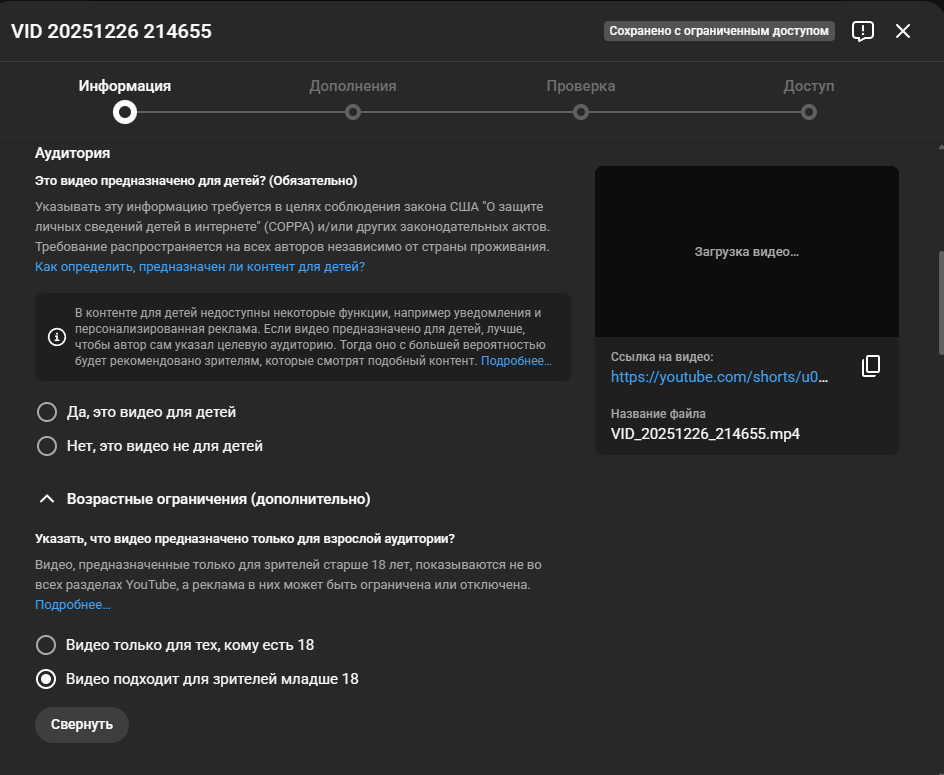
Popup загрузки нового видео на YouTube
Изначально, противоречивые radio button's, да еще и связанные между собой, да еще и захардкоженные if-else логикой на "гипотетический" возраст гугловой учетки, подаются в форме так, что единого понимания ожидаемого результата просто нет.
И всё, неверная комбинация параметров (а такое регулярно бывает) - и видео не показывается.
Алгоритмы рекомендаций тут ни причем, алгоритм ВАЛИДАЦИИ с абсолютно неверно собранными требованиями реализован как г@вно.
Как это исправить - элементарно:
- Устранить противоречивость требований
- Перекодить, починить валидацию
- Протестировать детальнее
- Дофиксить, выкатить.
А что в сухом остатке?
Расхожая фраза в постах и в комментах - "Ротация ваших <нужное подставить> зависит от рекомендательных алгоритмов".
И так везде: в социальных сетях, у контентных платформ, на видеохостингах и так далее, а также у музыкальных дистрибьютеров.
Ну не зависит результат от алгоритмов. В первую очередь он зависит от "недофикшеных" багов, которые возникают при неправильном выборе структур данных, недобору требований, недостаточному тестированию.
А алгоритмы учить именно в смысле зубрежки не надо. Надо учиться применять обычный здравый смысл и в жизни и в IT.
Изучайте структуры данных, требования. Обдумайте как они вам помогают в быту, а только потом алгоритмы.
Знания рано или поздно придут, если не лениться!
_____
Николай Широков, вокалист и гитарист Please Wait..., а также программист со стажем.
Спасибо за прочтение!
Подписывайтесь на наш телеграм: t.me/please_wait_band