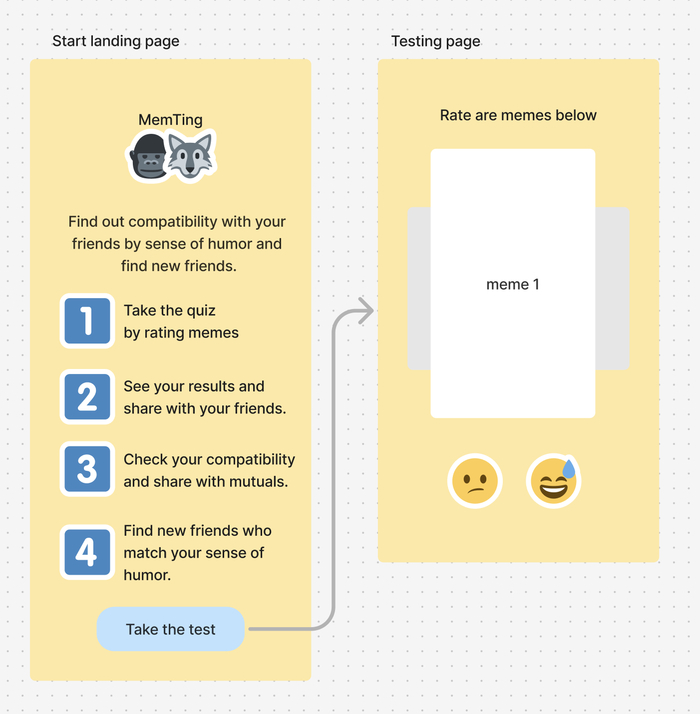
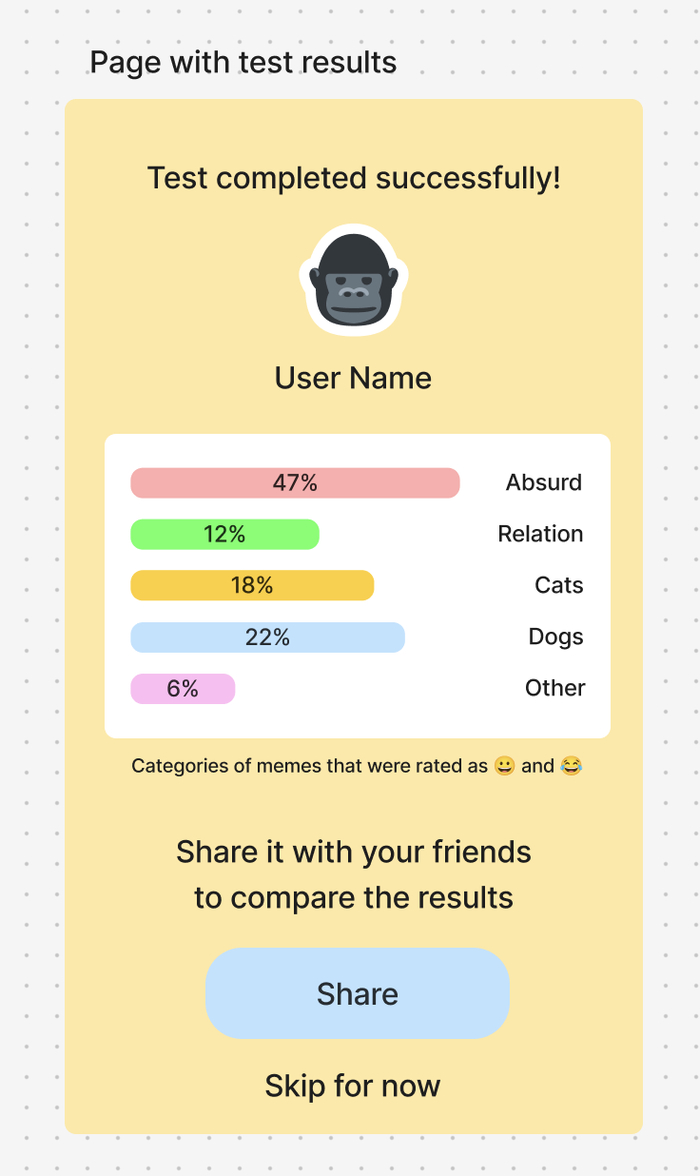
Часть 2: почему эмбеддинги мемов не дают совместимости по юмору, и что мы с этим сделали
В прошлой части я остановился на том, что мы попробовали мерить совместимость по реакциям на мемы тремя ручными способами и каждый раз упирались в одно: юмор это не про категорию мема, а про то, как именно в нём смешно.
В академической психологии есть тесты на юмор - тот же Humor Styles Questionnaire Мартина, и ещё штук пять-семь подобных. Все они меряют само-описание (отвечаешь, какие виды юмора тебе ближе). Это нормально работает в исследовании, но не работает в продукте: если ты на дейтинг-сайте спросишь "какой у тебя юмор", человек выберет вариант, который звучит выгоднее. Поэтому нам нужно было мерить реакцию, а не самоописание.
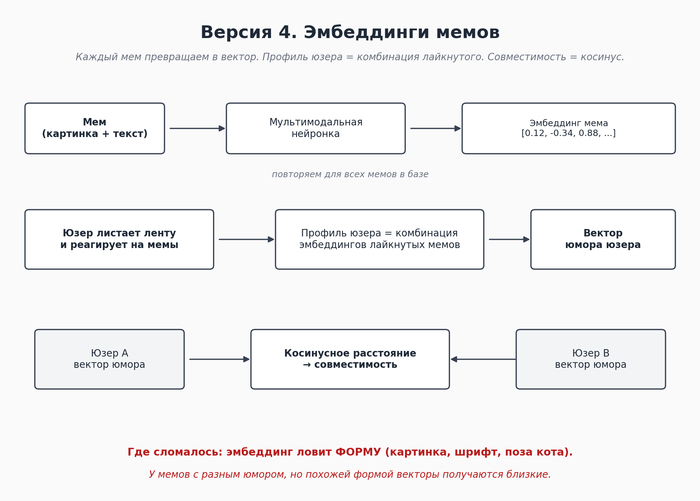
Версия 4. Эмбеддинги.
Эмбеддинги это когда нейронка превращает любой объект (картинку, текст, мем целиком) в набор чисел. Вектор. У схожих объектов вектора близкие. Сравниваем два вектора через косинусное расстояние, получаем число от -1 до 1.
Логика была такая. Каждому мему - свой вектор. Юзер лайкает мемы - собираем для него профиль из векторов лайкнутого. Два юзера сравниваем по их профилям. Чем ближе - тем выше совместимость по юмору. Бонусом выкидываем ручную разметку категорий, нейронка сама разделяет мемы по сути.
Заодно мы поменяли формат продукта. Статичный тест из 50 мемов это слабая механика - человек устаёт и быстро уходит. С эмбеддингами можно собрать адаптивную ленту: показывать мемы, близкие к тому, что юзеру нравится, профиль уточняется на ходу. Стало гораздо приятнее в использовании.
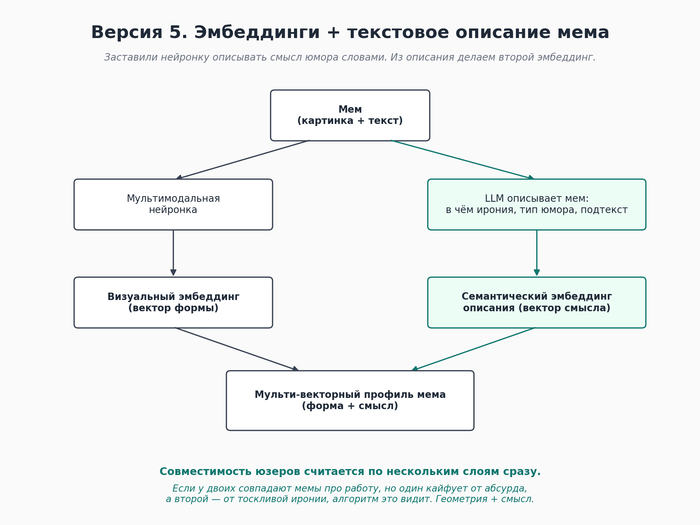
Версия 5. Эмбеддинги + текстовое описание сути мема.
В какой-то момент пришла странная на вид идея. Нейронка не "понимает" смысл юмора напрямую через картинку. Но если попросить её этот смысл проговаривать словами, она это делает довольно прилично.
Для каждого мема в базе мы стали генерировать описание. Не "кот в офисе". А несколько строк примерно такого вида:
Мем построен на контрасте между серьёзным офисным антуражем и нелепым выражением морды кота. Считывается как сатира на корпоративную депрессию миллениалов. Юмор работает через узнавание собственного состояния. Подтекст - усталость от рутины и невозможность изменить ситуацию. Тип юмора - самоироничный с лёгкой меланхолией.
И так по каждому мему. Сначала это звучало странно (заставлять модель писать литературный анализ мемов про котов), но именно это и сработало.
После этого у каждого мема в базе появилось два слоя:
Визуальный эмбеддинг (как в версии 4) - для базовой геометрии
Текстовое описание - его мы тоже превращаем в эмбеддинг, но это уже не вектор картинки, а вектор сути юмора
Совместимость двух юзеров теперь считается не по одному измерению, а по нескольким сразу. И вот тут наконец стало похоже на правду.
Конкретный пример. Допустим, у двух человек в лайках одинаковая доля мемов "про работу". В версии 4 они были бы засчитаны как близкие по этому слою. В версии 5 алгоритм видит, что у одного "мемы про работу" - это весёлый абсурд про неадекватного босса, а у другого - тоскливая ирония про burnout. Это разный тип юмора, и совместимость по нему уже не 95%, а гораздо аккуратнее.
Из этой архитектуры выросло то, что в приложении сейчас:
Адаптивная лента мемов
В профиле юзера хранится его вектор юмора (грубо говоря, юморный отпечаток)
Совместимость считается через близость и сонаправленность векторов
Чем дольше человек скроллит, тем точнее профиль
Тут начинается третья часть - про то, как из этого алгоритма выросло дейтинг-приложение и где продукт сейчас.
Чистые эмбеддинги мультимодальных моделей плохо работают на задачах, где важна семантика поверх формы. LLM-сгенерированное описание объекта поверх эмбеддинга часто даёт ощутимый прирост качества при минимальных затратах на инфраструктуру. У нас прирост по нашей внутренней метрике совместимости был заметный, но цифрами поделюсь, когда у меня самого до них дойдут руки и я буду уверен, что они стабильные, а не на маленькой выборке.