

Memeting
2 поста
2 поста
В прошлой части я остановился на том, что мы попробовали мерить совместимость по реакциям на мемы тремя ручными способами и каждый раз упирались в одно: юмор это не про категорию мема, а про то, как именно в нём смешно.
В академической психологии есть тесты на юмор - тот же Humor Styles Questionnaire Мартина, и ещё штук пять-семь подобных. Все они меряют само-описание (отвечаешь, какие виды юмора тебе ближе). Это нормально работает в исследовании, но не работает в продукте: если ты на дейтинг-сайте спросишь "какой у тебя юмор", человек выберет вариант, который звучит выгоднее. Поэтому нам нужно было мерить реакцию, а не самоописание.
Версия 4. Эмбеддинги.
Эмбеддинги это когда нейронка превращает любой объект (картинку, текст, мем целиком) в набор чисел. Вектор. У схожих объектов вектора близкие. Сравниваем два вектора через косинусное расстояние, получаем число от -1 до 1.
Логика была такая. Каждому мему - свой вектор. Юзер лайкает мемы - собираем для него профиль из векторов лайкнутого. Два юзера сравниваем по их профилям. Чем ближе - тем выше совместимость по юмору. Бонусом выкидываем ручную разметку категорий, нейронка сама разделяет мемы по сути.
Заодно мы поменяли формат продукта. Статичный тест из 50 мемов это слабая механика - человек устаёт и быстро уходит. С эмбеддингами можно собрать адаптивную ленту: показывать мемы, близкие к тому, что юзеру нравится, профиль уточняется на ходу. Стало гораздо приятнее в использовании.
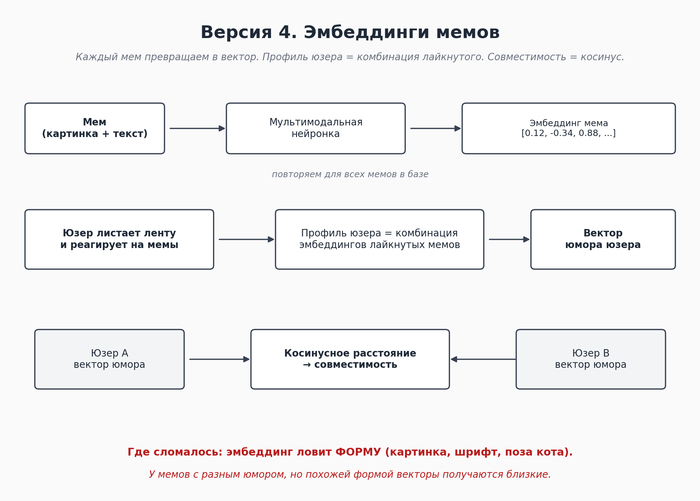
Версия 5. Эмбеддинги + текстовое описание сути мема.
В какой-то момент пришла странная на вид идея. Нейронка не "понимает" смысл юмора напрямую через картинку. Но если попросить её этот смысл проговаривать словами, она это делает довольно прилично.
Для каждого мема в базе мы стали генерировать описание. Не "кот в офисе". А несколько строк примерно такого вида:
Мем построен на контрасте между серьёзным офисным антуражем и нелепым выражением морды кота. Считывается как сатира на корпоративную депрессию миллениалов. Юмор работает через узнавание собственного состояния. Подтекст - усталость от рутины и невозможность изменить ситуацию. Тип юмора - самоироничный с лёгкой меланхолией.
И так по каждому мему. Сначала это звучало странно (заставлять модель писать литературный анализ мемов про котов), но именно это и сработало.
После этого у каждого мема в базе появилось два слоя:
Визуальный эмбеддинг (как в версии 4) - для базовой геометрии
Текстовое описание - его мы тоже превращаем в эмбеддинг, но это уже не вектор картинки, а вектор сути юмора
Совместимость двух юзеров теперь считается не по одному измерению, а по нескольким сразу. И вот тут наконец стало похоже на правду.
Конкретный пример. Допустим, у двух человек в лайках одинаковая доля мемов "про работу". В версии 4 они были бы засчитаны как близкие по этому слою. В версии 5 алгоритм видит, что у одного "мемы про работу" - это весёлый абсурд про неадекватного босса, а у другого - тоскливая ирония про burnout. Это разный тип юмора, и совместимость по нему уже не 95%, а гораздо аккуратнее.
Из этой архитектуры выросло то, что в приложении сейчас:
Адаптивная лента мемов
В профиле юзера хранится его вектор юмора (грубо говоря, юморный отпечаток)
Совместимость считается через близость и сонаправленность векторов
Чем дольше человек скроллит, тем точнее профиль
Тут начинается третья часть - про то, как из этого алгоритма выросло дейтинг-приложение и где продукт сейчас.
Чистые эмбеддинги мультимодальных моделей плохо работают на задачах, где важна семантика поверх формы. LLM-сгенерированное описание объекта поверх эмбеддинга часто даёт ощутимый прирост качества при минимальных затратах на инфраструктуру. У нас прирост по нашей внутренней метрике совместимости был заметный, но цифрами поделюсь, когда у меня самого до них дойдут руки и я буду уверен, что они стабильные, а не на маленькой выборке.
Сидим с другом в кафе, болтаем за всякое. У нас такой спорт - идеи, проекты, философия, чай стынет, мир сложный, мы умные. И в какой-то момент разговор сворачивает на людей, взаимоотношения. Я говорю: слушай, для меня в человеке важно чувство юмора. Не "адекватность", не общие интересы, не бэкграунд - именно юмор. И вот почему.
Человек, у которого с юмором ок, обычно умеет найти язык с кем угодно. Юмор это переходник, реально универсальная розетка. С шуткой любая жизненная ситуация, по моему мнению, переживается легче. Это даже физиология, не литература. Любая нормальная шутка работает минимум на двух уровнях. Кто видит второй слой, тот в среднем умнее тех, кто не видит. Не панацея, конечно, но корреляция есть.
А самое крутое - самоирония. Если человек умеет посмеяться над собой, у него в порядке голова. Эго не разваливается от подкола. Мозгов хватает увидеть себя со стороны. Опыта хватает признать, что он сам по себе бывает смешон. Это всё вообще-то про мозги, не про юмор. По-человечески, если перевести: значит с таким человеком можно найти общий яык.
Друг слушает, кивает. Потом говорит: "Ну ок, юмор важен, никто не спорит. А ты можешь его измерить?" И мы оба молча так зависли, если честно. Потому что психологические тесты на совместимость есть. На IQ есть. На любовь, на привычки бытовые, на привязанность - тонна. А на юмор? Вариант "спроси, что тебя смешит" отметается сразу - на свиданиях все врут, в анкетах тем более. Сравнить любимых комиков? У людей с разным юмором часто одни и те же любимые комики, просто потому что они популярные. Нужно что-то, что меряет реакцию. Не то, что человек о себе говорит.
А мы - программисты. Значит, будем пилить) Дальше у нас было пять версий теста. Расскажу по порядку.
Версия 1. Лайк-дизлайк.
Логика тупая: психологический тест работает по принципу "совпали ответы - совместимы". Значит, даём двум людям одну пачку мемов, сравниваем реакции, готово. А что такое концентрированный юмор сегодня? Конечно, мемы. Не анекдоты же из календарика.
Берём пачку картинок, юзер пробегает, тыкает 👍 или 👎. Совпало - совместимы. Казалось гениальным первые часов двенадцать.
Сломалось на первом же прогоне на себе. Открываю мем - он мне актуальный, но я над ним не ржу. Просто понимаю шутку. Что тыкать? Лайк? Я не смеюсь. Дизлайк? Мем нормальный. И таких мемов в любой ленте половина. Двоичная шкала просто не тянет. Закопали.
Версия 2. Пятибалльная.
Окей, не хватает градаций. Делаем нормальную шкалу: совсем не нравится / не нравится / нейтрально / нравится / супер нравится. Думали, поймаем нюансы. И вроде поймали - совместимость стала аккуратнее.
И всё равно как-то мутно. Потому что у одного "нейтрально" это "ну прикольно, не моё". А у другого "нейтрально" это "бесит, нажму середину чтоб быстрее пройти". Шкалы у людей внутри головы разные. Это как с ценой: для одного "дорого" - пять штук, для другого - пять лямов. Усреднять бесполезно.
Стало чуть лучше. Но до "работает" не дотянуло.
Версия 3. Категории, теги, ручная разметка.
Заходим с другой стороны. Каждому мему присваиваем категории вручную: коты, офис, работа, отношения, политика, абсурд, чёрный юмор, и так далее. Дальше смотрим, в каких категориях у двух людей реакции пересекаются.
На простых мемах работает. Котятники сходятся на котятах, офисные сходится на офисе.
А потом приходит мем: кот сидит в офисе с табличкой про дедлайн. Это что? "Кот"? "Офис"? "Работа"? "Абсурд"? Всё четыре? Что главнее? Я не шучу - я реально сидел над одной картинкой минут двадцать и не мог решить. И таких пограничных мемов - больше, чем простых.
Тегать руками первые полчаса прикольно. К сотому мему ты хочешь умереть. К двухсотому начинаешь сомневаться, что вообще понимаешь, что такое юмор, и не пора ли тебе уволиться из жизни.
И вот тут до нас допёрло. Юмор это не про тему. Юмор это про то, как именно оно смешно. Один "кот в офисе" - про абсурд бытия. Другой - про то, что миллениал не вывозит корпорацию. Третий - про эту вот тиктоковскую усталую иронию. Тема одна, по сути - три разных мема.
Категориями такое не возьмёшь в принципе. Мы упёрлись.
Сидим, тупим, чай уже даже не стынет, его налили заново и он снова стынет. И вылезает вообще-то очевидная вещь: нам нужно что-то, что само понимает, чем один мем отличается от другого. Не по тэгу. По вайбу. По смыслу шутки, которая внутри.
И тут мы такие - стоп. У нас же 2025 во дворе. Нейронки же есть. Чё мы как два мужика из 2014 года руками теги ставим.
С этого момента началась версия 4. И версия 5. Они уже более-менее заработали. Расскажу в следующем посте, иначе тут уже и так лонгрид на двух экранах.
Если совсем спойлерить - мы заставили нейронку не просто смотреть на мем, а писать про него развёрнутое сочинение: в чём ирония, на чём построен юмор, что считывается, какой подтекст. Звучит как бред, выглядело тоже как бред, но именно это всё перевернуло. То, что сейчас в приложении - выросло из этого момента. Но это уже следующая серия.
