

Как делают дипфейки
Вы не могли не видеть роликов, где известным киноперсонажам подставляют лица других актеров. Иногда подобные замены выглядят удивительно достоверно. Сегодня рассказываю про дипфейки.
ИСТОРИЯ
Термин дипфейк происходит от слов «deep learning», то есть «глубокое изучение» и «fake» - «подделка». Технология появилась в 2014-м. Алгоритм создал студент Стэнфордского университета Ян Гудфеллоу, взяв за основу нейросеть, которая детально изучает лицо человека, а затем подставляет к исходному файлу лицо «реципиента».
Таким образом дипфейки используют технологии искусственного интеллекта для синтеза изображений. На сегодняшний день существуют разные архитектуры алгоритмов, которые переносят лица с видео на видео.
видеоверсия статьи
GAN
Чаще всего дипфейки или face swap создаются с помощью генеративно-состязательной сети (GAN), в которой функционируют две системы - генератор и дискриминатор. Они работают в паре как кандидат и оппонент во время защиты: один озвучивает идеи и аргументы, а второй их критикует. Таким образом генератор создаёт изображения, а обученный на реальных фотографиях дискриминатор подсказывает, что нужно исправить. По мере того как генераторы обучаются обманывать дискриминатор, изображение получается всё более реалистичным. Таким образом, кодировщик и декодировщик отвечают за перенос изображения, а дискриминатор от генеративных сетей — за улучшение результата. Нейросеть работает лучше всего, если дать ей много изображений человека, снятых под разными углами и с разными условиями освещения. Этот принцип работает и в случае с методикой Autoencoder и decoder. Из названия понятно, что в основе технологии находится кодировщик и декодировщик. Процесс кодирования и декодирования отображен на схемах.
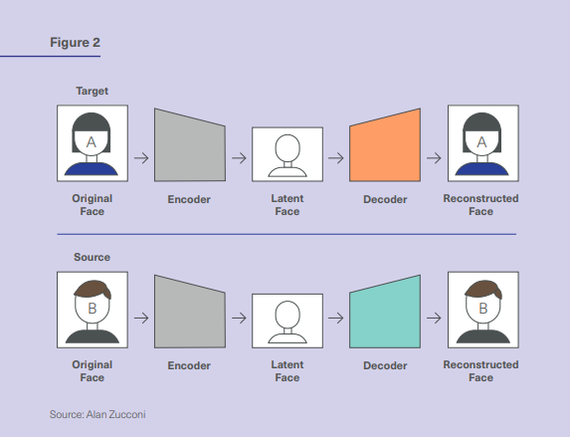

ОГРАНИЧЕНИЯ
Уши, лоб и волосы остаются в целевом видео родными, поскольку алгоритмы пересаживают исключительно область от бровей до подбородка и от уха до уха. В связи с этим нужно находить похожих друг на друга людей или использовать грим, как в случае с коммерческими проектами. На конечный результат цвет кожи и волос, а также комплекция и форма лица. Тот же Хавьер Бардем качественнее поженился со Шваренеггером чем с Ди Каприо или Уиллемом Дэфо, поскольку у них в жизни формы черепа похожи. Также нужно учитывать положение головы и крупность в донорском и целевом видео. Несовпадения принесут плачевные результаты. Оба человека должны побывать в максимально совпадающих условиях и ситуациях. На постпродакшен этапе при помощи композа и масок, конечно, можно докрутить и отшлифовать, но сама по себе технология еще требует серьезной доработки, чтобы выдерживать кинематографическое качество и впоследствии стать мощным инструментом, который бы не накладывал столько ограничений, а наоборот давал гибкость. В менее требовательном, но на более оборотистом рынке рекламы нейросети уже востребованы. А уж сколько однокнопочных сервисов для мобилок появилось. Но важно помнить, что качественный результат всегда требует времени. Тот же проект с Сальвадором Дали потребовал 1000 часов машинного обучения, 6000 фотографий и 146 видео с похожим внешне актером.
Рекламу для Сбера тоже делали ни один месяц. Наконец, для документального фильма "Добро пожаловать в Чечню" также использовали замену лиц, чтобы скрыть личности респондентов. Но там это и не скрывается. Фейк виден невооруженным глазом. Тем не менее это большой и серьезный труд по работе с дублерами и нейросетями, чтобы передать эмоции пострадавших представителей меньшинств.
Можете самостоятельно натренировать нейросеть. Ниже ссылки:
БИБЛИОТЕКА DeepFaceLab
https://github.com/iperov/DeepFaceLab
ИНСТРУКЦИЯ:
https://proglib.io/p/deepfake-tutorial-sozdaem-sobstvennyy-d...



Искусственный интеллект
5.2K постов11.5K подписчиков
Правила сообщества
ВНИМАНИЕ! В сообществе запрещена публикация генеративного контента без детального описания промтов и процесса получения публикуемого результата.
Разрешено:
- Делиться вопросами, мыслями, гипотезами, юмором на эту тему.
- Делиться статьями, понятными большинству аудитории Пикабу.
- Делиться опытом создания моделей машинного обучения.
- Рассказывать, как работает та или иная фиговина в анализе данных.
- Век жить, век учиться.
Запрещено:
I) Невостребованный контент
I.1) Создавать контент, сложный для понимания. Такие посты уйдут в минуса лишь потому, что большинству неинтересно пробрасывать градиенты в каждом тензоре реккурентной сетки с AdaGrad оптимизатором.
I.2) Создавать контент на "олбанском языке" / нарочно игнорируя правила РЯ даже в шутку. Это ведет к нечитаемости контента.
I.3) Добавлять посты, которые содержат лишь генеративный контент или нейросетевой Арт без какой-то дополнительной полезной или интересной информации по теме, без промтов или описания методик создания и т.д.
II) Нетематический контент
II.1) Создавать контент, несвязанный с Data Science, математикой, программированием.
II.2) Создавать контент, входящий в противоречие существующей базе теорем математики. Например, "Земля плоская" или "Любое действительное число представимо в виде дроби двух целых".
II.3) Создавать контент, входящий в противоречие с правилами Пикабу.
III) Непотребный контент
III.1) Эротика, порнография (даже с NSFW).
III.2) Жесть.
За нарушение I - предупреждение
За нарушение II - предупреждение и перемещение поста в общую ленту
За нарушение III - бан