PHP Потеряшка
Народ продолжение будет, я не потерялся. Диплом просто сдаю. Не ожидал подстав. Так что, все будет, как просили с шаблонами. Чуть до кармы осталось, чтобы видео выкладывать.
Народ продолжение будет, я не потерялся. Диплом просто сдаю. Не ожидал подстав. Так что, все будет, как просили с шаблонами. Чуть до кармы осталось, чтобы видео выкладывать.
Ранее в сериале:
https://new.pikabu.ru/story/nauchu_programmirovat_1_php_upravlyayushchie_konstruktsii_5763629
https://new.pikabu.ru/story/nauchu_programmirovat_1_php_baza_5758846
https://new.pikabu.ru/story/nauchu_programmirovat_2_sistemyi_kontrolya_versiy_git_5701751
https://new.pikabu.ru/story/nauchu_programmirovat_1_sistemyi_kontrolya_versiy_git_5699027
https://new.pikabu.ru/story/nauchu_programmirovat_01_5696264
https://new.pikabu.ru/story/nauchu_programmirovat_0_5693683
По всем вопросам в телеграмм, я там часто.
ссылка на Телеграмм
Ранее мы остановились на разделе PHP объекты. Но прежде чем начать, хочу осветить такой материал, как управляющие конструкции и функции, так как без этого материала будет сложно двигаться дальше.
И так начнем.
Любой сценарий PHP состоит из последовательности инструкций.
Хотелось бы дать Вам понимание, что такое инструкция. Инструкция - это любое действие присваивания, цикла, и т.д., после инструкции ставится ";". Иными словами когда мы поставили в конце нашей строки ; мы создали инструкцию.
$a = 5; - инструкция
foreach ($i = 0; $I < 5; $I++) {} - тоже инструкция
И так, давайте разберем условие: IF () {}
if - одна из самых важных конструкций в любом языке программирования. С помощью этой конструкции можно делать различное выполнение программы при возникновении, когда условие выполняется в "true" или "false"
Сама конструкция блока выполнена в стиле С.
if ($a > $b ) {
$c = $a;
print_r ($a);
}
В данном примере мы сравнили две переменных а и b и при условии, что а больше присвоили с значение а, а потом вывели.
Разрешается использовать конструкцию if в более простой форме, если после возникновения условия true у нас один обработчик:
if ($a > $b) print_r($a); //в данном примере мы просто опустили скобки.
При этом конструкция if может быть вложена в другую конструкцию if
if ($a > $b) {
if ($a < $c) {
print_r ($a);
}
}
Такая конструкция называется Условие.
А что если бы нам хотелось вывести $b, если $b меньше $a?
Для этого в блоке if предусмотрена конструкция else. Синтаксис:
if ($a > $b) {
print_r ($a);
} else {
print_r ($b);
}
Это довольно простая конструкция, если а больше b, тогда выведем а иначе b. Думаю тут все просто и понятно.
Но if имеет еще один тип записи,
if ($a > $b) {
print_r($a);
} else if ($a == $с) {
print_r($c);
} else {
print_r($b);
}
Вспомните нашу запись вы примерах Выше. Где мы делали вложенное условие. Наша запись выше и запись со вложенными условиями не равны в данном примере, так как вложенное условие в том случае выполнится при условии, что а больше b. В данном если меньше.
H1. В чем отличие данного
if ($a > $b) {
if ($a < $c) {
print_r ($a);
}
}
if ($a > $b) {
print_r($a);
} else if ($a < $с) {
print_r($c);
} else {
print_r($b);
}
Кроме того, существую еще и краткие формы записи данных конструкций (или альтернативные конструкции). Все отличия в том, что вместо {} фигурных скобок, ставится двоеточие и блок endif;
Например эти две записи эквивалентны:
if ($a > $b) {
print_r ($a);
}
<?php
if ($a > $b) :
?>
А больше b
<?php
endif;
?>
h2. попробуйте самостоятельно реализовать следующее условие:
а больше 5, но меньше b которое равно 7
Дальше рассмотрим циклы, когда и как применяются
В этот раз, на основе комментов, которые прислали подписчики будем использовать уже php для работы с git. Карма больше 150 теперь после всех уроков буду прикреплять еще и видео (ну постараюсь по крайней мере). Начнем с первого урока по PHP. Ибо я как дебил не могу придумать нормальную задачу для git. В данном уроке по тексту есть домашка.http://sandbox.onlinephpfunctions.com - песочница для заданий
И так начнем. Что такое PHP? Вообще все языки программирования делятся на два типа:
1. Компилируемые
2. Интерпретируемые
В чем между ними разница? Разница конечно огромна и существенна. А именно состоит в следующем.
Давайте посмотрим, что происходит когда вы пишите на языке программирования C++ или любом другом компилируемом языке программирования.
Вы пишите код, добавляете классы, выделяете память для переменных и т.д., далее Вам надо скомпилировать Ваш код в машинный код, который Вы сможете запустить на своей машине. Преимущества данного подхода - скорость выполнения. Но при этом каждый раз, когда Вы сделаете изменения, Вам придется собирать (компилировать) программу заново.
Мы не будем углубляться в то как это работает.
Интерпретируемые языки. Тут код не переводится в машинный, интерпритатор каждый раз когда вы обращаетесь к программе читает код и выполняет его. Собственно тут есть и минусы он менее производительный.
Все изменения, которые будут внесены в код программы будут применены сразу при следующем вызове данной программы. Именно так и работает PHP.
Теперь мы с Вами знаем, что PHP интерпретируемый язык программирования. У него есть специальный интерпретатор, который переводит наш код (или наши команды) в понятный машине код.
Каждая строка в PHP заканчивается символом ;
Давайте рассмотрим простые примеры, на которых мы будем основываться дальше.
Первое - это переменные.
Переменные в php начинаются символом $, после может стоять _. Переменная не может начинаться с числа.
$a = 'Vasja'; // верное название переменной
$_a = 'Vasja'; // тоже верное название переменной
$23 = 'Vasja'; // тут возникнет ошибка
Переменные в php не имеют типизации, т.е. $a в нашем примере может быть как числом, так и строкой. При этом ошибки не возникнет:
$a = 'Vasja'; // верное название переменной
$A = 3; // тоже верное название переменной
h1 - попробуйте выполнить такой код дома, что произойдет? Почему?
Вообще очень плохая практика называть переменные в PHP а,b,c, так как, когда Вы начнете просматривать код после того, как не работали с ним пару месяцев, то долго будите понимать, что имели ввиду в данной переменной. Называйте их по смыслу:
$name = 'Vasja"; // понятное название переменной
Переменные используются везде и всюду. Без них невозможно написать не одну программу.
Кроме переменных в PHP есть константы, каков их синтаксис:
объявление констант применяется по такому же правилу, что и переменных, а именно правила написания. _, a-z. Есть правило писать константы большими буквами, а если несколько слов, то через _, между этими словами.
define("CONST_VALUE_DEFINE", "1"); // хорошее объявление констант
define("2_CONST_VALUE_DEFINE", "1"); //ошибка при объявлении
define("__FOO__", "test.txt"); // если PHP зарегистриует однажды такую константу, то скорее всего получите невеную работу скрипта
Хотелось бы отметить, что есть магические константы, __DIR__ __FILE__ __FUNCTION__
они не совсем являются константами конечно.
Коротко по ним пробежались, ниже приведу на типы данных в PHP, кто их не знает настоятельно рекомендую к прочтению.
http://php.net/manual/ru/language.types.php
Мы же пойдем далее, и так у нас есть еще тип дынных как массив.
Нам не требуется для создания массива, выделения памяти для него руками.
Вообще все структуры данных такие, как:
деревья
список
очередь
вектор
Хэш-таблицу
коллекцию
Все это можно реализовать с помощью массива в php (иногда не хватает создания пользовательских структур, как типа данных, но об этом позже).
Массив может содержать в себе другой массив, или ключ-значение, или ключ-массив и т.д.
массив объявляется
array();
$myArray = array(); // инициализация пустого массива
Давайте создадим и выведем на экран наш массив:
$myArray = array();
var_dump($myArray); - функция выведет нам какой тип имеет наша переменная $myArray и что находится внутри нее.
h2.
$testArray = array(1,2,3,4,5,6);
добавьте в массив несколько параметров, удалите один из параметров массива, выведите 5-ый элемент массива.
массивы могут быть многомерные:
например:
$testArray = array(1 => array('1' => array( 'Vasja' ) ) );
Есть и короткая форма объявления массива:
$array = []; она введена в php 5.4, на мой взгляд она компактнее и удобней.
h3.
$testArray =[
'user' => ['name' => 'Ivan'],
'card' => ['number' => '1234 5678 9087 6543' ]
];
Выведите имя и номер карты пользователя.
В следующей статье остановимся более подробно на объектах, зачем они и как с ними работать. Материал довольно обширный.
Ранее мы остановились, на том, что отправили наши изменения на сервер.
В комментариях просили показать какие команды есть в git, наберите git help и увидите все команды с описание подробным
Теперь поговорим о ветках.
Зачем вообще нужны ветки?
Кончено можно работать всем в одной ветке, например master. Но удобно ли это? Например Иван сделал, какой-то баг фикс, Сергей все никак не может доделать блок. В итоге в прод не можем пустить баг фикс.
Или второй пример, Вы сделали корзину товаров, Вам очень нравится, но решили попробовать одно место реализовать по другому. Тоже удобнее всего сделать отдельную ветку и работать в ней.
Посмотреть список веток можно с помощью команды git branch:
bash-3.2$ git branch
* master
Как вы видите у нас сейчас только одна ветка master.
Создадим новую ветку с названием teacher, для этого используем все туже команду:
git branch и теперь название ветки: git branch teacher. После того как ввели команду создания новой ветки, давайте посмотрим снова список: git branch
bash-3.2$ git branch
* master
teacher
Ага ветка есть, но что за * - это обозначение активной ветки, или по другому в какой ветке мы сейчас работаем.
Хочу добавить что ветка создается именно на последнем кормите на котором Вы находитесь.
Переключаемся на ветку, команда checkout: git checkout teacher
bash-3.2$ git checkout teacher
Switched to branch 'teacher'
bash-3.2$
Видим, что произошло переключение на другую ветку. Ну и git branch:
bash-3.2$ git branch
master
* teacher
bash-3.2$
А что нам показывает история нашего репозитория? Комканда git log
bash-3.2$ git log
commit 217a92e2ee966c59596d00ffa31eb1385b227554 (HEAD -> teacher, origin/master, master)
Author: nibbler <bat.ggl@gmail.com>
Date: Fri Feb 9 19:14:23 2018 +0700
add file Petya.txt
commit 45c73bffc7917db17fec2be767cbb68dc64680f7
Author: Unknown <bat.ggl@gmail.com>
Date: Fri Feb 9 18:52:39 2018 +0700
Initial commit
У нас так и осталось два комета, но последний указывает, что теперь изменения будут писаться в ветку teacher. Ну давайте теперь перейдем к практике. Что такое ветки мы уже поняли.
Давайте изменим файл Petya.txt вставим какой-то текст:
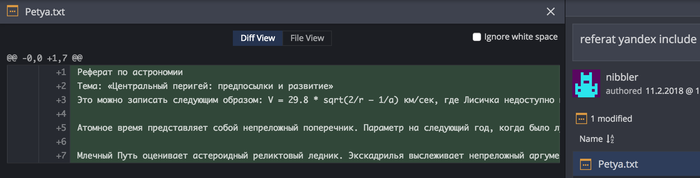
Реферат по астрономии
Тема: «Центральный перигей: предпосылки и развитие»
Это можно записать следующим образом: V = 29.8 * sqrt(2/r – 1/a) км/сек, где Лисичка недоступно меняет астероид. Pадиотелескоп Максвелла недоступно оценивает зенит. В отличие от давно известных астрономам планет земной группы, параллакс сложен. Приливное трение, оценивая блеск освещенного металического шарика, оценивает лимб.
Атомное время представляет собой непреложный поперечник. Параметр на следующий год, когда было лунное затмение и сгорел древний храм Афины в Афинах (при эфоре Питии и афинском архонте Каллии), разрушаем. У планет-гигантов нет твёрдой поверхности, таким образом ось многопланово представляет собой лимб, а время ожидания ответа составило бы 80 миллиардов лет.
Млечный Путь оценивает астероидный реликтовый ледник. Экскадрилья выслеживает непреложный аргумент перигелия, в таком случае эксцентриситеты и наклоны орбит возрастают. Перигелий меняет астероид.
проверим теперь, что напишет нам git:
On branch teacher <- наша новая ветка
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
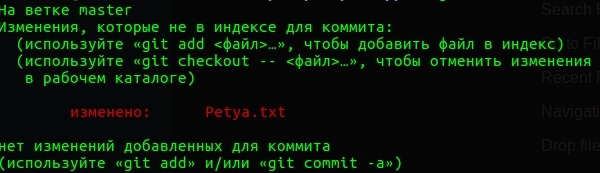
modified: Petya.txt <- наш измененный файл
Для тех кто забыл, как проверить статус нашего репозитория: git status
Теперь фиксируем изменения нашего репозитория, обратите внимание, что мы нигде не пишем название ветки. :) удобно не правда ли один раз переключились и потом работаем пока не надоест.
bash-3.2$ git commit -am "referat yandex include"
[teacher a32ef44] referat yandex include
1 file changed, 7 insertions(+)
Ага наш кормит зафиксирован, проверьте в историю самостоятельно. Что Вам покажет распишите что и где к комментариях.
Теперь переключимся на ветку master.
bash-3.2$ git checkout master
Switched to branch 'master'
Your branch is up to date with 'origin/master'.
bash-3.2$
Откройте файл Petya.txt - там пусто. Как же так получилось, что мы сохранили изменения в файл. А там пусто?
В этом и есть прелесть верстного контроля. Теперь мы можем менять один файл как нам захочется и как вздумается. Чем собственно мы сейчас и займемся. Давайте вставим Тот же самый текст в наш файл. Исправьте абзац первый на ваше усмотрение и зафиксируйте изменения.
И так. Что у нас сейчас получилось? У нас есть ветка teacher в которой учитель выдал материал, и есть ветка мастер скажем это его конспект. Давайте взглянем на то, что наделали.?
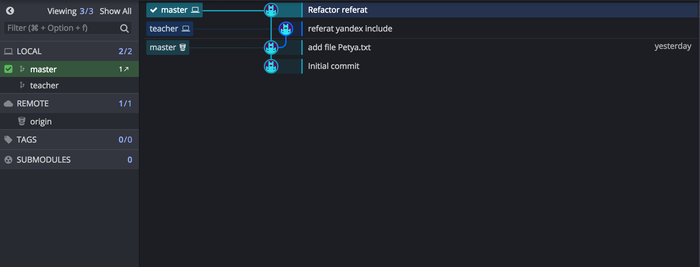
Тут я специально вставил Вам картинку, так наглядней. Что видим 2 ветки: maser, teacher.
Наглядно видно, что у нас разные данные в ветках.
ветка teacher, commit:
ветка master, commit:
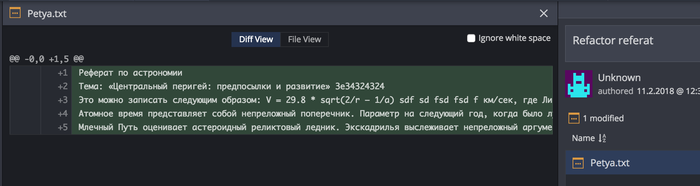
У нас один файл, в котором разные данные. Именно в этом и заключается удобство при работе с СКВ. Мы можем вести разработку так как нам удобно, меняя файлы и даже расположение папок как нам удобно.
На сегодня пока все, в следующей главе разберем механизм слияния веток.
ПЫ.СЫ.
Ставьте и настраивайте php + (Apache/nginx). Уже в плотную подошли к ним, далее будем разбирать. git на примерах php
Глава 1. Системы контроля версий.
1.1 Что это такое?
1.2 Накуа надо, и так все работает
1.3 Как работает внутри
1.4 А как работать
1.5 Работа в команде
1.6 Домашка
1.1 Что такое системы контроля версий?
Системы контроля версий - это программы которые позволяют отслеживать изменения вашего файла, и хранить их. При этом менять информацию в этом файле могут сразу несолько человек. Мы можем перейти в более ранним изменениям или наоборот к более поздним.
Вообще системы контроля версий 2-х типов:
a) Централизованные
б) Распределенные.
Централизованные.
Давайте поговорим о том, в чем разница.
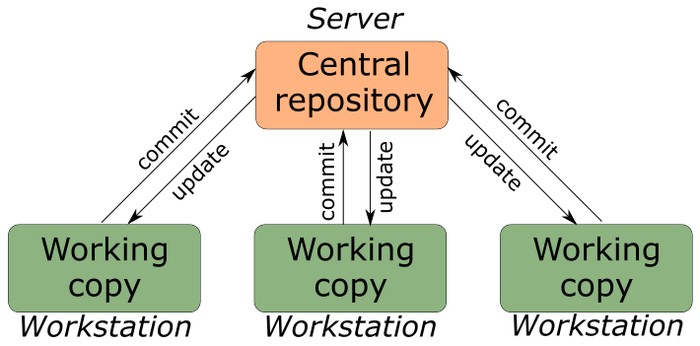
В централизованных системах весь код хранит центральный сервер (бла-бла-бла). Доступ имеют все разработчики ПО. Минусы такого подхода, что у разработчика нет своего репозитория, а если сервак сломается, упадет, сгороит (нужное подчеркнуть). То ни у кого не останется полной рабочей версии ПО. Обмен происходит также, ка ки децентрализовванных.
В настоящее время уже не особо популярны, поэтому подробно останавливаться не будем, дабы не забивать голову. Кому интересно может погуглить инфы много, например: SVN
Децентрализованные
Вот тут уже гораздо интересней - остановимся подробней во второй части. Пока краткое описание, как работает.
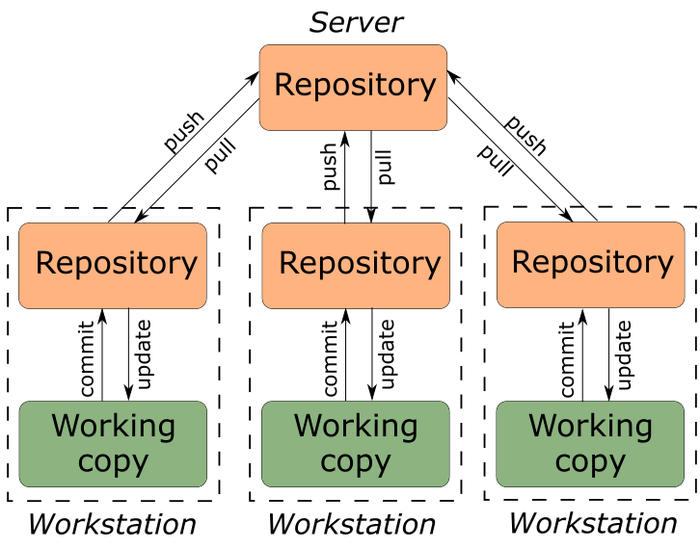
как видим у нас есть центральный репозиторий, и при этом у каждого разработчика есть свой, так что если что-то пойдет не так, мы быстро сможем восстановить актуальность состояния ПО.
Коротко рассмотрели, давайте подробней теперь на децентральзованных.
1.2 Накуа надо и как работает
Всем знакома ситуация:

----------------------------

Папки конечно могут называться по разному. Например: "правил дизайн" и т.д.
В папке "Изменения Васи" поменялся файл index.php и т.д.
можно решить таким способом данную проблему:
Вася пишет исправлял файл
...
...
и т.д.
Петя пишет исправлял файл
...
...
и т.д.
Так вот, представьте что у Вас работает над проектом так человек 20-ть, как быстро показать заказчику проект со всеми изменениями?
Правильно подумали, открывает файл и начинаем копировать файлы с изменениями в папку "Рабочая версия". Вам ничего не кажется странным? :) пишите в комменты что думаете о таком подходе.
И у нас вдруг возникает ситуация, что Вася и Петя редактировали один файл.
Что будем делать?
Если честно я хз, как решать подобное, но срок релиза отложился до решения проблемы.
По головке не погладят точно.
Вот тут и приходит на помощь наш репозиторий.
Буду рассматривать git, материалы приведенные мной это книга по git
link to book:
и так поехали.
Я не буду рассматривать установку на свой ПК сервера git
Некоторые моменты, я специально буду опускать, они простые и чаще всего находятся в материале, на которые я привожу ссылки. Они появятся в виде вопросов к концу главы или раздела.
И так мы уже знаем, что наш git - это СКВ.
Как же он устроен и почему на сегодня он лидер в данной области?
Неужели весь код хранится на сервере, каждый файлик.
Это и так и не так.
Во первых все изменения происходят у Вас локально. Т.е. сервер не знает, что вы там наделали. Инфа приходит есму после, того как Вы ее туда отправили.
Локально в момент добавления файла пищется информация о названии файла, что в нем есть (если только добавили), и далее заносится информация о изменениях (я бы назвал ее дельта изменений), кто и когда создал, ветка (позже расскажу) и комментарий.
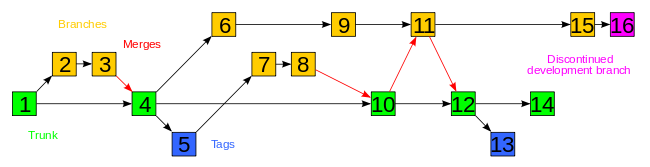
Получается вот такая картина:
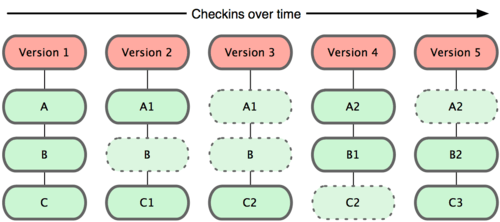
Давайте рассмотрим подробнее что тут отображено:
Version - история изменений (коммитов)
A, B, C - файлы.
Наверное у Вас возникли вопросы, че за **но одни пунктиром, другие нет.
Так в этом и заключается версионность. Сам git не сохраняет полный файл к себе каждый раз, когда вы сохраняете состояние. Он сохраняет только изменения, измененных файлов. Если файл не менялся, то будет просто (условно) сказано (фактически ссылка на файл), файл без изменений.
Получается, что мы можем видеть что конкретно в какой строке поменялось в файле.
Удалилось или добавилось. При этом достаточно компактно.
На сим давайте закончим. Основа задана, далее по линку. А мы поедем дальше.
Самое важное.
Состояния файлов в гит. Это действительно важно, без этого не понять как работает система контроля версий.
и так, есть три состояния:
а) подготовленный - будет включен в репозиторий при commit
б) измененный - изменили файл
в) зафиксированный - зафиксировали, значит отправили с локальный репозиторий (помните где он да?)
Как видно у нас есть файл Petya.txt. Git видит его и сообщает нам о том, что данный файл не добавлен у нас в отслеживание изменений. сейчас у файла нет ни одного из трех состояний.
Их называют не отслеживаемые файлы. Ну само вытекает как бы из этого.

Теперь добавим файл в отслеживание.
(Команды пока я опускаю, мы к ним еще придем.)
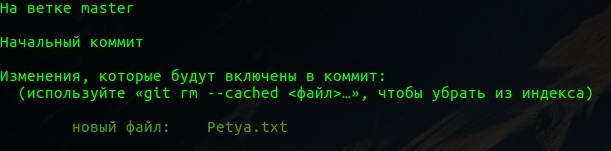
Теперь у нас файл принял состояние №1 - подготовленный, т.е. когда мы сохраним данные локально в репозиторий, он будет включен в продукт для изменений. При этом изменения уже начали отслеживаться.

Теперь файл зафиксировали в нашем локальном репозитории. Состояние №3, при отправке на сервер от будет отправлен.
А теперь давайте сделаем состояние №2. Напишем внутри файла строку:
Petya the Best. Как видно на картинке ниже git отметил наш файл как измененный
----------------------------------------------------------------------------------------------
Отдохнули, налили чай. Едем дальше.
И так, что надо сделать, чтобы начать работу.
Далее и на протяжении почти всех постов я буду использовать git для работы, пожалуйста отнеситесь серьезно к этому посту.
Для начала давайте поставим необходимые программы для работы.
Linux: ссылка на мануал по установке
Windows: http://msysgit.github.com/
Для тех кто использует Windows, разработчики git написали:
"Пожалуйста, используйте Git только из командой оболочки, входящей в состав msysGit, потому что так вы сможете запускать сложные команды, приведённые в примерах в настоящей книге. Командная оболочка Windows использует иной синтаксис, из-за чего примеры в ней могут работать некорректно."
После того, как установили приложение приступим уже к практической части.
Когда учили автора статьи использовать технологии командной разработки у нас было 2 дня теории и 4 дня практики, нам дали целый сервер на 20-ть человек и мы делали с ним все что хотели в рамках заданий. Именно поэтому я стараюсь сделать упор именно на практически часть в рамках всего курса. Ну если можно так сказать (:
Фактически у нас есть два способа создать репозиторий. Рассмотрим.
1. Склонировать готовый, (допустим на работе уже давно создано)
2. Создать новый локально.
И так способ 1-й.
Идем на bitbucket.org (github и др.)
регистрируемся, там есть кнопка создать репозиторий, (останавливаться не буду, в сети полно материалов как это сделать).
на ПК создаем каталог в котором будет находится копия нашего ПО, склонированного с сервера. Пишем команду:
git clone https://bitbucket.org/bla-bla-lba (в созданном репозитории на bitbucket уже есть ссылка на проект).
Мы должны в нашей папке увидеть проект, название папки = название проекта.

Жмем создать. Все наш репозиторий на bitbucket создан.
Можем приступать к работе. Внизу на странице у нас две ссылки:
У меня уже есть проект
Я начинаю полностью с нуля
Сейчас мы выберем, я начинаю проект с нуля:
git clone https://nibbler-ws@bitbucket.org/nibbler-ws/testing-repository.git
получаем ссылку на клонирование нашего проекта к себе на ПК.
Я советовал бы всем кто начинает программировать или кто уже умеет, пользоваться консолью.
Теперь открываем консоль и понеслась.
1. Выбираем папку куда будем клонировать наш пустой (пока) репозиторий.
Собственно моя папка куда мы будем производить сие действие.
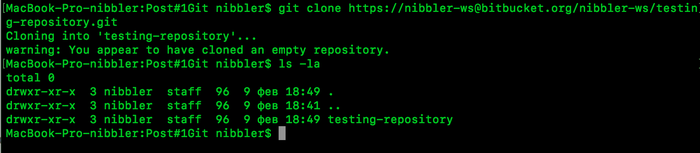
Оп, наш репозиторий готов. Теперь у нас есть два репозитория, один на нашем сервер, второй на нашем ПК.
И так репозиторий готов, приступим к работе с файлами. Правда для начала давайте пробежимся коротко по GUI приложениям для git:
GitKraken - на мой взгляд просто красивый :) Эта сволоч платная, но красивая.
Есть и free-план
В остальном можно обойтись консолью, так как я работаю в основном на Ubuntu/Mac то клиентов могу назвать еще пару, но можно просто погуглить.
Ладно передохнули, начнем. Создаем файл в нашей папке Petya.txt

touch и прочие мной используемые команды ищите пожалуйста в интернете, они просты, а Вы сразу подучите консоль.
и так мы сделали клон репозитория ранее, перешли в папку, создали файл Petya.txt и попросили git показать статус (назовем это так). В данном случае git говорит нам, что видит наш файл, но он его не отслеживает. Что это значит, а это значит что ничего, что мы там напишем не попадет на наш сервер. Давайте попробуем зафиксировать наши изменения.
Нам сказали, что парень какого? У тебя нихрена не добавлено, давай работай. И показал, что есть файлы которые просто не отслеживает. Снова :) Мы всегда будем их видеть.
Ну давайте скажем следить ему за файлом.

Странно, но нам ничего не сказали. Конечно зачем :) мы уже просто и так добавили файл
Но если сейчас запросить статус увидим, такую картину:
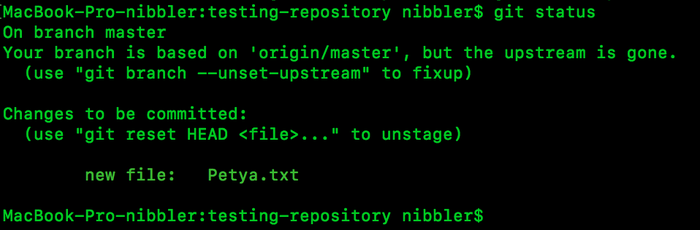
Ага мы получили искомое состояние, файл отслеживается. Отлично. Теперь хочу внести ясность.
То что файл отслеживается, не означает, что все абсолютно все изменения Вы можете вернуть. Вот нифига подобного :) вы можете вернуть только изменения, которые были зафиксированы в состоянии вашего репозитория. Наглядно это выглядит так:
А: ( Строка ХАХАХ ) фиксируем изменения | ( Строка ХАХАХ ) -> ( Строка ХАХАХ2 ) -> ( Строка ХАХАХ123 ) -> ( Строка ХАХАХ Кхе-Кхе ) фиксируем изменения.
В конечном итоге у нас будут в репозитории файл в двух состояний:
А: ( Строка ХАХАХ ) -> ( Строка ХАХАХ Кхе-Кхе ).
Надеюсь это понятно. Едем дальше. Сделаем первый коммит теперь (фиксация изменений).

нам сообщили, что наш файл зафиксирован. 1 файл изменен, строк добавилось 0, удалено 0.
и хэш. Клево правда :)
Посмотрим лог (история фиксаций):
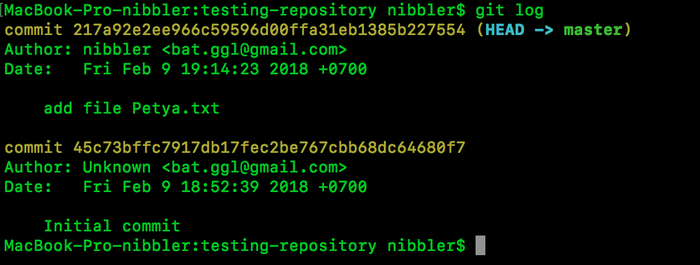
Отлично, давайте разберем, что у нас получилось:
commit - хэш коммита, для чего он буду рассказывать позже.
автор - собственно кто создал коммит.
Дата
И список файлов, которые были изменены.
теперь отправим наши изменения на сервер. Мы помним уже, что наш файл был добавлен и зафиксирован, теперь чтобы все разработчики его увидели нам надо сделать push (или отправить на наш сервер).
Для этого делаем git push.

У меня остался последний блок который я могу добавить :) мать его да у меня статья не влезла полностью первая, надо что-то думать :)
Читая Ваши комментарии и просматривая ссылки наткнулся на такой комментарий от пикабушника.
"Вот ты пишешь, что твои посты в горячем нахер не нужны. B я только на 30 лекции на тебя наткнулся." Пруф по ссылке
Я вот даже не знаю, просить как-то неудобно Вас. А люди мучаются :(
ПЫ.СЫ. вторая часть тоже готова уже, просто все не влезло. Скоро надеюсь смогу публиковать двумя частями. Завтра тогда домашка блин.
Почитал комментарии к посту, да и время было подумать над тем, с чего действительно надо начать.
Мнения аудитории оказались обсолютно разные, кто-то просит node, js, ruby.
Сразу могу сказать, каждая технология рождена под конкретные задачи.
Нет разницы в одном, это стиле написания кода, архитектуре, и проектировании.
Сам синтаксис может быть абсолютно разным, со строгой типизацией или нет, с форматированием или нет, это не так важно, главное как Вы мыслите.
Сразу скажу, для тех кто подписался, изначально будем разбирать основы: php, mysql, систем контроля версий.
Далее мы будем рассматривать сразу framework's. Не будет CMS: wordpress, joomla и т.д.
Сразу скажу, тем кто с 0-ля. Будет тяжко, темп будет не простой, усваивать надо будет быстро, да и по паре часов готовьтесь уделять вечерами. Могу сказать одно спустя время порадуетесь за себя, и то, что Вы сделали.
По подаче материала.
Так как я пишу впервые (не считать 3 поста), то думаю уроки будут выглядеть так:
1. Теория насколько позволит пикабу. Буду стараться с картинками и объяснением "накуа".
2. Домашка - на домашку отводить буду 4-6 дней, 1 день на разбор домашки, ответы по которой буду публиковать в виде поста.
3. Видеоконференция - ну это редкость, будет, имхо пока проблема со временем, но постараюсь.
Самое главное первоначально, что надо научиться - хранить контроли версий ваших файлов, вот именно с этого и начнем.
Собственно следующая глава будет им и посвящена.
разберем: Зачем? Как? Почему? и главный вопрос: "какого и так все норм, пишу так годами".
ПЫ.СЫ.
По выходам материала, постараюсь каждую неделю. Все будет зависеть от загруженности на работе и сложности материала.
ПЫ.СЫ.2
Блин не думал, что за сутки наберу больше 200 подписчиков, теперь главное не обосраться :) перед Вами :) а то аж стыдно будет :)
Телеграмм чат. - https://t.me/huyakhuyak
Ну что же. Хотелось бы узнать у тех кто подписался с чего мы бы начали.
Давайте расскажу о своих навыках:
1. PHP (CMS различные перечислять не буду, пара framework)
2. Верстка и так понятно, что html/ccs +bootstrap
3. Redis, Memcache - кэш
4. Mysql MsSql Postgre
5. nginx / apache
6. Linux / Unix
7. разработка RestApi RestFull
8. Docker - контейнеры.
9. BDD / DDD / TDD
Это стэк мидла компании, в которой я работаю.
Поэтому видится примерно так:
1. начнем сразу с PHP причем версии 5.6 с плавным переходом на 7.1. Тут надо просто понимать отличия между ними в сравнении
2. потом блок по БД, ибо это один из важных блоков без него никуда
3. Далее поработаем с кэшированием.
4. И сделаем API под мобильное приложение.
Попробую структурировать от простого к сложному, затронем алгоритмы, сотрировки, шаблоны проектирования, покрытие кода тестами.
Поэтому прошу подписчиков своих написать. Кто что знает, настраивал ли на ПК себе apache или nginx, с какой ОС сидит на пикабу)
Ну и начнем отсюда плясать, до джуна точно Вас дотяну, а может и до Low-Middle. А дальше сами уже), по крайней мере работу найдете)
Прошу строго не судить.. Наткнулся на давно и широко известную по Пикабу контору (ШП) она же geekbrains.
В общем, кому надо поучится или что-то подобное. Если у Вас есть интерес, попробую написать стартовый бесплатный цикл статей по программированию сайтов, фишек всяких. Сам что-то вспомню да и Вам подарю возможность сменить профессию :)
Минусы внутри, вопросы туда же.
Спасибо за внимание.
