Вышла новая модель HRM-Text-1B
Разработана новая модель HRM-Text-1B (https://huggingface.co/sapientinc/HRM-Text-1B) с отказом от дорогостоящего предобучения на сыром тексте в пользу архитектурно-целевого проектирования.
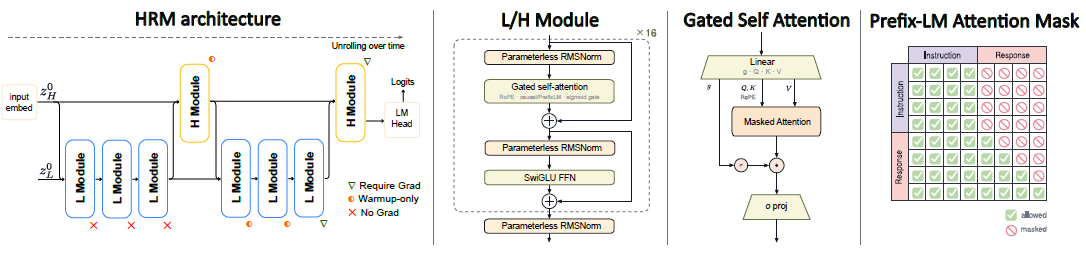
Использовали архитектуру, состоящую из иерархической рекуррентной модели (HRM) с медленным (H) и быстрым (L) слоями для имитации двухуровневой обработки. Для стабилизации глубокой рекуррентности применяли MagicNorm (PreNorm блоки и финальная норма на выходе), прогрев глубины обратного распространения (сначала 2 шага, затем до 5), а также Gated self-attention, SwiGLU, RoPE и parameterless RMSNorm.
Обучали только пары "инструкция-ответ" (без предобучения на неразмеченном тексте), при этом целевая функция -log P(xa | xq) осуществляла предсказание только ответа, в то время как маска внимания PrefixLM применяла двунаправленное внимание к инструкции и каузальное к ответу.
Исследование показало, что рекуррентность даёт большую эффективную глубину (logit lens, покомпонентные изменения), а загрязнение бенчмарков статистически незначимо или не влияет на выводы.
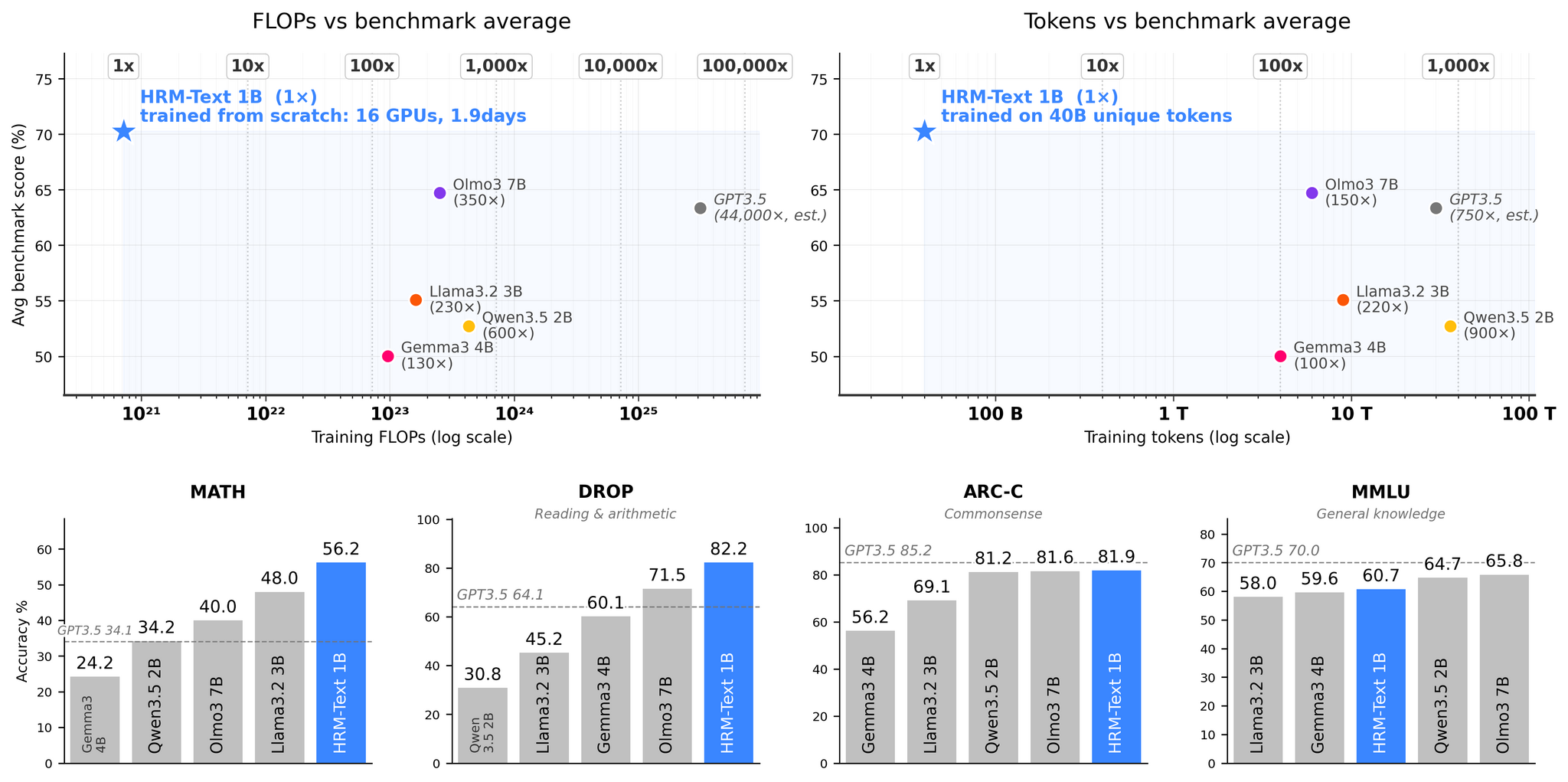
В результате удалось провести обучение с нуля на 40 млрд уникальных токенов при бюджете около $1500 (1,9 суток на 16 GPU) и получить 60.7% на MMLU, 81.9% на ARC-C, 82.2% на DROP, 84.5% на GSM8K и 56.2% на MATH, что сравнимо с открытыми моделями 2-7B параметров, используя в 100-900 раз меньше токенов и в 96-432 раза меньше вычислений.