

Удалить дубликаты ячеек в таблице Эксель
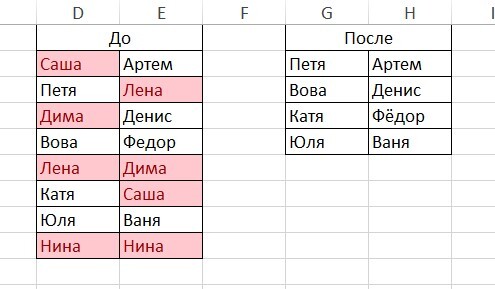
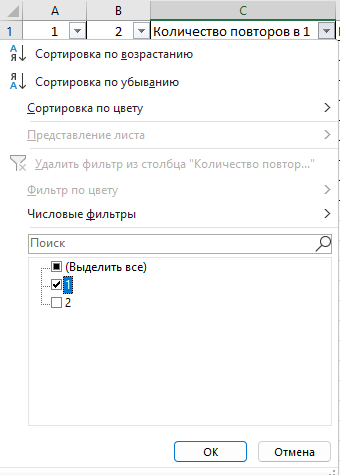
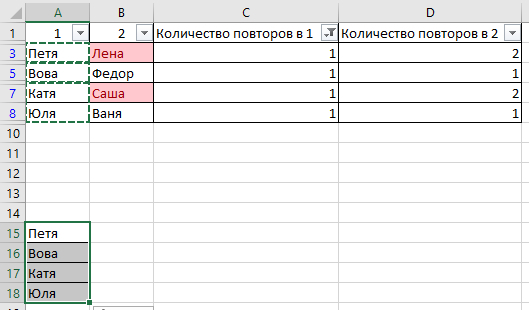
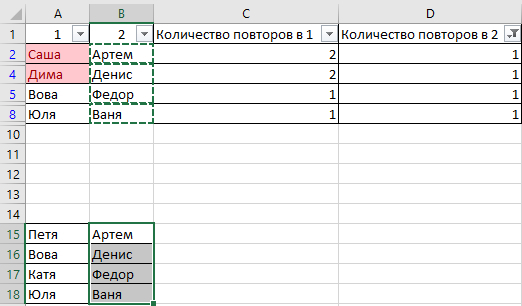
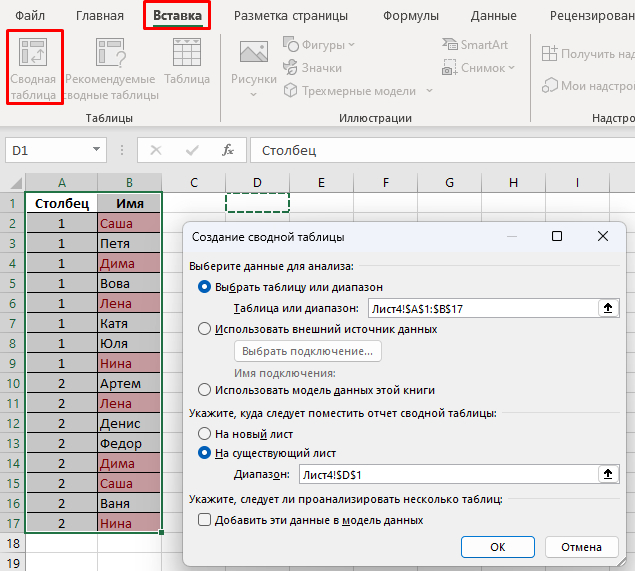
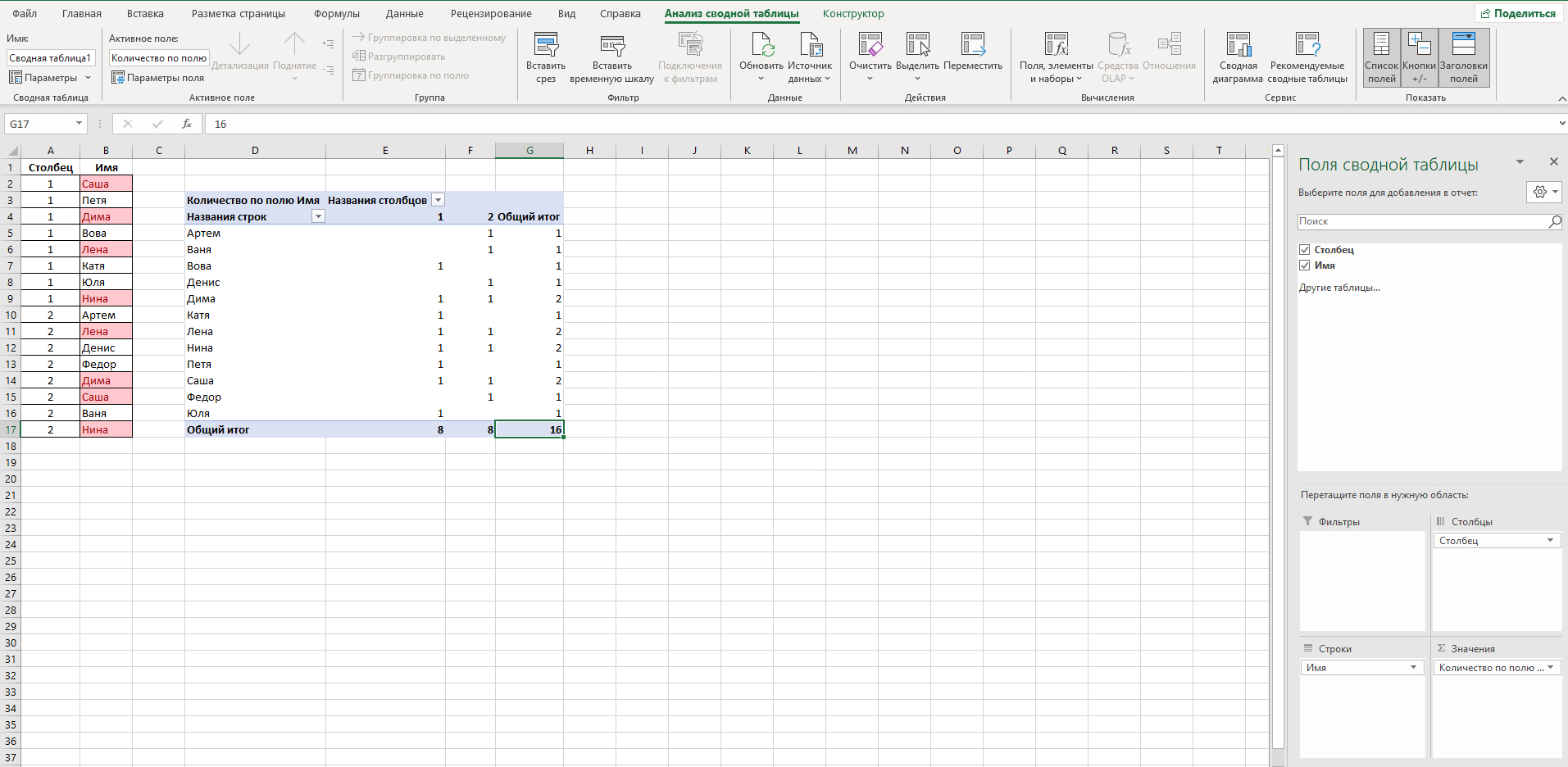
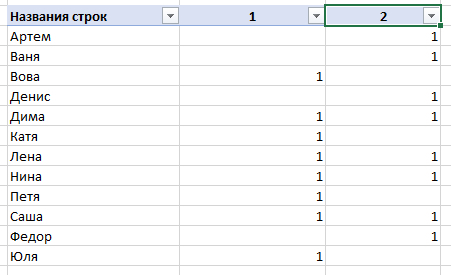
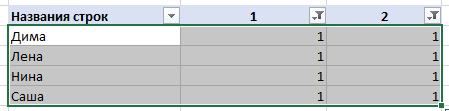
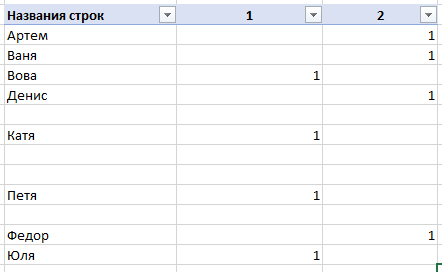
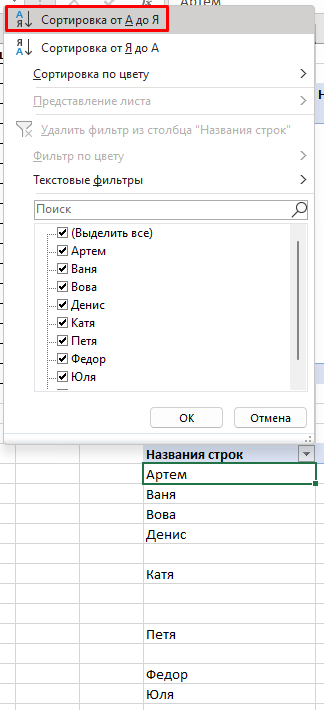
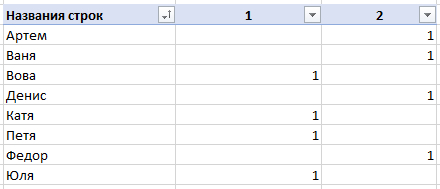
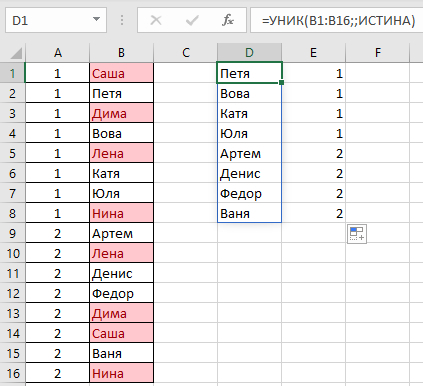
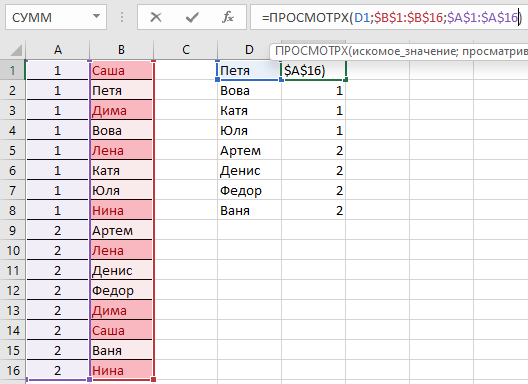
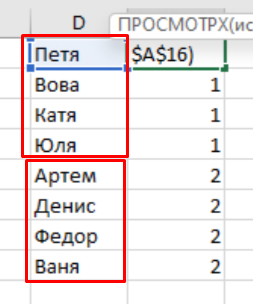
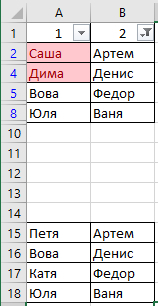
Может ли кто-то подсказать, как удалить одинаковые значения в разных столбцах таблицы Эксель? Поиск выдаёт громозкие формулы и ВПР, не верю, что нет простого решения. Получается выделить одинаковые значения и на этом всё.
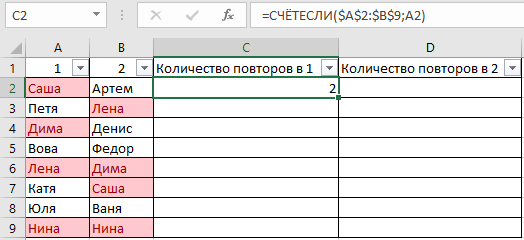
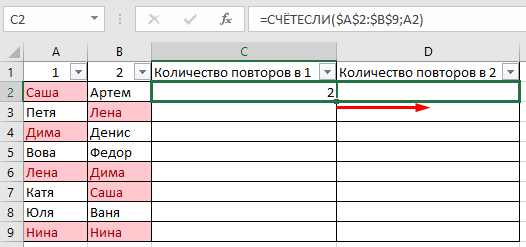
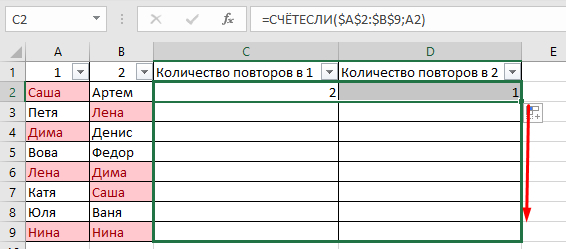
В таблице показала примерно, как вижу саму процедуру, но это сделала вручную, хотелось бы автоматизировать процесс на больших таблицах.
MS, Libreoffice & Google docs
764 поста14.9K подписчиков
Правила сообщества
1. Не нарушать правила Пикабу
2. Публиковать посты соответствующие тематике сообщества
3. Проявлять уважение к пользователям
4. Не допускается публикация постов с вопросами, ответы на которые легко найти с помощью любого поискового сайта.
По интересующим вопросам можно обратиться к автору поста схожей тематики, либо к пользователям в комментариях
Важно - сообщество призвано помочь, а не постебаться над постами авторов! Помните, не все обладают 100 процентными знаниями и навыками работы с Office. Хотя вы и можете написать, что вы знали об описываемом приёме раньше, пост неинтересный и т.п. и т.д., просьба воздержаться от подобных комментариев, вместо этого предложите способ лучше, либо дополните его своей полезной информацией и вам будут благодарны пользователи.
Утверждения вроде "пост - отстой", это оскорбление автора и будет наказываться баном.